

什么是多模态?多模态的难题是什么?
描述
作者:Peter,北京邮电大学 · 计算机
什么是多模态?
如果把LLM比做关在笼子里的AI,那么它和世界交互的方式就是通过“递文字纸条”。文字是人类对世界的表示,存在着信息提炼、损失、冗余、甚至错误(曾经的地心说)。而多模态就像是让AI绕开了人类的中间表示,直接接触世界,从最原始的视觉、声音、空间等开始理解这个世界,改变世界。
好像并没有对多模态的严谨定义。通常见到的多模态是联合建模Language、Vision、Audio。而很多时候拓展到3d, radar, point cloud, structure (e.g. layout, markup language)。
模型经历了从传统单模态模型,到通用单模态,再到通用多模态的一个大致的发展,大致如下图:
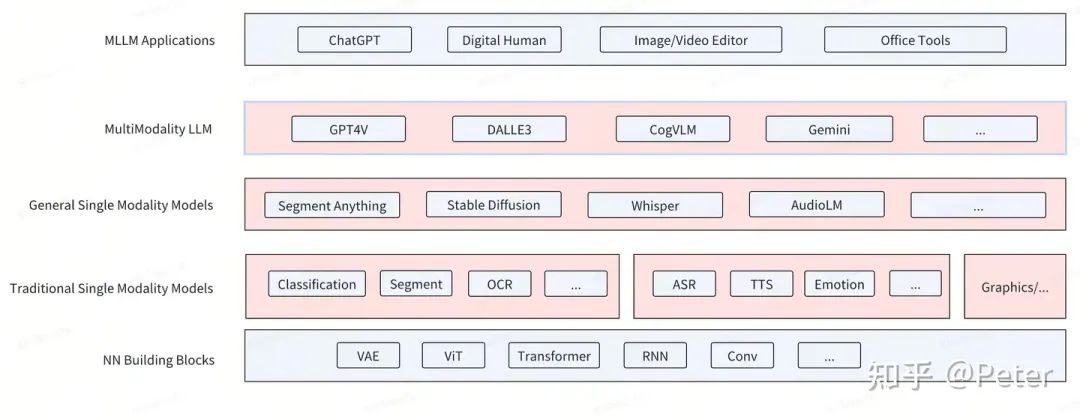
• NN Building Blocks: 相对通用的NN模型组件。
• Traditional Single Modality Models: 传统的垂类小模型,通常小于100M~1B参数,只在某个垂直场景上有效。虽然不通用,但是具有一些独特优势:显著的性能和成本优势,常常能够在移动端设备部署,离线可用。在很多场景和大模型组合使用,依然扮演重要角色。
• General Single Modality Models: 单模态大模型,通常大于100M~1B参数。具有较强的通用性,比如对图片中任意物体进行分割,或者生成任意内容的图片或声音。极大降低了场景的定制成本。
• MLLM:多模态大模型。以LLM为核心(>1B参数),端到端的具备多种模态输入,多种模态输出的大模型。某种程度上看见了AGI的曙光。
• MLLM Application: 灵活的结合LLM、MLLM、General/Traditional Single Modality Models等能力形成新的产品形态。
多模态的价值?
文字发展了数千年,似乎已经能精确的表达任意事物,仅凭文字就可以产生智能。数学物理公式、代码等更是从某种程度上远远超越了世界的表象,体现了人类智慧的伟大。
然而,人的一切依然依托于物理世界,包括人本身的物理属性。人们能毫不费力的处理十个小时的视觉信号(比如刷视频、看风景),十年如一日,但是一般人无法长时间的进行文字阅读理解。美丽的风景、优美的旋律能轻易的让大部分感受到愉悦,而复杂的文字或代码则需要更大的精力。
其他的各种人类社会的生产、消费、沟通等都离不开对世界自然信号的直接处理。难以想象这一切如果都需要通过中间的文字转化,才能被接受和反馈。(想象司机通过阅读文字,决定方向和油门)
AGI需要对自然信号的直接处理与反馈。
多模态技术
当前多模态大模型通常都会经过三个步骤:
• 编码:类比人的眼睛和耳朵,自然信号先要通过特定的器官转换成大脑可以处理的信号。
• 把每一个image切成多个patch,然后通过vit, siglip等vision encoder编码成一串vision embedding。考虑到视觉信号的冗余,可以再通过resampler, qformer等结构进行压缩,减少输入。
• 或者也可能是通过VAE编码成一个(h, w, c)shape的latent feature。或者是通过VQ编码成类似上文中language“词”的序号(integer),然后通过embedding table lookup转化成embedding。
• 对于language而言,通常就是文字的向量化。比如用bpe或者sentencepiece等算法把长序列的文字切成有限个数的“词”,从词表(vocabulary)中找到对应的序号,然后再通过embedding table lookup,把这些“词”转化成模型能理解的embedding。
• vision有一些不同的处理方式,比如:
• audio也需要进行编码,将传统的waveform通过fft处理成mel-spectrum。也有EnCodec或SoundStream等neural encoder可以把audio编码成一系列的token。
• 处理(思考):完成编码的信号就如同人们大脑接收到的视觉、声音、文字信号。可以通过“思考“的过程后,给出反馈。
• 基于diffusion的处理过程是近几年新出现的一类有趣的方法。在vision, audio生成中有卓越的表现。
• 基于llm的处理过程似乎更值得期待。llm本身已经具备相当的智能程度,提供了很高的天花板。如果llm能够很好的综合处理多模态信号,或许能接近AGI的目标。
• 解码:编码的反向过程,把模型内部的表示转化成物理世界的自然信号。就类似人们通过嘴巴说话,或者手绘画。
以下面两个多模态模型为例子:
StableDiffusion:
• 编码:image通过VAE encoder变成latent z。
• 处理:核心的处理过程在Unet中,通过多步denoise,对z进行去噪。
• 解码:z最终通过VAE decoder解码成image。
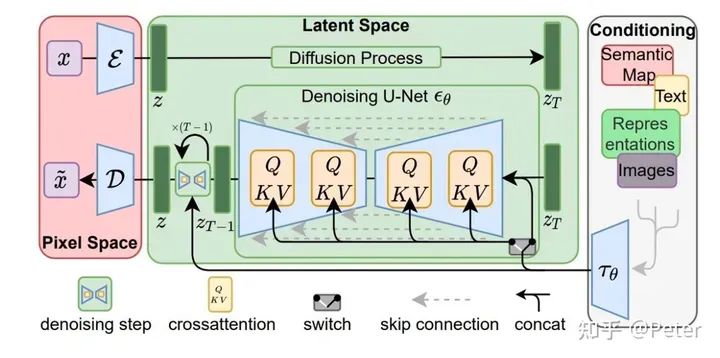
stable diffusion
DreamLLM:
• 编码:text通过word embedding,而图片通过visual encoder。
• 处理:casual llm对编码后的的语言和文字信号进行联合处理,预测需要生成的语言和文字信号。
• 解码:将预测结果还原成text和image。
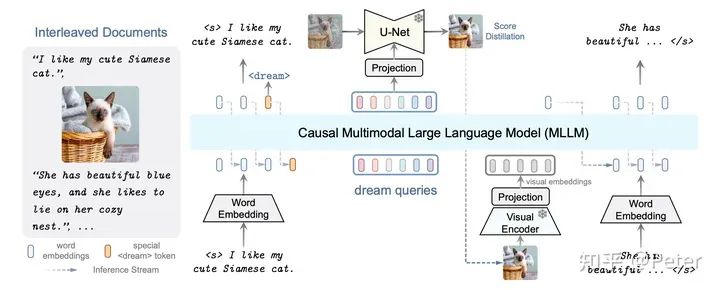
DreamLLM
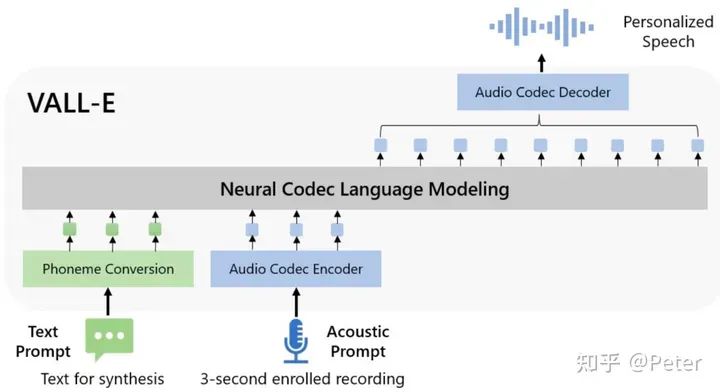
类似的架构还在语音生成的模型结构中出现,比如VALL-E,有对应的semantic, acoustic编码和解码,以及diffusion or llm的处理过程。
多模态的难题
目前我还有些多模态相关的问题没太想明白。
多模态scaling law
目前Meta, Google有放出一些多模态的实验,比如PALI对于ViT的scaling。但是还缺少一些理论性的支持和疑点。
• ViT在多模态理解中扮演了什么角色,需要如此大的参数规模?这部份参数是否可以转移到LLM上?
• 数据scale时,如何分配图片和文字的比例是比较好的实践?
如果做个思想实验:
• 一个网页上有500个字,需要800个token表示。
• 一个screenshot截图了这个网页,用vision encoder编码后得到400个token。
如果使用LLM分别处理两种输入,能够完成同样的任务。那么似乎就不需要用text作为LLM的输入了。
• 对于text, vision, audio信号编码的最佳实践是什么?每类信号需要使用多少的参数量才能无损的压缩原始信号?
从简单主义出发,scaling is all you need。
但是no profit, no scaling。所以还是得回到上面那个问题。
多模态生成的路径
Diffusion在生成上取得了不俗的效果,比如绘画。LLM同样可以完成视觉和音频的生成。
• 最终是LLM replace Diffusion, 还是Diffusion as decoder for LLM,还是通过别的方式?
• Diffusion的multi-step denoise是否可以通过llm的multi-layer transformer + iterative sampling来隐式模拟?
• 或许diffusion就像是convolution,是人们发明的inductive bias,最终会被general learnable method取代。
LLM end2end many2many是否是个伪需求?
• 是否有一种无损(或者近似)的信息传递方式,让多个LLM互相协作?
审核编辑:黄飞
-
《多模态大模型 前沿算法与实战应用 第一季》精品课程简介2026-05-01 186
-
体验MiniCPM-V 2.6 多模态能力jf_23871869 2025-01-20
-
lABCIWQmultyWindows多模态窗口20102016-05-17 497
-
多文化场景下的多模态情感识别2017-12-18 1279
-
Transformer模型的多模态学习应用2021-03-25 12157
-
多模态MR和多特征融合的GBM自动分割算法2021-06-27 1157
-
中文多模态对话数据集2023-02-22 2482
-
VisCPM:迈向多语言多模态大模型时代2023-07-10 1556
-
更强更通用:智源「悟道3.0」Emu多模态大模型开源,在多模态序列中「补全一切」2023-07-16 1682
-
基于Transformer多模态先导性工作2023-08-21 1796
-
基于视觉的多模态触觉感知系统2023-10-18 2280
-
探究编辑多模态大语言模型的可行性2023-11-09 1182
-
大模型+多模态的3种实现方法2023-12-13 3553
-
人工智能领域多模态的概念和应用场景2023-12-15 14195
-
商汤日日新多模态大模型权威评测第一2024-12-20 1947
全部0条评论

快来发表一下你的评论吧 !
