

怎么实现一个容器编排系统呢?
电子说
描述
1 故事开始
随着消费者购买力的不断提升,用户拥有越来越多的电子快消品。小李预计在未来五年内,二手电子快消品市场将会迅速扩张。小李觉得这是一个创业的好机会,于是找到了我和几个志同道合的小伙伴开始了创业,决定做一个叫“XX”的平台。
2 故事发展
旗鱼一开始是一个 all in one 的 Java 应用,部署在一台物理机上,随着业务的发展,发现机器已经快扛不住了,就赶紧对服务器的规格做了升级,从 64C256G 一路升到了 160C1920G,虽然成本高了点,但是系统至少没出问题。
业务发展了一年后,160C1920G 也扛不住了,不得不进行服务化拆分、分布式改造了。为了解决分布式改造过程中的各种问题,引入了一系列的中间件,类似 hsf、tddl、tair、diamond、metaq 这些,在艰难的业务架构改造后,我们成功的把 all in one 的 Java 应用拆分成了多个小应用,重走了一遍阿里当年中间件发展和去 IOE 的道路。
分布式改完了后,我们管理的服务器又多起来了,不同批次的服务器,硬件规格、操作系统版本等等都不尽相同,于是应用运行和运维的各种问题就出来了。
还好有虚拟机技术,把底层各种硬件和软件的差异,通过虚拟化技术都给屏蔽掉啦,虽然硬件不同,但是对于应用来说,看到的都是一样的啦,但是虚拟化又产生了很大的性能开销。
嗯,不如使用类似 docker 的技术,比如 podman,因为容器技术在屏蔽底层差异的同时,也没有明显的性能影响,真是一个好东西。而且基于容器镜像的业务交付,使得 CI/CD 的运作也非常的容易啦~
随着容器数量的增长,又不得不面对新的难题,就是大量的容器如何调度与通信?毕竟随着业务发展,公司规模日益增长,线上运行着几千个容器,并且按照现在的业务发展趋势,马上就要破万了。
不行,我们一定要做一个系统,这个系统能够自动的管理服务器(比如是不是健康啊,剩下多少内存和 CPU 可以使用啊等等)、然后根据容器声明所需的 CPU 和 memory 选择最优的服务器进行容器的创建,并且还要能够控制容器和容器之间的通信(比如说某个部门的内部服务,当然不希望其他部门的容器也能够访问)。
我们给这个系统取一个名字,就叫做容器编排系统吧。
3 容器编排系统
那么问题来了,面对一堆的服务器,我们要怎么实现一个容器编排系统呢?
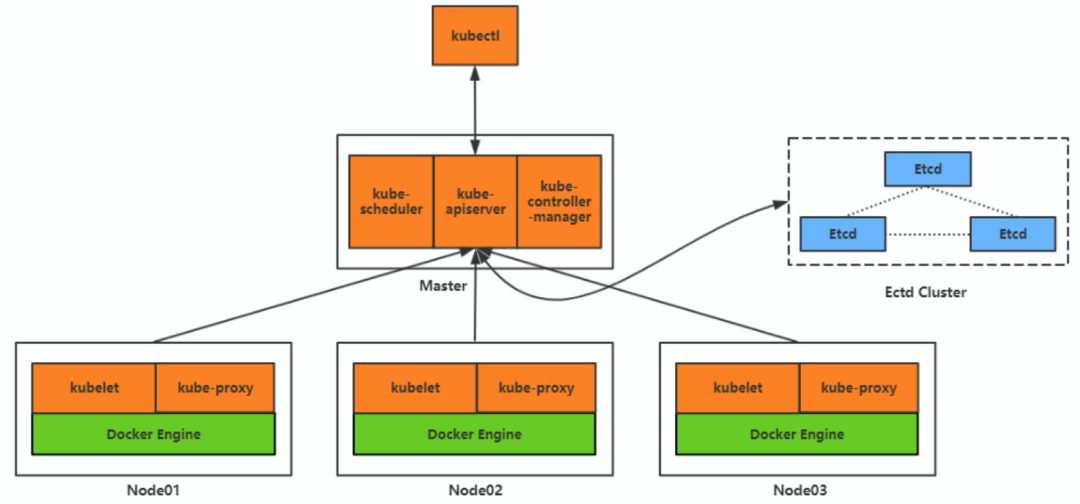
先假设已经实现了这个编排系统,那么服务器就会有一部分会用来运行这个编排系统,剩下的服务器用来运行业务容器,我们将运行编排系统的服务器叫做 master 节点,把运行业务容器的服务器叫做 worker 节点。
既然 master 节点负责管理服务器集群,那它就必须要提供出相关的管理接口,一个是方便运维管理员对集群进行相关的操作,另一个就是负责和 worker 节点进行交互,比如进行资源的分配、网络的管理等。
我们把 master 上提供管理接口的组件称为 kube apiserver,对应的还需要两个用于和 api server 交互的客户端,一个是提供给集群的运维管理员使用的,我们称为 kubectl;一个是提供给 worker 节点使用的,我们称为 kubelet。
那 master 又是怎么知道各个 worker 上的资源消耗和容器的运行情况的呢?这个简单,我们可以通过 worker 上的 kubelet 周期性的主动上报节点资源和容器运行的情况,然后 master 将这个数据存储下来,后面就可以用来做调度和容器的管理使用了。
至于数据怎么存储,我们可以写文件、写 db 等等,不过有一个开源的存储系统叫 etcd,满足数据一致性和高可用的要求,同时安装简单、性能又好,我们就选 etcd 吧。
现在我们已经有了所有 worker 节点和容器运行的数据,我们可以做的事情就非常多了。比如前面所说的,我们使用用户中心 2.0 版本的镜像创建了 1000 个容器,其中有5个容器都是运行在 A worker 节点上,如果 A 这个节点突然出现了硬件故障,导致节点不可用了,这个时候 master 就要将 A 从可用 worker 节点中摘除掉,并且还需要把原先运行在这个节点上的 5 个用户中心 2.0 的容器重新调度到其他可用的 worker 节点上,使得用户中心 2.0 的容器数量能够重新恢复到 1000 个,并且还需要对相关的容器进行网络通信配置的调整,使得容器间的通信还是正常的。
我们把这一系列的组件称为控制器,比如节点控制器、副本控制器、端点控制器等等,并且为这些控制器提供一个统一的运行组件,称为控制器管理器(kube-controller-manager)。
那 master 又该如何实现和管理容器间的网络通信呢?首先每个容器肯定需要有一个唯一的 ip 地址,通过这个 ip 地址就可以互相通信了,但是彼此通信的容器有可能运行在不同的 worker 节点上,这就涉及到 worker 节点间的网络通信,因此每个 worker 节点还需要有一个唯一的 ip 地址,但是容器间通信都是通过容器 ip 进行的,容器并不感知 worker 节点的 ip 地址,因此在 worker 节点上需要有容器 ip 的路由转发信息,我们可以通过 iptables、ipvs 等技术来实现。
那如果容器 ip 变化了,或者容器数量变化了,这个时候相关的 iptables、ipvs 的配置就需要跟着进行调整,所以在 worker 节点上我们需要一个专门负责监听并调整路由转发配置的组件,我们把这个组件称为 kube proxy(此处为了便于理解,就不展开引入 Service 的内容了)。
我们已经解决了容器间的网络通信,但是在我们编码的时候,我们希望的是通过域名或者 vip 等方式来调用一个服务,而不是通过一个可能随时会变化的容器 ip。因此我们需要在容器 ip 之上在封装出一个 Service 的概念,这个 Service 可以是一个集群的 vip,也可以是一个集群的域名,为此我们还需要一个集群内部的 DNS 域名解析服务。
另外虽然我们已经有了 kubectl,可以很愉快的和 master 进行交互了,但是如果有一个 web 的管理界面,这肯定是一个更好的事情。此处之外,我们可能还希望看到容器的资源信息、整个集群相关组件的运行日志等等。
像 DNS、web 管理界面、容器资源信息、集群日志,这些可以改善我们使用体验的组件,我们统称为插件。
至此,我们已经成功构建了一个容器编排系统,我们来简单总结下上面提到的各个组成部分:
Master 组件:kube-apiserver、kube-scheduler、etcd、kube-controller-manager
Node 组件:kubelet、kube-proxy
插件:DNS、用户界面 Web UI、容器资源监控、集群日志
审核编辑:黄飞
-
数据编排支持人工智能(AI)的下一步发展2021-09-24 4358
-
100个容器周边项目,点亮你的容器集群技能树2018-05-22 2522
-
K8S容器编排的互通测试2019-06-06 2154
-
kubernetes系统基本概念2019-11-05 1608
-
LCD汉字编排软件2015-12-28 841
-
基于DOCKER容器的ELK日志收集系统分析2017-11-06 1246
-
平台式惯导系统的力学编排详细资料说明2020-03-30 2151
-
异构容器云应用迁移系统研究综述2021-06-09 1261
-
如何实现一个秒杀系统2022-09-15 3103
-
什么是流程/规则编排2022-09-21 2999
-
为什么薄膜电容器可以自愈呢?2023-06-08 1918
-
iSulad Sandbox API简化容器调用链2023-11-20 1596
-
Docker容器实现开机自动启动策略2024-03-11 7567
-
深入剖析两大容器编排平台的核心差异2025-08-20 1076
全部0条评论

快来发表一下你的评论吧 !
