

深入探讨为什么需要1.6T数据传输
通信网络
描述
自20世纪80年代以来,以太网一直是一项基础技术。早期,工作站和个人电脑使用同轴电缆以10Mbps速率的共享局域网连接到现场服务器。此后,以太网不断发展,不仅支持双绞线和光纤布线,速率也从100Mbps发展到100Gbps,甚至是最新的1.6Tbps标准。
随着以太网速度的提高,其应用越发多样化,从音、视频流到多房间音频、工控网络,甚至车载网络。这一进展对数据传输提出了更高的安全可靠性要求。尤其是对丢失和延迟特别敏感的数据流来说,定义服务质量是至关重要的。
本文将深入探讨为什么需要1.6T数据传输、IEEE802.3dj小组的标准化工作、对1.6T以太网子系统组件的概述以及处理所有这些数据所需的以太网控制器的FEC考虑因素等内容。
我们为什么需要如此高的传输速度?
以太网的发展主要有两个维度:
1.
传输和存储海量数据的性能得到了提升;
2.
网络的可预测性和可靠性得到了提高,即使是要求最苛刻的控制系统也能被满足。
如今,互联网的带宽估计可达到500Tbps,这对数据中心内的后端流量提出了惊人的要求。虽然数据中心内的总流量已经能够达到每秒太比特的水平,但是单个服务器还无法达到这个速度。
1.6T以太网的尝鲜者——处理器间通信
单个设备的处理能力是有限的,即使使用了最先进的处理器或专为机器学习优化的加速器,其性能也会受限于芯片的实际制造尺寸。然而,一旦多个芯片联合起来,我们便有可能极大地扩展计算能力。因此,太比特级速度和极低延迟的新一代以太网技术的出现,让这一技术突破成为可能,处理器间通信成为了1.6T以太网的首个应用场景。继这一代应用之后,预计数据中心将推出交换机间的直连技术,实现高性能处理器和内存资源的集中利用,大幅提升云计算的扩展性和运行效率。
802.3dj:为1.6T以太网标准化奠定基础
要实现有效通信,网络上的每个节点都必须遵守同一套标准所定义的规则。电气和电子工程师协会(IEEE)自成立以来一直负责制定以太网标准。目前,802.3dj小组正在制定以太网标准的最新版本,其中概述了以每秒200G、400G、800G和1.6T速度运行的物理层和管理参数。
1.6Tbps的以太网MAC数据传输速率需满足以下条件:
MAC层的最大误码率(BER)为10-13
可选16和8通道附件单元接口(AUI),适用于芯片到模块(C2M)和芯片到芯片应用(C2C),使用112G和224G SerDes。
在物理层方面,1.6Tbps的传输规格包括:
在每个方向上传输8对铜双轴电缆,传输范围至少为1米;
在8对光纤上传输,最长可达500米
在8对光纤上传输,最长可达2千米
预计该标准将于2026年春季确定。不过,我们预计2024年底即可完成基线功能。
1.6T以太网子系统剖析
我们来深入了解下1.6Tbps以太网子系统的组件,尤其是一些用于在ASIC或ASSP硅芯片中实现以太网接口的元件。
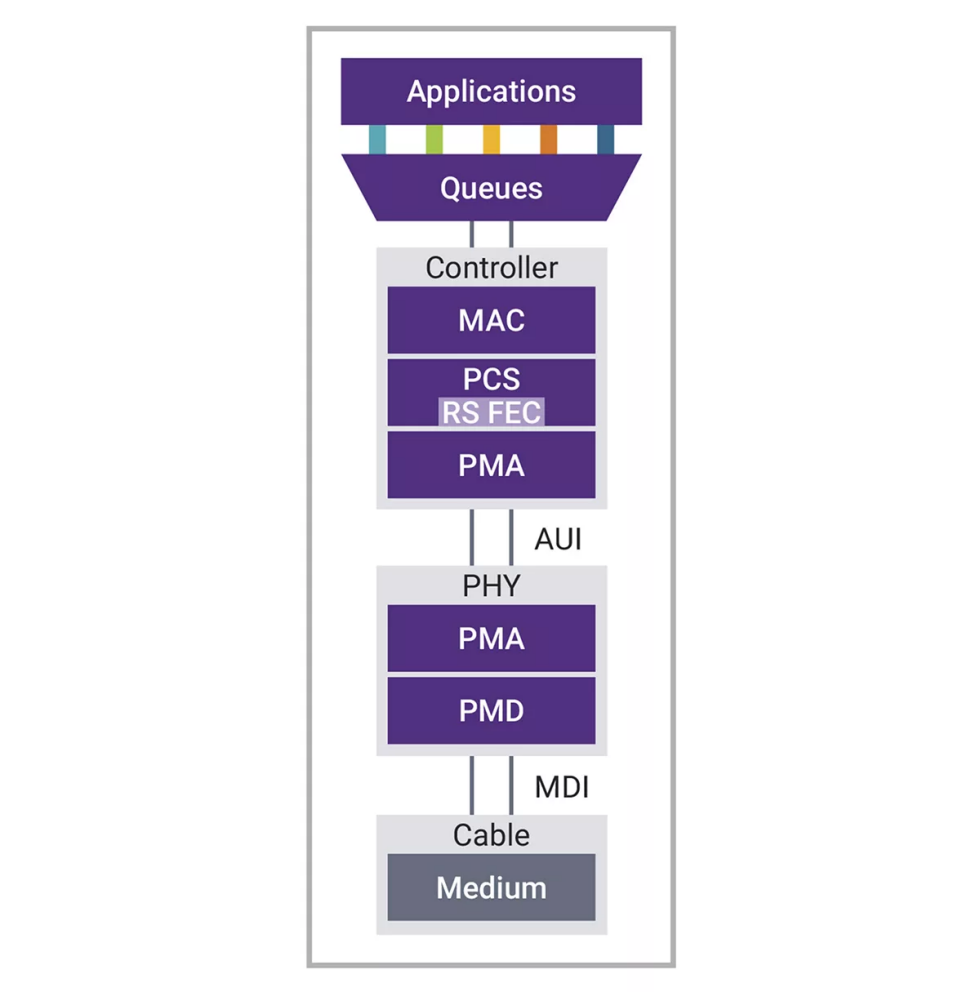
图2:1.6T以太网子系统组件的示意图
网络应用
最顶层是网络应用程序,既可以安装在客户端机器上,也可以安装在电脑或文件服务器上。它们既是所有以太网流量的来源,也是其目的地。但以太网桥或第二层交换机比较特殊,按照802.1d的定义规则,它是转发数据包的中间点。
队列连接
各个应用程序或实例通过一个或多个队列与以太网控制器相连接。队列很可能正在缓冲与应用程序之间的流量,平衡客户端与服务器端的网络性能。为实现最高性能,网络速度应与流量产生或消耗的速度相匹配。这样,我们就能最大限度地减少数据包在应用程序之间端到端交换时的延迟。
控制器、物理层和布线
以太网控制器通常由一个MAC和一个PCS组成,但一般我们会称之为“以太网MAC”。在PCS下方是附件单元接口(AUI)——有些读者可能还记得工作站背面的D型连接器,AUI电缆就插在上面。在今天的以太网中,这种接口依然存在,并且速度更快了。最后,在堆栈的更下面,我们可以找到负责控制和管理网络物理元素的模块,这些模块可能是光纤、铜缆或者背板。
1.6T以太网控制器:深入了解MAC、PCS和高级FEC机制
如图3所示,在应用程序和队列下面是介质访问控制器(MAC)。MAC负责管理以太网成帧——查看源地址和目标地址、管理帧的长度、在必要时添加填充(在有效载荷很短的情况下)以及添加/检查帧校验序列(FCS),以确保帧的完整性。
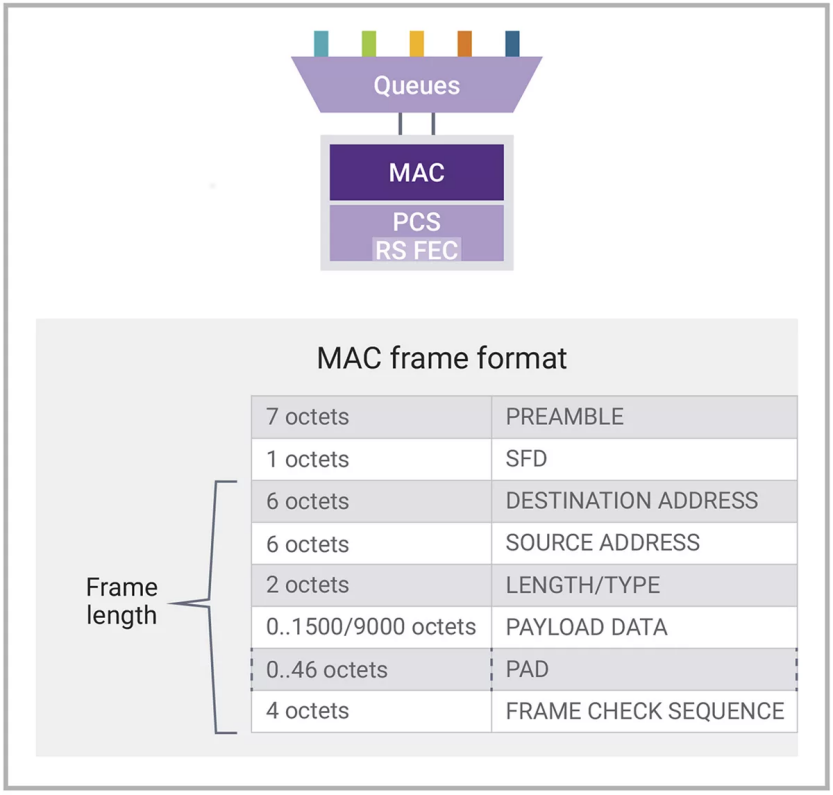
图3:MAC帧格式和长度:八进制分解
MAC的变体可分为两大类:
一、网络接口卡(NIC)中的MAC
这种MAC位于客户端、服务器或路由器中的网卡上。它们在有效载荷向下和向上传递堆栈时,通过添加和删除以太网的特定任务来完成终止以太网层的重要任务。其中一个不可或缺的功能是添加和检查帧校验序列(FCS),以确保数据完整性。如果在接收时检测到任何损坏,帧将被丢弃。此外,网卡中的MAC将检查帧的目标地址,确保在网络内准确传输。有效载荷很可能是一个IP(互联网协议)数据包。
NIC以前是一种插入式网卡,因此被称为"网络接口卡"。网卡执行MAC、PCS和PHY,而队列和任何其他智能功能则由主机处理器处理。如今,我们看到的智能网卡可以卸载许多网络功能,但仍保持相同的MAC层。
二、交换/桥接MAC
交换或桥接MAC采用了不同的方法。在这里,整个以太网帧在MAC和上层之间传递。MAC负责添加和检查FCS,并为支持远程网络监控(RMON)收集统计数据。从概念上讲,以太网交换机可被视为为此目的而设计的专用应用程序。尽管以太网交换机主要由硬件实现,以保证最佳线速性能,但其每个端口都包含一个专用的MAC。尽管这些端口可能以不同的速度运行,但任何速率适应都是在MAC层以上的队列中进行管理的。
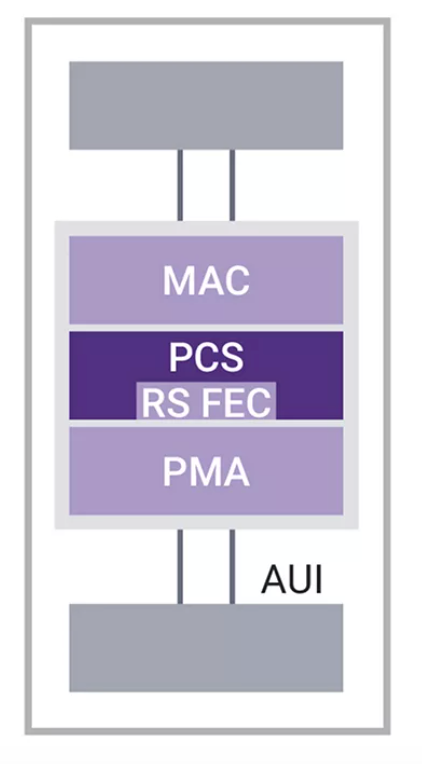
图4:MAC、PCS和PMA与AUI连接示意图
从基本编码到RS-FEC
对于较低的以太网速率,物理编码子层(PCS)只需对数据流进行编码,即可开始检测数据包,并确保信号平衡,即使在长的0或1数据流中也是如此。然而,随着以太网速度的提高,PCS的复杂性也在增加。如今,由于每个物理链路上都有高速信号,因此有必要使用前向纠错(FEC)来克服固有的信号衰减,即使在很短的链路上也会遇到这种情况。
与其他高速以太网变体的PCS一样,1.6T以太网采用了里德-所罗门前向纠错(RS-FEC)技术。这种方法建立的编码字由514个10位符号组成,编码成544个符号块,因此带宽开销为6%。这些FEC编解码字分布在AUI物理链路上,因此每个物理链路(1.6T以太网为8个)不会携带整个编解码字。这种方法不仅能提供额外的错误突发保护,还能在远端解码器上实现并行化,从而减少延迟。
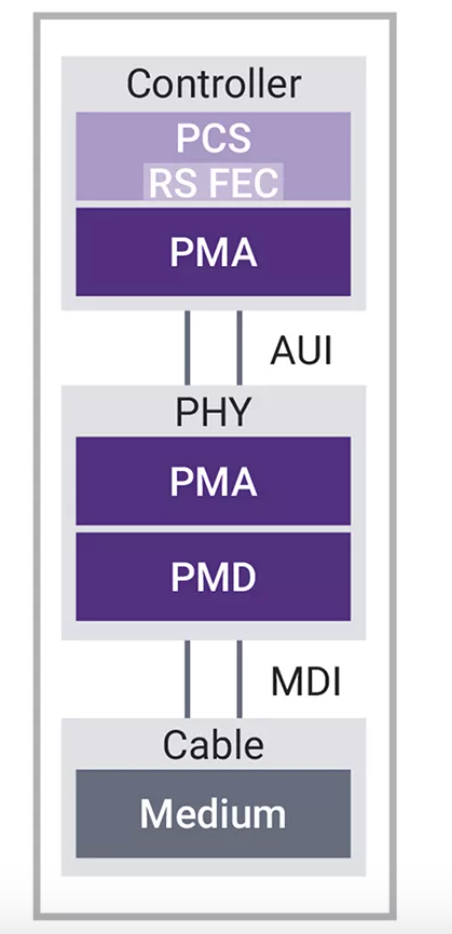
图5:1.6T以太网子系统的控制器、物理层和电缆组件示意图
在1.6T以太网中实现最佳比特误码率
虽然以太网PHY层包括PCS,但通常将PCS与以太网控制器内的MAC联系起来。物理介质附件(PMA)具有齿轮箱和SerDes,可将以太网信号传输到传输通道上。对于1.6T以太网,8个通道以212Gbps的速度运行,FEC编码扩展率为6%。值得注意的是,PMA的上半部分位于控制器内,然后将比特流交给AUI。PHY的每个物理链路都使用4级脉冲幅度调制(PAM-4)。这种方法为每个传输符号编码两个数据位,与传统的非归零(NRZ)传输相比,带宽增加了一倍。发送器采用数模转换器(DAC)对数据进行调制,而远端接收器则使用模数转换器(ADC)和DSP来提取原始信号。
以太网PCS在以太网链路端到端使用的数据流中增加了FEC,在长距离以太网链路中通常称为"外部FEC"。IEEE正在为单个物理线路定义额外的纠错级别,以实现更长的传输距离。在需要纠错的地方,光收发器模块将支持这种额外的纠错(可能是一种汉明码)。图6显示了使用串联FEC扩展传输距离时增加的开销。
让我们看一下图6中的系统示例,其中MAC和PCS的光发射器和接收器被一段光纤隔开:

图6:用一段光纤分隔MAC和PCS光TX/RX的示意图
在与光模块相连的链路上,PCS的误码率为10^-5,加上在光链路上引入的额外误码。如果我们只在该系统中端对端实施单个RS-FEC,则产生的误码率将无法满足10^-13以太网要求。该链路将被归类为不可靠链路。另一种方法是在每一跳上实施单独的RSFEC,RSFEC将进行三次编码和解码。一次在发送PCS,然后在光模块,最后在从光模块到远程PCS的远端链路。这样做的成本很高,而且会增加端到端延迟。
将串联汉明码FEC集成到光链路中是一种最佳解决方案,既能满足以太网要求,又能很好地处理光连接中遇到的随机误差。内部FEC层将线路速率从212Gbps提高到226Gbps,因此SerDes必须能够支持这一线路速率。
从发送到接收:了解以太网应用中的延迟状况
简单地说,以太网延迟是指从一个应用程序通过以太网传输信息到另一个应用程序接收信息之间的延迟。往返延迟测量的是从发送信息到收到响应所需的时间。当然,这种延迟取决于远端应用程序的响应时间,在考虑以太网延迟时,可以忽略这一点,因为它是以太网的外部延迟。以太网延迟的组成部分包括发送队列、信息处理时间、传输持续时间、介质穿越时间、信息接收时间、结束处理时间和接收队列中的时间。
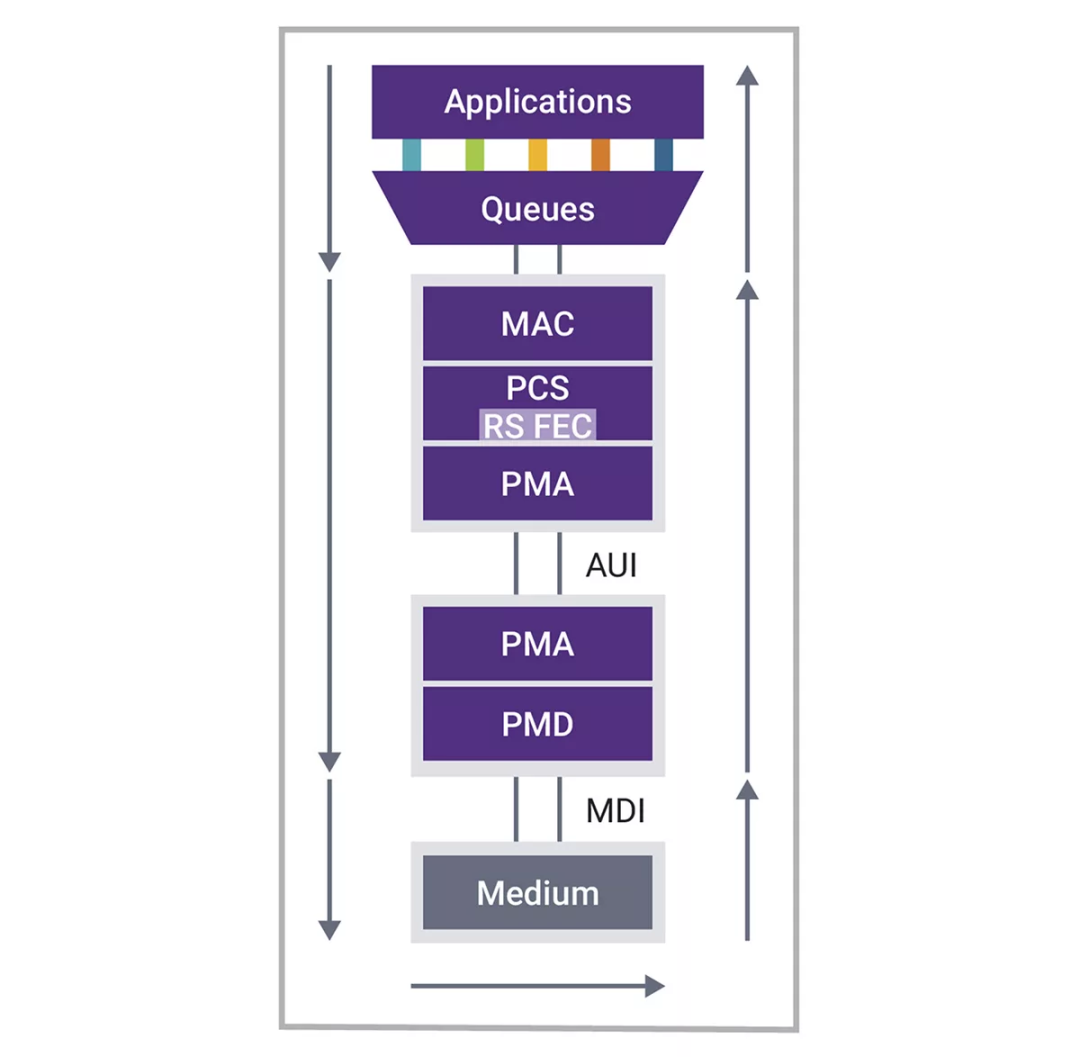
图7:描述完整1.6T以太网子系统和延迟路径的示意图
在关注最大限度减少以太网子系统(特别是以太网接口级,而非整个网络)中的延迟时,考虑具体情况至关重要,例如,当数据包源和数据包汇以匹配的高数据速率运行时。相反,在中继连接(如交换机之间的连接)中,由于较慢的客户端链路会产生较明显的延迟,因此延迟就不那么重要了。同样,在处理较长距离时,距离造成的固有延迟将占主导地位。
此外,值得注意的是,时间敏感网络(TSN)解决的是确定性延迟问题。在这种情况下,关键任务应用的最大延迟上限已被确定,尤其是对于低速网络或共享基础设施网络。当然,这并不意味着我们应该忽视其他情况下的延迟。最大限度地减少延迟仍然是一个不变的目标。首先,端到端的累计延迟会随着每一次连续跳转而增加。其次,延迟的增加往往表明控制器中增加了电路或处理功能,这可能会导致系统功耗增加。
延迟洞察:剖析以太网子系统层
首先,我们抛开任何队列延迟不谈,假设从应用程序到以太网控制器之间有一条清晰的路径,没有任何带宽竞争。带宽差异会导致数据包排队延迟,当延迟至关重要时,应避免这种情况。当数据包通过传输控制器时,以太网帧会即时建立或修改。值得注意的是,线路编码和传输FEC阶段不需要大量存储。
传输报文处理延迟取决于具体的实现方式,但可以通过良好的设计实践将其最小化。传输信息所需的时间取决于以太网速率和帧大小。对于1.6T以太网,传输一个最小大小的数据包需要0.4ns-基本上是2.5GHz时钟每跳动一下就传输一个以太网帧。标准最大以太网帧的传输时间为8ns,巨型帧的传输时间延长至48ns。
考虑到穿越介质的时间,光纤延迟大约为每米5ns,而铜缆稍快,为每米4ns。虽然信息接收时间与发送时间相同,但由于这两个过程同时进行,因此通常会被忽略。
大部分延迟发生在接收器控制器上
即使是最优化的设计,RSFEC解码器造成的延迟也是不可避免的。开始纠错时,必须接收并存储4个编码字,以1.6Tbps的速率计算,这需要12.8ns的时间。随后的流程,如执行FEC算法、纠错(必要时)、缓冲和时钟域管理,都会进一步增加控制器的接收延迟。虽然FEC编解码存储时间是一个恒定因素,但信息接收过程中的延迟与具体实施有关,但可以通过良好的数字设计实践进行优化。
从本质上讲,由于FEC机制和物理距离或电缆长度,存在固有的、不可避免的延迟。除了这些因素外,良好的设计实践在最大限度地减少以太网控制器造成的延迟方面也发挥着关键作用。利用集成的完整解决方案(包括MAC、PCS和PHY)以及专业的设计团队,可为最高效、低延迟的实施铺平道路。
总结
1.6Tbps以太网可满足带宽最密集、时延最敏感的应用需求。随着224GSerDes技术的出现以及MAC和PCSIP的开发,可提供符合不断发展的1.6T以太网标准的完整现成解决方案。控制器延迟在1.6Tbps应用中至关重要。除了协议和纠错机制造成的固有延迟外,IP数字设计还必须由专业设计团队精心设计,以防止数据通路增加不必要的延迟。
经过硅验证的解决方案需要优化的架构和精确的数字设计,强调能效并减少硅足迹,从而使1.6T数据速率成为现实。新思科技经过硅验证的224G以太网PHYIP为1.6TMAC/PCS的实现奠定了基础。利用领先的设计、分析、仿真和测量技术,新思科技将继续提供卓越的信号完整性和抖动性能,以及包括MAC+PCS+PHY在内的完整以太网解决方案。
审核编辑:黄飞
-
深入解析SCAN15MB200:高速数据传输的理想选择2025-12-29 484
-
环旭电子即将推出新一代1.6T光模组产品2025-07-30 2868
-
800G/1.6T:迈向下一代数据中心网络的关键路径2025-03-20 1320
-
MPU数据传输协议详解2025-01-08 2188
-
ADOP带你了解:800G和1.6T以太网的创新与挑战2024-08-20 2949
-
1.6T模块与DSP技术的演进2024-06-06 2118
-
DMA进行数据传输和CPU进行数据传输的疑问2023-05-25 1271
-
【原创】STM32 UART通信深入探讨2021-07-15 3737
-
DMA数据传输(源代码分享)2018-04-27 10387
-
深入探讨DFM在PCB设计中的注意要点2014-10-24 3940
-
数据传输,数据传输的工作方式有哪些?2010-03-18 6292
-
Modem数据传输标准2009-12-28 1402
-
DMB-T 的数据传输能力怎么样?2008-10-20 1152
-
数据传输2006-03-25 1022
全部0条评论

快来发表一下你的评论吧 !
