

教您如何精调出自己的领域大模型
电子说
描述
BERT和 GPT-3 等语言模型针对语言任务进行了预训练。微调使它们适应特定领域,如营销、医疗保健、金融。在本指南中,您将了解 LLM 架构、微调过程以及如何为 NLP 任务微调自己的预训练模型。
介绍
大型语言模型 (LLM) 的特别之处可以概括为两个关键词——大型和通用。“大”是指它们训练的海量数据集及其参数的大小,即模型在训练过程中学习的记忆和知识;“通用”意味着他们具有广泛的语言任务能力。
更明确地说,LLM 是 ChatGPT 或 Bard 等聊天机器人背后的一种新型 AI 技术,与通常针对单个任务进行训练的典型神经网络不同,LLM 是在尽可能大的数据集上训练的,就像整个互联网一样,以学习生成文本、代码等各种语言技能。

模型尺寸
然而,它们广泛的非专业基础意味着它们可能会在利基行业应用中失败。
例如,在医学领域,虽然LLM大模型可能擅长通过日常的基础训练总结通用文章,但它缺乏专业的医学知识来准确总结包含复杂技术细节和术语的专业外科手术文件。这就有了微调的用武之地——对LLM进行医学概述数据的进一步训练,教给它高质量医学摘要所需的专业知识和词汇。
好奇这种微调是如何完成的?嗯,这就是本指南的重点。请继续阅读,我们将更深入地研究使这些模型专业化的技术!
根据新技能训练模型
大型语言模型位于转换器架构上。近年来,这种结构极大地推动了自然语言处理的进步。在 2017 年的论文“Attention is All You Need”中首次引入,转换器架构通过其基于注意力的机制来理解语言上下文,标志着 NLP 的转折点。
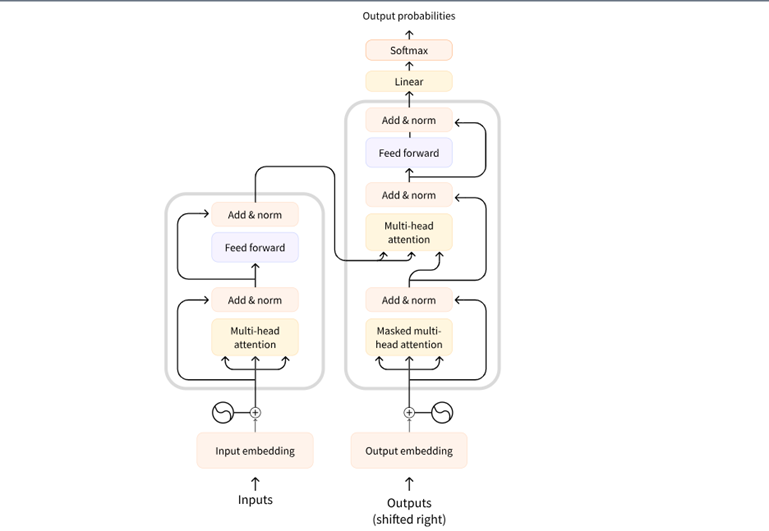
Transformers architecture
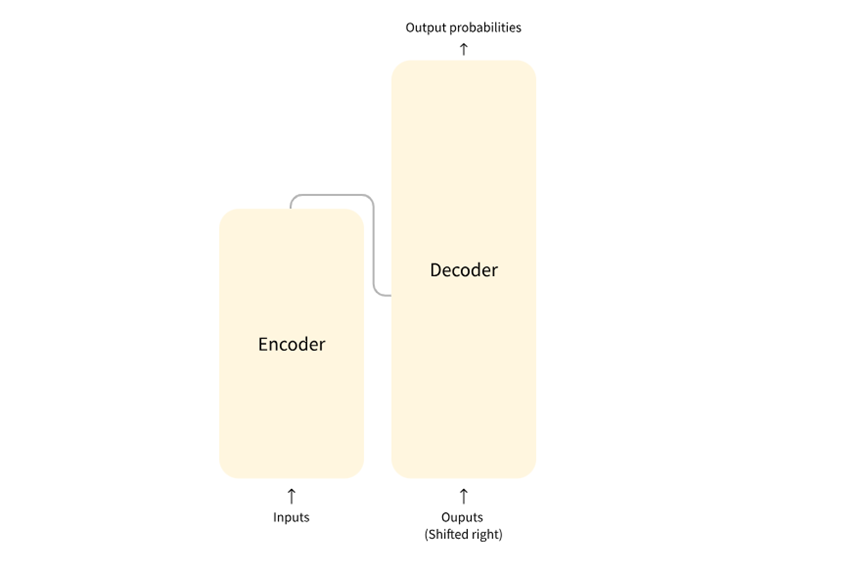
转换器的核心由编码器和解码器组成。编码器读取输入序列(如句子),并创建其抽象表示形式。该向量捕获单词背后的上下文和含义,然后解码器使用该表示来生成输出。
转换器通过注意力机制工作。允许模型专注于输入句子中最重要的单词。该模型根据每个单词在短语或句子中的上下文为每个单词分配权重和重要性。了解微调及其工作原理
转换器架构的突破通过对大量文本数据(包括书籍、网站等)进行训练,使创建功能非常强大的基础模型成为可能。T5、Roberta 和 GPT-3 等流行示例通过接触大量信息来培养强大的通用语言能力。然而,专业领域需要对广泛培训所遗漏的内容进行调整。
例如,我最近参与了一个项目,构建了一个 Web 应用程序,可以检测用户语音中的情感。从语音模式中识别快乐、沮丧或悲伤等感觉,只能通过在情绪数据集上微调预先训练的模型来实现。
弥合这种从宽到窄的差距是微调的用武之地。就像持续学习一样,微调可以通过吸收新信息来增强优势。通过使用特定领域的数据(例如医学期刊或客户对话)训练模型,它们的能力得到了提升,不仅可以匹配,而且可以在这些特定领域表现出色。
现在让我们来探讨一些可用于微调 LLM 的技巧。
微调技术
随着模型变得越来越大,微调所有模型参数可能效率低下,但有一些先进的方法可以只更新关键区域,同时保留有用的知识。让我们来看看其中的一些:
PEFT
PEFT(Parameter Efficient Fine-Tuning)是一个用于高效适应预训练语言模型的库。它可以通过仅更新一小部分内部参数而不是所有权重来适应大型预训练语言模型。这有选择地指导定制,大大降低了微调的计算和存储需求。
LoRa
LoRA是一种通过仅更新小的关键部分而不是直接更新所有大量内部参数来有效微调巨型模型的方法.
它的工作原理是在模型架构中添加薄的可训练层,将训练重点放在需要新知识的内容上,同时保留大多数现有的嵌入式学习。
QloRa
QLoRa通过大幅降低内存需求,允许在消费级GPU 上微调具有数十亿个参数的巨型模型。
它的工作原理是在训练期间将模型大小缩小到微小的 4 位精度。压缩格式显著减少了计算内存的使用量,确保在必要时将精度重新计算为完整格式。此外,微调过程只关注 LoRA 插入的小适配器层, 而不是直接对整个扩展模型进行更改。
微调的实际运用
现在我们已经了解了微调模型,让我们通过实际微调预训练模型来获得实践经验。在本教程中,我们将微调医学领域命名实体识别任务的模型。
这里使用的模型是xlm-roberta-base(https://huggingface.co/xlm-roberta-base),它是RoBERTa的多语言版本,数据集ncbi_disease(https://huggingface.co/datasets/ncbi_disease)包含NCBI疾病语料库的疾病名称和概念注释。
要继续操作,您需要一个 Hugging Face 帐户,这是大型语言模型构建模块的首选平台,我们将用于微调和共享我们的模型。如果您还没有帐户,可以在此处(https://huggingface.co/)创建一个帐户。
动手微调:代码示例
首先是第一件事。我们需要安装三个常用库:transformer、datasets 和 evalate。这将使我们能够访问将用于训练的模型和数据集,并在训练期间获得模型性能。
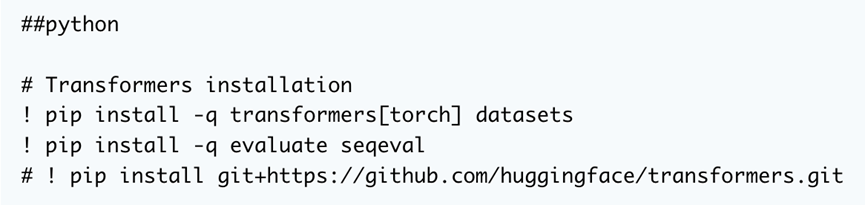
我们可以直接从 GitHub 上的源代码安装该库,以便在我们想要使用最新开发时提供灵活性。

然后,加载专门用于命名实体识别 (NER) 的 NCBI 疾病数据集。NCBI(The National Center for Biotechnology Information,美国国家生物技术信息中心)
如果需要,还可以从中心选择其他数据集,只需确保任何新数据集都适用于尝试微调的内容,然后再使用它。
接下来,我们可以检查测试数据中使用的实际命名实体识别 (NER) 标签。
这输出:

测试数据仅使用三个标签:O 表示超出范围的单词,B - Disease用于标记疾病实体的开始,I-Disease 用于疾病名称后面并构成疾病名称一部分的单词。
序列 ['O', 'B-Disease', 'I-Disease'] 是一组常用于命名实体识别 (NER) 任务的标签。
例如,考虑“患者已被诊断出患有肺癌”这句话。相应的标签为:
“O O O O B-疾病 I-疾病 I-疾病”
在这里,“O”标记不属于疾病实体的单词,“B-疾病”标记开始,“I-疾病”延续实体单词。
现在,我们需要加载一个分词器来预处理文本数据。

这将使用 Transformers 库初始化 xlm-roberta 分词器。
分词器将原始文本格式化为 ID 以供模型理解。这为我们的数据准备了微调预训练模型。
之后,我们需要创建一个函数,该函数将为模型输入准备文本数据。让我们将其分解为三个部分:
在这一部分中,我们使用分词器来处理输入词。它将单词分解成更小的部分,确保模型能够更好地理解它们。
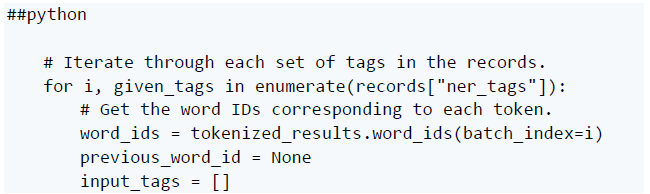
在这里,我们浏览记录中的标签。对于每组标签,我们找出它们在标记化输入中对应的单词(或子单词)。

最后一部分确定每个令牌的标记。如果它是一个特殊的令牌,它会得到一个特定的标记。如果它是一个新词,它会得到适当的标签。如果它是一个子词,它就会获得另一个特定的标签。接下来,将这些分配的标记添加到标记化结果中。

使用分词器分解数据集中的输入词。此步骤会添加特殊标记,并可能将单个单词拆分为较小的部分。
然后,您可以打印出键和值:
完成此操作后,我们可以使用 id2label 和 label2id 创建预期标记 ID 到其标记名称的映射:

在此阶段,我们可以使用 Transformers 库加载预训练模型,提供预期标记的数量和标记映射。

要训练模型,请使用 Hugging Face Trainer API。它初始化默认的训练参数:

然后训练模型:
此时,我们可以使用默认训练参数将模型推送到 Hub。但是,让我们先进行一些推理,然后可以更具体地针对数据自定义训练参数。

使用管道函数调用模型并对文本进行分类:

由于 Trainer 在训练过程中不会自动评估模型性能,我们需要给它传递一个函数来计算和显示指标,而Hugging Face评估库可以提供帮助,它只是提供了准确性函数,你可以用 evaluate.load() 加载。
首先,导入库:

然后,创建使用它的评估函数:


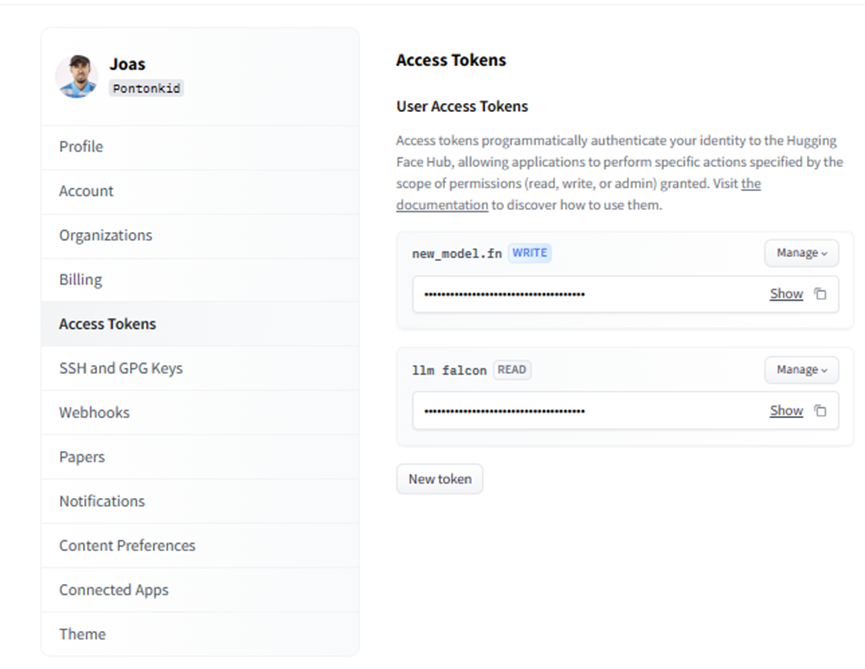
现在可以为模型定义训练参数了。但首先,登录到 Hub,以便稍后上传模型:

我们可以访问帐户中的令牌,只需确保它具有“写入”访问权限即可。
然后,指定训练超参数:


到了使用这些计算指标训练模型的时候了。
首先,重新加载原始的 xlm-roberta 模型和分词器: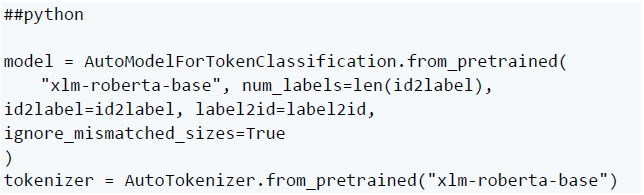
接下来,使用准确性指标和特定的 TrainingArguments 对其进行微调:

完成后,可以将模型推送到 Hub:

现在,我们已使用自定义训练参数和指标在 NCBI 疾病数据集上成功微调了预训练模型。
用于微调LLM 的工具
现在使用最小化编码或使用完全可视化界面的工具,可以更轻松地微调自己的语言模型。
让我们看看任何人都可以用来微调模型的一些选项:
Lamini
Source:Lamini
微调套件

Source:Cohere
首先,Cohere 是一个 NLP 平台,它为开发人员提供了对预构建的大型语言模型的访问,用于文本摘要、生成和分类等自然语言任务。
Cohere 现在允许使用新的微调选项轻松自定义模型,例如:
聊天专业化 - 个性化、上下文感知的对话能力
搜索/推荐专业知识 - 精确匹配用户偏好
多标签分类 - 跨多个属性有效地标记内容
它们通过微调 Web UI 或 Python SDK 选项来实现专业训练。
Autotrain
HuggingFace提供的不仅仅是模型访问、共享和训练库。他们还提供用于无代码微调的AutoTrain。
它无需编程即可在数据上直观地自定义最先进的模型,通过端到端平台处理上传数据集、训练、评估和部署量身定制的创作。
Galileo LLM Studio
Galileo公司帮助开发语言 LLM 应用程序,提供跨越项目生命周期的模块——从原型实验到生产监控。
Fine-Tune 模块专注于通过自动标记有问题的训练数据来最大限度地提高模型定制质量。这样可以协作识别和解决标签不正确、覆盖范围稀疏或污染专业能力潜力的低质量示例等问题。
当然,除了这里介绍的 Lamini、Cohere 或 AutoTrain 之外,还有许多其他微调工具。但这些选项可以帮助您入门,并随时将您知道的选项添加到列表中。
有效微调的最佳实践
在微调大型语言模型时,遵循一些最佳实践有助于确保获得所需的结果。
这些指南包括以下步骤:
定义目标和任务
我们可以从精确定义模型擅长的任务开始,例如语言翻译、文本分类或摘要。然后在这些更广泛的目标中缩小细节范围。例如,情绪分析可能涉及产品评论、医疗保健报告、法律文件等,每一项都需要稍作调整。
选择正确模型
选择预训练模型,使功能与定义的目标保持一致。我们可以前往 HuggingFace 或 Kaggle 等模型中心开始,然后调查架构基础知识、训练数据以及有关候选人的更多信息。
模型选择还取决于硬件资源,因为尽管效率很高,但较大的模型仍然需要严格的硬件。
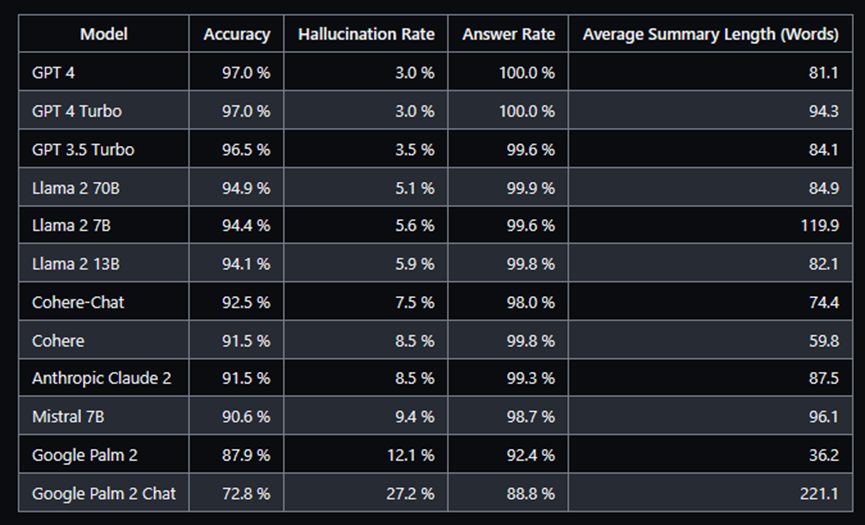
Vectara制作的幻觉(Hallucination)排行榜
如果我们打算微调文本生成或问答任务的模型,可以查看 Vectara 的模型幻觉排行榜或使用他们的模型。
整理高质量的训练数据
在获取数据以微调模型时,质量和相关性非常重要。模型从我们提供的确切训练示例中学习,因此我们必须投喂反映实际需求的有代表性的、准确、干净的示例。
有用的技术包括分词tokenization - 将句子拆分为整齐标准化的单词分组和词形还原。数据处理过程可确保无缝引入和学习。
监控和可观测性
在整个监控过程之前,要取得成功,在训练过程中调整学习率、批量大小和周期等因素非常重要。在开始检查模型中的偏差之前,这是必要的。
训练模型后,可以使用以下工具:
Giskard 来检测模型中嵌入的幻觉或事实不准确等问题。解决这些问题至关重要,因为在将模型部署到生产环境时,它们可能会带来重大风险。
Superwise 或 Langkit 用于大型语言模型监控。
结论
微调模型之后,考虑通过使用 Gradio 或 Streamlit 创建用户友好的应用程序将其提升到一个新的水平。这些框架使应用程序开发变得轻而易举,但有很多选项可供探索。
我们可能还想密切关注用于微调 LLM 的新技术。一个好的开始可能是查看"Language Models are Super Mario" 的论文,所有关于结合专家模型的知识。
原文:(https://bejamas.io/blog/fine-tuning-llms-for-domain-specific-nlp-tasks/ )
审核编辑:刘清
-
【「大模型启示录」阅读体验】如何在客服领域应用大模型2024-12-17 2437
-
创建您自己的Alexa2022-12-19 571
-
亚马逊为何需要推出自己的加密货币2019-07-22 839
-
中国可以做出自己的芯片吗?2018-06-30 29082
-
微星也即将推出自己的非公版显卡:GTX 1080 Ti红龙显卡2017-03-03 1439
-
工程师教您掌控自己的电源设计2013-04-16 3285
-
TI工程师教您掌控自己的电源设计2012-08-04 4587
全部0条评论

快来发表一下你的评论吧 !
