

AI算力服务器技术及产业链报告
人工智能
描述
算力调度层可类比为“算网大脑”,是算力网络中最核心的部分。除技术自身的难 度外,算力调度还需综合考虑成本、需求等因素,是困难的多约束求解问题。1)技 术:算力调度的技术创新主要包括计算能力跨区域调度、多级调度、算力资源统一 安排、网络协议、可视化监控和智能运维。2)需求:不同的应用场景对应不同的算 力或时延需求,如科学计算类和国计民生类工程项目需要超高算力,而普通商用、 民用交互场景则往往侧重于对时延的要求。3)成本:算力调度的一般原则为,根据 算力、时延要求,选择最经济的算力网络架构布局,来降低算力成本、网络成本、 运营成本。
算力调度平台建设如火如荼。“东数西算”工程启动以来,各地区相关单位就算力 度量、算力互联互通、算力调度、算力交易等重点问题展开前瞻性研究。据不完全 统计,目前全国已发布或建设 10 余个算力平台,涉及 3 个省份和 7 个城市,其中既 有“东数西算”枢纽节点,也有非枢纽节点参与算力平台建设。1)宁夏上线国内首 个一体化算力交易调度平台——东数西算一体化算力服务平台,该平台可为智算、 超算、通用算力等各类算力产品提供算力发现、供需撮合、交易购买、调度使用等 综合服务。2)北京发布算力互联互通验证平台,并已初步实验跨服务商、跨地区、 跨架构的算力互联互通能力,未来将实现对京津冀地区,宁夏、内蒙等国家算力枢 纽、四部战略合作地区的算力互联互通。
算力平台多以政府/国企/研究机构/数据单位/超算中心为建设主体,联合数据运营公 司、数据服务企业、数字化转型解决方案提供商等企业,及算力服务提供商、设备 商、大模型厂商等共同建设。以宁夏东数西算一体化算力服务平台为例,该平台通 过资源整合,已将中科曙光、华为、中兴、阿里云、天翼云等国内大算力领先企 业,国家信息中心、北京大数据研究院等国内主要大数据机构,以及商汤、百度等 大模型头部企业,中国电信、中兴通讯、万达信息、安恒信息、鹏博士、思特奇等 多家上市公司共计 27 家纳入平台。
算力调度,算力网络的大脑中枢
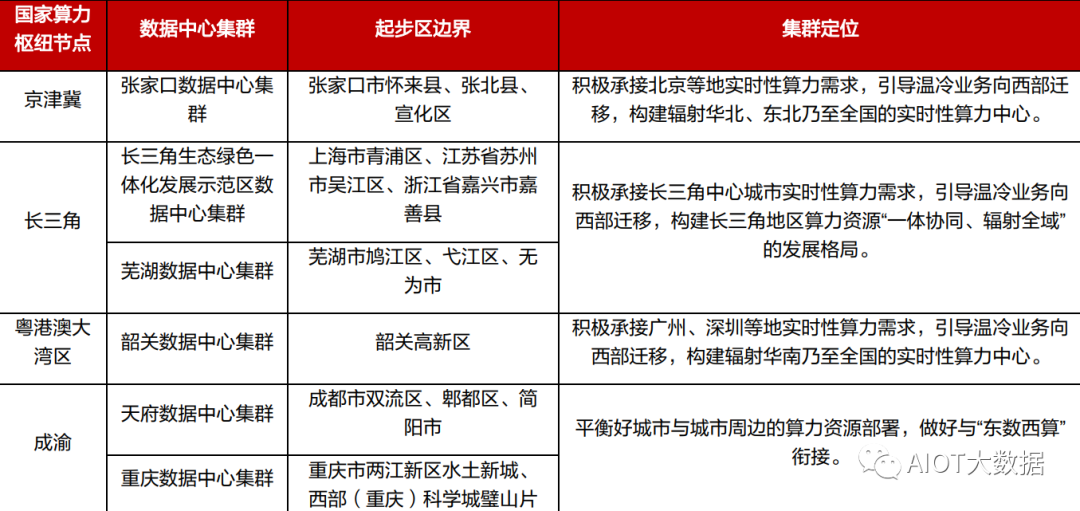
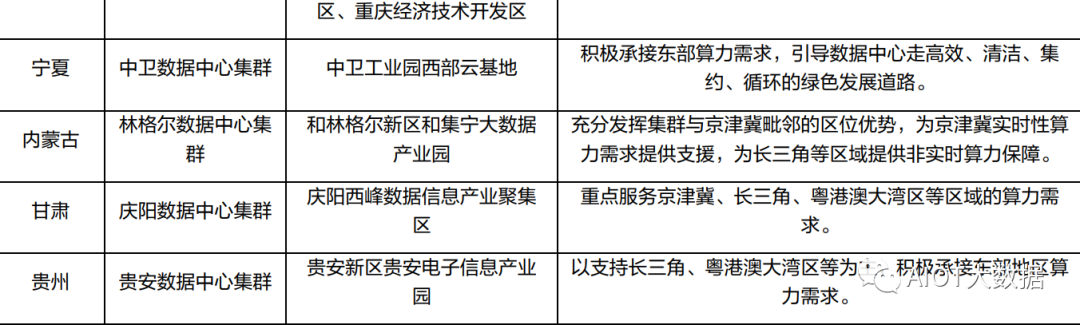
“东数西算”拉开全国一体化算力网络序幕,布局 8 大枢纽节点、10 大集群。2022 年 2 月 17 日,国家发改委、中央网信办、工信部、国家能源局联合印发通知,同意在京津冀、长三角、粤 港澳大湾区、成渝、内蒙古、贵州、甘肃、宁夏等 8 地启动建设国家算力枢纽节点,并规划了 10 个国家数据中心集群。至此,全国一体化大数据中心体系完成总体布局设计,“东数西算”工程 正式全面启动。根据布局,8 个国家算力枢纽节点将作为我国算力网络的骨干连接点,开展数据中心与网络、云 计算、大数据之间的协同建设,并作为国家“东数西算”工程的战略支点。每个枢纽节点将发展 1-2 个数据中心集群,算力枢纽和集群的关系,类似于交通枢纽和客运车站,数据中心集群将汇 聚大型、超大型数据中心,具体承接数据流量。
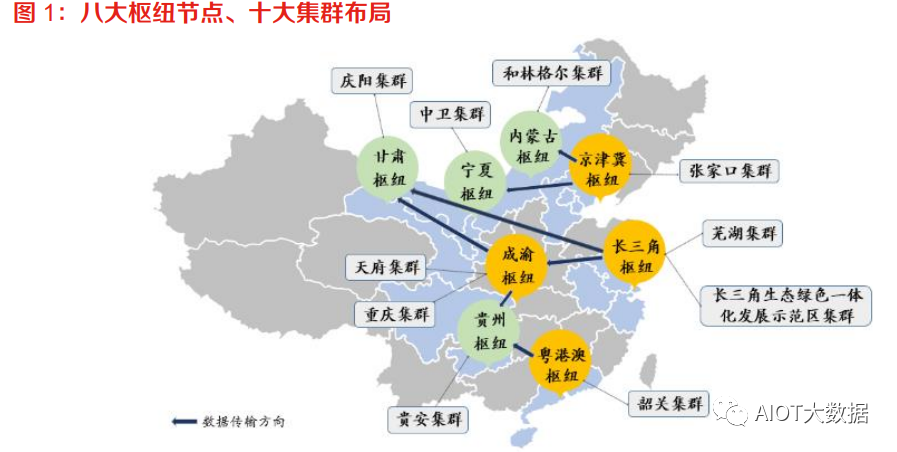
算力网络的目标,实现算力随取随用。
1961 年,美国科学家约翰·麦卡锡曾提出,算力应该像水 电资源一样随用随取。以电力资源为例,电力基础设施从发电、输电、储电、用电等各个环节全 面实现全局统一和环节解耦。发电环节,不论火力发电、水力发电还是光伏发电,都通过统一规 格和标准接入电网;输电环节,电网建设已经实现大范围覆盖,可以实现分级分片的电力资源的 多级管理和统一调度,做到电力资源即插即用。然而类比来看,算力设施基础化依然有一段路要 走。中国工程院院士、中国科学院计算技术研究所学术委员会主任孙凝晖认为,算力设施基础化 存在两个核心问题,一是标准化、统一供给,二是算力使用的抽象化。算力抽象的目的是使算力 的获取、使用更便捷更易上手,并基于抽象的生成工具、传输工具、消费工具,做出丰富多样的 各行各业应用。算网之于算力基础设施,就类似于电网之于电力基础设施,是串联起各环节的桥 梁。
算力网络分为资源层、控制层、服务层和编排管理层。
算力国际标准 ITU-T Y.2501 中提出将算力 网络功能架构分成 4 大模块:算力网络资源层、算力网络控制层、算力网络服务层和算力网络编 排管理层。其中,算网资源层主要提供算力资源、存储资源和网络转发资源,并结合网络中计算 处理能力和网络转发能力的实际情况,实现各类计算、存储资源的传递和流动;算网控制层主要 通过网络控制平面实现计算和网络多维度资源融合的路由;算网服务提供层主要实现面向用户的 服务、原子功能能力开放;算网编排管理层主要解决异构算力资源、服务/功能资源的注册、建模、 纳管、编排、安全等问题。
编排管理(即调度)层可类比于算力网络的大脑。
“算网大脑”即算力网络中最核心的部分,主 要进行全网算力资源的智能编排、弹性调度,具体而言有四个作用:
1) 获取全域实时的算、网、数资源,以及云、边、端分布情况,构建全域态势感知地图。
2) 跨域协同调度,将多域协同的调度任务智能、自动地分解给各个使能平台,实现算、网、数 的资源调度。
3) 多域融合编排,针对多域融合业务需求,基于算、网、数的原子能力按需灵活组合编排。
4) 智能辅助决策,基于不同业务的 SLA 要求、网络整体负载、可用算力资源池分布等因素,智 能、动态地计算出算、网、数的最优协同策略。
算力调度需综合考虑需求、成本等因素。
目前,我国东中西部数字新型基础设施布局不平衡的问 题依然存在,东西部数据中心在用机架数大概比例在7:3,北上广深等一线城市存在明显的供不应 求,平均缺口率达 25%,而中西部地区能源条件丰富,算力资源有一定的产能过剩。因此需通过 编排管理调度实现资源的合理分配与使用。由于平台异构、部署差异、网络带宽资源性价比差异等原因,算力调度存在诸多挑战。除了技术 本身的挑战外,还存在是否调度的问题,即资源在跨中心的流通还需考虑成本问题、代价问题以 及一些商业情况的问题。一般而言,算力调度主要针对计算、存储、时延等要求高的场景。
需求 1:算力。算力要求高的场景,如科学计算类和国计民生类工程项目,需依托超级算力 平台来实现。截至 2022 年 12 月,科技部批准建立了 10 家国家超级计算中心,分别位于天 津、广州、深圳、长沙、济南、无锡、郑州、昆山、成都、西安。另外鹏城实验室、华为公 司等联合建设了包括 20 个节点的中国算力网,主打 AI 算力。从布局看,均为集中式的算力 能力库需求。
需求 2:时延。针对普通商用、民用交互场景,时延则是关键因素。时延敏感型业务可分为 通信类、功能类、三维交互类。
(1)通信类:主要解决人的通信需求。一般而言,实时竞 技类游戏的时延要求是 50ms;实时交互类游戏的时延要求是 100ms;实时交互语音类的时 延要求是 100ms;实时交互视频类的时延要求是 150ms;非实时大部分互联网应用时延要 求是 300ms。
(2)功能类:主要指机器之间的通信需求,例如工业自动化控制的时延要求 是小于 10ms;远程 / 遥控驾驶的时延要求是小于 10ms。
(3)三维交互类:基于三维显示 和交互的元宇宙应用,为了避免头晕,需要 10ms 以内的交互时延。
成本:不同业务的需求决定了选择算力、网络的下限,往往对应多种算力调度方式。最终的 算力调度方式还取决于成本,一般原则为,根据算力、时延要求,选择最经济的算力网络架 构布局,来降低算力成本、网络成本、运营成本。
据不完全统计,目前全国已发布或建设 10 余个算力平台,涉及 3 个省份和 7 个城市,其中既有“东数西算”枢纽节点,也有非枢纽节点参 与算力平台建设。已经发布算力平台的地区有北京市、上海市、南京市、宁夏回族自治区、贵州 省、甘肃省,待发布算力平台的地区有深圳市,正在建设算力平台的地区有合肥市、郑州市、庆 阳市。数据显示,算力产业中每投入 1 元,平均将带动 3-4 元的经济产出,算力指数每提高 1 个 百分点可带来数字经济 3.3‰的增长和 GDP1.8‰的增长。
基于 GPT 4.0 模型的通信基础设施需求测算
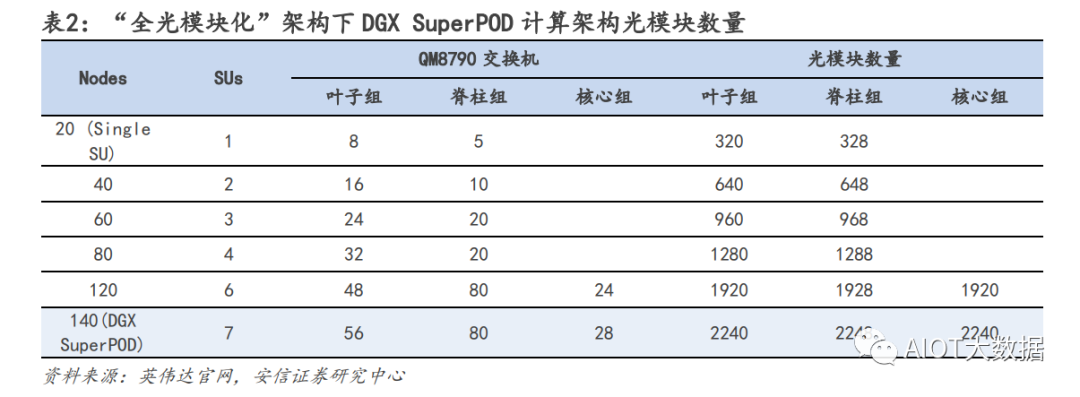
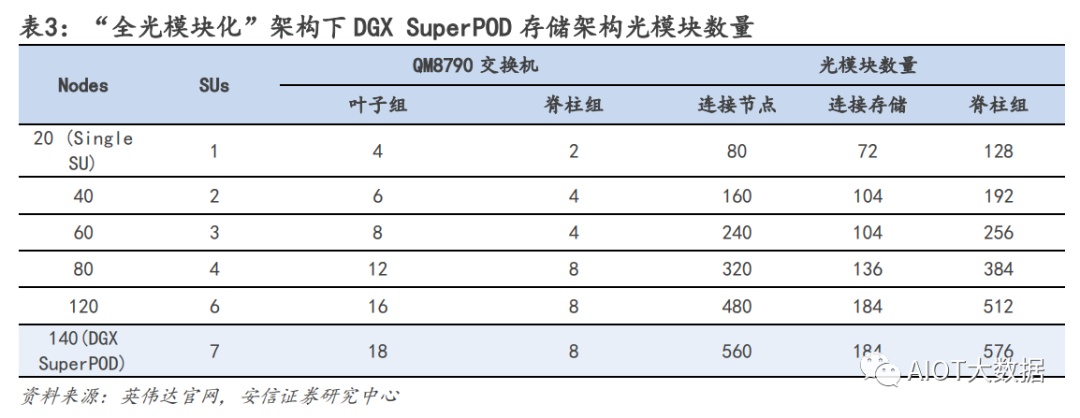
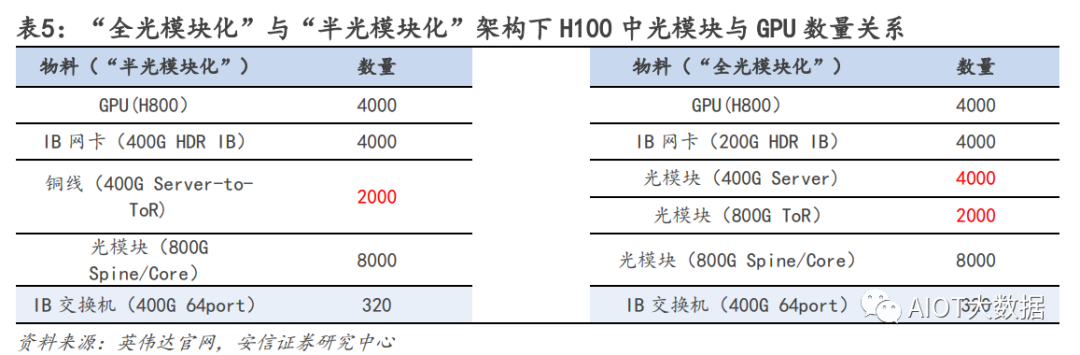
基于英伟达 AI 网络架构硬件需求比例:服务器:交换机:光模块=1:1.2:11.4 由于当前大部分 AIGC 模型都是基于英伟达方案来部署,我们从英伟达的 AI 集群模型架构进行拆解。对于较大的 AI 数据中心集群,一般可多达几千台 AI 服务器的需求,在部署方面会拆分成一个个基本单元 进行组件,英伟达对应的一个基本单元为 SuperPOD。根据 SuperPOD 公开信息:一个标准的 SuperPOD 由 140 台 DGX A100 GPU 服务器、HDR InfiniBand 200G 网卡和 170 台 NVIDIA Quantum QM8790 交换机构建而成,其中交换机速率为 200G,每个端口数为 40 个。
网络结构上,英伟达采用 Infinband 技术(“无限带宽”技术,简称 IB)和 fat tree(胖树)网络拓扑 结构,和传统的数据中心的区别在于,在 IB fat tree 结构下,使用的交换机数量更多,且因为每个节点 上行下行的端口数完全一致,使得该网络是是无收敛带宽的,每个端口可采用同样速率的光模块.
光模块用量测算:我们从线缆角度测算光模块需求,一个 SuperPOD 170 个交换机,每个交换机有 40 个端 口,最简单方式上下个 70 台服务器,依次端口互联(上下 1:1 连接)对应的线缆需求为 40×170/2=3400 根,但是由于实际网络拓扑结构交换价不是该情况,连接情况更加复杂且会分为三层结构,因此线缆数需 求有所提升,我们假设上升至 4000 根线缆需求。线缆的需求分为三种,第一种用在机柜内部,互联距离 5m 以内,常用需求为铜缆,不需要光模块;第二 类互联距离为 10m 以内,可以采用 AOC(有源光纤)连接,也不需要光模块;第三类,带光模块的光纤, 单根需求为 2 个光模块。考虑到 10m 以内的连接占据多数,我们假设铜缆:AOC:光模块光纤比例=4:4:2. 光模块需求=4000*0.2*2=1600 个。
对于一个 SuperPod,服务器:交换机:光模块的用量比例=140:170:1600=1:1.2:11.4. u 应用层面:单 GPT4.0 模型对于服务器需求用量测算 从用户使用角度来测算,我们对于服务器算力的测算受大模型参数,日活人数,每日每人提问等多因素影 响。在 ChatGPT 中,一个 token 通常指的是响应请求所需的最小文本单位,一般一个 30 词的提问大约对应 40 个 token,推理是 token 的算力调用是 2N。对应模型算力的需求我们分摊在一天 24h 的每一秒。

基于以下假设,我们可得到对应一个在 1 亿日活的应用需要的 AI 服务器的需求约为 1.5 万台。

弹性测算一:现有采购部署层面弹性测算(基础投入维度)
角度 1 我们选择从现有完成一个类似 GPT4.0 入门级别要求的需求假设去测算硬件基础设施层面需求。假设 1:结合现有各类公开数据,完成 ChatGPT4.0(训练+推理)需要至少 3 万张英伟达 A100 卡的算力投 入,对应 3750 台 A100 的 DGX 服务器。假设 2:全球假设国内和海外有潜在 20 家公司可能按照此规模进行测投入。假设 3:网络结构比例按照单个 SuperPOD 方式部署,即服务器:交换机:光模块的用量比例=1:1.2:11.4。假设 4:服务器价格参考英伟达价格,为 20 万美元;交换价结合 Mellanox 售价,假设单价为 2w 美金,光 模块根据交换机速率,现在主流为 200G,假设售价为 250 美金。结论:服务器、交换机、光模块的市场弹性分别为 15%、5%、3%。
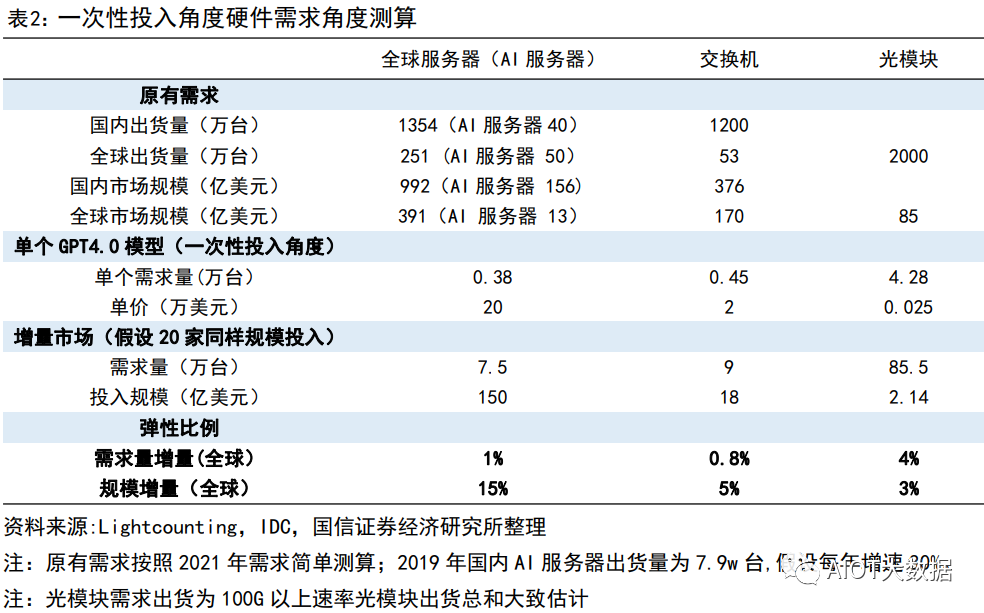
弹性测算二:下游需求亿级别大规模响应(远期应用规模起量角度) 角度 2:基于下游应用呈现规模角度,即按照单 GPT4.0 模型对于服务器需求用量测算。假设 1:单个应用的需求角度开看,服务器潜在用量为 1.5 万台。假设 2:全球假设国内和海外有潜在 20 家公司可能形成同样类型规模应用。假设 3:网络结构比例按照单个 SuperPOD 方式部署,即服务器:交换机:光模块的用量比例=1:1.2:11.4。假设 4:服务器价格参考英伟达价格,为 20 万美元;交换价结合 Mellanox 售价,假设为 2.5-3w 美金,光 模块根据交换机速率,现在主流为 200G,假设售价为 250 美金。结论:服务器、交换机、光模块的市场弹性分别为 65%、19%、10%。
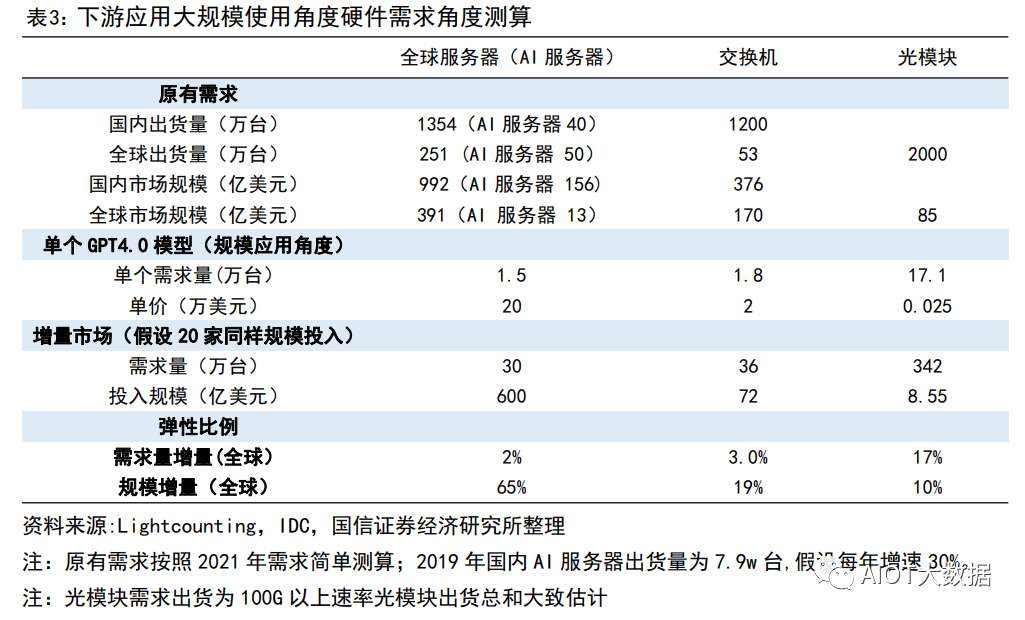

服务器整体市场情况
服务器构成:主要硬件包括处理器、内存、芯片组、I/O (RAID卡、网卡、HBA卡) 、硬盘、机箱 (电源、风 扇)。以一台普通的服务器生产成本为例,CPU及芯片组大致占比50% 左右,内存大致占比 15% 左右,外部 存储大致占比10%左右,其他硬件占比25%左右。
服务器的逻辑架构和普通计算机类似。但是由于需要提供高性能计算,因此在处理能力、稳定性、可靠性、 安全性、可扩展性、可管理性等方面要求较高。
逻辑架构中,最重要的部分是CPU和内存。CPU对数据进行逻辑运算,内存进行数据存储管理。
服务器的固件主要包括BIOS或UEFI、BMC、CMOS,OS包括32位和64位。
2022年12月,Open AI的大型语言生成模型ChatGPT火热,它能胜任刷高情商对话、生成代码、构思剧本 和小说等多个场景,将人机对话推向新的高度。全球各大科技企业都在积极拥抱AIGC,不断推出相关技术、 平台和应用。
生成算法、预训练模式、多模态等AI技术累计融合,催生了AIGC的大爆发。
目前,AIGC产业生态体系的雏形已现,呈现为上中下三层架构:①第一层为上游基础层,也就是由预训练 模型为基础搭建的AIGC技术基础设施层。②第二层为中间层,即垂直化、场景化、个性化的模型和应用工 具。③第三层为应用层,即面向C端用户的文字、图片、音视频等内容生成服务。
GPT模型对比BERT模型、T5模型的参数量有明显提升。GPT-3是目前最大的知名语言模型之一,包含了 1750亿(175B)个参数。在GPT-3发布之前,最大的语言模型是微软的Turing NLG模型,大小为170 亿(17B)个参数。GPT-3 的 paper 也很长,ELMO 有 15 页,BERT 有 16 页,GPT-2 有 24 页,T5 有 53 页,而 GPT-3 有 72 页。
训练数据量不断加大,对于算力资源需求提升。
回顾GPT的发展,GPT家族与BERT模型都是知名的NLP模型,都基于Transformer技术。GPT,是一种 生成式的预训练模型,由OpenAI团队最早发布于2018年,GPT-1只有12个Transformer层,而到了 GPT-3,则增加到96层。其中,GPT-1使用无监督预训练与有监督微调相结合的方式,GPT-2与GPT-3 则都是纯无监督预训练的方式,GPT-3相比GPT-2的进化主要是数据量、参数量的数量级提升。
未来异构计算或成为主流
异构计算(Heterogeneous Computing)是指使用不同类型指令集和体系架构的计算单元组成系统的计算方式,目前主 要包括GPU云服务器、FPGA云服务器和弹性加速计算实例EAIS等。让最适合的专用硬件去服务最适合的业务场景。
在CPU+GPU的异构计算架构中,GPU与CPU通过PCle总线连接协同工作,CPU所在位置称为主机端 (host),而GPU所在 位置称为设备端(device)。基于CPU+GPU的异构计算平台可以优势互补,CPU负责处理逻辑复杂的串行程序,而GPU重 点处理数据密集型的并行计算程序,从而发挥最大功效。
越来越多的AI计算都采用异构计算来实现性能加速。
阿里第一代计算型GPU实例,2017年对外发布GN4,搭载Nvidia M40加速器.,在万兆网络下面向人工智能深度学习场 景,相比同时代的CPU服务器性能有近7倍的提升。
CPU 适用于一系列广泛的工作负载,特别是那些对于延迟和单位内核性能要求较高的工作负载。作为强大的执行引擎, CPU 将它数量相对较少的内核集中用于处理单个任务,并快速将其完成。这使它尤其适合用于处理从串行计算到数据 库运行等类型的工作。
GPU 最初是作为专门用于加速特定 3D 渲染任务的 ASIC 开发而成的。随着时间的推移,这些功能固定的引擎变得更加 可编程化、更加灵活。尽管图形处理和当下视觉效果越来越真实的顶级游戏仍是 GPU 的主要功能,但同时,它也已经 演化为用途更普遍的并行处理器,能够处理越来越多的应用程序。
训练和推理过程所处理的数据量不同。
在AI实现的过程中,训练(Training)和推理(Inference)是必不可少的,其中的区别在于:
训练过程:又称学习过程,是指通过大数据训练出一个复杂的神经网络模型,通过大量数据的训练确定网络中权重和 偏置的值,使其能够适应特定的功能。
推理过程:又称判断过程,是指利用训练好的模型,使用新数据推理出各种结论。
简单理解,我们学习知识的过程类似于训练,为了掌握大量的知识,必须读大量的书、专心听老师讲解,课后还要做 大量的习题巩固自己对知识的理解,并通过考试来验证学习的结果。分数不同就是学习效果的差别,如果考试没通过 则需要继续重新学习,不断提升对知识的掌握程度。而推理,则是应用所学的知识进行判断,比如诊断病人时候应用 所学习的医学知识进行判断,做“推理”从而判断出病因。
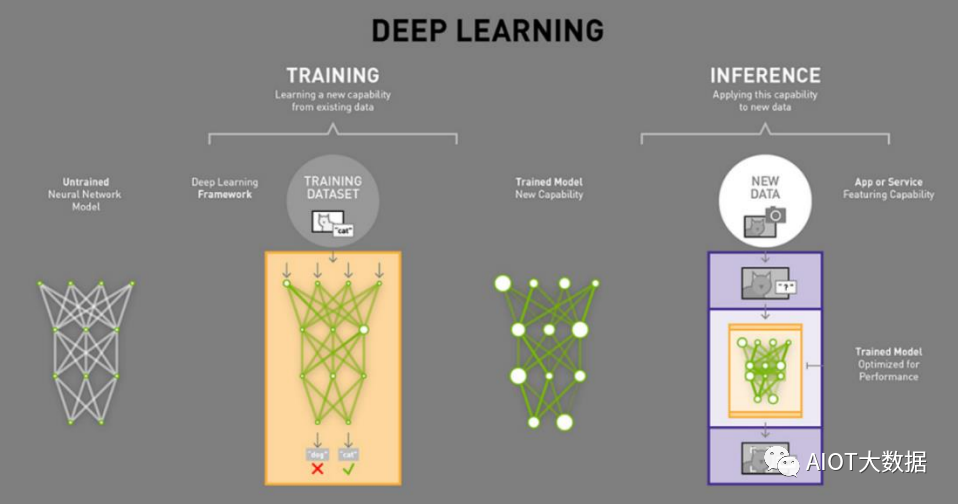
训练需要密集的计算,通过神经网络算出结果后,如果发现错误或未达到预期,这时这个错误会通过网络 层反向传播回来,该网络需要尝试做出新的推测,在每一次尝试中,它都要调整大量的参数,还必须兼顾 其它属性。再次做出推测后再次校验,通过一次又一次循环往返,直到其得到“最优”的权重配置,达成 预期的正确答案。如今,神经网络复杂度越来越高,一个网络的参数可以达到百万级以上,因此每一次调 整都需要进行大量的计算。吴恩达(曾在谷歌和百度任职)举例“训练一个百度的汉语语音识别模型不仅 需要4TB的训练数据,而且在整个训练周期中还需要20 exaflops(百亿亿次浮点运算)的算力”,训练是 一个消耗巨量算力的怪兽。
推理是利用训练好的模型,使用新数据推理出各种结论,它是借助神经网络模型进行运算,利用输入的新 数据“一次性”获得正确结论的过程,他不需要和训练一样需要循环往复的调整参数,因此对算力的需求 也会低很多。
此外,训练和推理过程中,芯片的部署位置、准确度/精度要求、存 储要求等都有所不同。
训练和推理所应用的GPU/服务器也有不同。
推理常用:NVIDIA T4 GPU 为不同的云端工作负载提供加速,其 中包括高性能计算、深度学习训练和推理、机器学习、数据分析和 图形学。引入革命性的 Turing Tensor Core 技术,使用多精度计算 应对不同的工作负载。从 FP32 到 FP16,再到 INT8 和 INT4 的精 度,T4 的性能比 CPU 高出 40 倍,实现了性能的重大突破。
训练:A100和H100。对于具有庞大数据表的超大型模型,A100 80GB 可为每个节点提供高达 1.3TB 的统一显存,而且吞吐量比 A100 40GB 多高达 3 倍。在 BERT 等先进的对话式 AI 模型上, A100 可将推理吞吐量提升到高达 CPU 的 249 倍。
根据OpenAI在2020年发表的论文,训练阶段算力需求与模型参数数量、训练数据集规模等有关,且为两者乘积的 6倍:训练阶段算力需求=6×模型参数数量×训练集规模。
GPT-3模型参数约1750亿个,预训练数据量为45 TB,折合成训练集约为3000亿tokens。即训练阶段算力需求 =6×1.75×1011×3×1011=3.15×1023 FLOPS=3.15×108 PFLOPS
依据谷歌论文,OpenAI公司训练GPT-3采用英伟达V100 GPU,有效算力比率为21.3%。GPT-3的实际算力需求应 为1.48×109 PFLOPS(17117 PFLOPS-day)。
假设应用A100 640GB服务器进行训练,该服务器AI算力性能为5 PFLOPS,最大功率为6.5 kw,则我们测算训练 阶段需要服务器数量=训练阶段算力需求÷服务器AI算力性能=2.96×108台(同时工作1秒),即3423台服务器工 作1日。

H100性能更强,与上一代产品相比,H100 的综合技术创新可以将大型语言模型的速度提高 30 倍。根据Nvidia测 试结果,H100针对大型模型提供高达 9 倍的 AI 训练速度,超大模型的 AI 推理性能提升高达 30 倍。
在数据中心级部署 H100 GPU 可提供出色的性能,并使所有研究人员均能轻松使用新一代百亿亿次级 (Exascale) 高性能计算 (HPC) 和万亿参数的 AI。
H100 还采用 DPX 指令,其性能比 NVIDIA A100 Tensor Core GPU 高 7 倍,在动态编程算法(例如,用于 DNA 序列比对 Smith-Waterman)上比仅使用传统双路 CPU 的服务器快 40 倍。
假设应用H100服务器进行训练,该服务器AI算力性能为32 PFLOPS,最大功率为10.2 kw,则我们测算训练阶段需 要服务器数量=训练阶段算力需求÷服务器AI算力性能=4.625×107台(同时工作1秒),即535台服务器工作1日。
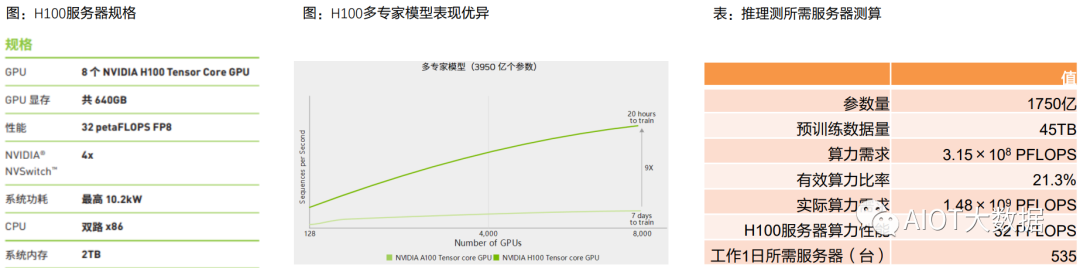
根据天翼智库,GPT-3模型参数约1750亿个,预训练数据量为45 TB,折合成训练集约为3000亿tokens。按照有 效算力比率21.3%来计算,训练阶段实际算力需求为1.48×109 PFLOPS。
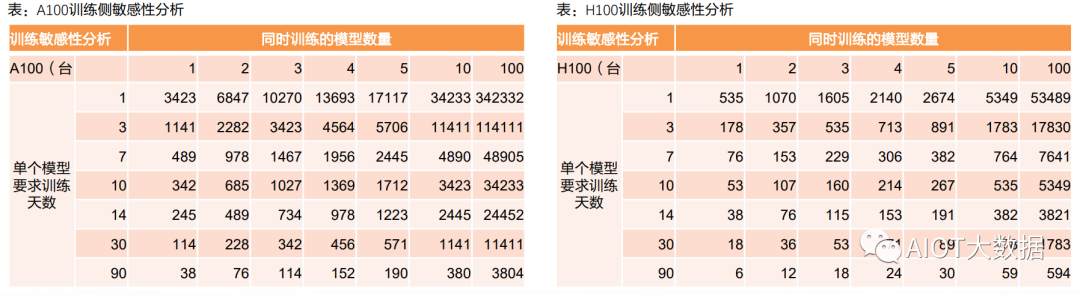
对AI服务器训练阶段需求进行敏感性分析,两个变化参数:①同时并行训练的大模型数量、②单个模型要求训练完 成的时间。
按照A100服务器5 PFLOPs,H100服务器32 PFLOPs来进行计算。
若不同厂商需要训练10个大模型,1天内完成,则需要A100服务器34233台,需要H100服务器5349台。
此外,若后续GPT模型参数迭代向上提升(GPT-4参数量可能对比GPT-3倍数级增长),则我们测算所需AI服务 器数量进一步增长。
AI服务器产业链
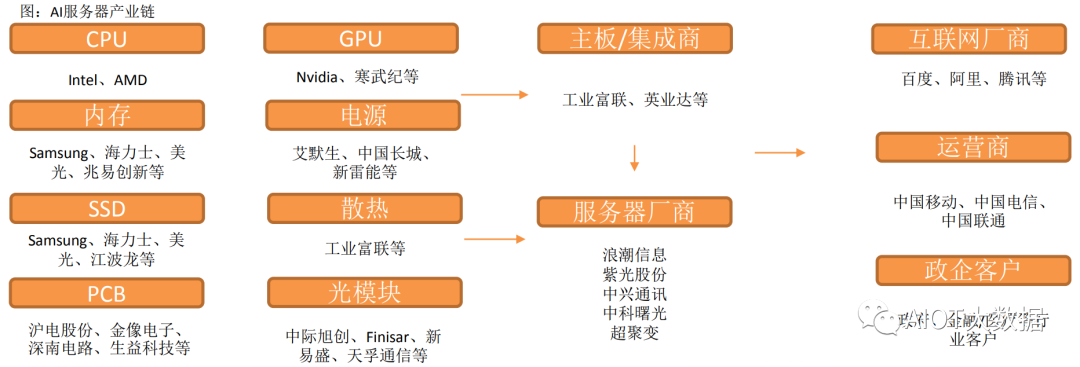
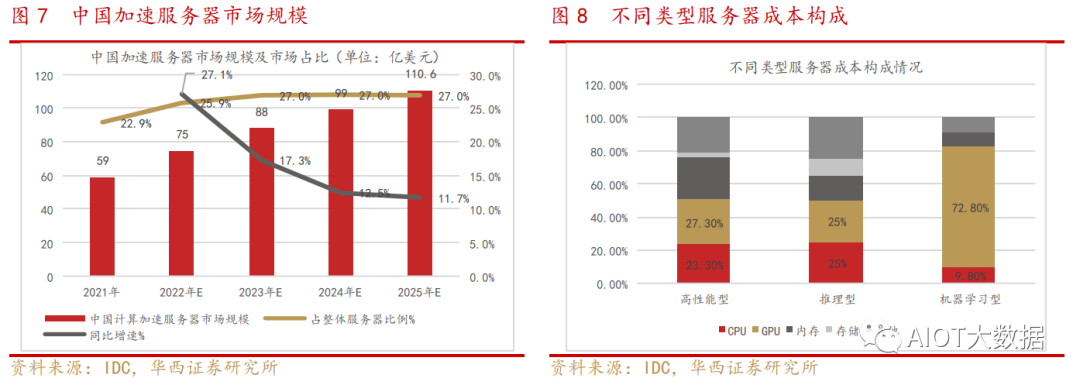
AI服务器核心组件包括GPU(图形处理器)、DRAM(动态随机存取存储器)、SSD(固态硬盘)和 RAID卡、CPU(中央处理器)、网卡、PCB、高速互联芯片(板内)和散热模组等。
CPU主要供货厂商为Intel、GPU目前领先厂商为国际巨头英伟达,以及国内厂商如寒武纪、海光信息等。
内存主要为三星、美光、海力士等厂商,国内包括兆易创新等。
SSD厂商包括三星、美光、海力士等,以及国内江波龙等厂商。
PCB厂商海外主要包括金像电子,国内包括沪电股份、鹏鼎控股等。
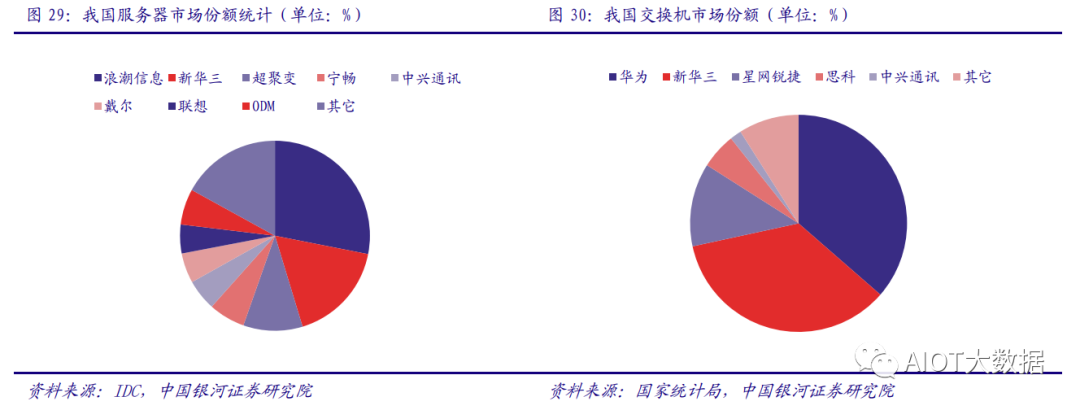
主板厂商包括工业富联,服务器品牌厂商包括浪潮信息、紫光股份、中科曙光、中兴通讯等。
审核编辑:黄飞
-
边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值2026-03-10 939
-
2015年智能照明市场及相关产业链发展趋势报告2015-01-15 6186
-
快速发展的物联网产业链2021-07-27 3997
-
地缘政治、产业链外迁,供应链安全对策2023-03-14 1213
-
算力网络产业链图谱2022-07-21 8208
-
美格高算力AI模组为SoC阵列式服务器提供澎湃算力2023-07-27 3787
-
认识一下AI算力应用中的光模块产品2023-12-29 2837
-
AI算力应用中的光模块产品2024-01-02 1592
-
AI服务器总体架构和关键技术2024-01-11 10177
-
鸿海强化北美AI服务器产能,深化产业链布局2024-05-23 1567
-
算力服务器为什么选择GPU2024-07-25 2676
-
RAKsmart服务器如何重塑AI高并发算力格局2025-04-03 1136
-
AI服务器PCBA加工技术解析:高算力时代的核心制造能力2026-04-16 280
-
必易微邀您相约2026世界AI服务器电源大会2026-05-09 257
-
聚焦绿色算力,共探电源革新 | 麦捷科技亮相2026世界AI服务器电源大会2026-05-23 620
全部0条评论

快来发表一下你的评论吧 !
