

如何写出好的代码?高质量代码的三要素
描述
脍炙人口的诗"春有百花秋有月,夏有凉风冬有雪",意境唯美,简明易懂。好的代码也是让人陶醉的,那么如何写出好的代码?
高质量代码有三要素:可读性、可维护性、可变更性。我们的代码要一个都不能少地达到了这三要素的要求才能算高质量的代码。
代码可读性的重要性
一提到可读性似乎有一些老生常谈的味道,虽然大家一而再,再而三地强调可读性,但我们的代码在可读性方面依然做得非常糟糕。由于工作的需要,常常需要去阅读他人的代码,维护他人设计的模块。
很多同行在编写代码的时候往往只关注一些宏观上的主题:架构,设计模式,数据结构等等,却忽视了一些更细节上的点:比如变量如何命名与使用,控制流的设计,以及注释的写法等等。以上这些细节上的东西可以用代码的可读性来概括。每当看到大段大段、密密麻麻的代码,而且还没有任何的注释时常常感慨不已,深深体会到了这项工作的重要。
由于分工的需要,我们写的代码难免需要别人去阅读和维护的。而对于许多程序员来说,阅读和维护别人的代码常有的事,而往往在平常很少关注代码的可读性,也对如何提高代码的可读性缺乏切身体会。有时即使为代码编写了注释,也常常是注释语言晦涩难懂形同天书,令阅读者反复斟酌依然不明其意。
对于一个整体的软件系统而言,既需要宏观上的架构决策,设计与指导原则,也必须重视微观上的代码细节。在过往中,有许多影响深远的重大失败,其根源往往是编码细节出现了疏漏。
不同于宏观上的架构,设计模式等需要好几个类,好几个模块才能看出来:代码的可读性是能够立刻从微观上的,一个变量的命名,函数的逻辑划分,注释的信息质量里面看出来的。
宏观层面上的东西固然重要,但是代码的可读性也属于评价代码质量的一个无法让人忽视的指标:它影响了阅读代码的成本(毕竟代码是给人看的),甚至会影响代码出错的概率!
对于一个整体的软件系统而言,既需要宏观上的架构决策,设计与指导原则,也必须重视微观上的代码细节。在软件历史中,有许多影响深远的重大失败,其根源往往是编码细节出现了疏漏。所以代码的可读性可以作为考量一名程序员专业程度的指标。
怎么理解代码可读性
或许已经有很多同行也正在努力提高自己代码的可读性。然而这里有一个很典型的错觉是:越少的代码越容易让人理解。
但是事实上,并不是代码越精简就越容易让人理解。相对于追求最小化代码行数,一个更好的提高可读性方法是最小化人们理解代码所需要的时间。
这就引出了这本中的一个核心定理:
可读性基本定理:代码的写法应当使别人理解它所需要的时间最小化。
相对于追求最小化代码行数,更好的提高可读性方法是:最小化人们理解代码所需要的时间。具体如何让代码易于理解?主要体现在下面三个层次:
表层上的改进:在命名方法(变量名,方法名),变量声明,代码格式,注释等方面的改进。控制流和逻辑的改进:在控制流,逻辑表达式上让代码变得更容易理解。结构上的改进:善于抽取逻辑,借助自然语言的描述来改善代码。
表层的改进
首先来讲最简单的一层如何改进,涉及到以下几点:
1.如何命名
我们在命名变量、函数、属性、类以及包的时候,应当仔细想想,使名称更加符合相应的功能。我们常常在说,设计一个系统时应当有一个或多个系统分析师对整个系统的包、类以及相关的函数和属性进行规划,但在通常的项目中这都非常难于做到。对它们的命名更多的还是程序员来完成。但是,在一个项目开始的时候,应当对项目的命名出台一个规范。譬如,在我的项目中规定,新增记录用new或add开头,更新记录用edit或mod开头,删除用del开头,查询用find或query开头。使用最乱的就是get,因此get开头的函数仅仅用于获取类属性。
关键思想:把尽可能多的信息装入名字中。
1.选择专业的词汇,避免泛泛的名字
2.给名字附带更多信息
3.决定名字最适合的长度
4.名字不能引起歧义
选择专业的词汇,避免泛泛的名字
比如get、query等词最好是用来做轻量级地取方法的开头,严禁使用拼音和英文混合的方式,更不允许直接使用中文的方式。
举个例子:
getPage(url)
通过这个方法名很难判断出这个方法是从缓存中获取页面数据还是从网页中获取。如果是从网页中获取,更专业的词应该是fetchPage(url)或者downloadPage(url)。
还有一个比较常见的反例:returnValue和retval。这两者都是“返回值”的意思,他们被滥用在各个有返回值的函数里面。其实这两个次除了携带他们本来的意思返回值以外并不具备任何其他的信息,是典型的泛泛的名字。
那么如何选择一个专业的词汇呢?答案是在非常贴近你自己的意图的基础上,选择一个富有表现力的词汇。
举几个例子:
相对于make,选择create,generate,build等词汇会更有表现力,更加专业。
相对于find,选择search,extract,recover等词汇会更有表现力,更加专业。
相对于retval,选择一个能充分描述这个返回值的性质的名字,例如:
var euclidean_norm = function (v){
var retval = 0.0;
for (var i = 0; i < v.length; i += 1;)
retval += v[i] * v[i];
return Match.sqrt(retval);
}
这里的retval表示的是“平方的和”,因此sum_squares这个词更加贴切你的意图,更加专业。
但是,有些情况下,泛泛的名字也是有意义的,例如一个交换变量的情景:
if (right < left){
tmp = right;
right = left;
left = tmp;
}
像上面这种tmp只是作为一个临时存储的情况下,tmp表达的意思就比较贴切了。因此,像tmp这个名字,只适用于短期存在而且特性为临时性的变量。
给名字附带更多信息
除了选择一个专业,贴切意图的词汇,我们也可以通过添加一些前后缀来给这个词附带更多的信息。这里所指的更多的信息有三种:变量的单位、变量的属性、变量的格式。
为变量添加单位
有些变量是有单位的,在变量名的后面添加其单位可以让这个变量名携带更多信息:
一个表达时间间隔的变量,它的单位是秒:相对于duraction,ducation_secs携带了更多的信息 一个表达内存大小的变量,它的单位是mb:相对于size,cache_mb携带了更多的信息。
为变量添加重要属性
有些变量是具有一些非常重要的属性,其重要程度是不允许使用者忽略的。例如:
一个UTF-8格式的html字节,相对于html,html_utf8更加清楚地描述了这个变量的格式。一个纯文本,需要加密的密码字符串:相对于password,plaintext_password更清楚地描述了这个变量的特点。
为变量选择适当的格式
对于命名,有些既定的格式需要注意:
使用大驼峰命名来表示类名:HomeViewController。
使用小驼峰命名来表示属性名:userNameLabel。
使用下划线连接词来表示变量名:product_id。
使用kConstantName来表示常量:kCacheDuraction。
使用MACRO_NAME来表示宏:SCREEN_WIDTH。
决定名字最适合的长度
名字越长越难记住,名字越短所持有的信息就越少,如何决定名字的长度呢?总结有几个原则:
1.如果变量的作用域很小,可以取很短的名字
2.驼峰命名中的单元不能超过3个
3.不能使用大家不熟悉的缩写
4.丢掉不必要的单元
如果变量的作用域很小,可以取很短的名字
如果一个变量作用域很小:则可以给它取一个很短的名字也无妨。
看下面这个例子:
if(debug){
map m;
LookUpNamesNumbers(&m);
Print(m);
}
在这里,变量的类型和使用范围一眼可见,读者可以了解这段代码的所有信息,所以即使是取m这个非常简短的名字,也不影响读者来理解作者的意图。
相反的,如果m是一个全局变量,当你看到下面这段代码就会很头疼,因为你不知道它的类型并不明确:
LookUpNamesNumbers(&m); Print(m);
驼峰命名中的单元不能超过3个
我们知道驼峰命名可以很清晰地体现变量的含义,但是当驼峰命名中的单元超过了3个之后,就会很影响阅读体验:
userFriendsInfoModel
memoryCacheCalculateTool
是不是看上去很吃力?因为我们大脑同时可以记住的信息非常有限,尤其是在看代码的时候,这种短期记忆的局限性是无法让我们同时记住或者瞬间理解几个具有3~4个单元的变量名的。所以我们需要在变量名里面去除一些不必要的单元:
丢掉不必要的单元
有些单元在变量里面是可以去掉的,例如:
convertToString可以省略成toString。
不能使用大家不熟悉的缩写
有些缩写是大家熟知的:
doc 可以代替document
str 可以代替string
但是如果你想用BEManager来代替BackEndManager就比较不合适了。因为不了解的人几乎是无法猜到这个名称的意义的。
所以类似这种情况不能偷懒,该是什么就是什么,否则会起到相反的效果。因为它看起来非常陌生,跟我们熟知的一些缩写规则相去甚远。
名字不能引起歧义
名字要表达意思明确,不能让人看不懂。
例如:
filter:过滤这个词,可以是过滤出符合标准的,也可以是减少不符合标准的:是两种完全相反的结果,所以不推荐使用。
clip:类似的,到底是在原来的基础上截掉某一段还是另外截出来某一段呢?同样也不推荐使用。
布尔值:read_password:是表达需要读取密码,还是已经读了密码呢?所以最好使用need_password或者is_authenticated来代替比较好。通常来说,给布尔值的变量加上is,has,can,should这样的词可以使布尔值表达的意思更加明确
2.如何声明与使用变量
开发过程中我们会声明很多变量(成员变量,临时变量),而我们要知道变量的声明与使用策略是会对代码的可读性造成影响的:
1.变量越多,越难跟踪它们的动向。
2.变量的作用域越大,就需要跟踪它们的动向越久。
3.变量改变的越频繁,就越难跟踪它的当前值。
相对的,对于变量的声明与使用,我们可以从这四个角度来提高代码的可读性:
1.减少变量的个数
2.缩小变量的作用域
缩短变量声明与使用其代码的距离
变量最好只写一次
没有价值的临时变量
有些变量的声明完全是多此一举,它们的存在反而加大了阅读代码的成本:
let now = datetime.datatime.now() root_message.last_view_time = now
上面这个now变量的存在是毫无意义的,因为:
没有拆分任何复杂的表达式
datetime.datatime.now已经很清楚地表达了意思
只使用了一次,因此而没有压缩任何冗余的代码
所以完全不用这个变量也是完全可以的:
root_message.last_view_time = datetime.datatime.now()
表示中间结果的变量
有的时候为了达成一个目标,把一件事情分成了两件事情来做,这两件事情中间需要一个变量来传递结果。但往往这件事情不需要分成两件事情来做,这个“中间结果”也就不需要了:
看一个比较常见的需求,一个把数组中的某个值移除的例子:
var remove_value = function (array, value_to_remove){
var index_to_remove = null;
for (var i = 0; i < array.length; i+=1){
if (array[i] === value_to_remove){
index_to_remove = i;
break;
}
}
if (index_to_remove !== null){
array.splice(index_to_remove,1);
}
}
这里面把这个事情分成了两件事情来做:
找出要删除的元素的序号,保存在变量index_to_remove里面。
拿到index_to_remove以后使用splice方法删除它。(这段代码是JavaScript代码)
这个例子对于变量的命名还是比较合格的,但实际上这里所使用的中间结果变量是完全不需要的,整个过程也不需要分两个步骤进行。来看一下如何一步实现这个需求:
var remove_value = function (array, value_to_remove){
for (var i = 0; i < array.length; i+=1){
if (array[i] === value_to_remove){
array.splice(i,1);
return;
}
}
}
上面的方法里面,当知道应该删除的元素的序号i的时候,就直接用它来删除了应该删除的元素并立即返回。
除了减轻了内存和处理器的负担(因为不需要开辟新的内容来存储结果变量以及可能不用完全走遍整个的for语句),阅读代码的人也会很快领会代码的意图。
所以在写代码的时候,如果可以“速战速决”,就尽量使用最快,最简洁的方式来实现目的。
缩小变量的作用域
变量的作用域越广,就越难追踪它,值也越难控制,所以我们应该让你的变量对尽量少的代码可见。
比如类的成员变量就相当于一个“小型局部变量”。如果这个类比较庞大,我们就会很难追踪它,因为所有方法都可以“隐式”调用它。所以相反地,如果我们可以把它“降格”为局部变量,就会很容易追踪它的行踪:
//成员变量,比较难追踪
class LargeCass{
string str_;
void Method1(){
str_ = ...;
Method2();
}
void Method2(){
//using str_
}
}
降格:
//局部变量,容易追踪
class LargeCass{
void Method1(){
string str = ...;
Method2(str);
}
void Method2(string str){
//using str
}
}
所以在设计类的时候如果这个数据(变量)可以通过方法参数来传递,就不要以成员变量来保存它。
缩短变量声明与使用其代码的距离
在实现一个函数的时候,我们可能会声明比较多的变量,但这些变量的使用位置却不都是在函数开头。
有一个比较不好的习惯就是无论变量在当前函数的哪个位置使用,都在一开始(函数的开头)就声明了它们。这样可能导致的问题是:阅读代码的人读到函数后半部分的时候就忘记了这个变量的类型和初始值;而且因为在函数的开头就声明了好几个变量,也对阅读代码的人的大脑造成了负担,因为人的短期记忆是有限的,特别是记一些暂时还不知道怎么用的东西。
因此,如果在函数内部需要在不同地方使用几个不同的变量,建议在真正使用它们之前再声明它。
变量最好只写一次
操作一个变量的地方越多,就越难确定它的当前值。所以在很多语言里面有其各自的方式让一些变量不可变(是个常量),比如C++里的const和Java中的final。
3.如何简化表达式
有些表达式比较长,很难让人马上理解。这时候最好可以将其拆分成更容易的几个小块。可以尝试下面的几个方法:
1.使用解释变量
2.使用总结变量
3.使用德摩根定理
使用解释变量
有些变量会从一个比较长的算式得出,这个表达式可能很难让人看懂。这时候就需要用一个简短的“解释”变量来诠释算式的含义。使用一个例子:

其实上面左侧的表达式其实得出的是用户名,我们可以用userName来替换它:

使用总结变量
除了以“变量”替换“算式”,还可以用“变量”来替换含有更多变量更复杂的内容,比如条件语句,这时候该变量可以被称为"总结变量"。使用一个例子:

上面这条判断语句所判断的是:“用户id是否相等”。我们可以使用一个总结性的变量isEqual来替换它:

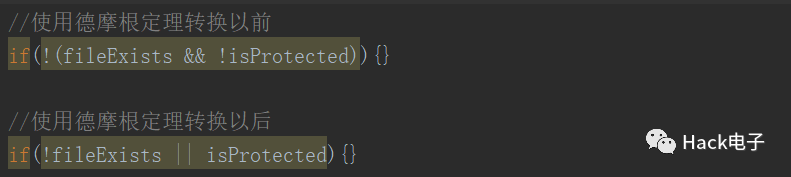
使用德摩根定理
当我们条件语句里面存在外部取反的情况,就可以使用德摩根定理来做个转换。
使用例子:
4.如何让代码具有美感
在读过一些好的源码之后我有一个感受:好的源码往往都看上去都很漂亮,很有美感。这里说的漂亮和美感不是指代码的逻辑清晰有条理,而是指感官上的视觉感受让人感觉很舒服。这是从一种纯粹的审美的角度来评价代码的:富有美感的代码让人赏心悦目,也容易让人读懂。
为了让代码更有美感,采取以下实践会很有帮助:
1.选择一个有意义的顺序
2.把代码分成"段落"
3.保持风格一致性
4.不要编写大段的代码
用换行和列对齐来让代码更加整齐
有些时候,我们可以利用换行和列对齐来让代码显得更加整齐。
换行
换行比较常用在函数或方法的参数比较多的时候。
使用换行:
- (void)requestWithUrl:(NSString*)url
method:(NSString*)method
params:(NSDictionary *)params
success:(SuccessBlock)success
failure:(FailuireBlock)failure{
}
不使用换行:
- (void)requestWithUrl:(NSString*)url method:(NSString*)method params:(NSDictionary *)params success:(SuccessBlock)success failure:(FailuireBlock)failure{
}
通过比较可以看出,如果不使用换行,就很难一眼看清楚都是用了什么参数,而且代码整体看上去整洁干净了很多。
列对齐
在声明一组变量的时候,由于每个变量名的长度不同,导致了在变量名左侧对齐的情况下,等号以及右侧的内容没有对齐:
NSString *name = userInfo[@"name"]; NSString *sex = userInfo[@"sex"]; NSString *address = userInfo[@"address"];
而如果使用了列对齐的方法,让等号以及右侧的部分对齐的方式会使代码看上去更加整洁:
NSString *name = userInfo[@"name"]; NSString *sex = userInfo[@"sex"]; NSString *address = userInfo[@"address"];
这二者的区别在条目数比较多以及变量名称长度相差较大的时候会更加明显。
选择一个有意义的顺序
当涉及到相同变量(属性)组合的存取都存在的时候,最好以一个有意义的顺序来排列它们:
让变量的顺序与对应的HTML表单中字段的顺序相匹配 从最重要到最不重要排序 按照字母排序
举个例子:相同集合里的元素同时出现的时候最好保证每个元素出现顺序是一致的。除了便于阅读这个好处以外,也有助于能发现漏掉的部分,尤其当元素很多的时候:
//给model赋值 model.name = dict["name"]; model.sex = dict["sex"]; model.address = dict["address"]; ... //拿到model来绘制UI nameLabel.text = model.name; sexLabel.text = model.sex; addressLabel.text = model.address;
把代码分成"段落"
在写文章的时候,为了能让整个文章看起来结构清晰,我们通常会把大段文字分成一个个小的段落,让表达相同主旨的语言凑到一起,与其他主旨的内容分隔开来。
而且除了让读者明确哪些内容是表达同一主旨之外,把文章分为一个个段落的好处还有便于找到你的阅读”脚印“,便于段落之间的导航;也可以让你的阅读具有一定的节奏感。
其实这些道理同样适用于写代码:如果你可以把一个拥有好几个步骤的大段函数,以空行+注释的方法将每一个步骤区分开来,那么则会对读者理解该函数的功能有极大的帮助。这样一来,代码既能有一定的美感,也具备了可读性。其实可读性又何尝不是来自于规则,富有美感的代码呢?
BigFunction{
//step1:*****
....
//step2:*****
...
//step3:*****
....
}
保持风格一致性
有些时候,你的某些代码风格可能与大众比较容易接受的风格不太一样。但是如果你在你自己所写的代码各处能够保持你这种独有的风格,也是可以对代码的可读性有积极的帮助的。
比如一个比较经典的代码风格问题:
if(condition){
}
or:
if(condition)
{
}
对于上面的两种写法,每个人对条件判断右侧的大括号的位置会有不同的看法。但是无论你坚持的是哪一个,请在你的代码里做到始终如一。因为如果有某几个特例的话,是非常影响代码的阅读体验的。
我们要知道,一个逻辑清晰的代码也可以因为留白的不规则,格式不对齐,顺序混乱而让人很难读懂,这是十分让人痛心的事情。所以既然你的代码在命名上,逻辑上已经很优秀了,就不妨再费一点功夫把她打扮的漂漂亮亮的吧!
5.如何写注释
注释是每个项目组都在不断强调的,可是依然有许多的代码没有任何的注释。为什么呢?因为每个项目在开发过程中往往时间都是非常紧的。在紧张的代码开发过程中,注释往往就渐渐地被忽略了。注释的目的是尽量帮助读者了解得和作者一样多。
在你写代码的时候,在脑海中可能会留下一些代码里面很难体现出来的部分:这些部分在别人读你的代码的时候可能很难体会到。而这些“不对称”的信息就是需要通过以注释的方式来告诉阅读代码的人。
控制流和逻辑的改进
控制流在编码中占据着很重要的位置,它往往代表着一些核心逻辑和算法。因此,如果我们可以让控制流变得看上去更加“自然”,那么就会对阅读代码的人理解这些逻辑甚至是整个系统提供很大的帮助。
那么都有哪相关实践呢?
1.使用符合人类自然语言的表达习惯
2.if/else语句块的顺序
3.使用return提前返回
4.代码不能写死
5.预测可能发生的变化
1.使用符合人类自然语言的表达习惯
写代码也是一个表达的过程,虽然表现形式不同,但是如果我们能够采用符合人类自然语言习惯的表达习惯来写代码,对阅读代码的人理解我们的代码是很有帮助的。条件语句中参数的顺序:首先比较一下下面两段代码,哪一个更容易读懂?

大家习惯上应该会觉得code1容易读懂。还有条件语句中的正负逻辑:在判断一些正负逻辑的时候,建议使用if(result)而不是if(!result)。
2.if/else语句块的顺序
在写if/else语句的时候,可能会有很多不同的互斥情况(好多个else if)。那么这些互斥的情况可以遵循哪些顺序呢?
先处理掉简单的情况,后处理复杂的情况:这样有助于阅读代码的人循序渐进地地理解你的逻辑,而不是一开始就吃掉一个胖子,耗费不少精力。
先处理特殊或者可疑的情况,后处理正常的情况:这样有助于阅读代码的人会马上看到当前逻辑的边界条件以及需要注意的地方。
3.使用return提前返回
在一个函数或是方法里,可能有一些情况是比较特殊或者极端的,对结果的产生影响很大(甚至是终止继续进行)。如果存在这些情况,我们应该把他们写在前面,用return来提前返回(或者返回需要返回的返回值)。
这样做的好处是可以减少if/else语句的嵌套,也可以明确体现出:“哪些情况是引起异常的”。
4.代码不能写死
目的就是能够使用中提高代码可维护性,便于日后的变更。
5.预测可能发生的变化
在开发过程中,如果将一些关键参数放到配置文件中,可以为软件部署和使用带来更多的灵活性。要做到这一点,要求我们在软件设计时,应当有更多的意识,考虑到软件应用中可能发生的变化。就可能方便部署人员在实际部署中进行灵活变化。然而这样的配置,必要的注释说明是非常必要的。软件可维护性的另一层意思就是软件的设计便于日后的变更。这一层意思与软件的可变更性是重合的。所有的软件设计理论的发展,都是从软件的可变更性这一要求逐渐展开的,它成为了软件设计理论的核心。
代码组织的改进
关于代码组织的改进,以下三种方法:
1.抽取出与程序主要目的“不相关的子逻辑”
2.重新组织代码使它一次只做一件事情
3.借助自然语言描述来将想法变成代码
一个函数里面往往包含了其主逻辑与子逻辑,我们应该积极地发现并抽取出与主逻辑不相关的子逻辑。类似于工具方法的函数其实是脱离于某个具体的需求的:它可以用在其他的主函数中,也可以放在其他的项目里面。
结语
遵循一些简单的规定(规范化指导)能使代码将更容易阅读(从而进一步理解、维护和扩展)。个人认为这一点是最重要的,好的程序员都是有强迫症的,他们会严格要求自己,通过不断的学习来提升自己的技术最终成为大神级别的程序员。如果不能以高标准来要求自己,即使看再多的如何写出高质量代码,懂再多的代码规范,也是没有用,最终还是会写出低质量代码。但是,提高自我要求是一种改变,一般来说,改变都不是一蹴而就的,需要一步一步来。所以,改变最好从小事做起,慢慢积累,最终蜕变。先从代码规范开始,熟悉代码规范,遵循规范写代码,直到成为习惯,然后再学习其它方法,最终写出高质量代码,让我们一起坚持,且一起行动。
审核编辑:汤梓红
-
分享一些优秀的verilog代码 高质量verilog代码的六要素2023-07-18 2252
-
何为高质量的代码?如何写出高质量代码?2023-08-02 1526
-
如何写出时序最优的HDL代码?如何写出时序裕量足够的代码?2024-03-12 2049
-
编写高质量C语言代码2013-07-31 4785
-
如何用B&R写出高质量的程序2021-09-29 1234
-
如何写出漂亮的嵌入式C代码2021-12-17 706
-
10个嵌入式小技巧 教你写出高质量代码!2021-12-20 4027
-
如何写好一篇高质量的引用论文2008-11-24 1009
-
微软四大名著之编程精粹:编写高质量C语言代码2016-04-20 1605
-
介绍了五个简单的总体概念 可轻松写出写出好代码2018-01-10 6295
-
高质量Verilog代码有什么特点2019-03-30 2406
-
如何写出行云流水般的高质量代码2019-10-08 4795
-
如何编写高质量的Javascript代码2021-01-21 983
-
教你如何写出性能更高的SystemVerilog代码2023-07-26 2253
-
如何写出高效优美的C语言代码2023-11-18 407
全部0条评论

快来发表一下你的评论吧 !
