

通用Tensilica软件堆栈提供最佳边缘AI性能
描述
开发敏捷的软件堆栈对 AI 在边缘侧的成功部署非常重要。基于多种 AI 框架创建的新机器学习模型已经不再罕见,这些框架采用了最新的算子和最先进的机器学习模型拓扑。就像寒武纪生命大爆发一样,其快速发展源于富有创造性的开源社区对 AI 技术的广泛采纳,并在边缘侧不断推动机器学习模型的应用。
这些模型由学术界和工业界共同创建,使用了最尖端工具和概念;因此,在高性能、最新的 AI 软件堆栈上高效运行这些模型对任何组织而言都很复杂。
得益于多年的专业领域积累,Cadence 拥有业界领先的基础设计 IP,为全球的计算平台提供支持。Cadence 在 IP 市场的领先地位推动了现有客户和合作伙伴对人工智能计算需求的不断增长。过去二十年来,Tensilica 成功提供了可扩展、可配置的处理器 IP,被大量客户用于边缘侧的 SoC 设计。Tensilica IP 被广泛应用于音频、视觉、雷达、汽车和基于微控制器的子系统。
考虑到 Cadence 处理器 IP 被广泛使用,以及 AI 推理在各个细分市场的应用,我们致力于推出通用的“一站式”解决方案,为客户提供统一的、可扩展、可配置的 ML 软件堆栈。一站式工具理念是我们整体 AI 软件产品的核心。
一款通用的软件接口和工具将大幅缩短客户产品的上市时间,助其更好地为不断发展的 AI 市场做好准备。
从超低功耗、永远在线的使用场景到 ADAS 和自动驾驶等高端车载应用,在边缘侧可以看到各类用例。这些用例对 AI 的计算需求从每秒几千兆次运算(GOPS)到每秒数万亿次运算(TOPS)不等。
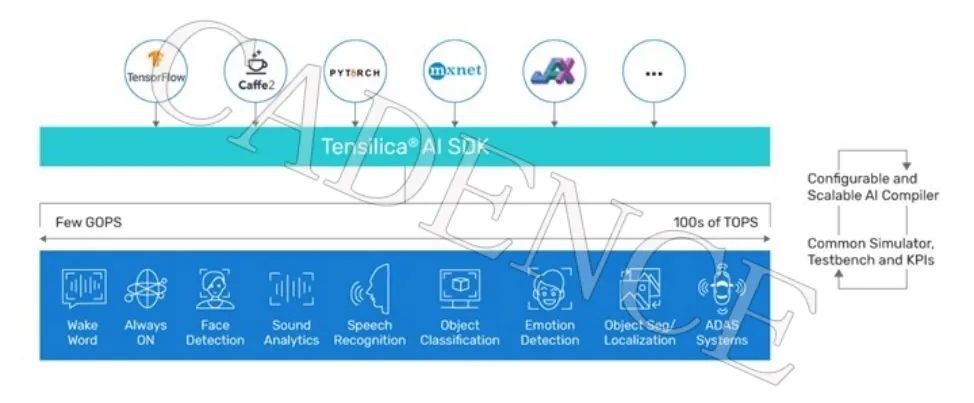
图1:适用于所有垂直市场的通用 AI 软件工具
我们的目标是在高性能机器学习编译器堆栈的各个方面改进我们的产品,包括统一的前端设计、通用的中间表示法、对混合精度量化格式的支持、无损压缩技术、图和张量优化等。
这些技术将在各类 AI 部署的场景中帮助客户,例如使用基于委派模式的框架进行提前编译、即时编译和/或运行时解释器框架。

图2:AI 软件堆栈支柱
客户可以在流片前进行 ML 工作负载的软件仿真并提取关键 KPI。在软硬件协同设计阶段,拥有这些准确的指标是非常有价值的。迭代各类 ML 模型,微调可配置参数以从硬件 IP 中获得最大性能是每个 SoC 架构师的基本目标。
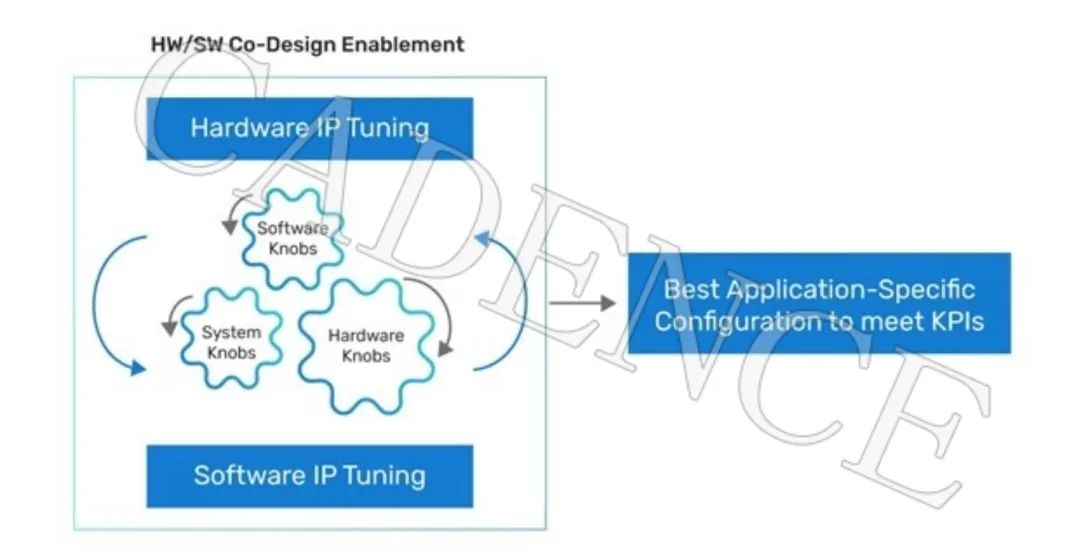
图3:实现软硬件协同设计
利用开源工具实现 Cadence AI 软件堆栈的同时,我们也积极参与开放论坛,为开源社区做出贡献。作为嵌入式 IP 领域的市场领先者,Cadence 与全球各地的合作伙伴协作,致力于为细分市场提供领先的 AI 解决方案。
审核编辑:刘清
-
硬件帮助将AI移动到边缘2019-05-29 2588
-
一文了解边缘计算和边缘AI 精选资料分享2021-07-23 2325
-
嵌入式边缘AI应用开发指南2022-11-03 1504
-
ST MCU边缘AI开发者云 - STM32Cube.AI2023-02-02 1325
-
HT MCU 软件堆栈的应用2010-03-26 607
-
Morpho为Tensilica便携客户提供图像处理支持2008-10-31 792
-
Irida Labs为Tensilica新的IVP图像/视频DSP提供计算机视觉应用软件2013-02-22 1835
-
Cadence推出全面的终端侧 Tensilica AI 平台,加速智能系统级芯片开发2021-09-15 1942
-
高通AI软件栈产品组合提供从边缘到云端的AI功能2022-06-23 2512
-
Cadence加强其Tensilica Vision和AI软件合作伙伴生态2023-04-12 1921
-
Cadence推出全新一代AI IP和软件工具2023-09-20 2688
-
Cadence推出全新HiFi和Vision DSP,为Tensilica IP产品阵容再添新成员,面向普适智能和边缘AI推理2023-10-30 3049
-
NVIDIA 通过 Holoscan 为 NVIDIA IGX 提供企业软件支持,实现边缘实时医疗、工业和科学 AI 应用2024-06-03 831
-
NVIDIA 通过 Holoscan 为 NVIDIA IGX 提供企业软件支持2024-06-04 1738
-
NVIDIA IGX平台加速实时边缘AI应用2024-09-09 2534
全部0条评论

快来发表一下你的评论吧 !
