

微美全息(NASDAQ:WIMI)探索全局-局部特征自适应融合网络框架在图像场景分类中的创新运用
电子说
描述
随着计算机视觉技术的不断发展以及数字图像规模的爆炸式增长,图像场景分类已成为许多领域的关键任务,已经得到了广泛的研究和应用。图像场景分类旨在识别和理解图像中的场景类型,在实际应用中,图像场景分类仍然面临着许多挑战,如复杂的场景等。然而,现有的图像场景分类方法往往只关注全局或局部特征的提取,而忽略了全局和局部特征之间的互补关联。为了解决这些问题,微美全息(NASDAQ:WIMI)不断探索新的网络架构和算法,正在将全局-局部特征自适应融合(Global-local feature adaptive fusion,“GLFAF”)网络框架运用于图像场景分类的实践中,以进一步提高图像场景分类的准确性。
全局-局部特征自适应融合(GLFAF)网络框架采用设计的CNN来提取多尺度和多层次的图像特征。通过利用这些多尺度和多层次特征的互补优势,该框架还设计了全局特征聚合模块,以发现全局注意力特征,并进一步学习这些全局特征之间的空间尺度变化的多重深度依赖关系。同时,该框架还设计了局部特征聚合模块,用于聚合多尺度和多层次的特征。基于通道注意力融合同一尺度的多级特征,然后基于通道依赖聚合不同尺度的空间融合特征。此外,空间上下文注意力旨在跨尺度细化空间特征,不同的Fisher向量层旨在学习空间特征之间的语义聚合。另外,还引入了两个不同的特征自适应融合模块,以探索全局和局部聚合特征的互补关联,从而获得全面和差异化的图像场景呈现。
据悉,WIMI微美全息试图将全局-局部特征自适应融合 (GLFAF) 网络框架运用在图像场景分类的实践中,不仅提高了分类的准确性,还增强了特征提取的鲁棒性。通过全局特征聚合模块,网络能够捕捉到图像的全局特征,理解图像的整体结构和内容。而局部特征聚合模块则关注于图像的细节信息,能够提取出图像中的关键特征和细节信息。通过融合全局和局部特征,充分利用它们之间的互补关联,从而更全面、更准确地理解图像场景。同时,这种融合方式也能够更好地应对图像中的噪声和干扰。通过全局特征和局部特征的自适应融合,能够充分利用图像的上下文信息,提高场景分类的准确性和鲁棒性。同时,该网络也具有较好的通用性和可扩展性,可以应用于不同的场景分类任务。进一步提高了其在实际应用中的灵活性。
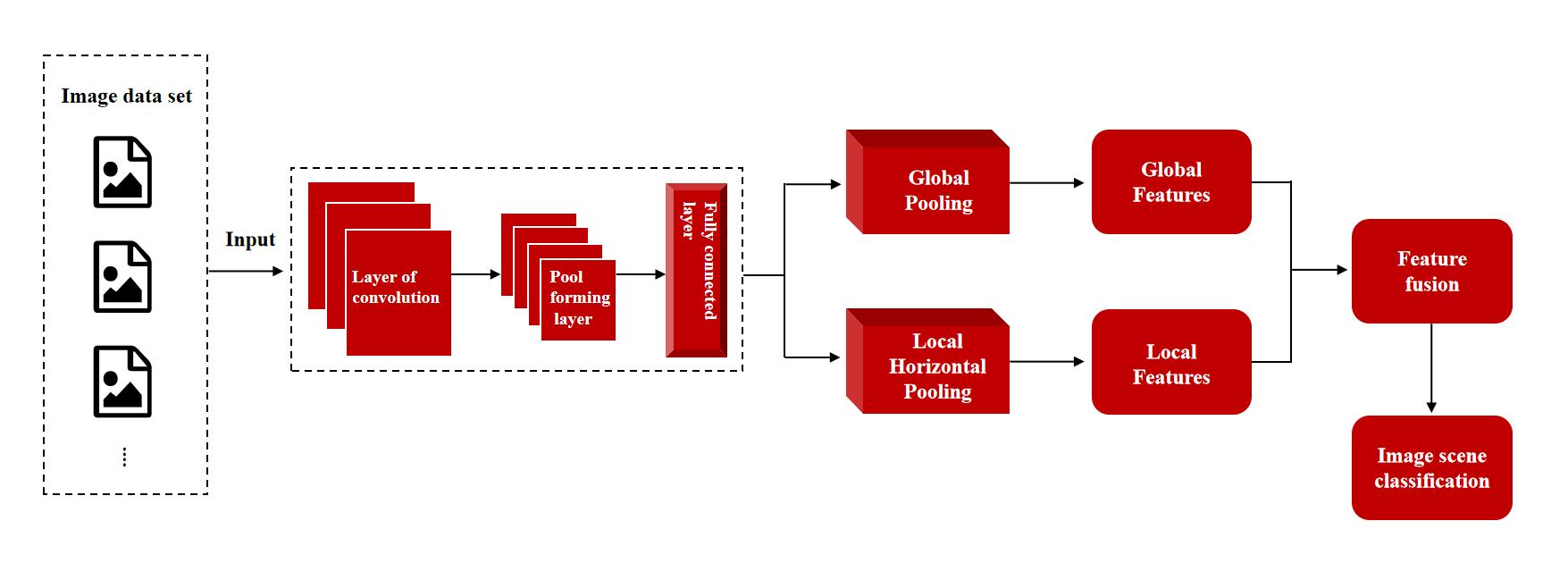
全局-局部特征自适应融合 (GLFAF) 网络框架在图像场景分类的运用为计算机视觉领域的研究提供了一种新的思路和方法。此外,这种网络框架还具有很好的可扩展性。通过简单地调整网络结构,可以适应不同的图像场景分类任务,提高其在实际应用中的灵活性。同时,这种网络框架的设计思路也可以应用于其他计算机视觉任务,如目标检测、图像分割等,为这些任务提供更全面、更准确的特征表示。
在未来的研究中,WIMI微美全息将不断完善和优化网络结构,提高算法的性能和鲁棒性。此外,WIMI微美全息还将致力于将全局-局部特征自适应融合网络框架应用于其他更多的实际场景中,如智能交通、安防监控、医疗诊断等,为相关领域的发展和应用提供有力的支持。
审核编辑 黄宇
-
工业彩色图像的局部自适应滤波2011-05-26 940
-
分块多特征自适应融合的多目标视觉跟踪_施滢2017-03-19 869
-
一种新的基于全局特征的极光图像分类方法2017-11-30 1050
-
基于自适应图像分类方法2017-12-04 898
-
一种坚固特征级融合和决策级融合的分类方法2017-12-19 3098
-
利用DCNN融合特征对遥感图像进行场景分类2018-01-10 1360
-
微美全息(WiMi)确定IPO价格 预计8月1日登陆纳斯达克2019-07-17 979
-
一种新型的自适应神经网络遥感场景分类模型2021-03-16 1033
-
基于特征交换的卷积神经网络图像分类算法2021-03-22 1879
-
结合局部特征融合的时间卷积网络方法2021-04-21 1043
-
基于自适应多分类器融合的手势识别方法2021-05-18 1329
-
微美全息(NASDAQ:WIMI)开发基于增强现实控制的闭环混合信号脑机接口机械臂控制系统2023-05-19 1328
-
微美全息(NASDAQ:WIMI)推出基于特征空间物体的高分辨图像自动配准技术2023-06-12 1698
-
微美全息(NASDAQ:WIMI)推出用于新一代互联网的两级编辑器网络技术2023-06-29 1802
-
微美全息(NASDAQ:WIMI)开发基于数字全息技术的半导体晶圆缺陷检测技术2023-07-12 1819
全部0条评论

快来发表一下你的评论吧 !
