

什么是LlamaIndex?LlamaIndex数据框架的特点和功能
描述
来源:Coggle数据科学
什么是LlamaIndex ?
LlamaIndex是一个数据框架,用于让基于LLM的应用程序摄取、结构化和访问私有或领域特定的数据。它提供Python和Typescript版本。
LLMs提供了人类和数据之间的自然语言接口。广泛可用的模型预先训练了大量公开可用的数据,如维基百科、邮件列表、教科书、源代码等。然而,虽然LLMs在大量数据上进行了训练,但它们没有接触您的数据,这可能是私有的或与您要解决的问题特定相关的数据。它可能存在于APIs、SQL数据库中,或者被困在PDF和幻灯片中。
LlamaIndex特点
LlamaIndex采用了一种称为检索增强生成(RAG)的不同方法。与要求LLMs立即生成答案不同,LlamaIndex:
先从您的数据源中检索信息,
将其添加到您的问题作为上下文,
要求LLMs基于丰富的提示进行回答。
RAG克服了微调方法的所有三个缺点:
由于不涉及训练,因此它是便宜的。
仅在您要求时才检索数据,因此它始终保持最新。
LlamaIndex可以向您展示检索到的文档,因此它更可信。
LlamaIndex对您如何使用LLMs没有限制。您仍然可以将LLMs用作自动完成、聊天机器人、半自主代理等(请参见左侧的用例)。它只是使LLMs对您更有相关性。
LlamaIndex功能
LlamaIndex提供以下工具:
数据连接器从其原生来源和格式摄取您的现有数据。这可以是APIs、PDF、SQL等等。
数据索引将您的数据结构化为中间表示,LLMs可以轻松高效地使用。
引擎为您的数据提供自然语言访问。例如:
查询引擎是用于知识增强输出的强大检索接口。
聊天引擎是用于与数据进行多消息、“来回”交互的对话接口。
数据代理是由工具增强的LLM驱动的知识工作者,从简单的辅助功能到API集成等等。
应用集成将LlamaIndex与您的生态系统的其余部分相连接。这可以是LangChain、Flask、Docker、ChatGPT或… 其他任何东西!
LlamaIndex安装
pip install llama-index
安装通常所需的可选依赖项的方法。目前,这些依赖项分为三组:
pip install llama-index[local_models] 安装对私有LLMs、本地推理和HuggingFace模型有用的工具
pip install llama-index[postgres] 如果您正在使用Postgres、PGVector或Supabase,则此选项很有用
pip install llama-index[query_tools] 为您提供混合搜索、结构化输出和节点后处理的工具
检索增强生成(RAG)
LLMs在庞大的数据集上进行训练,但它们并没有接触您的数据。检索增强生成(RAG)通过将您的数据添加到LLMs已经可以访问的数据中来解决这个问题。在本文档中,您将经常看到对RAG的引用。
在RAG中,您的数据被加载并准备进行查询或“索引”。用户的查询作用于索引,将您的数据筛选到最相关的上下文。然后,此上下文和您的查询与LLM一起传递给一个提示,LLM将提供响应。
即使您正在构建的是一个聊天机器人或代理,您也会想要了解RAG技术,以将数据引入您的应用程序。
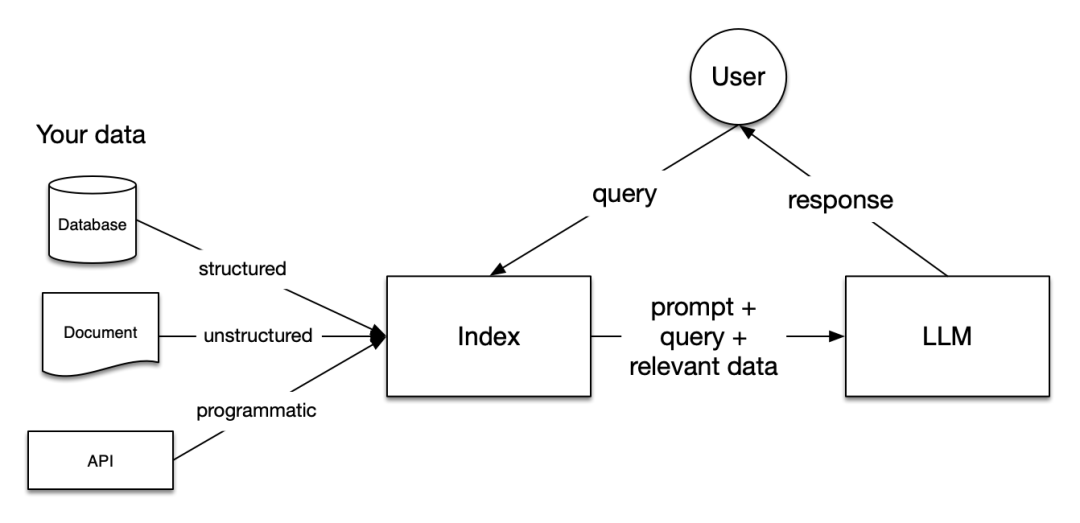
RAG中的阶段
RAG中有五个关键阶段,这些阶段将成为您构建的任何更大应用程序的一部分。这些阶段是:
加载:这指的是从数据所在的地方(无论是文本文件、PDF、另一个网站、数据库还是API)获取您的数据,将其引入您的管道。LlamaHub 提供了数百个可供选择的连接器。
索引:这意味着创建一个允许查询数据的数据结构。对于LLMs,这几乎总是意味着生成矢量嵌入,这是您的数据意义的数字表示,以及许多其他元数据策略,使其易于准确找到上下文相关的数据。
存储:一旦您的数据被索引,您几乎总是希望存储您的索引,以及其他元数据,以避免必须重新索引它。
查询:对于任何给定的索引策略,您可以使用LLMs和LlamaIndex数据结构以多种方式进行查询,包括子查询、多步查询和混合策略。
评估:在任何管道中,检查其相对于其他策略或在进行更改时的有效性是一个关键步骤。评估提供了有关您对查询的响应的准确性、忠实度和速度的客观度量。

每个步骤中的重要概念
在每个阶段中,您还会遇到一些涉及到这些阶段的术语。
加载阶段
节点和文档:一个文档是围绕任何数据源的容器,例如PDF、API输出或从数据库检索的数据。节点是LlamaIndex中数据的原子单位,表示源文档的“块”。节点具有将其与所在文档和其他节点相关联的元数据。
连接器:数据连接器(通常称为读取器)从不同的数据源和数据格式中摄取数据到文档和节点中。
索引阶段
索引:一旦摄取了您的数据,LlamaIndex将帮助您将数据索引到易于检索的结构中。这通常涉及生成矢量嵌入,这些嵌入存储在一个称为矢量存储的专用数据库中。索引还可以存储有关您的数据的各种元数据。
嵌入:LLMs生成称为嵌入的数据的数字表示。在为相关性过滤数据时,LlamaIndex将查询转换为嵌入,并且您的矢量存储将找到数值上与查询嵌入相似的数据。
查询阶段
检索器:检索器定义了在给定查询时如何有效地从索引中检索相关上下文。您的检索策略对于检索的数据的相关性以及执行此操作的效率至关重要。
路由器:路由器确定将使用哪个检索器从知识库中检索相关上下文。更具体地说,RouterRetriever类负责选择一个或多个候选检索器来执行查询。它们使用选择器根据每个候选的元数据和查询选择最佳选项。
节点后处理器:节点后处理器接收一组检索到的节点并对其应用变换、过滤或重新排序逻辑。
响应合成器:响应合成器使用用户查询和一组检索到的文本块从LLM生成响应。
将所有内容整合在一起
有无数数据支持的LLM应用程序的用例,但它们大致可以分为三类:
查询引擎:查询引擎是一个端到端的管道,允许您在数据上提问。它接收自然语言查询,并返回一个响应,以及检索到的并传递给LLM的参考上下文。
聊天引擎:聊天引擎是一个端到端的管道,用于与您的数据进行对话(而不是单一的问答)。
代理:代理是由LLM驱动的自动决策者,通过一组工具与世界互动。代理可以采取任意数量的步骤来完成给定任务,动态决定最佳行动方案,而不是按照预先确定的步骤进行。这使得它具有处理更复杂任务的额外灵活性。
审核编辑:汤梓红
-
利用OpenVINO和LlamaIndex工具构建多模态RAG应用2025-02-21 3782
-
使用 llm-agent-rag-llamaindex 笔记本时收到的 NPU 错误怎么解决?2025-06-23 556
-
多功能程序框架2016-05-13 2749
-
主流web前端技术框架2018-03-28 3325
-
power_supply框架包括哪些功能?2021-07-28 1779
-
WCDB移动数据框架的功能2017-09-25 980
-
基于功能体验ios新增了SiriKit框架2017-09-26 1130
-
SHARC音频模块:裸机框架源代码的结构及功能2019-06-27 4283
-
AD7616产品数据手册及功能框架图2021-11-09 2119
-
DB4494_无线工业节点上的多传感器AI数据监控框架,STM32Cube的功能包2022-11-23 618
-
LlamaIndex:面向QA系统的全新文档摘要索引2023-05-12 2299
-
fastapi框架原理及应用2023-07-18 1625
-
使用OpenVINO和LlamaIndex构建Agentic-RAG系统2024-10-12 2050
-
LlamaIndex高级索引系统优化策略2026-06-24 208
全部0条评论

快来发表一下你的评论吧 !
