

基于神经辐射场的自监督多相机占用预测
描述
1、笔者导读
我们提出了一种名为OccNeRF的方法,用于自监督多相机3D占用预测。该方法通过参数化重建的占用场来表示无限空间,并通过神经渲染将占用场转换为多相机深度图。为了提供几何和语义监督,该方法利用多帧图像之间的光度一致性进行监督。此外,为了语义占用预测,该方法还设计了几种策略来处理预训练的开放词汇模型。
2、解决了什么?
本研究提出了一种自监督的多摄相机3D占据预测方法,名为OccNeRF。该方法旨在解决无界场景的建模问题。
3、方法
主要包括以下几个方面:
参数化占用场景表示:
使用神经辐射场(Neural Radiance Fields,NeRF)来表示占用场景。
引入参数化坐标系,将无界的场景表示为有界的占用场景。
使用参数化坐标系中的体素来表示占用场景的内部和外部区域。
使用占用场景的体素表示来训练网络。
多摄像头特征聚合
对于每个摄像头,将其对应的图像特征投影到参数化坐标系中的体素上。
使用双线性插值将投影后的特征聚合为体素特征。
使用三维卷积网络提取特征并预测最终的占用输出。
多帧深度估计
使用体素渲染技术将占用场景投影到多摄像头的深度图上。
通过沿着摄像头中心到像素的射线采样一系列点,计算对应像素的深度值。
使用渲染权重代替密度来适应占用场景的表示。
使用多帧光度损失来训练深度估计模型。
开放词汇语义监督
使用多摄像头图像的二维语义标签提供像素级的语义监督。
通过将预训练的开放词汇模型的输出与图像特征进行对齐,生成二维语义标签。
使用二维语义标签来训练网络,提高几何一致性和体素之间的空间关系的捕捉能力。
4、损失函数
研究所涉及的损失函数有以下几种:
渲染损失:用于训练神经辐射场(Neural Radiance Fields,NeRF)模型的监督信号。通过计算渲染的像素颜色与真实像素颜色之间的差异来衡量模型的性能。
时序光度损失:用于多帧深度估计的监督信号。通过将相邻帧投影到当前帧,并计算投影图像与原始图像之间的重构误差来训练模型。
语义损失:用于语义三维占据预测的监督信号。通过提供多相机图像的二维语义标签,帮助网络捕捉几何一致性和体素之间的空间关系。
5、实验结果
本研究采用了自监督的多相机占据预测方法,称为OccNeRF。我们的实验方法和结果如下:
数据集:本研究在nuScenes数据集上进行实验,该数据集包含600个场景用于训练,150个场景用于验证,150个场景用于测试。数据集包含大约40000帧图像和17个类别。
自监督深度估计:首先,将LiDAR点云投影到每个视角上,得到深度图作为自监督深度估计的输入。然后,使用神经辐射场(Neural Radiance Fields,NeRF)方法进行深度估计。NeRF使用渲染方程将3D场景中的颜色和深度信息映射到2D图像中。本研究在NeRF的基础上进行改进,引入了时间光度约束和多帧渲染,以提高深度估计的准确性。
占据预测:为了预测场景中的占据情况,本研究使用了Grounding DINO模型和Grounded-SAM模型。首先,使用Grounding DINO模型生成检测边界框和对应的logits和短语。然后,将这些信息输入到Grounded-SAM模型中,生成精确的语义分割二值掩码。最后,使用体素渲染技术将语义标签投影到图像空间中,得到占据预测结果。
实验评估:本研究使用了多个评估指标来评估深度估计和占据预测的性能,包括绝对相对误差(Abs Rel)、平方相对误差(Sq Rel)、均方根误差(RMSE)等。同时,与其他自监督和有监督方法进行了比较,以验证OccNeRF方法的优越性。
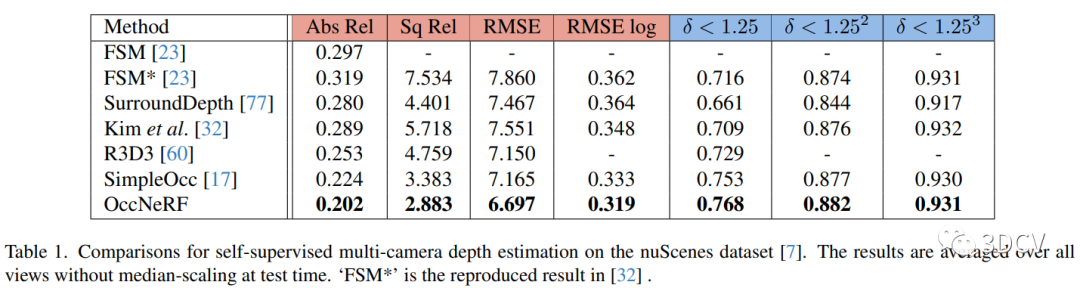
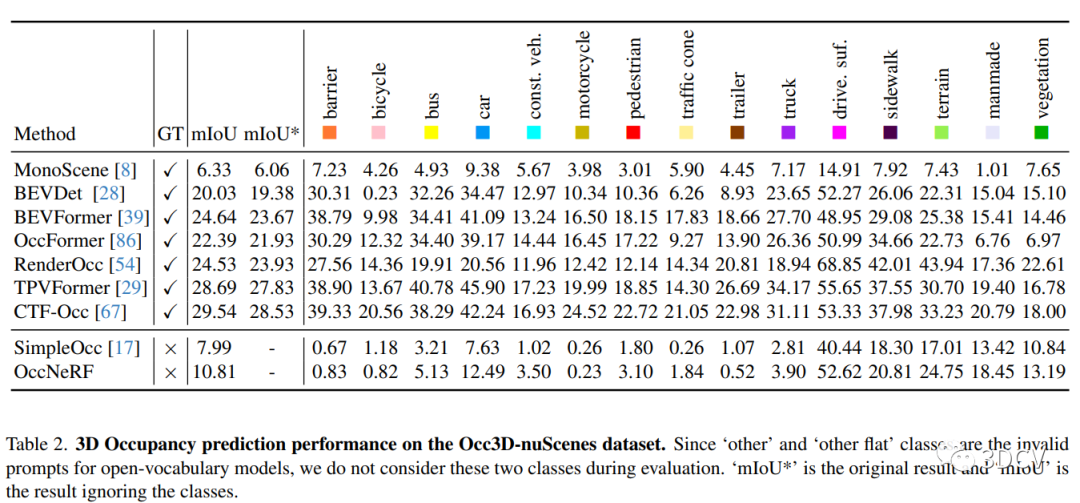
5、总结
本研究通过自监督深度估计和占据预测方法,实现了对多摄像头场景中的占据情况的准确预测。实验结果表明,OccNeRF方法在深度估计和占据预测方面取得了较好的性能。
审核编辑:黄飞
-
有提供编写神经网络预测程序服务的吗?2011-12-10 1762
-
关于BP神经网络预测模型的确定!!2014-02-08 4328
-
如何用卷积神经网络方法去解决机器监督学习下面的分类问题?2021-06-16 3016
-
基于小波包_神经网络的太阳逐时辐射预测_陈杰2016-12-31 917
-
基于概率的无监督缺陷预测方法2017-11-21 1002
-
多相机视域下行人目标匹配2018-03-07 704
-
自监督学习与Transformer相关论文2020-11-02 3461
-
基于主动学习的半监督图神经网络模型来对分子性质进行预测方法2020-11-24 5338
-
采用自监督CNN进行单图像深度估计的方法2021-04-27 1290
-
基于多相机捕捉系统下的通用物体运动捕捉方法2021-06-25 885
-
介绍一种神经场成对配准的技术NeRF2NeRF2023-02-20 1463
-
NeRF2NeRF神经辐射场的配对配准介绍2023-03-31 1889
-
基于神经辐射场(NeRFs)的自动驾驶模拟器2023-08-01 1435
-
WACV 2023 I从ScanNeRF到元宇宙:神经辐射场的未来2023-09-01 1522
-
基于几何分析的神经辐射场编辑方法2023-11-20 1645
全部0条评论

快来发表一下你的评论吧 !
