

如何在不微调的情况下提高RAG的准确性?
描述
数据科学家、AI 工程师、MLOps 工程师和 IT 基础设施专业人员在设计和部署检索增强生成(RAG)工作流时,必须考虑各项因素,比如大语言模型(LLM) 核心组件以及评估方法等等。
这是由于 RAG 是一个系统,而不仅仅是一个或一组模型。该系统由若干阶段组成,RAG 101:揭秘检索增强生成工作流一文对这些阶段进行了深入讨论。在这些阶段中,您都可以根据需求做出设计决策。
以下是一些常见问题与回答:
何时应微调 LLM?何时又该使用 RAG?
在 LLM 的世界里,您可以根据应用的具体需求和限制,为 LLM 选择微调、参数有效微调(PEFT)、提示工程或 RAG。
微调通过使用特定领域的数据集,更新模型大部分或全部参数,从而定制一个专门用于特定领域的预训练 LLM。这种方法需要耗费大量资源,但能为专门的用例提供很高的准确性。
PEFT 侧重于模型的一个子集,因此只需更新较少的参数就能修改预训练 LLM。该方法平衡了准确性与资源使用,在数据和计算需求可控的情况下,为提示工程提供改进。
提示工程在不改变模型参数的情况下,通过操纵 LLM 的输入来引导模型输出。这是一种最节省资源的方法,适用于数据和计算资源有限的应用。
RAG 利用外部数据库中的信息增强了 LLM 提示功能,它本质上是一种复杂的提示工程。
使用哪种技术并不是关键,实际上,这些技术可以串联使用。例如,可以将 PEFT 集成到 RAG 系统中,以进一步完善 LLM 或嵌入模型。使用哪种方法最好取决于应用的具体要求,同时还要兼顾准确性、资源可用性和计算限制。
如要进一步了解用于提高特定领域准确性的自定义技术,请参阅选择大语言模型自定义技术:https://developer.nvidia.com/blog/selecting-large-language-model-customization-techniques/
使用 LLM 构建应用程序时,首先要使用 RAG,借助外部信息提升模型的响应性。这种方法可以快速提高相关性和深度。
之后,如果您需要提高特定领域的准确性,可以采用前面所述的模型自定义技术。该流程分为两步,既能够借助 RAG 进行快速部署和通过模型定制实现有针对性的改进,又兼顾了高效开发和持续改进策略。
如何在不微调的情况下提高 RAG 的准确性?
简而言之,在利用 RAG 的企业解决方案中,获得准确性是至关重要的,而微调只是一种可能提高 RAG 系统准确性的技术,反之亦然。
首先,也是最重要的一点,是找到一种衡量 RAG 准确性的方法。在起点都不清楚的情况下,改进又从何谈起?目前有几个评估 RAG 系统的框架,如 Ragas、ARES 和 Bench 等。
在对准确性进行评估后,就可以在无需进行微调的情况下,通过多种途径来提高准确性。
虽然这听起来很麻烦,但首先要检查并确保您的数据被正确解析和加载。例如,当文档包含表格甚至图像时,某些数据加载器可能会遗漏文档中的信息。
在摄取数据后,要对其进行分块,也就是将文本分割成片段的过程。分块可以是固定长度的字符,但也有许多种其他的分块方法,如句子分割和递归分块等。文本的分块方式决定了如何将其存储在嵌入向量中以便检索。
除此之外,还有许多索引和相关检索模式。例如,可以为不同类型的用户问题构建多个索引、可以根据 LLM 将用户查询引导至相应的索引等。
检索策略也是多种多样的。最基本的策略是利用索引的余弦相似性,BM25、自定义检索器或知识图也可以用来提高检索效率。
根据特殊要求,对检索结果进行重新排序也可以提高灵活性和准确性。查询转换可以很好地分解更加复杂的问题。即使只是改变 LLM 的系统提示,也能极大地提高准确性。
归根结底,重要的是要花时间进行试验,并衡量各种方法所产生的准确性变化。
像 LLM 或嵌入模型这样的模型只是 RAG 系统的一部分。有很多方法可以在不需要进行任何微调的情况下改进 RAG 系统,使其达到更高的准确性。
如何将 LLM 连接到数据源?
有多种框架可以将 LLM 连接到数据源,如 LangChain 和 LlamaIndex 等。这些框架提供评估程序库、文档加载器、查询方法等各种功能,新的解决方案也层出不穷。建议您先了解各种框架,然后选择最适合您应用的软件和软件组件。
RAG 能否列出检索数据的来源?
可以。列出检索数据的来源能够改善用户体验。在 GitHub 资源库中的 /NVIDIA/GenerativeAIExamples 的 AI 聊天机器人 RAG 工作流示例中
RAG 需要哪类数据?如何确保数据安全?
目前,RAG 支持文本数据。随着多模态用例研究的深入,RAG 系统对图像和表格等其他形式数据的支持也在不断改进。您可能需要根据数据及其位置编写额外的数据预处理工具。LlamaHub 和 LangChain 提供了多种数据加载器。如要进一步了解如何使用链构建强化管线,请参阅保护 LLM 系统不受提示注入的影响:https://developer.nvidia.com/zh-cn/blog/securing-llm-systems-against-prompt-injection/
确保数据安全对企业来说是至关重要的。例如,某些索引数据可能只针对特定用户。基于角色的访问控制(Role-based access control, RBAC)可以根据角色来限制对系统的访问,从而实现数据访问控制。比如,在向矢量数据库发出请求时,可以使用用户会话 token,这样就不会返回超出该用户权限范围的信息。
许多用于保护环境中模型的术语,与用于保护数据库或其他关键资产的术语相同。您需要考虑您的系统将如何记录生产管线产生的活动(提示输入、输出和错误结果)。虽然这些活动可以为产品的训练和改进提供丰富的数据集,但它们同时也是 PII 等数据泄漏的来源,因此必须像管理模型管线本身一样谨慎管理。
人工智能模型有许多常见的云部署模式。您应该充分利用 RBAC、速率限制等工具以及此类环境中常见的其他控制措施,来提高 AI 部署的稳健性。模型只是这些强大管线中的一个元素。
与终端用户的交互性质是所有 LLM 部署的工作重点之一。RAG 管线大部分都围绕自然语言输入和输出。您应该考虑如何通过输入/输出调节来确保体验符合一致的期望。
人们可能会用多种不同方式提问。您可以通过 NeMo Guardrails 等工具助 LLM “一臂之力”,这些工具可以对输入和输出进行二次检查,以确保系统处于最佳运行状态、解决系统所要解决的问题,并引导用户到其他地方解决 LLM 应用无法处理的问题。
如何加速 RAG 管线?
数据预处理
数据去重是识别并删除重复数据的过程。在对 RAG 数据进行预处理时,可以使用数据去重,减少为检索而必须建立索引的相同文档数量。
NVIDIA NeMo Data Curator 使用 NVIDIA GPU,通过并行执行最小哈希算法、Jaccard 相似性计算和连接组件分析来加速数据去重,可以大大减少数据去重所需的时间。
另一个方法是分块。由于下游嵌入模型只能对低于最大长度的句子进行编码,因此必须将大型文本语料库分成更小、更易于管理的语块。流行的嵌入模型(如 OpenAI)最多可以编码 1,536 个词元。如果文本的词元超过这个数量,就会被截断。
NVIDIA cuDF 可通过在 GPU 上执行并行数据帧操作来加速分块处理,可以大大减少对大型语料库进行分块处理所需的时间。
最后,您可以在 GPU 上加速分词器,分词器负责将文本转换成整数词元供嵌入模型使用。文本分词过程的计算成本很高,对于大型数据集来说尤其如此。
索引和检索
RAG 非常适合经常更新的知识库,经常需要重复生成嵌入。检索是在推理时进行,因此要求实现低延迟。NVIDIA NeMo Retriever 可以加速这些流程。NeMo Retriever 用于提供最先进的商用模型和微服务,这些模型和微服务专为实现最低延迟和最高吞吐量而优化。
LLM 推理
LLM 至少可用于生成完全成型的回答,还可用于查询分解和路由选择等任务。
由于需要多次调用 LLM,低延迟对于 LLM 至关重要。NVIDIA NeMo 包含用于模型部署的 TensorRT-LLM,可优化 LLM 以实现突破性的推理加速和 GPU 效率。
NVIDIA Triton 推理服务器也可以部署经过优化的 LLM,以实现高性能、高成本效益和低延迟的推理。
有哪些办法可以改善聊天机器人的延迟?
除了建议使用 Triton 推理服务器和 TensorRT-LLM 来加速 RAG 管线(如 NeMo 检索器和 NeMo 推理容器等)外,您还可以考虑使用流式传输来改善聊天机器人的感知延迟。响应可能用时很久,流式传输用户界面可先显示部分已准备好的内容,减少可感知的延迟。
也可以考虑针对您的用例使用经过微调的较小 LLM。通常情况下,较小的 LLM 的延迟远低于较大的 LLM。
一些经过微调的 7B 模型在特定任务(如 SQL 生成)上的准确性已经超过了 GPT-4。例如,ChipNeMo 是 NVIDIA 为帮助公司内部工程师生成和优化芯片设计软件而定制的 LLM,该模型使用的就是 13B 微调模型,而不是 70B 参数模型。TensorRT-LLM 提供的闪存、FlashAttention、PagedAttention、蒸馏和量化等模型优化功能适合在本地运行规模较小的微调模型,这些模型可减少 LLM 所使用的内存。
LLM 的响应延迟取决于首个词元的生成时间(TTFT)和单个输出词元的生成时间(TPOT)。
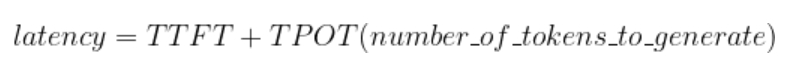
对于较小的 LLM 来说,TTFT 和 TPOT 都会比较低。
开始在您的企业中构建 RAG
通过使用 RAG,您可以轻松地为 LLM 提供最新的专有信息,并构建一个能够提高用户信任度、改善用户体验和减少幻觉问题的系统。
审核编辑:刘清
-
名单公布!【书籍评测活动NO.52】基于大模型的RAG应用开发与优化2024-12-04 6706
-
【「基于大模型的RAG应用开发与优化」阅读体验】+Embedding技术解读2025-01-17 2854
-
系统快速性、稳定性和准确性之间的权衡2013-07-28 7409
-
如何提高工程预算的准确性2016-07-25 2829
-
合同智能审核软件-提高审查效率和准确性2019-09-05 6069
-
如何提高交流脉冲对HPMMM充磁和去磁时磁场定向的准确性?2021-11-19 1726
-
在ADC输入内阻不配情况下提高ADC准确度方法2023-10-19 548
-
如何提高投标报价编制的准确性2010-01-08 852
-
AI可提高天气预报的准确性和准确性,助力农民和可再生能源行业2020-09-30 3593
-
如何在没有Arduino情况下制作机器人2022-12-05 600
-
如何在不构建专用硬件的情况下制作充电宝原型2023-07-10 1354
-
如何在电压不稳的情况下保障SSD的稳定性能?2023-11-24 1706
-
在不牺牲尺寸的情况下提高脉搏血氧仪溶液的性能2024-09-21 462
-
如何提高电位测量准确性2024-12-28 1867
-
如何提高OTDR测试的准确性2024-12-31 2528
全部0条评论

快来发表一下你的评论吧 !
