

如何从训练集中生成候选prompt 三种生成候选prompt的方式
描述
作者:刘小虎,中国科学院计算技术研究所
组内现在正在做大模型相关,笔者负责prompt engineering,在实际工程中会发现prompt对模型的输出影响巨大,可能一个字就会改变模型的输出(笔者用的是量化后的7B model),而且换一个模型,就要改变手工制定的prompt,非常麻烦和受限。因此想到了Automatic prompt engineering。由此记录自己的paper阅读,肯定会有自己的理解错误的地方,如有发现请联系笔者进行更正。
APE: Larger Language models are human-level prompt engineers
这篇论文的核心思路就是:
• 从训练集中生成候选prompt
• 评估这些候选prompt,选出得分最高的prompt
• resample, 使用LLM 生成语义相近的prompt(2中得分最高的prompt),然后再进行评估,最终得到prompt
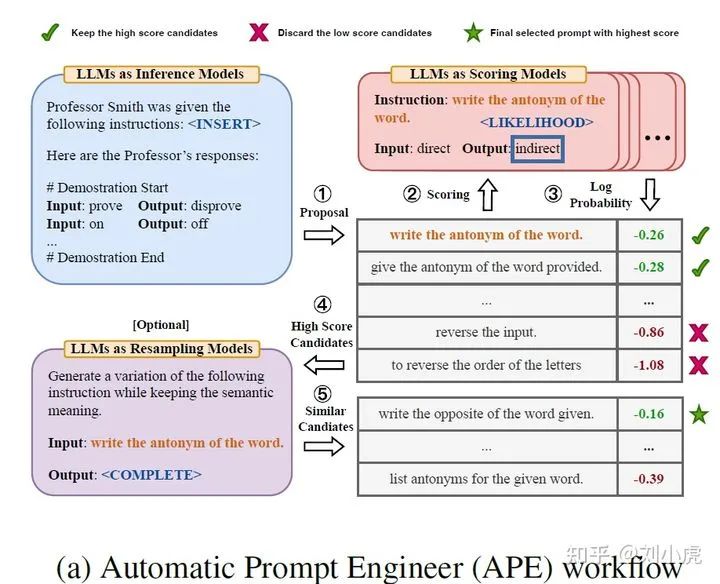
APE整体框架图
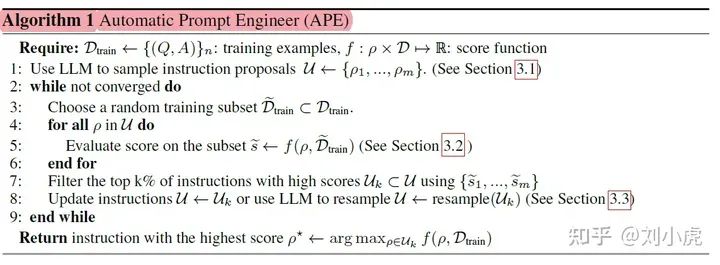
APE算法
生成候选prompt
论文指出有三种生成候选prompt的方式
• Forward Mode Generation

这个比较直观,就是写一段指令,然后将训练集的输入输出给出,直接让LLM自动生成prompt。这个生成prompt的模板不知道是哪的出处,有网友知道是哪的,可以直接指出。
• Reverse Mode Generation

这个也很直观,就是填补空白的方式。但是这个方式怎么实现呢?我比较疑惑,不知道怎么实现这个填补空白的方式,因为LLM都是一个字一个字的自回归生成。

• Customized Prompts

这一类就是自己根据task来设计了,论文给出了一个示例。我认为就是使用不同的模板来扩充了多样性(可能是我的理解有错误)
评估候选prompt
• Execution accuracy
这种方式其实就是使用GT来进行比较。将得分最高的prompt扔进模型,得到结果和GT进行比较。
• Log probability
给定指令和问题后所得到的所需答案的对数概率
另外,这一步如果在全量训练集上评估,则开销非常大,因此作者提出一种multi-stage策略。大致思想是先在少量subset上评估,然后过滤掉比较差的,循环这一过程直到候选集足够小,此时再在全量训练集上进行评价、挑选。
Resample
使用的是蒙特卡罗搜索的方式。说的这么玄乎,其实还是使用LLM来生成prompt!但是这一步他是使用之前得分最高的prompt再次来生成语义相近的prompt。

这里可以是迭代的方式进行。怎么迭代呢?笔者是这样认为的:
1、得到语义相近的prompt。
2、评估这些prompt。
3、得到得分最高的prompt 重复1、2步骤。
作者实验发现,对于比较难的任务,进行resample能够进一步提升效果。
ProTeGi (Automatic Prompt Optimization with “Gradient Descent and Beam Search)

这篇文章早就在arxiv上发出来了。当时的缩写还是APO。今年被EMNLP2023收录
首先让我们先来看看这篇论文的整体框架图。
ProTeGi总体框架图
方法:利用数值梯度下降自动优化提示,同时结合beam search和bandit selection procedure提高算法效率。
优势:无需调整超参数或模型训练,ProTeGi可以显著提高提示的性能,并具有可解释性。
什么原理呢?
• 得到当前prompt的“gradient”
这个“gradient”怎么得到的了呢,这是个啥玩意,怎么还有梯度?注意,注意。人家是带引号的!比喻成梯度。这玩意有什么用呢。
文章指出给定一批error samples(当前prompt无法预测正确的),让LLM给出当前prompt预测错误的原因,这一原因即文本形式的“gradient”。使用的还是LLM!

• 将“gradient”输入到LLM中,得到新的prompt

• 和APE一样,resample, 得到语义相近的prompt,然后迭代。
注意注意啊,每轮迭代中,最外层包含一个beam search过程,以便强化探索。这一块就看不懂了, 也是本论文的贡献之一。没有想过改进,所以略过直接使用。
OPRO (Large Language Models as Optimizers)

paper: Large Language Models as Optimizers 链接:https://arxiv.org/abs/2309.03409 code: https://github.com/google-deepmind/opro
首先来看框架图
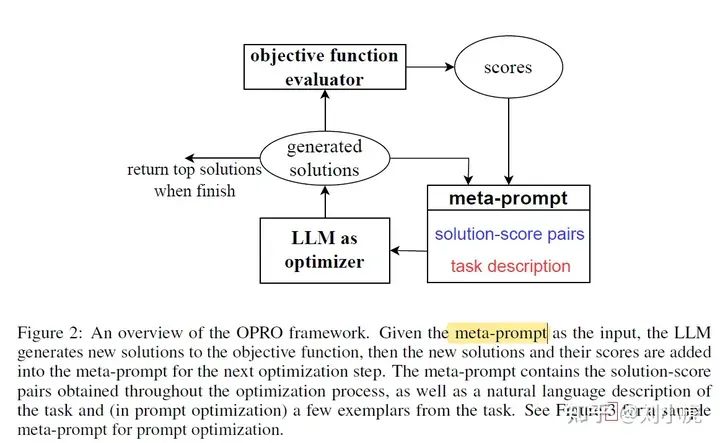
然后接着看论文对meta-prompt的定义

blue 蓝色的是 solution-score pairs 也就是 prompt + score。这个score怎么来的呢?使用LLM进行打分,也就是Figure 2 中的 objective function evaluator。这应该也是个LLM, 这个LLM和 LLM as optimizer 可以是同一个 也可以不是。** 注意,这个打分其实就是评估新生成的prompt在任务上的表现,说白了就是和GT进行对比(对了+1)**。
orange 橙色 就是指令 meta-instructions.
purple 紫色 就是task description,包含一些任务的examples、优化的目标等
因此, OPRO的核心思路是让LLM基于过往的迭代记录、优化目标,自己总结规律,逐步迭代prompt,整个过程在文本空间上完成。
PE2 (Prompt Engineering a Prompt Engineer)

paper: Prompt Engineering a Prompt Engineer 链接https://arxiv.org/abs/2311.05661
这一篇paper 是 APE 和 APO (ProTeGi)的改进版,集成了这2个方法的优点。
这篇论文主要提出了一个meta-prompt的东东(等等,我去,这玩意和OPRO这篇论文里的好像啊)
提供更细节的指令和内容
• 提供提示工程的教程
• 2阶段的任务描述
• step-by-step 推理的模板
• 明确指定提示与输入之间的相互关系
结合优化的概念
• batch size : 指的就是使用batch size失败的例子
• step size : 指的就是改变原始的prompt中step size个字
• Optimization History and Momentum : 其实就是增加了以外的prompt和修改后的prompt
看完后惊呼道:这是真能写啊。写的玄乎又玄乎的。一图胜千言


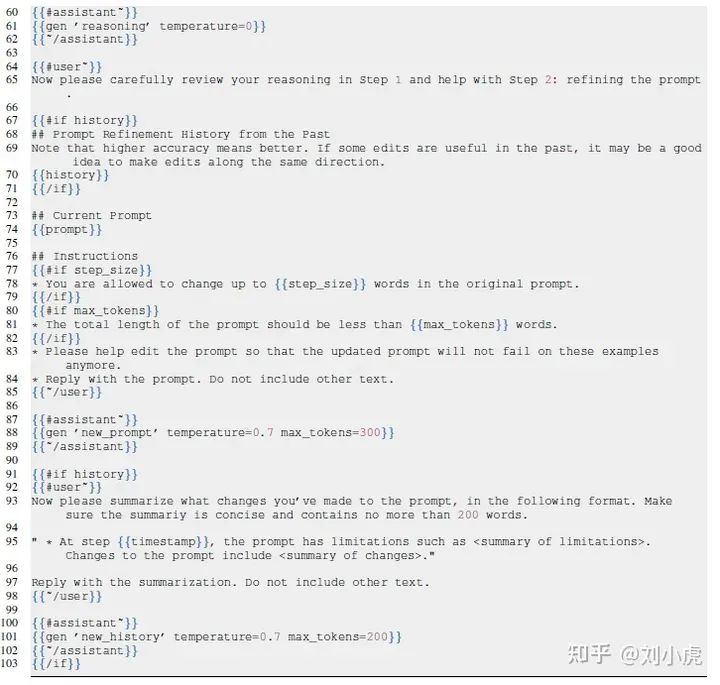
给我的感觉就是前面3篇论文的集成版本。
将OPRO中的meta-prompt的概念用到了 APO中了,然后丰富了模板的内容。有反思分析有推理,迭代的让模型自动修改prompt。
审核编辑:黄飞
-
AI对话魔法 Prompt Engineering 探索指南2024-11-07 2171
-
三种SPWM波形生成算法的分析与实现2016-08-24 1107
-
HTML DOM prompt()方法使用2017-11-28 5869
-
推荐系统中候选生成和冷启动挑战的研究2019-07-30 3169
-
应用于任意预训练模型的prompt learning模型—LM-BFF2021-08-16 5477
-
揭秘Prompt的前世今生2021-09-01 3960
-
Prompt范式你们了解多少2021-09-10 3617
-
NLP中Prompt的产生和兴起2021-09-12 3243
-
基于预训练视觉-语言模型的跨模态Prompt-Tuning2021-10-09 4174
-
万能的prompt还能做可控文本生成2022-03-22 3619
-
关于Prompt在NER场景的应用总结2022-05-24 2691
-
一种基于prompt和对比学习的句子表征学习模型2022-10-25 1652
-
专业音频应用中生成负电源轨的方案2022-10-31 585
-
从评论中生成艺术的开源项目2023-07-05 596
-
prompt在AI中的翻译是什么意思?2023-08-22 4909
全部0条评论

快来发表一下你的评论吧 !
