

【Rust AI】01. 使用Jupyter学习Rust
电子说
描述
简介
大家(好的,其实是大多数人)都说 Rust 很难,但我不这么认为。虽然 Rust 可能比 Python 稍微难一些,但我们可以像学习 Python 一样学习 Rust - 通过使用 Jupyter。
在本文中,我将向你展示如何以交互模式编写 Rust 代码,特别是在数据科学场景中。
安装
首先,你需要安装 Python 开发的交互式笔记本 Jupyter。你可以通过以下方式安装(我假设你之前已经安装了 Python):
pip install jupyterlab
请记得检查安装是否成功,请运行以下命令:
jupyter lab
你将会看到一个 Web 用户界面,请立即关闭它。之后,我们需要安装 Evcxr Jupyter Kernel,它是 Jupyter 的 Rust 内核扩展。你可以通过以下方式安装(我假设你之前已经在计算机上安装了 Rust):
cargo install --locked evcxr_jupyter
evcxr_jupyter --install
之后,再次启动 Jupyter UI,你将看到类似于以下内容:
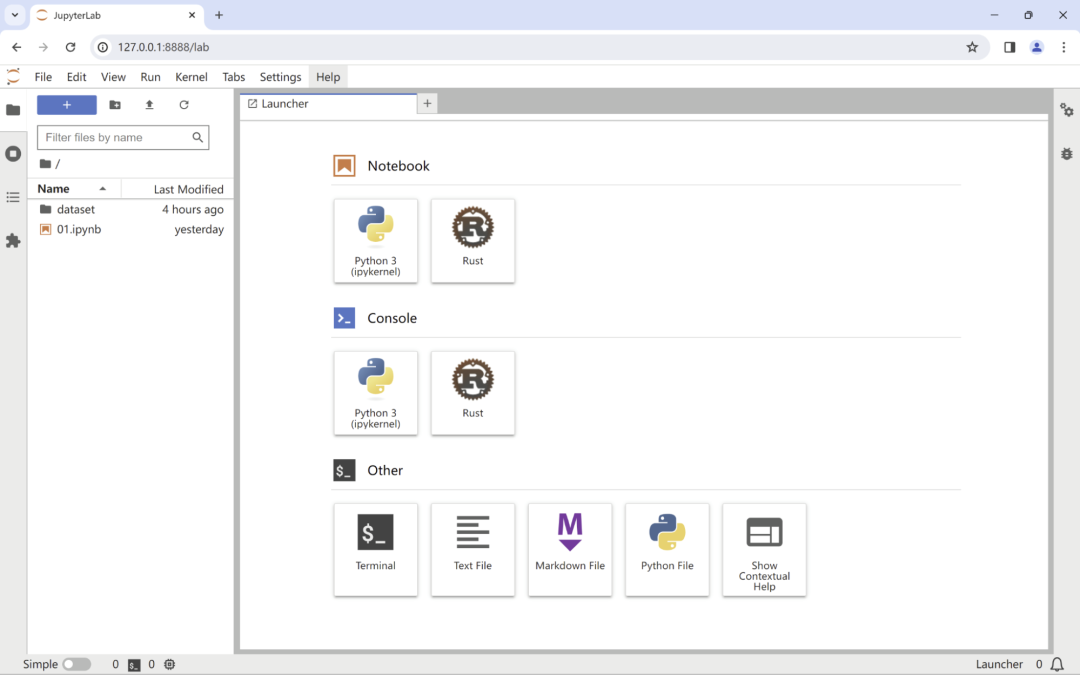
恭喜,我们在启动器面板上看到了 Rust 的标志。
只需单击 Notebook 部分下的 Rust 方块,我们就可以得到:
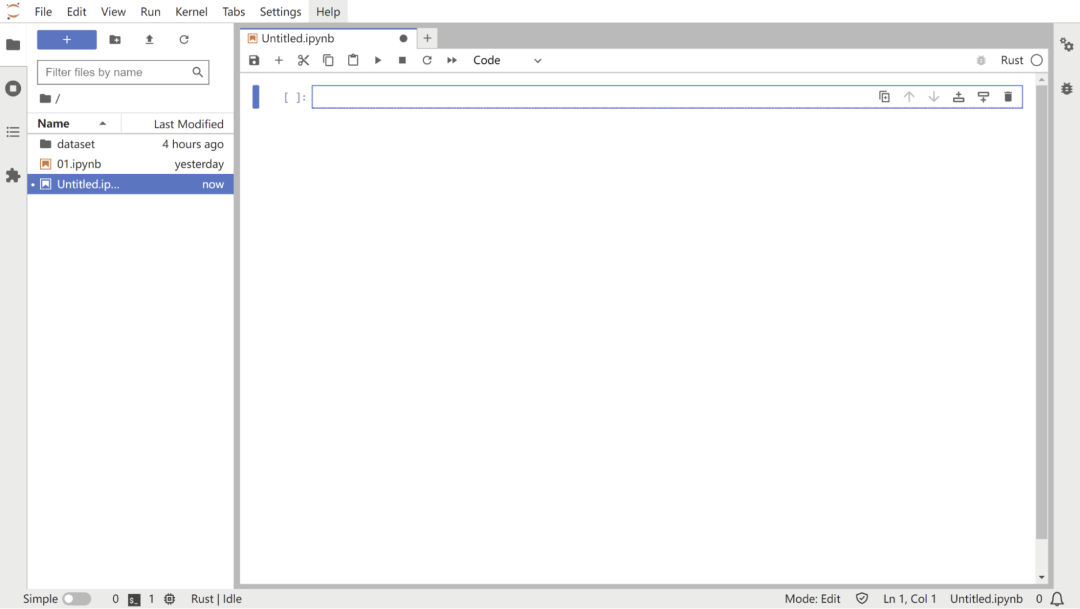
一切准备就绪,我们开始吧!
基本操作
为了练习本教程,我建议你具备 Rust 语言的基本背景。让我们从测试基本变量绑定开始,
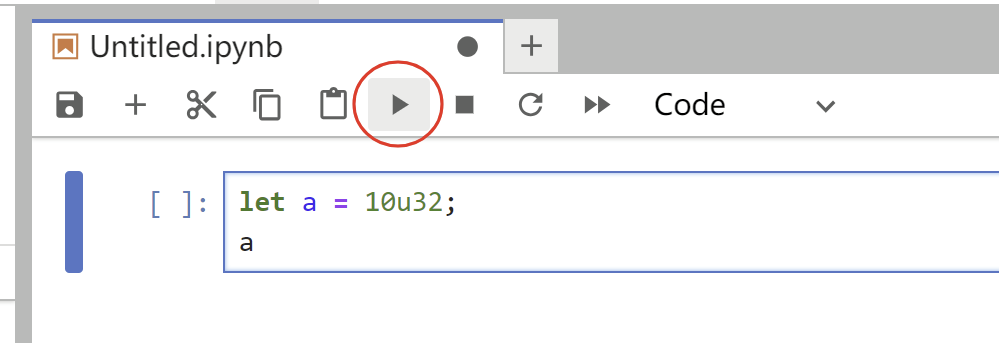
输出:
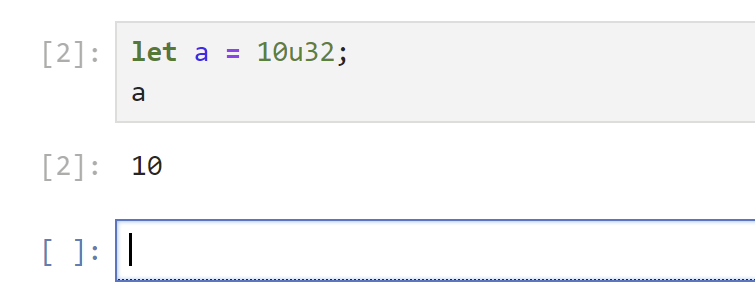
输出会在 Rust 代码下一行打印,是的,是交互式的。
让我们继续。

看起来一切都很顺利。我们现在可以继续进行更复杂的任务。
我们将利用三个数据科学工具:polars、ndarray 和 plotters,学习如何使用 Rust 进行数据分析。
使用Polars分析数据集
在本教程中,我将选择泰坦尼克号数据集作为示例,以说明 Rust 的便利性。
根据 Bing 的说法:“泰坦尼克号数据集是用于数据科学和机器学习的流行数据集。它包含有关泰坦尼克号上的乘客的信息,包括年龄、性别、等级、票价以及他们是否在灾难中幸存。这个数据集经常用于预测建模练习,例如根据乘客的特征预测乘客是否能够幸存。这是一个适合数据分析和机器学习初学者的经典数据集,广泛用于 Kaggle 竞赛。”
我们可以从这里(https://huggingface.co/datasets/phihung/titanic)下载泰坦尼克号数据集,并将其移动到 dataset/ 子目录中。
添加依赖:
:dep ndarray = {version = "0.15.6"}
:dep polars = {version = "0.35.4", features = ["describe", "lazy", "ndarray"]}
:dep plotters = { version = "0.3.5", default_features = false, features = ["evcxr", "all_series", "all_elements"] }
显示依赖:
:show_deps
输出:
ndarray = {version = "0.15.6"}
plotters = { version = "0.3.5", default_features = false, features = ["evcxr", "all_series", "all_elements"] }
polars = {version = "0.35.4", features = ["describe", "lazy", "ndarray"]}
将数据集读入 polars 内存:
use polars::*;
use polars::DataFrame;
use std::Path;
fn read_data_frame_from_csv(
csv_file_path: &Path,
) -> DataFrame {
CsvReader::from_path(csv_file_path)
.expect("Cannot open file.")
.has_header(true)
.finish()
.unwrap()
}
let titanic_file_path: &Path = Path::new("dataset/titanic.csv");
let titanic_df: DataFrame = read_data_frame_from_csv(titanic_file_path);
查看数据的形状:
titanic_df.shape()
输出:
(891, 12)
DataFrame 是 polars 中的基本结构,与 Python Pandas 中的 DataFrame 相同,你可以将其视为具有每列命名标题的二维数据表格。
以下是查看数据集基本统计信息的代码示例:
titanic_df.describe(None)
输出: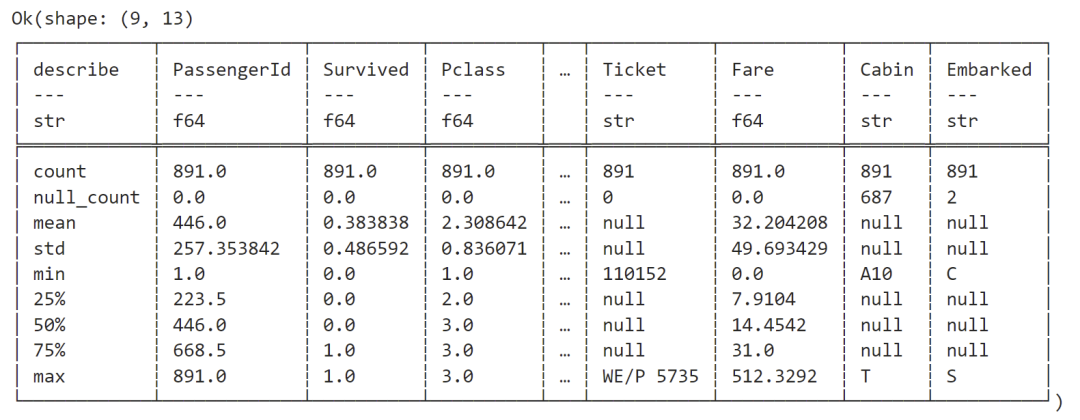
我们可以看到这个数据集中有一些空单元格。
以下是查看数据集前 5 行的代码示例:
titanic_df.head(Some(5))
输出:
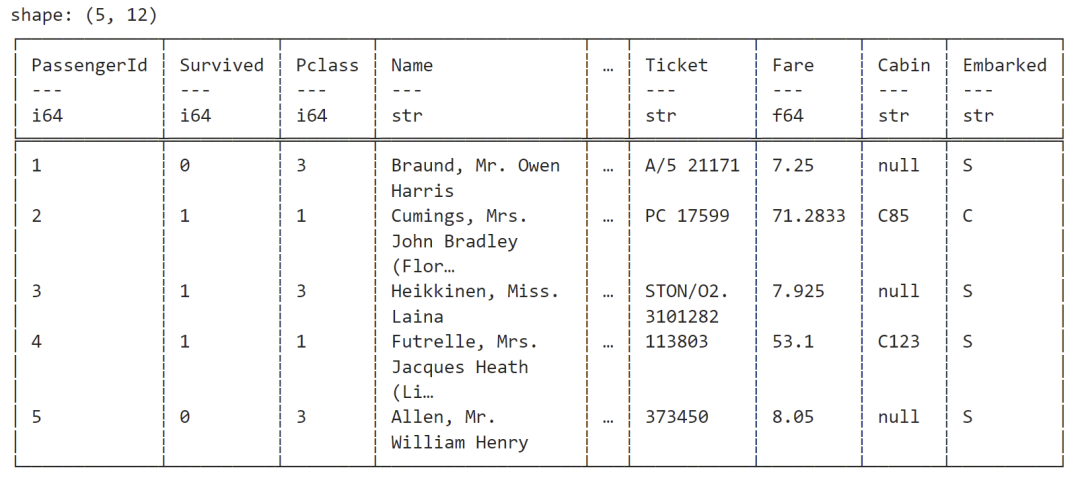
如果你想查看数据集中的列名,请使用 .schema() 方法。以下是代码示例:
titanic_df.schema()
输出:
Schema:
name: PassengerId, data type: Int64
name: Survived, data type: Int64
name: Pclass, data type: Int64
name: Name, data type: String
name: Sex, data type: String
name: Age, data type: Float64
name: SibSp, data type: Int64
name: Parch, data type: Int64
name: Ticket, data type: String
name: Fare, data type: Float64
name: Cabin, data type: String
name: Embarked, data type: String
使用以下代码来查看泰坦尼克号数据集中幸存者:
titanic_df["Survived"].value_counts(true, true)
输出:
Ok(shape: (2, 2)
┌──────────┬───────┐
│ Survived ┆ count │
│ --- ┆ --- │
│ i64 ┆ u32 │
╞══════════╪═══════╡
│ 0 ┆ 549 │
│ 1 ┆ 342 │
└──────────┴───────┘)
查看泰坦尼克号数据集中的性别分布:
titanic_df["Sex"].value_counts(true, true)
输出:
Ok(shape: (2, 2)
┌────────┬────────┐
│ Sex ┆ counts │
│ --- ┆ --- │
│ str ┆ u32 │
╞════════╪════════╡
│ male ┆ 577 │
│ female ┆ 314 │
└────────┴────────┘)
你可以在 titanic_df DataFrame 上继续进行更复杂的 EDA(探索性数据分析)。
使用Plotters对数据可视化
接下来,我们可以使用 plotters crate 来可视化我们的输出数据。以下是导入 plotters crate 的符号:
use plotters::*;
画一个柱状图:
evcxr_figure((640, 480), |root| {
let drawing_area = root;
drawing_area.fill(&WHITE).unwrap();
let mut chart_context = ChartBuilder::on(&drawing_area)
.caption("Titanic Dataset", ("Arial", 30).into_font())
.x_label_area_size(40)
.y_label_area_size(40)
.build_cartesian_2d((0..1).into_segmented(), 0..800)?;
chart_context.configure_mesh()
.x_desc("Survived?")
.y_desc("Number").draw()?;
let data_s: DataFrame = titanic_df["Survived"].value_counts(true, true).unwrap().select(vec!["counts"]).unwrap();
let mut data_source = data_s.to_ndarray::(IndexOrder::Fortran).unwrap().into_raw_vec().into_iter();
chart_context.draw_series((0..).zip(data_source).map(|(x, y)| {
let x0 = SegmentValue::Exact(x);
let x1 = SegmentValue::Exact(x + 1);
let mut bar = Rectangle::new([(x0, 0), (x1, y)], BLUE.filled());
bar.set_margin(0, 0, 30, 30);
bar
}))
.unwrap();
Ok(())
}).style("width:60%")
显示: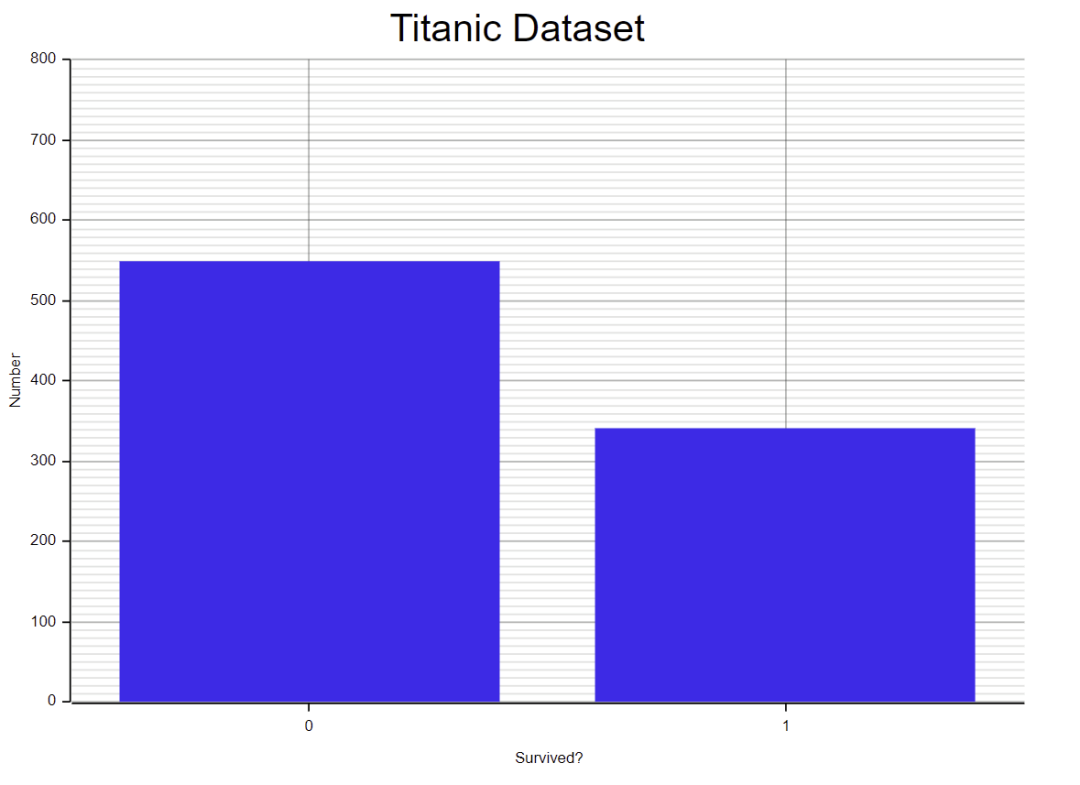
这段代码看起来有些冗长和繁琐,以后最好在 plotters 中封装一个简单的 API 。现在的核心问题是 1. 配置项过多,2. 类型转换复杂。
Plotters 支持各种图形、绘图和图表,你可以将 plotters 视为 Rust 生态系统中 Python matplotlib 的对应物,但它要赶上 matplotlib 的易用性,还有不小的差距。
有关 plotters 的更多信息,请访问:https://docs.rs/plotters/latest/plotters/
接下来,我们将介绍矩阵操作库 ndarray。
使用Ndarray操作矩阵
DataFrame 有一个方法可以将自身转换为 Ndarray 的多维矩阵。例如:
let a = UInt32Chunked::new("a", &[1, 2, 3]).into_series();
let b = Float64Chunked::new("b", &[10., 8., 6.]).into_series();
let df = DataFrame::new(vec![a, b]).unwrap();
let ndarray = df.to_ndarray::(IndexOrder::Fortran).unwrap();
println!("{:?}", ndarray);
将输出:
[[1.0, 10.0],
[2.0, 8.0],
[3.0, 6.0]], shape=[3, 2], strides=[1, 3], layout=Ff (0xa), const ndim=2
我们可以使用 ndarray crate 来进行复杂的矩阵操作。
导入 ndarray crate 的符号:
use ndarray::*;
创建一个 2x3 矩阵:
array![[1.,2.,3.], [4.,5.,6.]]
输出:
[[1.0, 2.0, 3.0],
[4.0, 5.0, 6.0]], shape=[2, 3], strides=[3, 1], layout=Cc (0x5), const ndim=2
创建一个范围:
Array::range(0., 10., 0.5)
输出:
[0.0, 0.5, 1.0, 1.5, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5, 5.0, 5.5, 6.0, 6.5, 7.0, 7.5, 8.0, 8.5, 9.0, 9.5], shape=[20], strides=[1], layout=CFcf (0xf), const ndim=1
创建一个具有指定相等间隔的范围:
Array::linspace(0., 10., 18)
输出:
[0.0, 0.5882352941176471, 1.1764705882352942, 1.7647058823529411, 2.3529411764705883, 2.9411764705882355, 3.5294117647058822, 4.11764705882353, 4.705882352941177, 5.294117647058823, 5.882352941176471, 6.470588235294118, 7.0588235294117645, 7.647058823529412, 8.23529411764706, 8.823529411764707, 9.411764705882353, 10.0], shape=[18], strides=[1], layout=CFcf (0xf), const ndim=1
以下是创建一个 3x4x5 矩阵(也称为机器学习中的“张量”)的代码示例:
Array::::ones((3, 4, 5))
输出:
[[[1.0, 1.0, 1.0, 1.0, 1.0],
[1.0, 1.0, 1.0, 1.0, 1.0],
[1.0, 1.0, 1.0, 1.0, 1.0],
[1.0, 1.0, 1.0, 1.0, 1.0]],
[[1.0, 1.0, 1.0, 1.0, 1.0],
[1.0, 1.0, 1.0, 1.0, 1.0],
[1.0, 1.0, 1.0, 1.0, 1.0],
[1.0, 1.0, 1.0, 1.0, 1.0]],
[[1.0, 1.0, 1.0, 1.0, 1.0],
[1.0, 1.0, 1.0, 1.0, 1.0],
[1.0, 1.0, 1.0, 1.0, 1.0],
[1.0, 1.0, 1.0, 1.0, 1.0]]], shape=[3, 4, 5], strides=[20, 5, 1], layout=Cc (0x5), const ndim=3
以下是创建一个零值初始矩阵的代码示例:
Array::::zeros((3, 4, 5))
输出:
[[[0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0]],
[[0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0]],
[[0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0]]], shape=[3, 4, 5], strides=[20, 5, 1], layout=Cc (0x5), const ndim=3
对行和列求和
let arr = array![[1.,2.,3.], [4.,5.,6.]];
按行求和
arr.sum_axis(Axis(0))
输出:
[5.0, 7.0, 9.0], shape=[3], strides=[1], layout=CFcf (0xf), const ndim=1
按列求和:
arr.sum_axis(Axis(1))
输出:
[6.0, 15.0], shape=[2], strides=[1], layout=CFcf (0xf), const ndim=1
所有元素求和:
arr.sum()
输出:
21.0
矩阵转置:
arr.t()
输出:
[[1.0, 4.0],
[2.0, 5.0],
[3.0, 6.0]], shape=[3, 2], strides=[1, 3], layout=Ff (0xa), const ndim=2
求点积:
arr.dot(&arr.t())
输出:
[[14.0, 32.0],
[32.0, 77.0]], shape=[2, 2], strides=[2, 1], layout=Cc (0x5), const ndim=2
求方根:
arr.mapv(f64::sqrt)
输出:
[[1.0, 1.4142135623730951, 1.7320508075688772],
[2.0, 2.23606797749979, 2.449489742783178]], shape=[2, 3], strides=[3, 1], layout=Cc (0x5), const ndim=2
矩阵操作暂时演示到这里。ndarray 是一个非常强大的工具,你可以使用它来执行与矩阵和线性代数相关的任何任务。
回顾
在本文中,我演示了如何使用 Jupyter 交互式地学习 Rust。Jupyter 是数据科学家(或学生)的超级工具,我们现在可以使用 Rust 在 Jupyter 中完成探索性数据分析任务。Polars、plotters 和 ndarray 是强大的工具集,可以帮助我们处理数据分析和数据预处理工作,这是后续机器学习任务的先决条件。
-
请问OpenVINO™ 是否支持 Rust 绑定?2025-06-25 399
-
从Rustup出发看Rust编译生态2024-01-02 1827
-
Rust GUI实践之Rust-Qt模块2023-09-30 3120
-
谷歌程序员认为学习Rust很easy2023-07-03 1114
-
Rust的内部工作原理2023-06-14 1595
-
在Rust代码中加载静态库时,出现错误 ` rust-lld: error: undefined symbol: malloc `怎么解决?2023-06-09 1082
-
rust语言基础学习: 智能指针之Cow2023-05-22 4411
-
Chromium正式开始支持Rust2023-01-14 1645
-
以调试Rust的方式来学习Rust2023-01-03 1703
-
如何利用C语言去调用rust静态库呢2022-06-21 3700
-
rust-av基于rust的多媒体工具包2022-06-01 630
-
rust-analyzer Rust编译器前端实现2022-05-19 1171
-
怎样去使用Rust进行嵌入式编程呢2021-12-22 1652
-
只会用Python?教你在树莓派上开始使用Rust2020-05-20 4010
全部0条评论

快来发表一下你的评论吧 !
