

重铸AI云纪元:助力超大模型运行的GPU集群
人工智能
描述
集群资源以提高性能并非新鲜事。在集群技术的早期,Beowulf 项目就证明了商品硬件也可以实现高性能。如今,每当部署某种新技术时就会使用"Beowulf集群备忘录"。例如,“想象一个由Frontier系统组成的Beowulf集群。”有趣的是,GigalO和TensorWave最近的声明更接近现实。
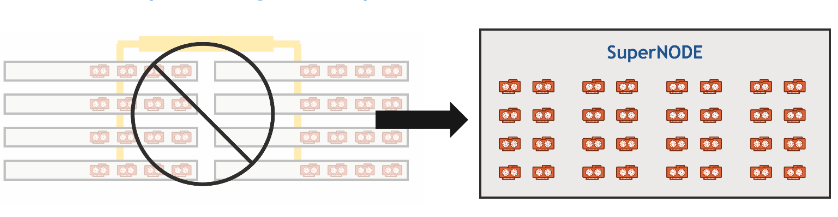
GigaIO 于今年 6 月推出了首款 32 GPU 单节点超级计算机 SuperNODE。SuperNode 在11月丹佛举行的 2023 年超级计算大会上赢得了两项令人垂涎的 HPCwire 编辑选择奖:最佳人工智能产品或技术奖和五大值得关注的新产品或技术奖。HPCwire 曾报道过 32 GPU GigaiO superNODE 和 64 GPU SuperDuperNODE 的性能。现在,GigaIO 和 TensorWave 似乎已经将“想象一个由这些 GPU 组成的Beowulf集群”铭记于心。
近日,GigaIO 宣布其旗舰产品 SuperNODE 获得了迄今为止最重要的订单,该产品最终将使用数万台 AMD Instinct MI300X 加速器,这些加速器也在AMD “Advanced AI” 活动上发布。GigaIO的新型基础设施将成为名为 “TensorNODE”的裸机专用人工智能云代码的骨干,该云将由云提供商TensorWave构建,用于访问AMD数据中心GPU,特别是用于大语言模型(LLM)。
正如GigaIO全球销售首席技术官Matt Demas在接受采访时所说:"我们利用我们的SuperNODE为TensorWave创建了一个大型集群。“每个 SuperNODE 都有两台额外的服务器,并可以访问整个 TensorNODE 的所有 GPU 内存。每个 TensorNODE 上还有大量可用的暂存磁盘。
TensorNODE 部署将以 GigaIO SuperNODE 架构为基础,规模更大,利用 GigaIO 的 PCIe Gen-5 内存结构,提供比传统网络更简单的工作负载设置和部署,并减少相关的性能消耗。
TensorWave 将利用 GigaIO 的 FabreX 创建首个 PB 级 GPU 内存池,而不会受到非内存中心网络的性能影响。TensorNODE 的第一批产品预计将于 2024 年初开始运行,其架构将在单个 FabreX 存储结构域上支持多达 5,760 个 GPU。由于所有 GPU 都可以访问域内所有其他 GPU 的 VRAM,因此可以实现超大模型。工作负载可以在任何节点的单个作业中访问超过 PB 的 VRAM,从而使最大型的作业也能在创纪录的时间内完成。在整个 2024 年,将部署多个 TensorNODE。
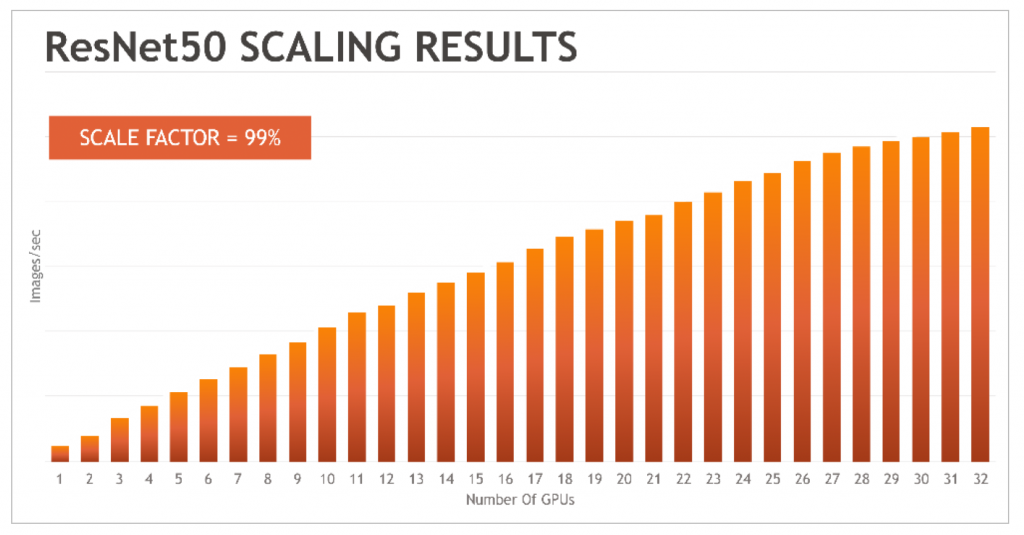
TensorNODE 是全 AMD 解决方案,采用第四代 AMD CPU 和 MI300X 加速器。MI300X 可为每个加速器提供 192GB 的 HBM3 内存,从而实现了 TensorNODE 的预期性能。这些加速器的内存容量与 GigaIO 的内存结构相结合,可在几乎不降低性能的情况下实现近乎完美的扩展,从而解决了分布式内存模型导致的 GPU 内核利用不足或闲置的难题。
TensorWave 首席执行官 Darrick Horton 表示:"TensorWave 很高兴能与 GigaIO 和 AMD 一起将这一创新解决方案推向市场。"我们之所以选择GigaIO平台,是因为它具有卓越的功能,而且GigaIO符合我们的价值观和对开放标准的承诺。我们正在利用这种新型基础设施来支持大规模人工智能工作负载,我们很荣幸能与 AMD 合作,成为首批部署 MI300X 加速器解决方案的云提供商之一。"
与标准的静态基础设施相比,GigaIO动态基础设施的可组合性为TensorWave提供了独特的灵活性和敏捷性;随着LLM和人工智能用户的需求不断发展,基础设施可以随时调整,以满足当前和未来的需求。此外,TensorWave 的云将比其他云更环保,因为它省去了 GPU 服务器主机(通常每台服务器 4-8 个 GPU)和相关网络设备,从而节省了成本、复杂性、空间、水和电力。
"通过将革命性的 AMD Instinct MI300X 加速器与 GigaIO 的人工智能基础架构(包括我们独特的内存结构 FabreX)相结合,我们很高兴能够为 TensorWave 的基础架构提供大规模支持。这次部署验证了我们重新构想数据中心基础设施的开创性方法,"GigaIO 首席执行官 Alan Benjamin 说。"TensorWave 团队在云计算方面具有远见卓识,在建立和部署非常复杂的加速数据中心方面具有深厚的专业知识。
考虑到 GenAI 模型对内存的需求,GigaIO 和 AMD 提供的巨大内存大小和带宽应该会使 TensorWave TensorNode 吸引许多正在云中构建和提供人工智能解决方案的客户。
审核编辑:黄飞
-
名单公布!【书籍评测活动NO.41】大模型时代的基础架构:大模型算力中心建设指南2024-08-16 4276
-
【「大模型时代的基础架构」阅读体验】+ 未知领域的感受2024-10-08 1170
-
无法在GPU上运行ONNX模型的Benchmark_app怎么解决?2025-03-06 577
-
适用于数据中心和AI时代的800G网络2025-03-25 2752
-
睿海光电以高效交付与广泛兼容助力AI数据中心800G光模块升级2025-08-13 748
-
【产品活动】阿里云GPU云服务器年付5折!阿里云异构计算助推行业发展!2017-12-26 3522
-
DGX SuperPOD助力助力织女模型的高效训练2022-04-13 1733
-
NVIDIA助力百度智能云落地新一代高性能AI计算集群2022-05-20 1955
-
AI大模型时代需要什么样的网络?2023-07-14 3520
-
完成适配!曦云C500在智谱AI升级版大模型上充分兼容、高效稳定运行2023-08-23 9963
-
GPU是如何训练AI大模型的2024-12-19 2042
-
搭建万卡GPU集群,小米AI大模型即将全力启动2024-12-29 4219
-
小米加速布局AI大模型,搭建GPU万卡集群2024-12-28 1112
全部0条评论

快来发表一下你的评论吧 !
