

KubeCASH:基于软硬件融合的容器管理平台
电子说
描述
编者按
Kubernetes(K8S)虽然强大,但也有劣势,劣势在于K8S主要基于CPU平台。有的朋友可能会说,不是有CDI吗,可以实现硬件加速器的支持。但其实CDI能做的事情非常有限,CRI、CNI、CSI、CDI等接口都奉行一个重要的原则:“不做事,就不会犯错”。K8S可以理解成嵌于整个软硬件堆栈的一个薄层,仅仅提供硬件到容器环境的一个接入。至于具体的软硬件交互接口和机制、硬件加速器的系统架构和实现、如何把硬件性能和性能价值充分发挥出来的计算框架,以及硬件加速原生的软件架构规范等等,它统统不管。
透过现象看本质,核心的问题在于软件和硬件之间的已经产生的巨大鸿沟。做软件的朋友,在CPU的环境里,任意驰骋,各种花活玩的很溜;但CPU性能的天花板,使得大家所能玩的越来越有限,像AI大模型、高阶智驾等场景,在容器环境都很难高效的用起来。做硬件加速芯片的朋友,距离业务很远,做出来的东西,也许很好,但能覆盖的场景和迭代很少,加速芯片很难大规模的用起来。软硬件鸿沟的本质挑战,难啃的骨头,K8S也爱莫能助。
KubeCASH,聚焦于啃硬骨头,实现K8S相关软件和其他各种加速类型处理器的整合,充分压榨硬件加速器的性能和多样性算力的价值。给K8S装上腾飞的翅膀,单车变火箭。KubeCASH的目标是:相比目前的CPU/GPU平台,给客户提供100+倍的性能提升;以及单位算力成本下降到1%以下。
1 K8S综述
1.1 K8S容器虚拟化
容器属于OS层虚拟化技术,基于Linux内核cgroup、namespace、Union FS等技术,对进程进行封装隔离。最知名的容器引擎Docker,最初基于LXC,从1.11版本开始,使用Runc和containerd。
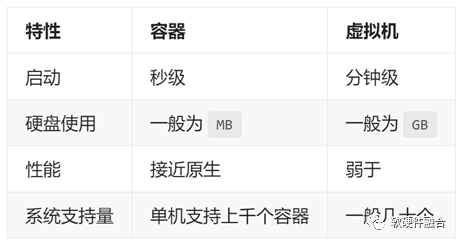
容器的优势:高效利用系统资源、快速启动、一致的运行环境、持续交付和部署、更轻松的迁移、更轻松维护和扩展。
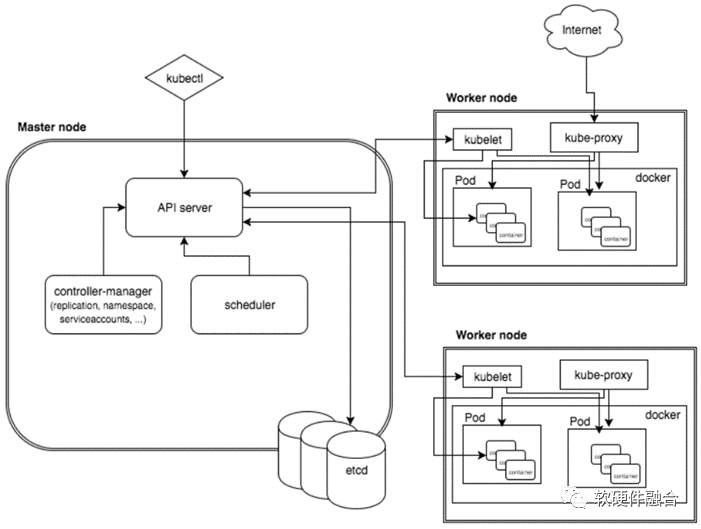
Kubernetes是一个开源的容器编排平台,自动完成应用容器的部署、管理和扩展。Kubernetes简写为K8s。
K8s集群由主节点(Master)与工作节点(Worker)组成。这些节点可以运行在VM、物理机,或公有云实例上。K8s主节点,是集群控制面系统服务的集合。包括API服务器、控制器管理器、调度器、ETCD。K8s工作节点,是K8s集群的实际容器运行的节点。每个工作节点上运行的组件包括:节点本地总控Kubelet、容器运行时、集群网络的Kube-proxy、以及运行调度原子单位Pod。
1.2 从硬件视角看K8S存在的问题
K8S存在问题吗?说真的,作为还跨在门槛上的我,很难给出全面而权威的答案。
但从底层软硬件的视角,还是可以来分析分析K8S的问题的。
我们之前就说过,当软硬件解耦之后,软件和硬件才能完全的放飞自我,快速迭代发展。K8S,就是在完全解耦的CPU平台上,完全不考虑硬件的情况下,做出来的既强大又优秀,还得到广大开发者认可的容器编排工具,同时基于K8S已经形成了云原生的庞大生态。
从底层软硬件视角看,K8S,或者说K8S生态的问题主要在于:
K8S生态主要基于CPU。然而,我们的CPU已经存在了50多年的时间了,早已不堪重负,CPU做点管理工作还行,做点性能敏感的计算这点“重体力”活,会累得够呛。而K8S生态对硬件加速的支持很少。
相比虚机,K8S容器完全“脱实向虚”。K8S基于一个标准化的解耦的软硬件接口——CPU架构,不用不考虑硬件对软件的影响。基于CPU实现的标准化软硬件接口,意味着扩展新的加速硬件处理器就变得很难,其他各种性能更优的硬件加速器就很难加入到K8S的底层计算平台支撑。
一方面,K8S以应用为中心,相比虚机(以硬件资源为中心),对硬件灵活性的要求要更高。而另一方面,加速处理器在增加性能的时候,其灵活性势必是降低的。这样,两者背向而行,硬件加速处理器就变得愈发无法满足K8S的更高灵活性要求。
2 硬件加速器面临的挑战
2.1 业务快速变化
本质的讲,随着业务越来越庞大,越来越复杂,其变化也就越来越快,想用专用的加速器去实现业务的加速,势必越来越难。
作为底层芯片开发者,即使再努力,也只能捕捉到一个高质量的业务的瞬时状态而已。等花费大量人力物力以及时间成本,把硬件加速器做好的时候,业务早已变的“面目全非”。
用“面目全非”来形容业务,并不夸张。上层的软件业务通常是2个月一个小迭代,半年一个大迭代,作为算法和业务逻辑的开发者来说,都很难预料未来两年三年,算法和业务会变成什么样子。
业务开发者自己都很难把握业务的发展方向,底层的芯片开发者则更难把握业务;并且,芯片的开发周期2年,生命周期5年,这么长的时间周期,更难预判业务的未来发展。
2.2 算力无法灵活、充分的利用
2.2.1 算力的粒度
通过虚拟化,可以实现资源按粒度自由切分和重组。虚拟化能力是系统灵活性的一种体现:
CPU是一个非常好的处理器,线程调度可以让很多软件共享单个CPU Core,虚拟化可以实现用于软件工作任务的资源弹性。可以把CPU按照时间片的细粒度进行划分,然后分配给软件。我们给软件工作任务分配的CPU核的数量可以是万分之一、千分之一、百分之一、一、十、百等各种不同的规格,非常的灵活。因为CPU是完全软件化的运行平台,软件开发者可以随心所欲,做任何可以想象到的事情。
而GPU的虚拟化共享,就比较困难。很长一段时期,GPU并不支持虚拟化和可扩展性。目前,GPU即使支持虚拟化,其虚拟化功能也非常的有限,比如有的GPU支持把设备虚拟化成若干固定的份数,这些是硬件支持的能力,而软件仍然无法自由定义虚拟化的份数。
GPU已经是相对灵活的加速处理器了,其他的各类更偏专用的加速处理器器,就更难谈对虚拟化的支持了。
“不受硬件约束,软件随心所欲的虚拟化”,对硬件加速器来说,是一种奢望。
2.2.2 算力的匹配度
云计算也好,边缘计算也好,在服务器上运行什么样的业务,其实是非常不确定的。
如果我们在服务器上准备的加速处理器是专用的加速,这意味着,在绝大部分时间里,客户的业务可能无法把这个算力资源用起来。
此外,受用户业务差异性和迭代的影响,硬件加速器跟业务算法和逻辑可能存在偏差,致使算力的利用率很低。
可以说,实际环境,硬件加速器和业务的匹配度存在偏差的可能性极高。我们稍微量化一下:
长期来看,业务可能只有5%左右的时间里,可以利用硬件加速的资源;
并且,即使在这5%左右的时间里,能利用到的算力也仅有标称算力的5%左右;
两者相乘,意味着算力的实际利用率仅有0.25%。
2.2.3 算力的协同
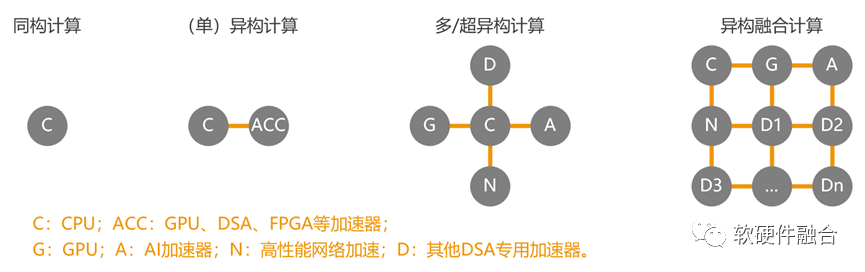
因为CPU已经性能瓶颈,因为GPU逐渐性能瓶颈,我们不得不选择越来越多的加速算力。在微观的芯片和设备级,我们把这样的计算架构称为多/超异构、异构融合;在宏观的数据中心以及云网边端级,我们把它描述为多元异构、算力多样性等等。
不管怎么称呼,异构的算力越来越多,已经成为共识。那么,紧接着的挑战,就是如何把这么多的异构算力资源充分协同起来。
“一根筷子轻轻被折断,十双筷子牢牢抱成团”,如果无法实现如此多异构算力的协同计算,那么一盘散沙的多样性算力,几乎碎到不能再碎的各自私有的软硬件生态,不但无法解决算力挑战的问题,反而会使得系统越来越复杂,最后得不偿失。
3 软硬件之间的鸿沟需要填平
软件和硬件的矛盾如此严重,那该如何做?抛砖引玉,我们给出的答案是:全栈协同优化。
3.1 硬件应该怎么做?
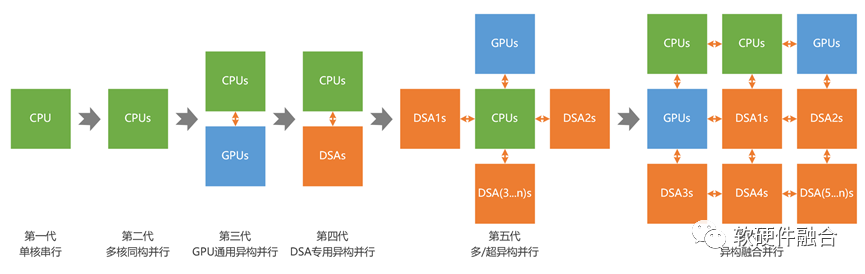
硬件上,一方面是需要集成更多的异构算力,实现显著的Scale Up。从计算架构的角度,则是从CPU的同构计算、GPU/AI处理器等的异构计算,再到更多异构集成的多/超异构计算,最终实现更多异构处理器充分协同和融合的异构融合计算。
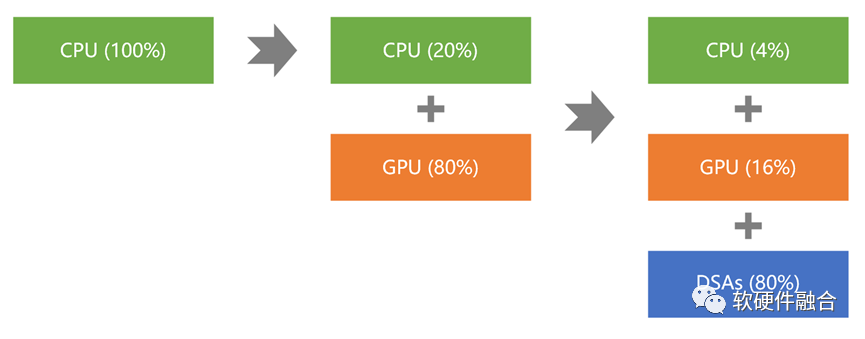
当然,只实现更多异构的融合计算还不够。受限于业务的差异性和快速迭代,芯片需要足够通用。依据“二八原理”,系统越来越复杂,沉淀下来的确定性的不怎么变化的工作任务就越多,因此可以通过CPU+GPU+多个DSA的方式,以及软硬件融合设计能力,实现通用的异构融合计算。
3.2 框架应该怎么做?
计算框架是非常关键的部分,承上启下:上接业务软件,下接硬件处理器。其主要工作包括:
首先,本职工作。能够把硬件加速器的性能和性能价值彻底的发挥出来。
其次,计算框架要能和K8S的集群管理系统完美融合,充分实现虚拟化支持以及基于容器的计算和调度。
再次,计算框架需要实现跨处理器运行。比如能够基于CPU、GPU和DSA处理器运行。
最后,不同处理器的子框架还需要整合,实现多种架构处理器的协同和融合,实现支持异构“融合”计算的宏计算框架。
3.3 业务软件应该怎么做?
这里,我们借用“云原生”的概念,给出一个新概念“硬件加速原生”。
硬件加速原生:指的是,软件在架构设计的时候,就要把控制面和数据面分离,然后定义好两者之间交互的标准化接口;这样,后续优化的时候,就可以在不改变既有运行机制的情况下,快速友好的实现数据面的硬件加速器运行。这个时候,控制面仍然运行在CPU,而数据面可以在CPU和硬件加速器自由切换,或者实现类似快慢路径的两路并行机制。
软件在架构设计的时候,就考虑硬件加速的支持,可以实现“硬件加速原生”的软件开发,可以实现业务软件对硬件加速的支持,可以实现业务性能多个数量级的提升和运行成本多个数量级的下降。
4 KubeCASH:基于软硬件融合的容器管理平台
4.1 KubeCASH综述
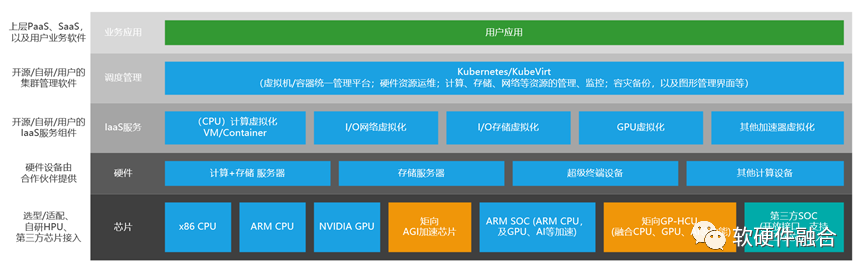
KubeCASH,Kubernetes + CASH(Converged Architecture of Software and Hardware,软硬件融合架构),实现基于软硬件融合的、充分压榨硬件算力及算力价值的、开源开放的容器管理平台。
4.2 底层计算架构:支持同构、异构、多异构和异构融合
KubeCASH的四个演进阶段:
第一阶段,仅支持CPU处理器。包括x86、ARM和RISCv;
第二阶段,仅支持GPU加速处理器。包括NVIDIA GPU和AMD GPU,未来也考虑支持国产GPU。
第三阶段,逐步加入对更多加速处理器的支持。这些处理器可以是集成单芯片,也可以是单个服务器里的多个分立的处理器,还可以是通过集群/跨集群实现的各种不同架构的远程处理器资源。
第四阶段,在第三阶段基础上实现异构融合的支持,充分实现各种异构处理器、多样性算力之间的协同和融合。
4.3 应对多样性算力的挑战
在2.2节我们介绍了算力无法充分利用的问题,这里简单概括一下:一方面,算力的匹配度导致算力利用率非常低,另一方面,算力之间没有协同效应,越来越多的异构算力,越使得系统走向失衡。
KubeCASH,能够实现更多算力的接入,能够更好的匹配算力和业务,能够实现多种架构处理器算力的充分利用,能够实现多样性算力的充分协同,以此满足上层业务日益快速增长的算力需求。
4.4 KubeCASH开源项目
KubeCASH,聚焦于啃硬骨头,实现K8S相关软件和其他各种加速类型处理器的整合,充分压榨硬件加速器的性能和多样性算力的价值。给K8S装上腾飞的翅膀,单车变火箭。
KubeCASH的目标是:相比目前的CPU/GPU平台,给客户提供100+倍的性能提升;以及单位算力成本下降到1%以下。
软硬件融合技术社区,发起KubeCASH开源项目,寻找“同频共振”的伙伴一起,共同开发,共襄盛举。
审核编辑:汤梓红
- 相关推荐
- 热点推荐
- 处理器
- cpu
- 容器
- kubernetes
-
电池管理系统(BMS)软硬件介绍2024-03-27 868
-
软硬件融合的概念和内涵2023-10-17 3230
-
为什么要从“软硬件协同”走向“软硬件融合”?2022-12-07 4094
-
如何对SOA进行软硬件部署2022-06-10 2918
-
2021 OPPO开发者大会主会场:软硬件融合技术升级2021-10-27 2103
-
基于FPGA芯片的软硬件平台的使用2021-07-01 2391
-
NI软硬件平台在汽车ECU开发和测试中的应用是什么?2021-05-12 1506
-
USB的串行通信软硬件设计2017-09-04 1195
-
基于嵌入式网络的无线传感器网络平台软硬件设计2017-01-12 1237
-
SOPC的嵌入式软硬件协同设计平台实现2011-12-22 2018
-
支持过程级动态软硬件划分的RSoC设计与实现2010-05-28 2005
-
基于NI的软硬件开发标准的测试平台2010-03-26 758
-
满足高低端血压计设计的软硬件平台2010-03-05 1492
-
单片机测控系统的软硬件平台技术2009-08-13 864
全部0条评论

快来发表一下你的评论吧 !
