

深度解析大语言模型的位置编码及其外推性
人工智能
描述
现在,众多大型模型已开始支持长文本的推理,如最新的 GPT4 Turbo 能处理超过 128k 的内容,而 Baichuan2 也可应对最长为 192K 的文本。但受显存资源约束,这些模型在训练时并不一定会处理如此长的文本,其预训练阶段通常仅涉及约 4k 的内容。 因此,如何在推理阶段确保模型能处理远超预训练时的文本长度,已成为当前大型模型面临的核心问题之一,我们将此问题视为大模型的外推性挑战。 而为了应对这个挑战,最关键的地方就是如何优化大模型的位置编码。在之前的文章十分钟读懂旋转编码(RoPE)中,我们已经介绍了目前应用最广的旋转位置编码 RoPE。
然而,那篇文章并未涉及 RoPE 在外推性方面的表现以及如何优化其外推性。恰好最近,我们组的同事在论文分享中进一步探讨了大模型位置编码的相关内容,其中包含一些我之前未曾接触的新观点。因此,本文旨在更全面地介绍位置编码及其与外推性的关系。 我们主要围绕以下两个问题展开: 1. RoPE 是如何实现相对位置编码的?(如何想到的?) 2. 如何通过调整旋转角(旋转角 ),提升外推效果。
本文主要有以下几个结论: 1. 虽然 RoPE 理论上可以编码任意长度的绝对位置信息,但是实验发现 RoPE 仍然存在外推问题,即测试长度超过训练长度之后,模型的效果会有显著的崩坏,具体表现为困惑度(Perplexity,PPL)等指标显著上升。 2. RoPE 做了线性内插(缩放位置索引,将位置 m 修改为 m/k)修改后,通常都需要微调训练。 3. 虽然外推方案也可以微调,但是内插方案微调所需要的步数要少得多。 4. NTK-Aware Scaled RoPE 非线性内插,是对 base 进行修改(base 变成 )。
5. NTK-Aware Scaled RoPE 在不微调的情况下,就能取得不错的外推效果。(训练 2048 长度的文本,就能在较低 PPL 情况下,外推 8k 左右的长文本) 6. RoPE 的构造可以视为一种 进制编码,在这个视角之下,NTK-aware Scaled RoPE 可以理解为对进制编码的不同扩增方式(扩大 k 倍表示范围 L->k*L,那么原本 RoPE 的 β 进制至少要扩大成 进制)。
绝对位置编码
我们先来回顾一下绝对位置编码的问题。绝对位置编码通过可学习的 Positional Embedding 来编码位置信息,这种方案直接对不同的位置随机初始化一个 postion embedding,然后与 word embedding 相加后输入模型。postion embedding 作为模型参数的一部分,在训练过程中进行更新。比如下面是绝对位置编码的实现:
# 初始化
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
# 计算
position_embeddings = self.position_embeddings(position_ids)
embeddings += position_embeddings
对绝对位置编码进行可视化,如下图所示:

▲ 图1-1 绝对位置编码可视化 可以看到每个位置都会被区分开,并且相邻的位置比较接近。这个方案的问题也非常明显,不具备外推的性质。长度在预设定好之后就被固定了。
正弦编码(Sinusoidal)
基于 Sinusoidal 的位置编码最初是由谷歌在论文 Attention is All You Need 中提出的方案,用于 Transformer 的位置编码。具体计算方式如下所示: 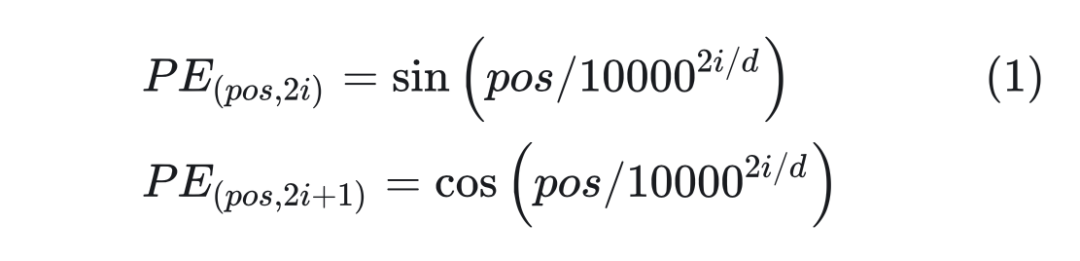 其中 pos 是位置,i 表示维度。 看起来是通过 sin 和cos函数将位置编码的取值固定在了 [-1, 1] 之前,但是为什么不用线性函数?而且这里面的10000是怎么想到的? 谷歌在论文里面给出了解释:
其中 pos 是位置,i 表示维度。 看起来是通过 sin 和cos函数将位置编码的取值固定在了 [-1, 1] 之前,但是为什么不用线性函数?而且这里面的10000是怎么想到的? 谷歌在论文里面给出了解释:
具有相对位置表达能力:Sinusoidal 可以学习到相对位置,对于固定位置距离的 k,PE(i+k) 可以表示成 PE(i) 的线性函数。
两个位置向量的内积只和相对位置 k 有关。
Sinusoidal 编码具有对称性。
随着 k 的增加,内积的结果会直接减少,即会存在远程衰减。
下面我们来分析一下为什么会有上面四点结论。
2.1 相对位置表达能力
Sinusoidal 可以学习到相对位置,对于固定位置距离的 k,PE(i+k) 可以表示成 PE(i) 的线性函数。证明如下:
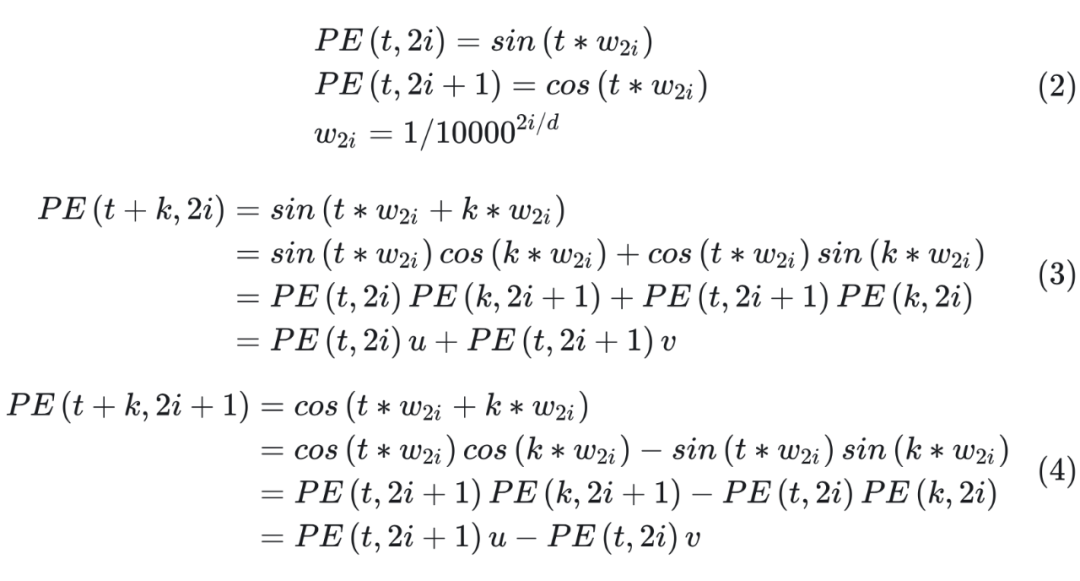
其中 u, v 为关于 k 的常数,所以可以证明 PE(i+k) 可以由 PE(i) 线性表示。
2.2 内积只和相对位置k有关
Attention 中的重要操作就是内积。计算两个位置的内积 PE(t+k)PE(t) 如下所示:
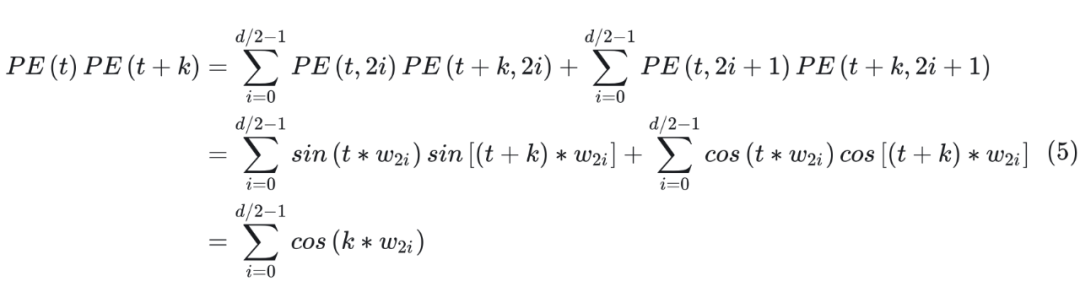
可以看到,最终的结果是关于 k 的一个常数。这表明两个位置向量的内积只和相对位置 k 有关。 通过计算,很容易得到 PE(t+k)PE(t) = PE(t)PE(t-k),这表明 Sinusoidal 编码具有对称性。
2.3 远程衰减
可以发现,随着 k 的增加,位置向量的内积结果会逐渐降低,即会存在远程衰减。如下图所示:
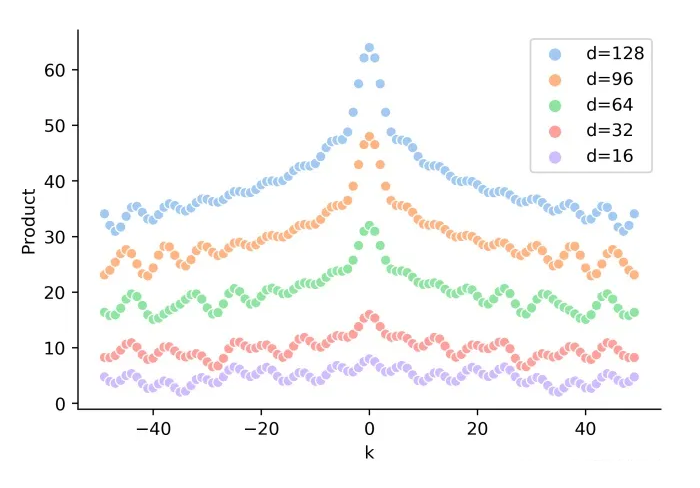
▲ 图2-1 随着相对距离 k 的增加,位置向量内积 PE(t)PE(t+k) 逐渐降低
2.4 为什么选择参数base=10000
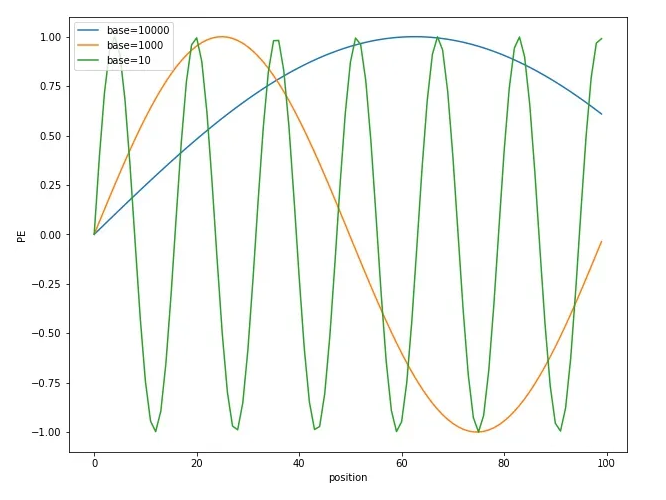
选择 sin,cos 是因为可以表达相对位置,以及具备远程衰减。但是 sin/cos 里面的参数 10000 是如何来的? 这里可以从 sin/cos 的周期性角度进行分析。分析周期可以发现,维度i的周期为 ,其中 0<=i
▲ 图2-2 不同 base 下的 position embedding 取值 可以看到随着 base 的变大,周期会明显变长。Transformer 选择比较大的 base=10000,可能是为了能更好的区分开每个位置。 备注:解释下为什么周期大能更好区分位置 从图 2-2 可以看出,base 越大,周期越大。而周期越大,在 position 从 0~100 范围内,只覆盖了不到半个周期,这使得重复值少;而周期小的,覆盖了多个周期,就导致不同位置有大量重复的值。
2.5 正弦编码是否真的具备外推性?
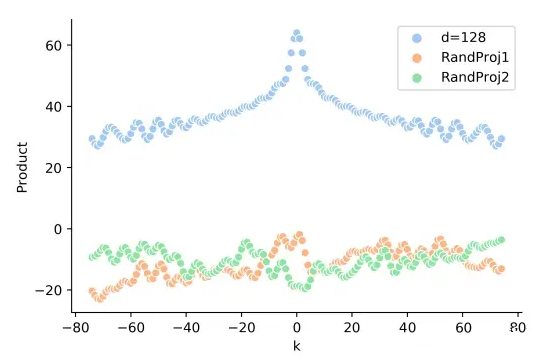
在前面的图 2-1 中,似乎 Sinusoidal 只和相对位置有关。但是实际的 Attention 计算中还需要与 attention 的权重 W 相乘,即 ,这时候内积的结果就不能反映相对距离,如下图所示:
▲ 图2-3 真实的 q,k 向量内积和相对距离之间,没有远程衰减性
旋转位置编码(RoPE)
3.1 什么是好的位置编码
既然前面的绝对位置编码和 Sinusoidal 编码都不是好的位置编码,那么什么才是好的位置编码? 理想情况下,一个好的位置编码应该满足以下条件:
每个位置输出一个唯一的编码
具备良好的外推性
任何位置之间的相对距离在不同长度的句子中应该是一致的
这两条比较好理解,最后一条是指如果两个 token 在句子 1 中的相对距离为 k,在句子 2 中的相对距离也是 k,那么这两个句子中,两个 token 之间的相关性应该是一致的,也就是 attention_sample1 (token1, token2) = attention_sample2 (token1, token2)。
▲ 图3-1 平移性 而 RoPE 正是为了解决上面三个问题而提出的。
3.2 RoPE如何解决内积只和相对位置有关
RoPE 旋转位置编码是苏神在论文 RoFormer 中提出的,也是目前大模型广泛采用的一种位置编码方式。这种编码不是作用在 embedding 的输入层,而是作用在与 Attention 的计算中。 假设位置 m 的位置编码为 ,位置 n 的位置编码为 ,如果使用之前的绝对位置编码方式,那么两个位置之间的 attention 可以表示为:
其中 表示位置 m 的旋转矩阵。 将 d=2 扩展到多维,旋转矩阵表示如下:
▲ 图3-2 为什么 RoPE 选择 方式进行位置编码
3.3 RoPE的远程衰减
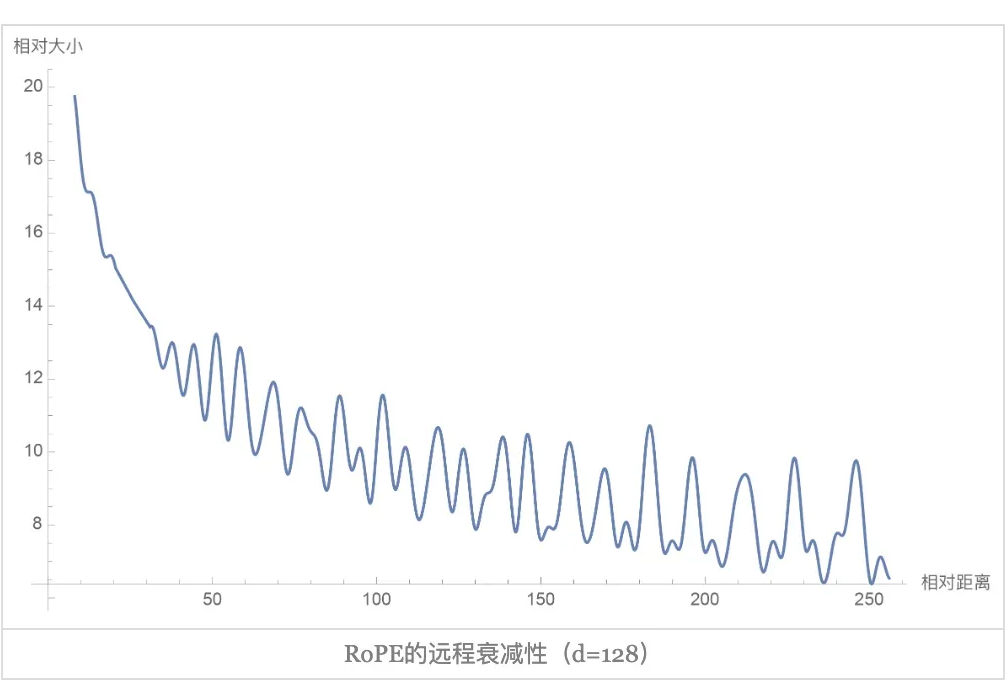
▲ 图3-3 RoPE 的远程衰减 从图中我们可以看到随着相对距离的变大,内积结果有衰减趋势的出现。因此,选择 ,确实能带来一定的远程衰减性。论文中还试过以 为初始化,将 视为可训练参数,然后训练一段时间后发现 并没有显著更新,因此干脆就直接固定 了。
调整旋转角提升外推效果
虽然 RoPE 理论上可以编码任意长度的绝对位置信息,并且 sin/cos 计算就能将任意长度的相对位置信息表达出来,但是实验发现 RoPE 仍然存在外推问题,即测试长度超过训练长度之后,模型的效果会有显著的崩坏,具体表现为困惑度(Perplexity,PPL)等指标显著上升。 对此,就有很多人提出了如何扩展 LLM 的 Context 长度,比如有人实验了“位置线性内插”的方案,显示通过非常少的长文本微调,就可以让已有的 LLM 处理长文本。 几乎同时,Meta 也提出了同样的思路,在论文 Extending Context Window of Large Language Models via Positional Interpolation 中提出了位置线性内插(Position Interpolation,PI)。 随后,又有人提出了 NTK-aware Scaled RoPE,实现了不用微调就可以扩展 Context 长度的效果。 从 Sinusoidal 编码到旋转位置编码 RoPE, 的取值一直都是 ,也就是base = 10000。而最新的位置线性内插和 NTK 都打破了这一传统。
4.1 位置线性内插(Position Interpolation,PI)
传统的 RoPE 算法在超出最大距离后,PPL 就会爆炸,因此直接推广的效果一定是很差的,因此 Position Interpolation 绕过了推广的限制,通过内插的方法,如下图所示。
▲ 图4-1 RoPE 位置线性内插(base 和位置线性内插的效果对比)
图 4-1 是关于“位置线性内插(Position Interpolation)”方法的图示说明。对于预训练 2048 长度,外推 4096 长度: 左上角图示:
这部分是 LLM 预训练的长度。
蓝色点代表输入的位置索引,它们都在 0 到 2048 的范围内,即预训练范围内。
这意味着给模型提供的输入序列长度没有超过它预训练时的最大长度。
右上角图示:
这部分展示了所谓的“长度外推”(Extrapolation)情况。
在这种情况下,模型被要求处理位置索引超出 2048 的情况,直到 4096(由红色点表示)。
这些位置对于模型来说是“未见过的”,因为在预训练时它们并没有涉及。
当模型遇到这种更长的输入序列时,其性能可能会受到影响,因为它没有被优化来处理这种情况。
左下角图示:
这部分展示了“位置线性内插”方法的应用。
为了解决模型处理更长序列时的问题,研究者们提出了一个策略:将位置索引本身进行下采样或缩放。
具体来说,他们将原本在 [0, 4096] 范围内索引(由蓝色和绿色点表示)缩放到 [0, 2048] 的范围内。
通过这种方式,所有的位置索引都被映射回了模型预训练时的范围内,从而帮助模型更好地处理这些原本超出其处理能力的输入序列。
我们再举一个例子,base=10000,d=2048,对于 token embedding 第 2000 维,RoPE 为:
base = 10000
由于 ,因此相当于是扩大了 base,缩小了 。 从小到大对应低频到高频的不同特征(周期 ,频率 )。 下面是实验结果:
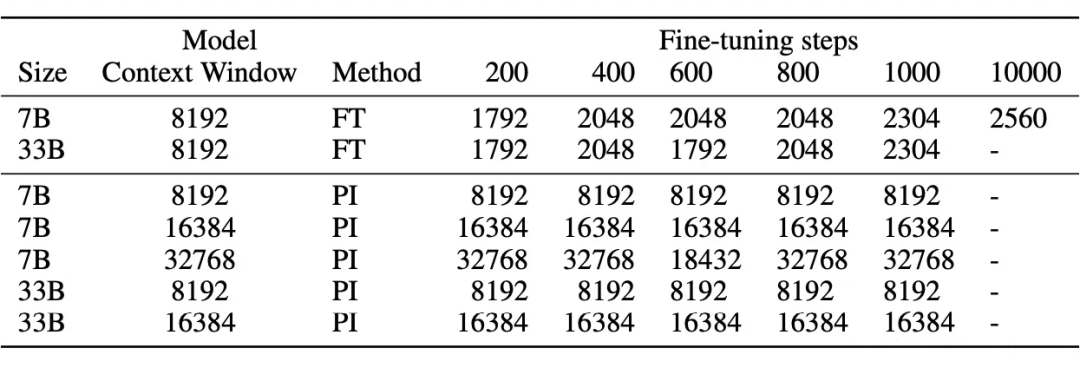
▲ 图4-3 微调少量长文本,位置线性内插就能推理长文本 从图 4-2 可以看出,使用 10000 条样本,直接进行微调长度为 8192 的文本,外推长度只能到 2560;而只用 1000 条样本,在微调中使用位置线性内插,外推长度就可以达到 8192。
4.2 NTK-Aware Scaled RoPE
位置线性内插虽然效果不错,但是插值方法是线性的,这种方法在处理相近的 token 时可能无法准确区分它们的顺序和位置。因此,研究者提出了一种非线性的插值方案,它改变 RoPE 的 base 而不是比例,从而改变每个 RoPE 维度向量与下一个向量的“旋转”速度。 由于它不直接缩放傅里叶特征,因此即使在极端情况下(例如拉伸 100 万倍,相当于 20 亿的上下文大小),所有位置都可以完美区分。 新的方法被称为 “NTK-Aware Scaled RoPE”,它允许 LLaMA 模型在无需任何微调且困惑度降低到最小的情况下扩展上下文长度。这种方法基于 Neural Tangent Kernel(NTK)理论和 RoPE 插值进行改进。 NTK-Aware Scaled RoPE 在 LLaMA 7B(Context 大小为 2048)模型上进行了实验验证,结果表明在不需要对 4096 Context 进行微调的情况下,困惑度可以降低到非常小。 NTK-Aware Scaled RoPE 的计算非常简单,如下所示:
可以看到,公式(15)只是对 base 进行了放大,但是实验效果却非常好。为什么会取得这样的效果? 为了解开这个谜底,我们需要理解 RoPE 的构造可以视为一种 进制编码,在这个视角之下,NTK-aware Scaled RoPE 可以理解为对进制编码的不同扩增方式。
4.2.1 进制表示 假设我们有一个 1000 以内(不包含 1000)的整数 n 要作为条件输入到模型中,那么要以哪种方式比较好呢? 最朴素的想法是直接作为一维浮点向量输入,然而 0~999 这涉及到近千的跨度,对基于梯度的优化器来说并不容易优化得动。那缩放到 0~1 之间呢?也不大好,因为此时相邻的差距从 1 变成了 0.001,模型和优化器都不容易分辨相邻的数字。总的来说,基于梯度的优化器只能处理好不大不小的输入,太大太小都容易出问题。 所以,为了避免这个问题,我们还需要继续构思新的输入方式。在不知道如何让机器来处理时,我们不妨想想人是怎么处理呢。对于一个整数,比如 759,这是一个 10 进制的三位数,每位数字是 0~9。 既然我们自己都是用 10 进制来表示数字的,为什么不直接将 10 进制表示直接输入模型呢?也就是说,我们将整数n以一个三维向量 [a,b,c] 来输入,a,b,c 分别是n的百位、十位、个位。这样,我们既缩小了数字的跨度,又没有缩小相邻数字的差距,代价是增加了输入的维度——刚好,神经网络擅长处理高维数据。 如果想要进一步缩小数字的跨度,我们还可以进一步缩小进制的基数,如使用 8 进制、6 进制甚至 2 进制,代价是进一步增加输入的维度。
4.2.2 直接外推 假设我们还是用三维 10 进制表示训练了模型,模型效果还不错。然后突然来了个新需求,将 n 上限增加到 2000 以内,那么该如何处理呢? 如果还是用 10 进制表示的向量输入到模型,那么此时的输入就是一个四维向量了。然而,原本的模型是针对三维向量设计和训练的,所以新增一个维度后,模型就无法处理了。有一种方法是提前预留好足够多的维度,训练阶段设为 0,推理阶段直接改为其他数字,这就是外推(Extrapolation)。
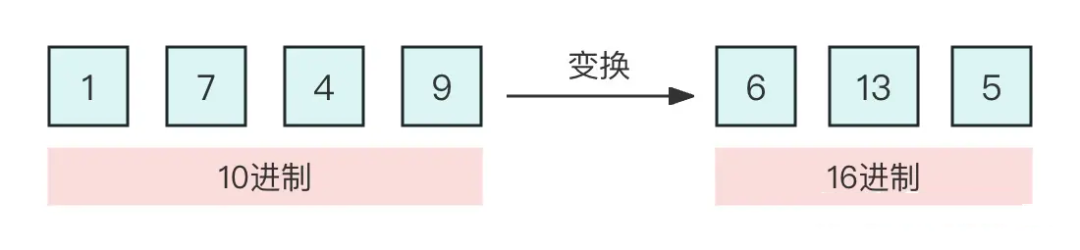
▲ 位置线性内插 当然,外推方案也可以微调,但是内插方案微调所需要的步数要少得多,因为很多场景(比如位置编码)下,相对大小(或许说序信息)更加重要,换句话说模型只需要知道 874.5 比 874 大就行了,不需要知道它实际代表什么多大的数字。而原本模型已经学会了 875 比 874 大,加之模型本身有一定的泛化能力,所以再多学一个 874.5 比 874 大不会太难。 不过,内插方案也不尽完美,当处理范围进一步增大时,相邻差异则更小,并且这个相邻差异变小集中在个位数,剩下的百位、十位,还是保留了相邻差异为 1。换句话说,内插方法使得不同维度的分布情况不一样,每个维度变得不对等起来,模型进一步学习难度也更大。 4.2.4 进制转换 有没有不用新增维度,又能保持相邻差距的方案呢? 有,就是进制转换。三个数字的 10 进制编码可以表示 0~999,如果是 16 进制呢?它最大可以表示 。所以,只需要转到 16 进制,如 1749 变为 [6,13,5],那么三维向量就可以覆盖目标范围,代价是每个维度的数字从 0~9 变为 0~15。
▲ 图4-5 进制转换 刚才说到,我们关心的场景主要利用序信息,原来训练好的模型已经学会了 875 > 874,而在 16 进制下同样有 875 > 874,比较规则是一模一样的(模型根本不知道你输入的是多少进制)。 唯一担心的是每个维度超过 9 之后(10~15)模型还能不能正常比较,但事实上一般模型也有一定的泛化能力,所以每个维度稍微往外推一些是没问题的。所以,这个转换进制的思路,甚至可能不微调原来模型也有效!另外,为了进一步缩窄外推范围,我们还可以换用更小的 进制而不是 16 进制。 接下来我们将会看到,这个进制转换的思想,实际上就对应着前面的 NTK-aware scaled RoPE。 4.2.5 位置编码 为了建立起它们的联系,我们先要建立如下结果:
位置 n 的旋转位置编码(RoPE),本质上就是数字 n 的 β 进制编码
看上去可能让人意外,因为两者表面上迥然不同。但事实上,两者的运算有着相同的关键性质。为了理解这一点,我们首先回忆一个 10 进制的数字 n,我们想要求它的 β 进制表示的(从右往左数)第 m 位数字,方法是:
对比公式(16)和(17),两者都有相同的 ,并且 mod,cos,sin 都是周期函数。所以,除掉取整函数这个无关紧要的差异外,RoPE/Sinusoidal 位置编码类比为位置 n 的 进制编码。 建立起这个联系后,直接外推方案就是啥也不改,位置线性内插就是将 n 换成 n/k,其中 k 是要扩大的倍数,这就是 Meta 的论文所实验的 Positional Interpolation,里边的实验结果也证明了外推比内插确实需要更多的微调步数。 至于进制转换,就是要扩大 k 倍表示范围,那么原本的 β 进制至少要扩大成 进制(公式(17)虽然是 d 维向量,但 cos,sin 是成对出现的,所以相当于 d/2 位 进制表示,因此要开 d/2 次方而不是 d 次方),或者等价地原来的底数 10000 换成 10000k,这基本上就是 NTK-aware Scaled RoPE。 跟前面讨论的一样,由于位置编码更依赖于序信息,而进制转换基本不改变序的比较规则,所以 NTK-aware Scaled RoPE 在不微调的情况下,也能在更长 Context 上取得不错的效果。 4.2.6 NTK-Aware Scaled RoPE和RoPE β进制的关系 所以,这跟 NTK 有什么关系呢?NTK 全称是 “Neural Tangent Kernel”,具体原理可以参考《从动力学角度看优化算法:SGD ≈ SVM?》。 要说上述结果跟 NTK 的关系,更多的是提出者的学术背景缘故,提出者对《Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains》等结果比较熟悉,里边利用 NTK 相关结果证明了神经网络无法直接学习高频信号,解决办法是要将它转化为 Fourier 特征——其形式就跟公式(17)的 Sinusoidal 位置编码差不多。 所以,提出者基于 NTK 相关结果的直觉,推导了 NTK-aware Scaled RoPE。假设要扩大 k 倍范围表示,根据 NTK-Aware Scaled RoPE,高频外推、低频内插。具体来说,公式(17)最低频是 ,引入参数 变为 ,让他与内插一致,即:
▲ 图4-6 不同插值方法的效果(这里的 scale 是指位置插值中扩大的倍数 k,alpha 是指 NTK 中的 lambda 参数或者是公式(15)中的 alpha 参数)
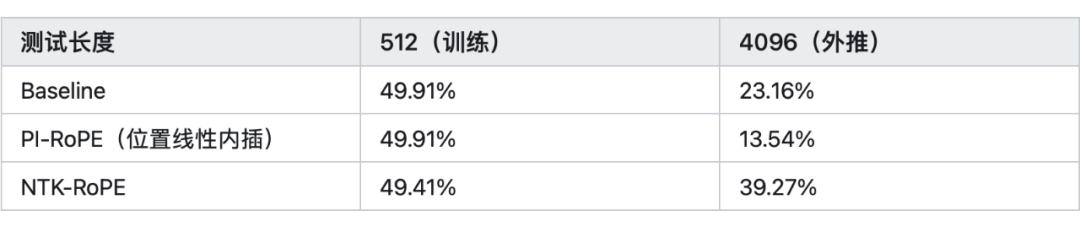
从图中可以看出在 时,NTK 可以在比较小的 PPL 情况下,外推 8k 左右的长文本。 再看一下苏神的实验结论(表中的数据表示准确率),当 k=8 时,结论如下:
上面的结论是没有经过长文本微调的结果,其中 Baseline 就是外推,PI(Positional Interpolation)就是 Baseline 基础上改内插,NTK-RoPE 就是 Baseline 基础上改 NTK-aware Scaled RoPE。 从表中我们得出以下结论:
1、直接外推的效果不大行
2、内插如果不微调,效果也很差
3、NTK-RoPE 不微调就取得了不错的外推结果
总结
目前大模型处理长文本的能力成为研究的热点,由于收集长文本的语料非常的困难,因此如何不用微调或者少量微调,就能外推 k 倍的长文本,成为大家的关注的焦点。 本文详细介绍了 Meta 的位置线性内插和 NTK 两种优化外推的方法,结合苏神对 RoPE 解释为一种 进制编码,那么位置线性内插和 NTK 都可以理解为对进制编码的不同扩增方式。
审核编辑:黄飞

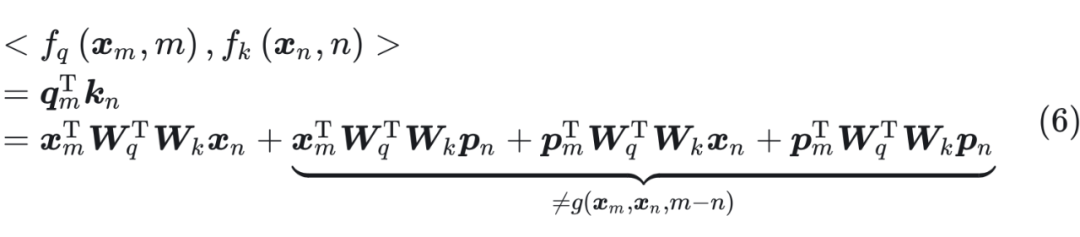 后面的三项都是和绝对位置位置 m,n 有关,无法表示成 m-n 的形式。 因此,我们需要找到一种位置编码,使得公式(6)表示为如下的形式:
后面的三项都是和绝对位置位置 m,n 有关,无法表示成 m-n 的形式。 因此,我们需要找到一种位置编码,使得公式(6)表示为如下的形式: 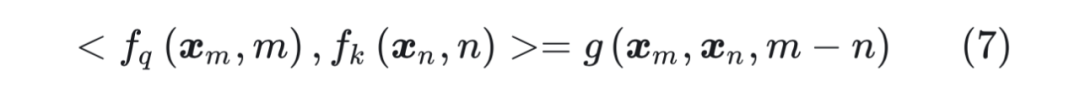 接下来的目标就是找到一个等价的位置编码方式,从而使得上述关系成立。 假定现在词嵌入向量的维度是两维 d=2,这样就可以利用上 2 维度平面上的向量的几何性质,然后论文中提出了一个满足上述关系的 f 和 g 的形式如下:
接下来的目标就是找到一个等价的位置编码方式,从而使得上述关系成立。 假定现在词嵌入向量的维度是两维 d=2,这样就可以利用上 2 维度平面上的向量的几何性质,然后论文中提出了一个满足上述关系的 f 和 g 的形式如下: 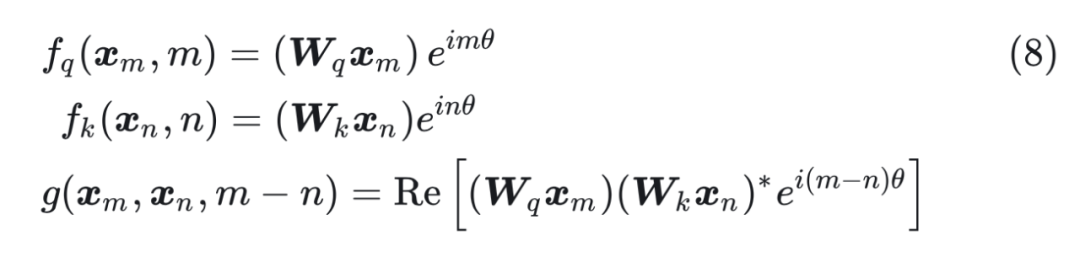 这里面 Re 表示复数的实部。 进一步地, 可以表示成下面的式子:
这里面 Re 表示复数的实部。 进一步地, 可以表示成下面的式子: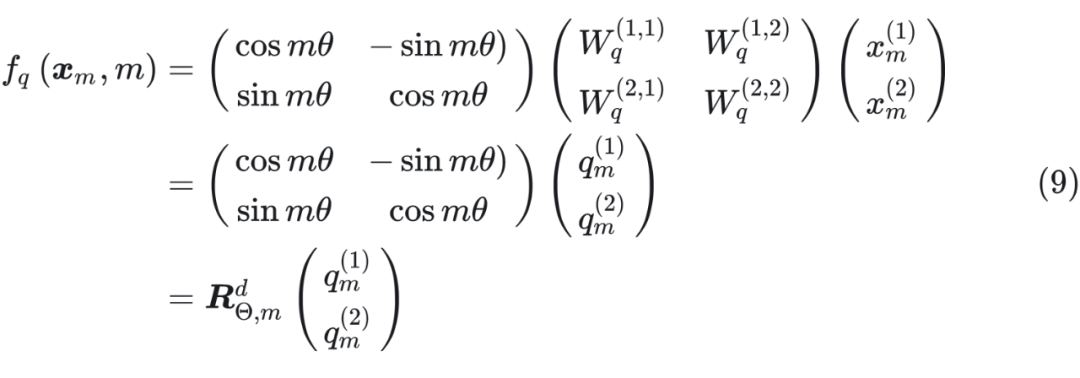
 总结来说,RoPE 的 self-attention 操作的流程是:对于 token 序列中的每个词嵌入向量,首先计算其对应的 query 和 key 向量,然后对每个 token 位置都计算对应的旋转位置编码,接着对每个 token 位置的 query 和 key 向量的元素按照两两一组应用旋转变换,最后再计算 query 和 key 之间的内积得到 self-attention 的计算结果。 RoPE 为什么会想到用 进行位置编码?来看一下苏神现身说法(相乘后可以表达成差的形式,所以可能可以实现相对位置编码):
总结来说,RoPE 的 self-attention 操作的流程是:对于 token 序列中的每个词嵌入向量,首先计算其对应的 query 和 key 向量,然后对每个 token 位置都计算对应的旋转位置编码,接着对每个 token 位置的 query 和 key 向量的元素按照两两一组应用旋转变换,最后再计算 query 和 key 之间的内积得到 self-attention 的计算结果。 RoPE 为什么会想到用 进行位置编码?来看一下苏神现身说法(相乘后可以表达成差的形式,所以可能可以实现相对位置编码):
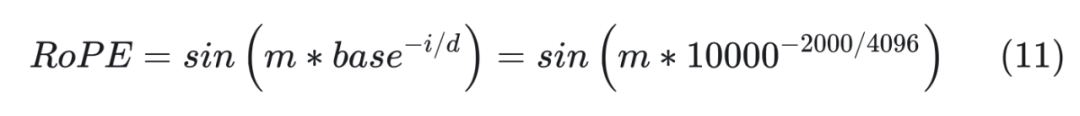
i = 2000
d = 4096
pos = list(range(1, 2049))
w = math.pow(base, -i/d)
v = np.array([math.cos(p * w) for p in pos])
index = sorted(random.sample(pos, 15))
# 绘制曲线
plt.figure(figsize=(10, 4)) # 创建一个新的图形
plt.scatter([pos[-1]], [v[-1]])
index_to_highlight = -1
# 添加注释显示坐标值
plt.annotate(f'({pos[index_to_highlight]}, {v[index_to_highlight]:.2f})',
xy=(pos[index_to_highlight], v[index_to_highlight]),
xytext=(10, -10), # 文本位置相对于注释点的偏移量
textcoords="offset points", # 文本坐标的参照系(基于点的偏移)
# arrowprops=dict(arrowstyle="-|>", connectionstyle="arc3,rad=0.2")
) # 箭头样式和连接样式
plt.plot(pos, v, '-') # 绘制第一条曲线
plt.scatter(index, v[index], color='blue', s=20, label='pre-trained RoPE') # 绘制第一条曲线
pos = list(range(2048, 4097))
w = math.pow(base, -i/d)
v = np.array([math.cos(p * w) for p in pos])
index = sorted(random.sample(pos, 15))
v_ = np.array([math.cos(p * w) for p in index])
plt.plot(pos, v, 'green') # 绘制第一条曲线
plt.scatter(index, v_, color='r', s=20, label='Extrapolation RoPE') # 绘制第一条曲线
plt.annotate(f'({pos[index_to_highlight]}, {v[index_to_highlight]:.2f})',
xy=(pos[index_to_highlight], v[index_to_highlight]),
xytext=(10, -10), # 文本位置相对于注释点的偏移量
textcoords="offset points", # 文本坐标的参照系(基于点的偏移)
# arrowprops=dict(arrowstyle="-|>", connectionstyle="arc3,rad=0.2")
) # 箭头样式和连接样式
plt.grid(axis='y')
# 添加图例
plt.legend()
# 显示图形
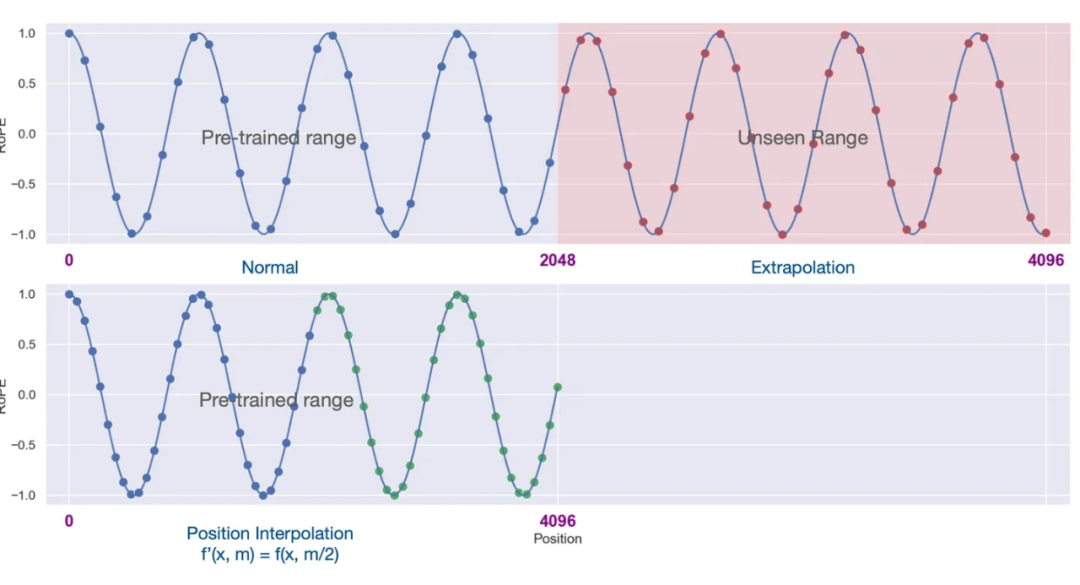
plt.show()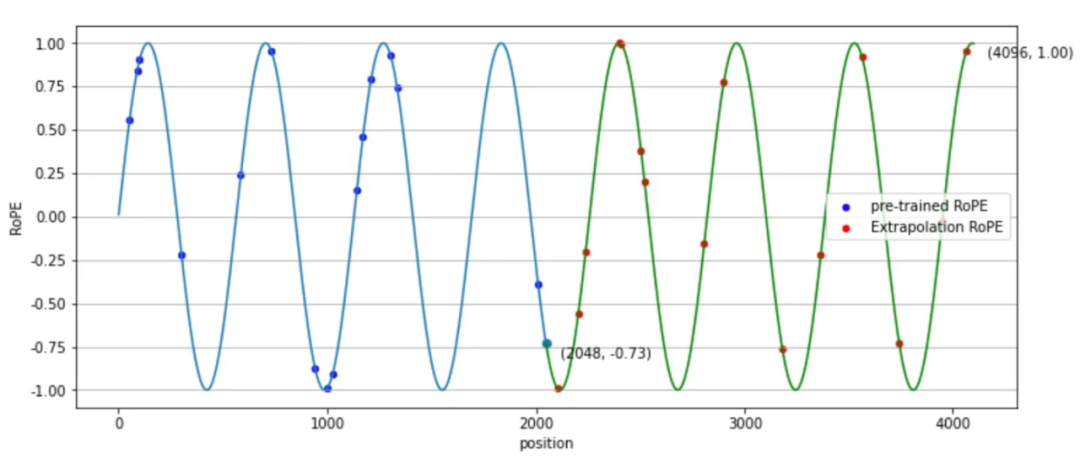 ▲ 图4-2 RoPE位置编码 从图 4-2 可以看出,在外推(Extrapolation)时,红色点超出了预训练时的位置编码。 为了解决这个问题,位置线性内插的核心思想是通过缩放位置索引,使得模型能够处理比预训练时更长的序列,而不损失太多性能。
▲ 图4-2 RoPE位置编码 从图 4-2 可以看出,在外推(Extrapolation)时,红色点超出了预训练时的位置编码。 为了解决这个问题,位置线性内插的核心思想是通过缩放位置索引,使得模型能够处理比预训练时更长的序列,而不损失太多性能。 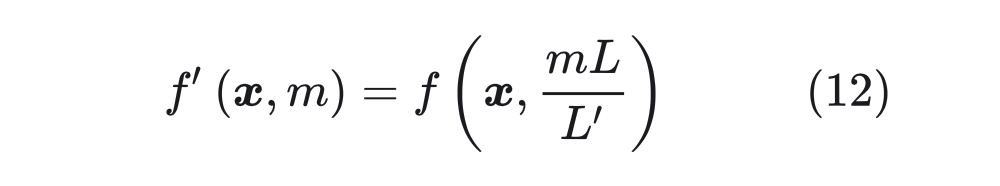 其中 x 是 token embedding,m 是位置。对于一个超过之前最大长度 L 的样本(长度为 L’),通过缩放将所有位置映射回 L 区间,每个位置都不再是整数。通过这种方式在长样本区间训练 1000 步,就能很好的应用到长样本上。 我们看一下新的位置编码后,设 ,内积可以表示为:
其中 x 是 token embedding,m 是位置。对于一个超过之前最大长度 L 的样本(长度为 L’),通过缩放将所有位置映射回 L 区间,每个位置都不再是整数。通过这种方式在长样本区间训练 1000 步,就能很好的应用到长样本上。 我们看一下新的位置编码后,设 ,内积可以表示为: 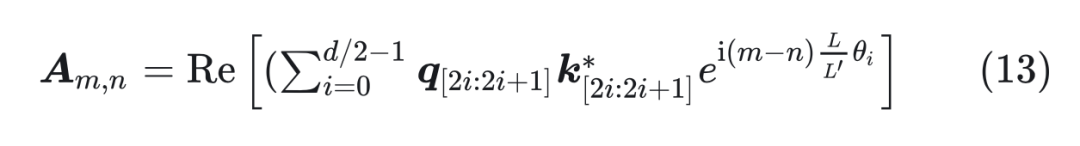 其中 可以表示为 , 中的“*”表示共轭,可以表示为 。这里面 可以改写为:
其中 可以表示为 , 中的“*”表示共轭,可以表示为 。这里面 可以改写为: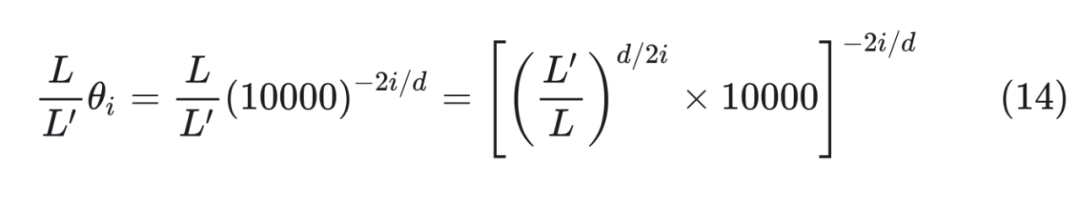
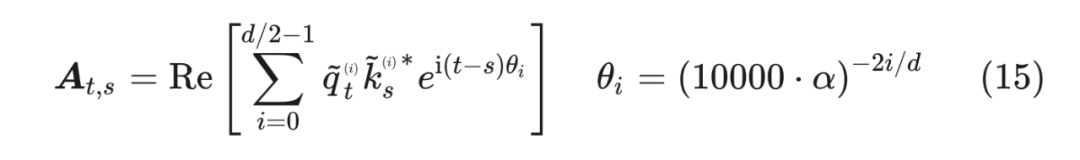
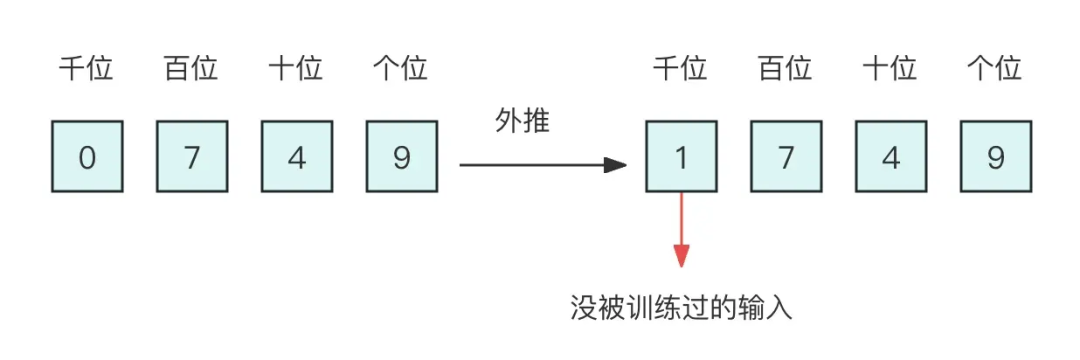 ▲ 图4-4 直接外推 然而,训练阶段预留的维度一直是 0,如果推理阶段改为其他数字,效果不见得会好,因为模型对没被训练过的情况不一定具有适应能力。也就是说,由于某些维度的训练数据不充分,所以直接进行外推通常会导致模型的性能严重下降。 4.2.3 线性内插 于是,有人想到了将外推改为内插(Interpolation),简单来说就是将 2000 以内压缩到 1000 以内,比如通过除以 2,1749 就变成了 874.5,然后转为三维向量 [8,7,4.5] 输入到原来的模型中。从绝对数值来看,新的 [7,4,9] 实际上对应的是1498,是原本对应的 2 倍,映射方式不一致;从相对数值来看,原本相邻数字的差距为 1,现在是 0.5,最后一个维度更加“拥挤”。 所以,做了内插修改后,通常都需要微调训练,以便模型重新适应拥挤的映射关系。
▲ 图4-4 直接外推 然而,训练阶段预留的维度一直是 0,如果推理阶段改为其他数字,效果不见得会好,因为模型对没被训练过的情况不一定具有适应能力。也就是说,由于某些维度的训练数据不充分,所以直接进行外推通常会导致模型的性能严重下降。 4.2.3 线性内插 于是,有人想到了将外推改为内插(Interpolation),简单来说就是将 2000 以内压缩到 1000 以内,比如通过除以 2,1749 就变成了 874.5,然后转为三维向量 [8,7,4.5] 输入到原来的模型中。从绝对数值来看,新的 [7,4,9] 实际上对应的是1498,是原本对应的 2 倍,映射方式不一致;从相对数值来看,原本相邻数字的差距为 1,现在是 0.5,最后一个维度更加“拥挤”。 所以,做了内插修改后,通常都需要微调训练,以便模型重新适应拥挤的映射关系。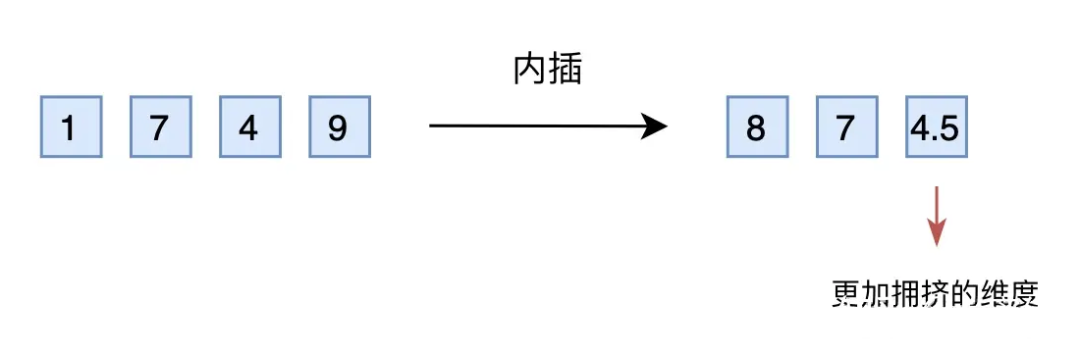
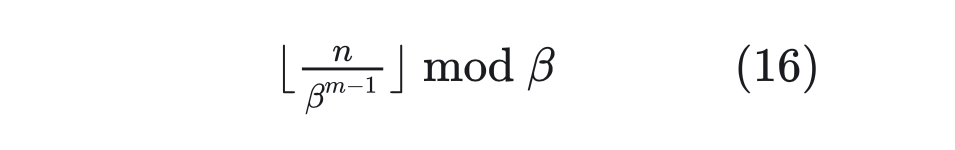 也就是先除以 次方,然后求模(余数)。然后再来回忆 RoPE,它的构造基础是 Sinusoidal 位置编码,可以改写为:
也就是先除以 次方,然后求模(余数)。然后再来回忆 RoPE,它的构造基础是 Sinusoidal 位置编码,可以改写为: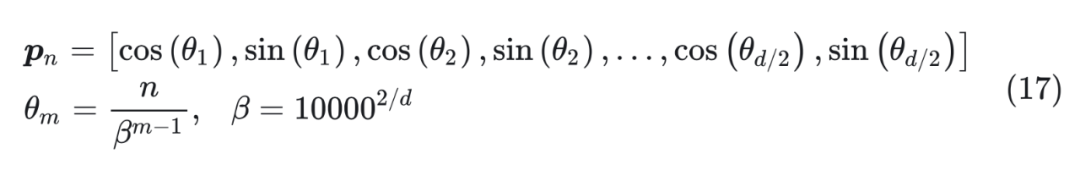
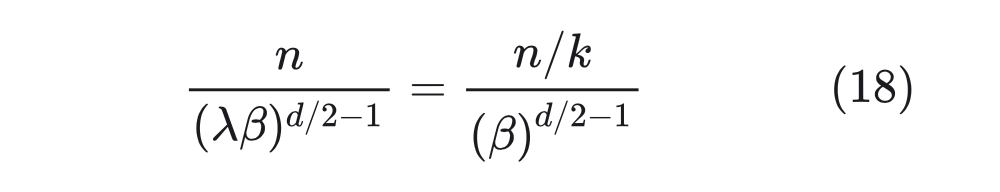 那么得到 。至于最高频是 项,引入 变为 ,由于 d 很大,,所以它还是接近于初始值 ,等价于外推。 所以这样的方案简单巧妙地将外推和内插结合了起来。另外,由于 d 比较大,因此 跟 差别不大,所以它跟前面基于进制思想提出的解 是基本一致的。还有,从提出者这个思想来看,任意能实现“高频外推、低频内插”的方案都是可以的,并非只有上述引入 的方案。 如果从前面的进制转换的角度分析,直接外推会将外推压力集中在“高位(m 较大)”上,而位置内插则会将“低位(m 较小)”的表示变得更加稠密,不利于区分相对距离。而 NTK-aware Scaled RoPE 其实就是进制转换,它将外推压力平摊到每一位上,并且保持相邻间隔不变,这些特性对明显更倾向于依赖相对位置的 LLM 来说是非常友好和关键的,所以它可以不微调也能实现一定的效果。 从公式(17)可以看出,cos,sin 事实上是一个整体,所以它实际只有 d/2 位,也就是说它相当于位置 n 的 d/2 位 进制。如果我们要扩展到 k 倍 Context,就需要将 进制转换为 进制,那么 应该满足:
那么得到 。至于最高频是 项,引入 变为 ,由于 d 很大,,所以它还是接近于初始值 ,等价于外推。 所以这样的方案简单巧妙地将外推和内插结合了起来。另外,由于 d 比较大,因此 跟 差别不大,所以它跟前面基于进制思想提出的解 是基本一致的。还有,从提出者这个思想来看,任意能实现“高频外推、低频内插”的方案都是可以的,并非只有上述引入 的方案。 如果从前面的进制转换的角度分析,直接外推会将外推压力集中在“高位(m 较大)”上,而位置内插则会将“低位(m 较小)”的表示变得更加稠密,不利于区分相对距离。而 NTK-aware Scaled RoPE 其实就是进制转换,它将外推压力平摊到每一位上,并且保持相邻间隔不变,这些特性对明显更倾向于依赖相对位置的 LLM 来说是非常友好和关键的,所以它可以不微调也能实现一定的效果。 从公式(17)可以看出,cos,sin 事实上是一个整体,所以它实际只有 d/2 位,也就是说它相当于位置 n 的 d/2 位 进制。如果我们要扩展到 k 倍 Context,就需要将 进制转换为 进制,那么 应该满足: 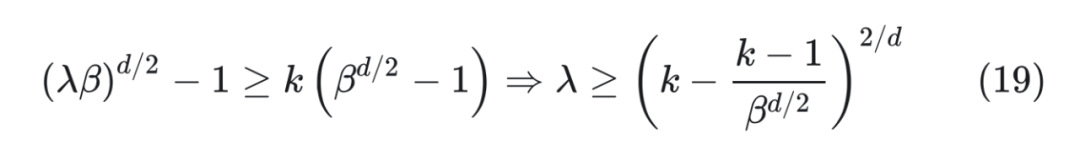 所以可以取 。 于是新的 RoPE 变为:
所以可以取 。 于是新的 RoPE 变为:  这样就从 进制的思路解释了 NTK-RoPE 的原理。 下面我们看一下位置插值和 NTK-Aware Scaled RoPE 的实验效果:
这样就从 进制的思路解释了 NTK-RoPE 的原理。 下面我们看一下位置插值和 NTK-Aware Scaled RoPE 的实验效果: 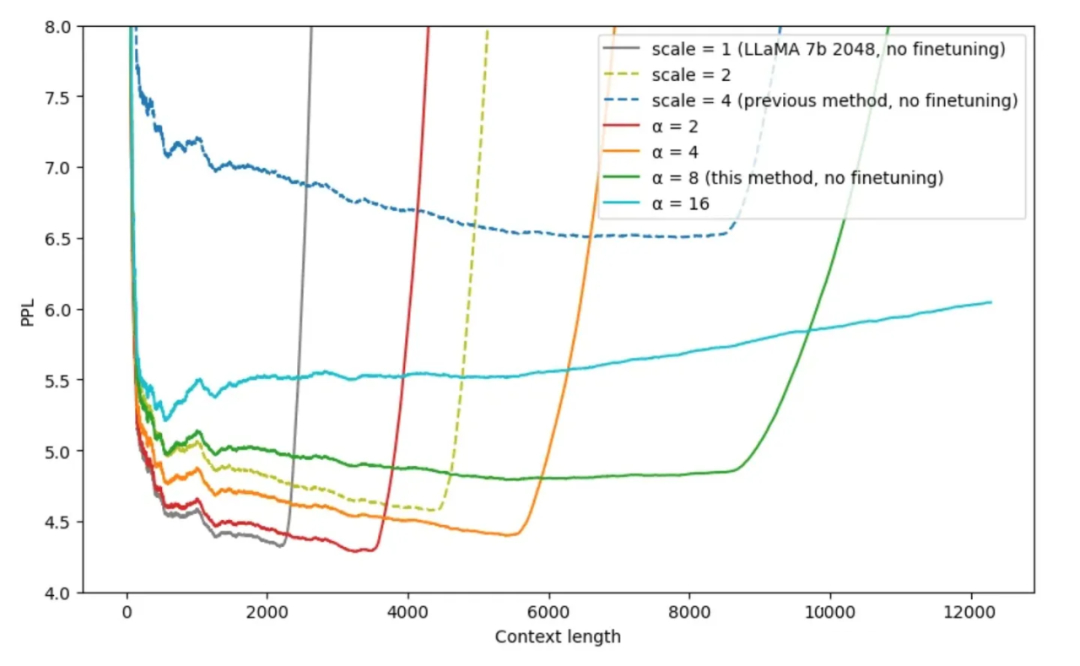
-
3万字长文!深度解析大语言模型LLM原理2025-09-02 3712
-
VLM(视觉语言模型)详细解析2025-03-17 10096
-
【《大语言模型应用指南》阅读体验】+ 基础知识学习2024-08-02 3403
-
【大语言模型:原理与工程实践】大语言模型的预训练2024-05-07 1572
-
【大语言模型:原理与工程实践】大语言模型的基础技术2024-05-05 1387
-
【大语言模型:原理与工程实践】揭开大语言模型的面纱2024-05-04 891
-
大语言模型概述2023-12-21 3475
-
C语言深度解析2023-09-28 881
-
大模型的位置编码和外推性问题一样吗2023-09-06 1447
-
大型语言模型的应用2023-07-05 3097
-
大型语言模型有哪些用途?2023-02-23 6359
-
AUTOSAR架构深度解析 精选资料推荐2021-07-28 2759
-
基于深度学习的自然语言处理对抗样本模型2021-04-20 1494
-
各类电机位置编码器及其接口的概述2018-09-05 10170
全部0条评论

快来发表一下你的评论吧 !
