

基于生成式人工智能的工业软件自主创新路径分析
描述
01
引言
当前,以ChatGPT 为代表的预训练大模型 展现出自主学习、跨模态理解、推理抽象思维和人类社会理解等特征优势,正引发新一轮人工智能范式革命,成为推动科技跨越发展、产业优化升级、生产力整体跃升的重要驱动力。随着以大模型为代表的生成式AI 技术可用性增强及工业信息化水平提升,通用AI 的工业落地时间间隔逐步缩短,大模型为工业软件领域自主创新提供了有效路径。
02
我国工业软件发展现状
工业软件是工业知识的计算机代码化表达,是工业知识、经验、技能长期沉淀积累并数学化、工程化、代码化的结果。工业软件作用于工业产品的研发设计、生产制造、经营管理和运维服务等全生命周期,具有细分种类多、功能差异大、行业壁垒高和用户粘性强等特点。
我国工业软件门类相对齐全,市场发展迅速。据工信部统计数据显示,2021 年,我国工业软件市场规模达2 414 亿元,同比增长24.8%,未来五年内将持续以两位数幅度增长,市场规模有望于2026 年突破4 300 亿元, 具有较强的发展潜力。但总体上看,国产工业软件市场占有率较低,与国外的差距较大,主要存在市场规模小、产品受制于人、产业安全受国外威胁,以及关键技术和工业知识缺失等四大短板。
云计算、大数据、人工智能等新一代信息技术正在重塑工业软件形态。与传统的工业软件相比,基于新一代信息技术的工业软件采用工业互联网平台体系架构, 依托工业基础软件的支持,以数据要素为驱动,通过低代码工具和应用开发平台实现应用软件的定制化开发, 以云化和服务化的方式部署。基于新一代信息技术的工业软件在工业知识软件化基础上,增加了对工业大数据的处理和智能化分析能力,使解决复杂工业系统建模、控制与优化的难题成为可能,是工业互联网时代的新型生产工具。
03
大模型在工业领域的应用情况
3.1 大模型赋能生产制造全生命周期
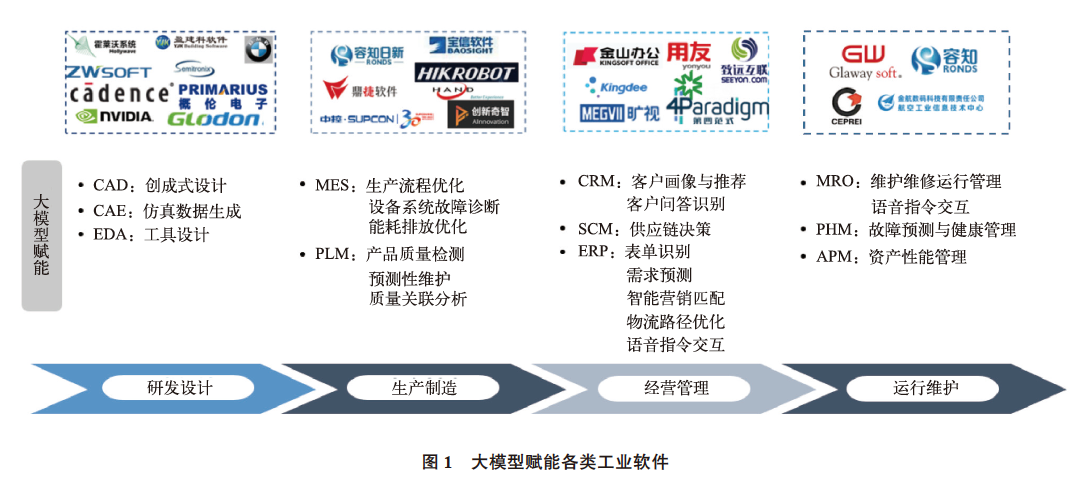
随着大模型技术的跃迁式发展,生成式AI 同工业领域加速融合,为工业软件创新发展提供了重要实现路径。基于大模型的自动识别、模型优化和推理决策三大核心能力,可实现对研发设计、生产制造、经营管理和运维服务等工业制造全生命周期的赋能。大模型赋能各类工业软件如图1 所示。
在研发设计方面,基于云计算和大数据技术,大模型能够自动生成或优化设计方案,提高EDA、CAD、CAE 等软件设计效率和精度。例如,Cadence 公司推出了Allegro X AI technology 新一代系统芯片设计技术,利用生成式AI 简化系统设计流程,将PCB 设计周转时间缩短至原来的十分之一;大模型赋能创成式设计,可实现3D CAD 的自主优化设计,提升Siemens Solid Edge、PTC Creo 等主流CAD 的设计效率。
在生产制造方面,利用自然语言处理和计算机视觉等算法,大模型实现与人类的自然交互和协作,提高生产效率和质量。比如,西门子自动化生产SIMATIC IT 软件引入ChatGPT,有效实现了操作者与系统自然语言的交互;西门子和微软正在合作开发可编程逻辑控制器(PLC) 的代码生成工具,利用ChatGPT 通过自然语言输入生成PLC 代码。
在经营管理方面,通过迁移学习和模型微调,大模型能够快速掌握垂直领域知识,提高ERP、CRM、SCM 等软件的管理效率和水平。例如,微软推出了GPT 互动式AI 能力商业产品Dynamics 365 Copilot 和Microsoft 365 Copilot,大幅提升用户在经营管理类软件上的工作效率, 未来将扩展至供应链管理、客户服务和市场营销等场景;国内企业第四范式上线企业级产品4Paradigm SageGPT, 将大模型与垂直领域专业知识融合,具备企业级场景下的多模态及Copilot 能力;旷世科技布局基于视觉大模型的供应链智能管理,探索基于“感知- 决策- 执行- 反馈” 的全链条仓储物流优化方案。
在运维服务方面,大模型可有效提升早期缺陷检测、预测性维护、产品质量分析和生产预测等能力,持续优化MRO、PHM 等软件性能。美国明星创业公司Uptake 将AI 能力引入设备预测性维护,并取得良好运营效果;国内容知日新开展基于AI 的工业设备状态监测与故障诊断研究,打造基于数据、算法和算力管理的PHM 引擎, 提升智能运维能力。
3.2 大模型的工业应用挑战
大模型在工业领域具有广阔的应用前景,国内外科技巨头及工业软件企业已开展相关研究布局,主要是调用大模型的基础能力,实现辅助操作环节应用。大模型赋能工业软件研发设计等核心环节主要面临技术、数据和产业三方面的挑战。
技术方面,当前国内在大模型领域的基础技术储备不足、通用大模型性能仍需提升、工业领域垂直大模型尚待构建。同时,大模型训练部署对算力、存储、数据等基础设施有较高需求,传统的工业软件主要运行在本地,计算和存储能力有限,更新迭代慢,使得生成式AI 的研发设计、工业仿真、低代码开发等业务场景的落地受到阻碍。
数据方面,我国工业领域数据体量大、实时性高, 存储成本大、价值密度低,数据源异构性强,数据孤岛现象严重,工业数据开放程度低,各种类型的设备和工序之间相互独立,数据流通缺少统一的标准。当前工业场景的数据量对于深度学习而言都还是小规模,需要对全行业的数据进行汇聚、对齐和训练,形成面向工业软件领域的大模型。
产业方面,大模型的工业应用仍在探索阶段。在供给侧,大模型需要高昂的资金和人才投入。我国工业软件企业综合优势不强,当前还停留在基础能力补短板阶段,缺乏复合型技术人才。在需求侧,当前大模型对知识原理的理解有限,尚未做到答案完全可控与准确,而工业领域对安全可靠性要求高,当前大模型缺乏可落地的应用场景。
04
基于大模型的工业软件技术创新路径
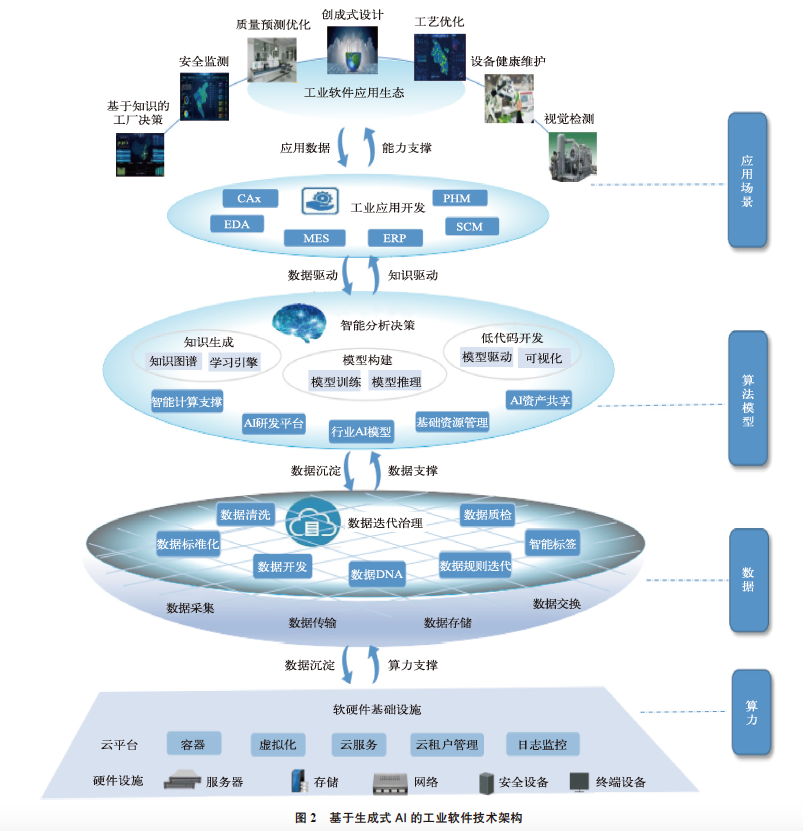
大模型在工业软件领域具有广阔的应用前景,国内外科技巨头及工业企业已开展相关研究布局,但目前应用尚浅,主要是调用大模型的通用能力提供基础服务。基于生成式AI 的工业软件技术架构如图2 所示。为提升大模型在工业机理方面的应用深度,推动生成式AI 与工业软件融合发展,可考虑从如下几方面进行研究布局。
1)构建工业软件云。大模型的算力门槛非常高,传统的工业软件主要运行在本地,计算和存储能力有限, 更新迭代慢,严重制约大模型的应用。工业软件云化部署后,可大幅提高基础服务的多样性,通过调用高性能计算、GPU 算力、大数据服务等资源,满足大模型训练部署对算力、存储、数据等基础设施的需求,降低开发和应用成本,使得基于生成式AI 的研发设计、工业仿真、低代码开发等业务场景能够真正落地。通过将散落分布的业务数据汇聚到云上,对大模型进行持续优化迭代, 有效提升产品的差异化竞争力。
2)建设工业大脑。改变过去工业领域“碎片化”、“作坊式”、成本消耗大、效率低的AI 模式,基于基础大模型底座,汇聚海量行业数据,通过模型微调、蒸馏等方式, 形成面向各个领域的行业大、中、小模型,实现工业知识和专家经验的沉淀,构建具有深度认知能力的工业大脑。通过大小模型协同的方式,快速、高效地开发面向特定行业场景的各类工业软件/APP,提升工业软件的智能化水平。
3)构建“SaaS+ 低代码”的工业软件应用生态。工业SaaS 把传统架构的工业软件分解成具有统一接口、灵活且可配置的应用,通过封装大量通用的行业Know-how 知识经验或知识组件以及算法和原理模型组件,以低代码方式构建上层工业APP。大模型的代码生成能力的跨越式进步有望重塑工业PaaS 低代码开发平台。未来随着生成式AI 在代码生成能力方面的逐步成熟,可实现零代码研发设计和生产优化,大幅提升工业软件的应用创建能力、降低应用开发成本。
4)推动工业软件开发新生态。从技术趋势来看,设计、制造、仿真一体化趋势推动工业软件超融合发展。基于超融合平台,可以实现AI 模型开发、训练、调优、运营等复杂过程的封装,提供低门槛、高效率的企业服务。从开发模式来看,多主体协作趋势推动工业软件走向开源与开放,大模型通过自动生成代码、提供开源工具等方式,助力工业软件开发。利用AI 技术生成需求文档、功能规格说明书、代码、测试用例和测试脚本等,实现持续交付,推动软件工程3.0 的发展,真正实现模型驱动开发、数据驱动开发和AI 原生开发。
05
发展建议
为提升大模型的应用深度,推动生成式AI 与工业软件的深度融合,建议抢先布局基于大模型的工业软件应用体系,突破工业软件核心关键技术,推动基于新一代信息技术的工业软件融合创新。
1)全面规划工业软件创新发展的顶层战略。制定重点行业国产工业软件创新行动计划,明确基于大模型的国产工业软件发展目标、重点任务和关键举措,培育基于生成式AI 的工业软件等重点技术攻关项目。聚焦通用人工智能和工业软件融合创新,着力构建一个适用的技术体系架构、打造一套完整的技术标准体系、支持一批重点技术攻关项目、形成一批典型的融合应用模式,以及培育一批有成效的“AI+ 工业应用”平台,部署重点行业工业软件应用先试先行和试点示范工程。
2)超前布局基于大模型的工业软件技术体系。一方面,鼓励工业软件云化部署,支持企业开放高性能计算、GPU 算力、大数据服务等资源,通过共享算力、数据的方式,降低开发和应用成本。通过将散落分布的业务数据汇聚到云上,对大模型进行持续优化迭代,形成完整高效的开源算法模型,有效提升产品的差异化竞争力。另一方面,构建工业软件领域的大模型评测标准体系, 研究多模态多维度的基础模型评测基准及评测方法,开发基础模型评测工具集,建立公平高效的自适应评测机制,推动大模型在研发设计、生产制造、经营管理和运维服务等环节的深度融合应用。
3)逐步形成大模型赋能工业软件的数据应用机制。一是探索建立基于数据托管机制的大模型训练数据监管体系,确保工业数据来源可靠,在数据标准、数据质量、数据安全和隐私保护等方面依法合规,保障大模型输出结果的高质量并符合监管要求。二是建立工业软件数据交换共享机制,使得行业数据能够对白名单企业、机构、高校适当开放,在确保数据安全使用的同时,增强工业软件领域大模型研究实力。三是鼓励优先采用安全可信的软件、工具、计算和数据资源,通过改进算法等技术手段,确保训练数据的安全性、规范性与合法性。
4)积极推动工业软件自主创新生态建设。一是依托北京市工业软件产业创新中心等载体,汇聚国内工业软件企业、大模型开发企业、高等院校和研究机构等力量, 在技术创新、场景应用、产业发展等方面深化交流合作, 推动基于大模型的工业软件开发应用。二是加强复合型人才培养,鼓励国内科研院所、高校和企业开展合作, 建立“产、学、研、用”综合实践应用平台、人才实训基地等,培养一批高端型工业软件人才。三是聚焦重点行业工业软件替代需求清单和关键共性技术需求清单, 开展供需对接,围绕石化、船舶、航空等重点行业,打通技术、场景和人才壁垒,打造一批基于大模型的工业软件示范应用,共同推动人工智能技术与产业的快速发展,助力工业经济高质量发展。
06
结束语
抢抓新一代信息技术,推动我国工业软件自主创新, 是解决工业软件“卡脖子”问题的重要路径。生成式人工智能在提升工业软件研发设计、生产维护等效率方面取得一定的进展,但与工业机理的深度融合仍然存在难点。建议布局基于大模型的工业软件技术和应用体系, 持续推进技术创新、场景应用、产业发展等,共同推动人工智能技术与产业的快速发展,为抢抓新一轮科技革命和产业变革机遇、实现工业经济高质量发展作出更大贡献。
审核编辑:刘清
-
嵌入式人工智能的就业方向有哪些?2024-02-26 12463
-
《AI for Science:人工智能驱动科学创新》第一章人工智能驱动的科学创新学习心得2024-10-14 1750
-
嵌入式和人工智能究竟是什么关系?2024-11-14 4013
-
人工智能是什么?2015-09-16 6455
-
基于人工智能的创新教学云平台建设2018-04-16 3856
-
人工智能:超越炒作2019-05-29 5048
-
基于人工智能的传感器数据协同作用2019-07-25 3380
-
路径规划用到的人工智能技术2021-07-20 2429
-
嵌入式与人工智能关系是什么2021-10-27 3445
-
什么叫嵌入式人工智能2021-10-28 2076
-
人工智能对汽车芯片设计的影响是什么2021-12-17 2240
-
嵌入式人工智能实践课程改革研讨会在南京顺利召开2022-08-31 4428
-
嵌入式人工智能学习路线2022-09-16 4544
-
生成式人工智能和感知式人工智能的区别2024-02-19 3769
-
生成式人工智能在教育中的应用2024-09-16 4489
全部0条评论

快来发表一下你的评论吧 !
