

NLP领域的语言偏置问题分析
描述
来自:南大NLP
01研究动机
许多研究证明,学术论文表达的nativeness会影响其被接受发表的可能性[1, 2]。先前的研究也揭示了非英语母语的作者在国际期刊发表论文时所经历的压力和焦虑。我们通过对自然语言处理(NLP)论文摘要进行全面的统计分析,发现不同语言背景的作者在写作中的词汇、形态、句法和连贯性方面有明显的差异,这表明NLP领域存在语言偏置的可能性。因此,我们提出了一系列建议,以帮助学术期刊和会议的出版社改进他们对论文作者的指南和资源,以增强学术研究的包容性和公平性。
02数据收集
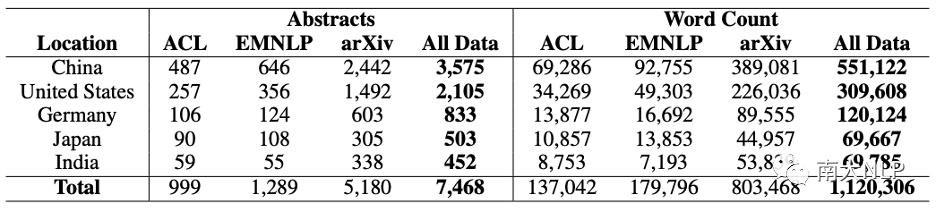
为了分析NLP领域的语言偏置,我们收集的论文摘要来自于ACL和EMNLP会议上发表的论文,以及arXiv.org的论文,标签为“Computation and Language”。本文研究中,我们假设第一作者是文章的撰写者。为了确定每篇文章的第一作者的国籍,我们设计了一些启发式方法。首先,我们通过提取电子邮件地址来确定作者所属机构的国籍。然后,我们使用一个姓名起源数据库来确定第一作者是否与该机构具有相同的国籍。在机构国籍未知或作者国籍与机构国籍不太可能相符的情况下,这些摘要将被丢弃。最后,为了确保有足够的数据进行分析,我们保留了数据集中摘要最多的五个国家的数据。这些国家分别是中国、美国、德国、日本和印度。数据集的统计信息见表1。
表1:数据集统计数据
03分析
我们的分析涵盖了词汇、形态、句法和连贯性等语言特性,这被认为是语法能力和文本能力的核心组成部分[3]。以下是对每种特性的分析和讨论。
3.1 词汇
我们从两个不同的层次分析不同国家使用的词汇特征。首先,我们通过计算类符行符比(token-type ratio)来研究词汇的多样性。其次,我们通过词汇束(lexical bundle)分析来探索多词级别的词汇,从中找出常用的词汇块。
3.1.1 词汇多样性
为了分析词汇多样性,我们计算每个文本的类符行符比(token-type ratio)。类符行符比通过将文本中独特词的数量除以总词数来计算。较高的比率表示更高的词汇多样性。统计结果如表2中所示。
表2: 平均类符行符比和词汇链长度
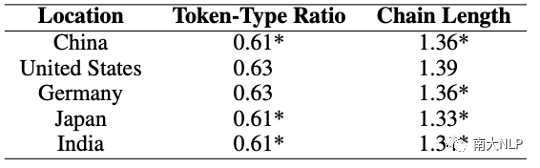
从结果中可以看到,与其他语料库相比,美国和德国的语料库有相对稍高的类符行符比(token-type ratio)。我们假设这是由于使用同义词、下义词和上义词的增加所导致的。为了验证这点,我们计算了词汇链的长度,其中每个链包含一个摘要中所有语义相关的词汇;这些词汇可以通过同义词、下义词或上义词来进行语义关联。所有名词的平均链长度展示在表2的右侧列中。可以看到,美国语料库中的平均词汇链长度是所有语料库中最长的,这意味着平均而言他们会使用更广泛的词汇来描述类似概念。相比之下,日本和印度的语料库具有最短的平均链长度,相对稍少的语义相关术语的使用是一个可能的因素。
3.1.2 词汇束
为了捕捉不同国家的作家如何使用词汇束,我们对四个词汇束的使用模式进行了分析。我们通过保留超过预定频率阈值和分散阈值的词汇束来确保每个语料库的代表性。表3展示了词汇束的频率(Bundles per Million Words)、独特词汇束的数量(Unique Bundles)和不同语法类别的词汇束数量。
表3:四个词汇束统计信息

从表3中可以看出,在不同的语料库之间,词汇束的频率存在很大的差异。例如,在中国、日本和印度的语料库中,词汇束的使用量是美国语料库的两倍以上,而美国语料库的使用量最少(Bundles per Million Words)。此外,还可以观察到非英语母语的语料库中使用的独特词汇束数量(Unique Bundles)比美国语料库更多。第二语言使用者使用词汇束的情况已经在文献中广泛研究过[4, 5, 6, 7],其中有一种假设是增加使用次数是因为作者依赖使用固定的词汇表达式以产生更符合学术要求的文本,并避免产生被视为非传统的表达方式[7]。
我们更深入地研究了词汇束在摘要中特定功能的使用,即引入论文主要思想的功能。该功能的规范化束计数如表4所示。
表4: 表达引入论文主要思想的词汇束频率(每百万词)
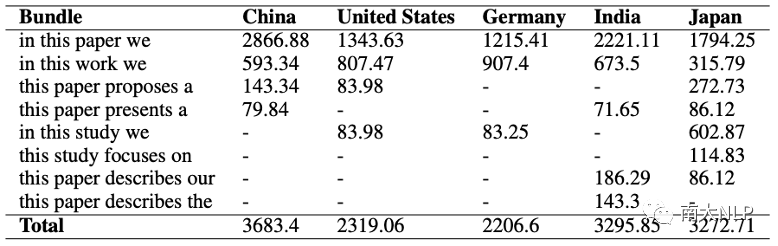
可以看到,在中国、印度和日本的语料库中,这个特定功能的词汇束使用率很高,使用频率比美国的语料库高出41%(日本语料库)到69%(中国语料库)。然而,我们注意到这三个语料库中的模式有所不同。例如,在中国语料库中,总体使用量较高似乎可以归因于一个特定词汇束的高使用率(in this paper we)。如果将其与日本语料库进行对比,我们可以看到尽管词汇束的总体使用仍然很高,但使用情况分布在更广泛的词汇束范围内,而不是一个单一的词汇束。
3.2 形态
为了分析形态学维度,我们调查了五个国家作家使用不同动词形式的分布情况。具体来说,对于每个语料库中的句子,我们确定主动词,并根据其是否是过去时态、过去分词、基本形式、第三人称现在时、非第三人称现在时或动名词来分类动词形式。分布结果如图1所示。
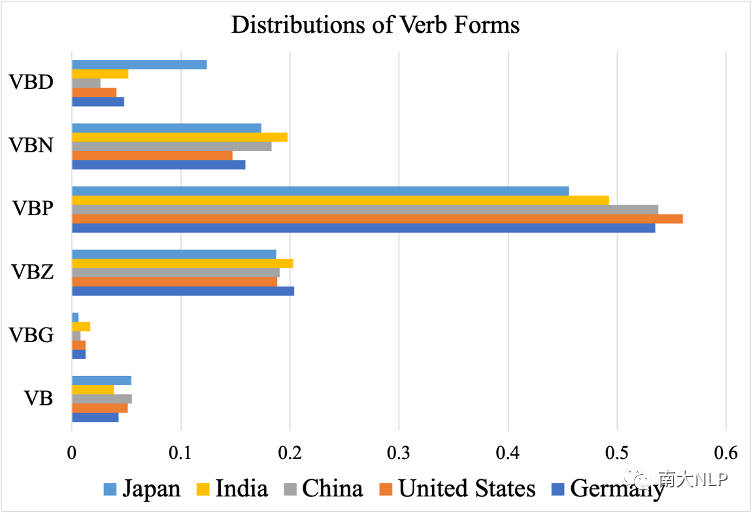
图 1:每个语料库中动词形式的分布
根据分析,我们发现这些分布在不同地点上相当一致。然而,还是存在一些例外情况。例如,对于过去时使用(VBD),日本语料库显示出这种动词形式的使用更频繁,超过12%的动词带有VBD标记。这比其他地点的使用频率高出两倍以上。相反地,非第三人称现在时(VBP)在日本语料库中使用相对较少,有45.5%的动词使用这种形式,而美国语料库中有56%的动词使用这种形式(这是最频繁的情况)。
3.3 句法
在句法分析中,我们探索短语级别、从句级别和句子级别的复杂性。为了做到这点,我们使用了多种测量方法:名词短语修饰语的平均数量、每个句子中的从句数量、平均解析树深度和平均句子长度。分析结果如表5所示。
表5:句法复杂度指标
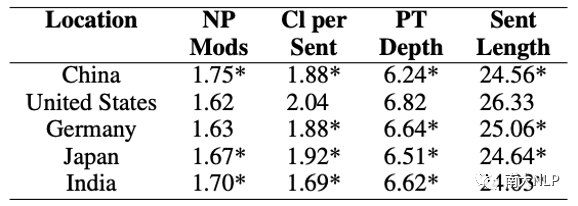
我们观察到在名词短语层面上,与数据集中的其他国家相比,美国和德国的语料库表现出较低的复杂性(即,较少使用名词短语修饰语)。然而,当我们观察从句和句子的层面时,来自美国和德国的文本比其他国家的写作表现出更高的复杂性。这一观察意味着在表达复杂思想方面可能存在一些不同的偏好,其中一种选择是通过更多的短语修饰语来表达复杂性,而另一种选择是将句子拆分成多个从句。
3.4 连贯性
与已有分析第二语言使用者写作连贯性的研究[8, 9, 10, 11]相似,我们比较了不同国家作者之间的语篇连接词的使用情况。为此,我们记录了所有来自[12]提供的语篇连接词清单中的连接词的使用。平均每个句子的语篇连接词数量如表6所示。
表6: 每个句子中平均的语篇连接词数量

如上所述,可以看出,美国和德国的文本中使用了更多的链接词。为了探究不同国家的链接词偏好,我们列出了与美国语料库相比每个语料库使用率最高的五个连词。结果如表7所示。
表7:与美国语料库相比,使用比例最高的五个语篇连接词
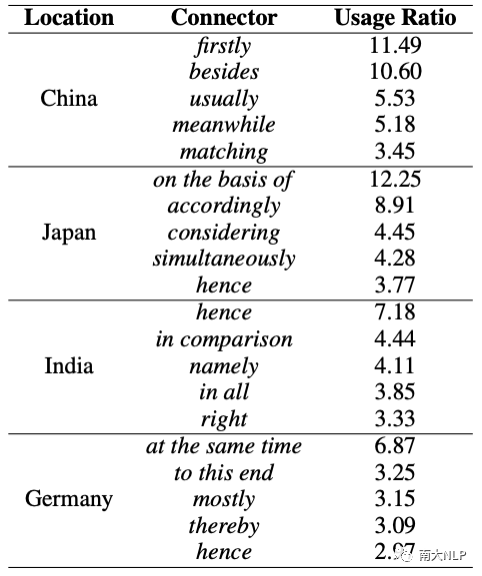
可以看出,每个语料库都有自己独特的语篇连接词集,在与整个数据集相比时更受偏爱。例如,在中国语料库中,firstly 是一种高度偏爱的连接词,比来自美国的作者使用频率高出11倍。同样,besides 也是中国作者高度偏爱的连接词,在中国语料库中的出现频率比美国语料库高出10倍以上。我们还注意到,德国、印度和日本语料库中对consequential(以结果为导向)连接词有偏好,其中hence、thereby和therefore的出现频率显著高于美国语料库(其中一些未在表中列出,因为它们仅略逊于前5位)。
04结论和推荐
在本文研究中,我们致力于解决学术出版中的语言偏置问题。我们对自然语言处理领域的学术写作进行了全面对比分析,发现了许多特征在来自不同国籍的作者之间存在很大差异。这些发现凸显了语言偏置的潜在风险。为了解决这个问题,我们概述了一套推荐措施,建议学术期刊和会议在他们的作者指南中如何支持来自全球各地的论文作者。我们的建议专注于本研究中四个语言特性。例如,在不同作者群体之间差异较大的语言方面,作者指南中可以添加详细的解释和示例。另外,我们鼓励出版商提供免费访问的自动写作工具,能够进行改写等功能。
审核编辑:汤梓红
-
nlp自然语言处理的主要任务及技术方法2024-07-09 3630
-
nlp自然语言处理的应用有哪些2024-07-05 5124
-
NLP技术在人工智能领域的重要性2024-07-04 2330
-
什么是自然语言处理 (NLP)2024-07-02 4271
-
人工智能nlp是什么方向2023-08-22 3472
-
NLP 2019 Highlights 给NLP从业者的一个参考2020-09-25 2692
-
自然语言处理(NLP)的学习方向2020-07-06 14303
-
【推荐体验】腾讯云自然语言处理2019-10-09 2943
-
Richard Socher:NLP领域的发展要过三座大山2018-09-06 4488
-
NLP的介绍和如何利用机器学习进行NLP以及三种NLP技术的详细介绍2018-06-10 79014
全部0条评论

快来发表一下你的评论吧 !
