

高阶自动驾驶,需要一颗什么样的芯片?
描述
芯片厂商永远不会放过 CES 的角斗场。
与往届一样,2024 年 CES 的芯片专区也开启了神兽乱斗模式。
一个更加显著的特征是,芯片战场已经从 PC、智能手机转移到了智能汽车。
无论是以英伟达为代表的从游戏起家的老牌芯片厂商,还是以安霸为代表的视觉芯片厂商,都在加码投入到智能汽车自动驾驶芯片的竞争中。
两年前,在 CES 上芯片厂商的关键词是: 期货 、百 Tops 算力。
2022 年 EyeQ Ultra 芯片算力也不过 176 TOPS,英伟达的自动驾驶计算架构 DRIVE Hyperion 9 内置的智能驾驶芯片 Atlan,以跳票告终。
而英伟达发布的另一款算力超 2000TOPS 的 Drive Thor,则要等到 2025 年才投产。
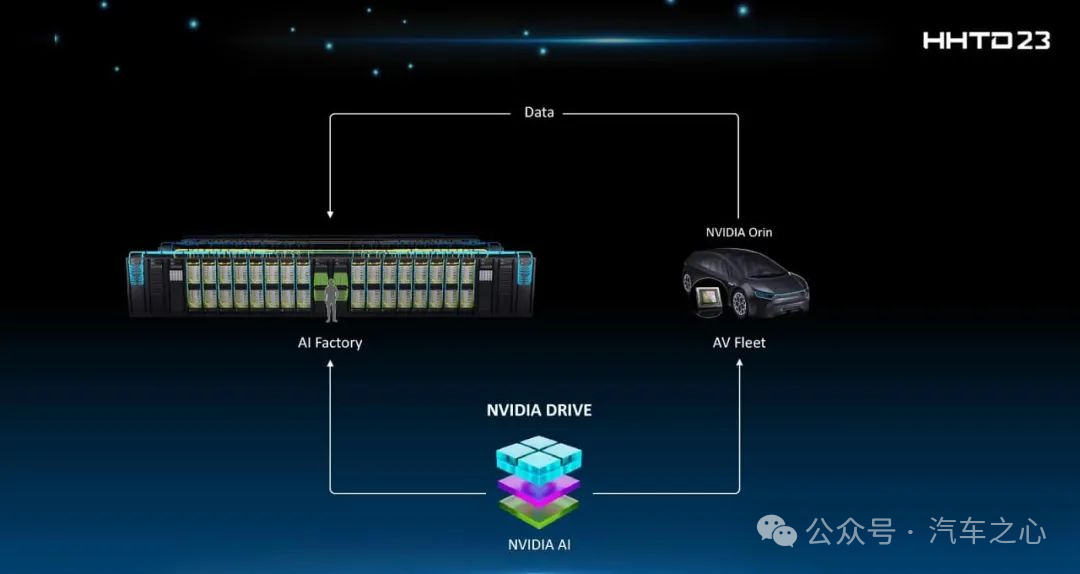
NVIDIA DRIVE Hyperion 9将内置芯片从Atlan换为Thor
两年后,2024 年汽车市场中的芯片关键词则围绕高阶自动驾驶展开:
性价比,大算力、BEV 算法、集中式架构。既要保证价格要能在红海中出圈,又要保证硬件冗余、智驾领先,还要为中央集成式计算平台做好准备。
尤其随着中国车企卷起城区 NOA 大战,**BEV+Transformer **成为头部车企以及自动驾驶厂商最主流的技术方案,更大算力的芯片将承担技术底座。
一个问题横亘在前,高阶自动驾驶,到底需要一颗什么样的芯片?仅仅是大算力就够了吗?
高阶自动驾驶恰好需要一颗「看不见」的芯片。
看不见说的是芯片制程必须更加先进,肉眼可观察到的芯片体积正在缩小,同时也是芯片必须打通过去分布式架构的隔阂,放大芯片一体化、平台化的优势,向****中央计算架构更进一步。
过去,只能看到智驾芯片是算力为王的单边竞争,堆砌足够多的算力就能赢下一局,但高阶智驾到来,看不见的芯片反而要面临的挑战争夺——单边竞争变成了关注性能指标、价格、团队协同的多边竞争。
一体化、大算力、先进制程决定了自动驾驶芯片的底层技术。
成本、性能、功耗决定了车企采用芯片的商业逻辑。
单芯片、强协同、平台化决定了芯片厂商未来的技术发展方向。
随着竞争要素的组合与变化,高阶自动驾驶芯片正掀起新一轮竞争范式。
01
一体化、大算力、先进制程:
智驾芯片进入迭代新周期
如果说过去分布式走向域控制器的过程是靠一个复杂的域控黑盒完成的,那么到了高阶自动驾驶逐渐向中央计算靠拢时,就得用单颗大算力智驾芯片取代盒子。
过去,由于大多数智驾 SoC 无法满足高功能等级安全要求,往往还会在智驾域控主板上外挂独立 MCU,英飞凌、瑞萨、NXP 的 MCU 都是抢手的香饽饽。
现在,多数 SoC 已经内置了 MCU 的功能安全岛,而自动驾驶芯片的变化远不止这一个细节。
业界将自动驾驶芯片的趋势总结成三个关键词:一体化、大算****力、先进制程。
随着市场渗透率的快速提升和 ODD 持续拓展,芯片厂商已普遍采用能力均衡的异构计算平台应对复杂场景考验。
如果过去厨师做是井然有序的川菜、江浙菜、鲁菜,那么今天 GPU、CPU、NPU、ISP 等不同 IP 模块协同作战才是主流,相当于厨师做出了「新式融合菜」。
融合就是取不同处理器所长之处组合在一个芯片中,比如 CPU 擅长逻辑控制和通用计算,GPU 适合大规模并行计算和图像处理,NPU 专注于深度学习算法和人工智能计算,DSP 功耗低,MCU 则安全等级更高。
那么异构计算平台发挥** 1+1+1>3 **的效果,应对多传感器数据不同的计算能力和处理方式,满足路径规划、物体识别、决策控制等不同应用和算法的计算需求。
据汽车之心了解,目前算力在 200TOPS 以上的自动驾驶芯片多采用异构计算,尤其是面向深度神经网络,靠 CPU 一己之力远远不够。
异构计算对芯片带来的改变可以归纳为「两降一提」。
一方面,能够降低整体功耗和散热需求。
另一方面,由于不同的处理器具有不同的故障模式和可靠性特性,通过组合也可以进一步提升系统容错性。
在异构计算平台的背景下,更大算力与更高制程成为必然。
大算力与更高制程呈正相关关系,算力越高也需要制程越先进。
换句话说,算力大小取决于芯片设计,而有着更大算力的芯片能否流片成功,则考验晶圆和制造、封装环节。
汽车之心梳理了现阶段的市场情况,我们发现 2024—2025 年将会集中出现一批算力突破** 1000TOPS **的智驾芯片,相应的,5nm、3nm 乃至更先进制程将成为芯片角力的新战场。
从目前已经释放的大算力芯片来看,2025 年战况焦灼:
英伟达 DRIVE Thor 算力 2000 TOPS,4nm 工艺制程,将于 2025 年投产。
蔚来自研神矶芯片算力预计超过 1000TOPS,5nm 工艺制程,将于 2025 年上车。
特斯拉更为激进,已经准备启动 3nm 制程芯片代工计划,在 N3E 基础上继续强化速度和功耗表现,预计 2024 年投产。

随着芯片制程工艺不断接近物理极限和工程极限,也使得面向 5nm 乃至 3nm 市场的单片晶圆及芯片设计成本同步指数级上升。
据台积电最新报价,仅芯片流片中的制作晶圆费用 3nm 每片晶圆 19865 美元,折合人民币** 14.2 万**元。
而将芯片设计模版复制到半导体硅片上的掩模则更加昂贵。因此,台积电 5nm 芯片全光罩流片费用过亿不足为奇。
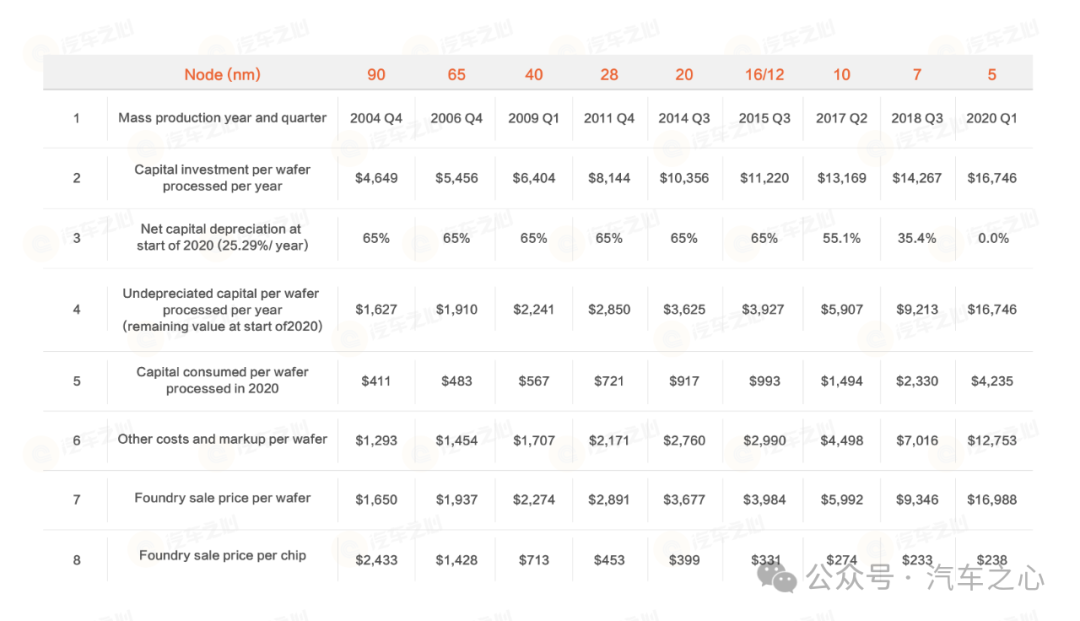
数据来源:The Information Network
一颗小小的智驾芯片,已经是车企、芯片厂商同台秀技术的大舞台。
往往,谁能造出制程更先进的异构智驾芯片,这意味着开发费用与技术实力都不缺。
02
成本、性能、功耗的平衡:
芯片从「不可能三角」到多要素耦合
一体化、大算力、先进制程说的都是技术命题,但智能芯片作为智能驾驶大脑,要投向商业化市场。
商业化市场最残酷的命题是技术与成本的平衡。
因此,智驾芯片并不会不计成本地永远突破性能上限。
以城市 NOA 为代表的 L2++转而对大算力智驾芯片上车提出了多维度的精细要求。
业界期待高阶智驾快速普及的另一面是全行业持续的降本压力。
现阶段,自动驾驶厂商其针对城区 NOA 解决方案也降至万元以下,更不用提车企已经到了把钱掰两半花的地步。
高阶智能驾驶的前景一路坦途,目前 L2+已处在规模化爆发前夜,亟待在合理的性价比区间达到流畅的驾驶体验,并在正式进军城市场景前打好「重感知,轻地图」的头阵。
同时,随着智驾进城,系统不仅需要应对各类复杂场景和偶发情况,脱图的趋势也加大了对于激光雷达的需求。
在此背景下,城市 NOA 的芯片方案还需要在高速 NOA 基础上继续全面升级。
更高算力的芯片虽呼之欲出,硬件资源抢占引发的更加严重的功耗、散热问题同样更加不容忽视,芯片的模块化、拓展性、综合性价比诉求也开始凸显。
在行业内真实存在「搞不定散热」的情况。
一家 Tier1 原来做一体机,后来为车企做行泊一体方案,干了半年发现无法在车企既有车型的预留小空间中搞定散热,白费了半年时间。
现阶段面向 L2+的芯片方案的痛点来源于方方面面,简单概括是成本、算力、利用率、功耗、散热、空间布置等要素间的选择错位:
算力层面:芯片性能虚高,但在实际应用中会碰到性能瓶颈;单芯片方案算力、ISP 普遍性能不足,导致难以充分调动多 V 传感器实现 BEV 感知,跑得了 BEV 方案的成本又太高;
性能层面:双芯片组合方案「貌合神离」,成本高、系统复杂,且难以做到真正的全时行泊一体;芯片就跑不了 BEV 难以最大程度摆脱高精度地图,无法提升性价比;
结构层面:真实算力强的,功耗居高不下,散热措施成问题,加风冷水冷不仅费工费时,在正式上车时还要抢占空间布置;
而以上任意≥2 个要素一旦互相组合出现,就非常容易衍生智驾项目开发的各类过程风险。
应对上述多要素耦合的迫切需求,2023 年,安霸在上海车展期间推出 CV72AQ,用这颗 5nm 车规制程芯片,打响高速 NOA 行泊一体之战。
对一颗智驾芯片来说,最基本的要求是制程先进,算力真实。
CV72AQ 率先发挥 5nm 制程优势,算力适中同时功耗小于 5 瓦,1 秒钟处理** 90 帧 800 万像素**的图像,并实时处理 6 枚摄像头输入;
在芯片结构上改变了过去行业中的「双芯」,采用单芯片设计,延续 ISP、视频编码器等传统强项,直接面向全时行泊一体,硬件资源深度复用,高效运行各类 BEV;
最后在开发工具链上,安霸基于 CVflow AI 开发平台提供一整套易用的算法开发和优化工具,降低产品设计开发成本的同时最大限度地提高软件的可复用性。
如果说 SLAM 算法+深度学习技术是第一代自动驾驶技术,在传感器类型与数量变得更加复杂时,如何持续输入多模态数据成为第一代自动驾驶技术的挑战。
随之 BEV+Transformer 这样全新的第二代自动驾驶技术袭来。
BEV+Transformer 凭借全局性的表征关联、空间/时序的融合能力、跨模态的特征级融合效果为城市 NOA 落地敲开大门后,业界对智驾芯片做「多边形战士」的要求又增加了极为重要的一条:对先进算法的高效支持。

在芯片和算法都在快速迭代的当下,业界普遍的做法仍然是硬件优先——先确定一个各方面性能均衡的异构计算平台,再基于硬件部署算法方案,进行优化、调度、通讯部署并逐步解决工程挑战。
但是,新一轮 BEV+Transformer 带来的却是从算法渗透到芯片的变革压力,解决两者间耦合的错配问题,与芯片本身的成本、性能、功耗平衡同样迫切。
一个业内普遍的困扰是,目前市面上大部分的自动驾驶芯片均是在 Transformer 出现之前设计的,对 Transformer 的支持并不友好。
BEV+Transformer 越热,就意味着不支持这一技术架构的芯片在未来的竞争中越有可能出局。
芯片厂商及车企接下来很可能在产品开发层面马上进行适应性调整。
在此之前,业内已经普遍在积极寻求折中方案,包括但不限于算子的重新适配,深度的网络架构和底层软件优化,以及改善带宽要求。
但这样的针对性优化方案在小网络上效果尚可,应对更大的算法模型,挑战仍然不可持续。
安霸半导体副总裁刘清涛则表示,安霸虽然是一家芯片供应商,但一贯遵循「算法优先」策略,尤其是考虑到 AI 算法仍然在快速演进,因此在芯片开发过程中会广泛测试和评估开源网络和自研算法,评估当下主流神经网络的同时超前考虑未来算法方向。
在 AI 域控制器芯片 CV3-AD 的开发过程中,安霸就测试了几百种的开源算法,甚至整个芯片的开发都是围绕着通用型算法进行的优化,包括对 Transformer 神经网络进行了专门的支持。
这也是 CV3-AD 在更早前的 2022 年 CES 上发布,却能支持后来流行的用于 BEV 的 Transformer 算法的根本原因。
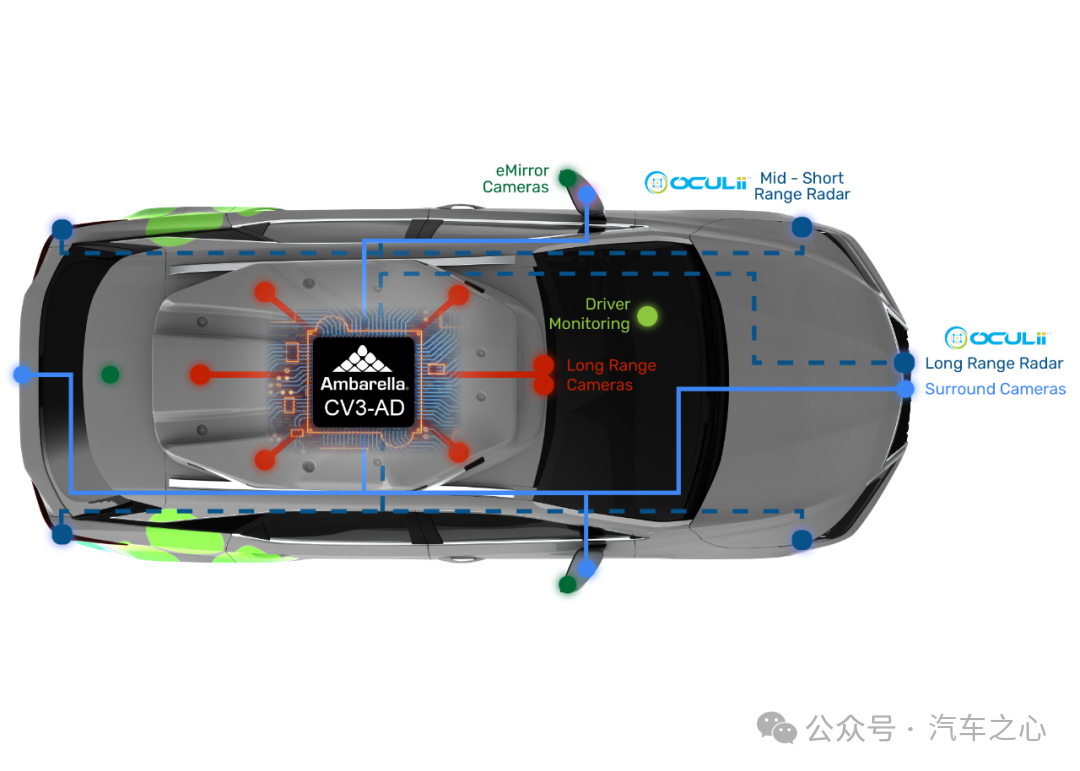
在今年的 CES 上,安霸发布了 CV3-AD 系列芯片的最新产品:
CV3-AD635 和 CV3-AD655。
其中,CV3-AD635 高效支持多个摄像头及毫米波雷达,可实现主流的 L2+ 自动驾驶功能,如高速公路自适应巡航和自动泊车;
CV3-AD655 支持更高等级的 L2++ 和城区自动驾驶功能,并高效支持更多的摄像头、毫米波雷达、激光雷达和其他传感器。
联合此前发布的两款芯片:
适用 L3/L4 自动驾驶系统的旗舰产品 CV3-AD685 和主打中国市场的 CV72AQ,CV3-AD 系列芯片算力覆盖范围广,可以满足汽车厂商从主流车型到中高端车型的算力要求。
在神经网络处理能力方面,CV3-AD685 是 CV3-AD655 的** 3 倍**;CV3-AD655 是 CV3-AD635 的 2 倍。
据安霸介绍,从 CV72AQ 到 CV3-AD685,芯片的 AI 性能提高到 18 倍,是目前「汽车行业中性能覆盖范围最广的、兼容性最好的 AI 域控芯片系列」。

安霸芯片登上的量产车型
这背后是安霸自研的一套 AI 算法加速硬件引擎 CVflow——采用特殊的流架构、支持非结构化稀疏,内嵌多种非线性运算加速硬件,同时又和 ISP 集成在一起。
这带来的好处是:在真实环境运行 Transformer 算法时 AI 性能、性能功耗比和内存带宽效率优势明显。
03
单芯片、强协同、平台化:
高阶智驾芯片产业再升级
高阶智驾芯片解决要素错配,不是某一家企业能推动得了,而要靠汽车芯片产业技术路线再升级。
这一技术路线升级可以概括为:
单芯片、强协同、平台****化。
过去,英伟达和 TI 分别在高算力、低算力芯片上占据多芯片行泊一体方案的半壁江山。
特别是前期面向高阶智驾需求,算法的演进路径尚不清晰的行业现象,车企们普遍先拼配置、做硬件预埋、准备系统冗余,双 Orin 乃至 4 Orin 的方案率先成为主流方案。
这背后也存在一个原因——高阶智驾渗透前期,通用芯片更受欢迎。
从芯片设计理念出发:
通用芯片无法为了没有固化的业务作出灵活改变,比如 GPU、FPGA 是目前比较成熟的通用型芯片。通用芯片在设计之初会加入预留模块,优点是通用性高、修改性强,但相应地功耗高、价格也更贵。
专有芯片是针对固化业务进一步「降本增效」,专用芯片针对单一功能设计,速度快、功耗低,相应成本也更低。
在高阶智驾渗透前期,需要给芯片留出「试错空间」,因此英伟达 Orin 系列芯片作为通用芯片大受欢迎。
但随着高阶智驾逐渐走向深水区,专用芯片则会成为必然趋势。

比如安霸 CV3-AD 系列芯片就是专用芯片,支持各种网络模型,大到 LLM(多模态大模型),小到各种嵌入式前端的网络。
但专用芯片只是增本增效的第一步,单芯片方案对算力资源的深度复用及成本优势,有望使其成为大算力域控的长远终极方案。
相比于多芯片,单芯片如果匹配充足 AI 的算力支持及多源异构架构设计,可以满足高阶智驾所需的各类传感器接入,与之匹配各类存储器和带宽需求并预留扩充接口,各类 buff 叠满后相比多芯片有天然优势:
传感器深度复用,计算资源完全共享,AI 算力需求可比多芯片大幅降低;
不再需要与各自 SoC 配套的多套电源芯片和存储芯片,更具成本优势;
芯片级稳定性天然高于板级稳定性,两套系统间交互衍生的开发难度和开发成本也不复存在。
安霸半导体副总裁刘清涛表示,多芯片只是权宜之计,从成本上来说双芯片要两套电源,从稳定性来说,单芯片级别的稳定性与连接板级别的稳定性不可同日而语。
眼下,以安霸为代表的单芯片行泊一体方案均已陆续登场,志在单颗芯片包打全场景 NOA。
在高阶智驾开发中,芯片和算法的关系已完全不同于传统的逻辑计算架构。
如果说过去两者的关系是芯片先行,算法在后,那今天,两者的关系变成了相互定制。
芯片在设计之初,就需要考虑后续实际运行的先进算法架构,算法的设计过程既需要、也有极大机遇根据芯片硬件架构适配升级。
在此背景下,芯片公司做自动驾驶软件的驱动力不断凸显,一方面为下一代 AI 芯片或 AI 引擎进行开展算法预研,更进一步改善芯片架构或微架构,推动部署优化,甚至打通是算法和芯片,提升可扩展性。
以英伟达、安霸为代表的芯片厂商,已经在软硬协同、全栈优化方面动作频频。这些芯片厂商基本上都以「芯片+开发工具链」的形式给到客户。
更有压力的是,蔚来、理想、比亚迪等车企也都陆续向上游芯片自研摩拳擦掌。
安霸则根植于「算法优先」已先行一步,一方面在芯片开发过程中保持领先架构,同时作为一家 AI 视觉芯片公司,也一直在下一局关于「算法」的棋局。
一家企业的禀赋总是与其诞生背景息息相关。
过去,ISP、图像处理、视频压缩编码算法是安霸在消费、安防、汽车等领域的一贯长项,这决定了其在自动驾驶图像视觉上天然的禀赋。
安霸先后的两次收购动作则增强了其在自动驾驶算法的业务能力。
比如 2015 年收购 VisLab 后,安霸在硬件层面整合了自动驾驶感知算法。在 2021 年收购傲酷后,安霸吸纳了大量 4D 毫米波雷达及融合算法。
一个案例是,安霸在 CV3 中就去掉雷达前端 DSP,用 GVP 专门处理雷达信息,实现原始数据集中处理和底层跨模态融合。
CV3 系列芯片是安霸算法先行的代表之作。
安霸的 CV3 系列芯片采用新一代 CVflow 架构,其中神经矢量处理器 NVP 通过对 Transformer 网络进行硬件加速,支持 BEV+Transformer 算法更快落地。
业界对芯片的期待更是结构性的降本增效,从而系统支持智驾带来的销量红利,在激烈竞争中突出重围。
这也对芯片的「平台化」提出了更高要求。
安霸 CV3 全系列统一 SDK,这意味着在一套硬件架构下实现算法、中间件、应用软件等各层面迁移复用,从而覆盖不同自动驾驶等级和各个智驾细分领域,释放芯片的硬件潜力和利用效率,节约投入的同时缩短开发周期。
安霸总裁兼 CEO 王奉民曾表示,安霸已经把中国市场作为全球战略重点,CV3 系列的首批收入也将来自中国。
现在,智驾芯片更像是智驾技术、车企定制化需求、再带点营销词汇的内卷产物。
就像今天,我们说算力,有的厂商会用 GPU 的乘积累加矩阵运算算力来定义,有的厂商会在这个基础上加上每秒图像帧率 FPS 的数据。
但走上城区道路的高阶智驾到底需要怎样的芯片,除了以上总结的多个趋势外,一个概念也会越发清晰:
高阶智驾需要的芯片,不只在于芯片本身,更在于其是否能够去伪存真,更加标准化深度参与智驾功能的开发。
这考验的其实是「厚积薄发」的能力。
高阶智驾市场是新一轮的牌局,而最适合高阶智驾的芯片一定会在最卷的中国市场率先被验证。
审核编辑:刘清
-
【话题】特斯拉首起自动驾驶致命车祸,自动驾驶的冬天来了?2016-07-05 14464
-
自动驾驶真的会来吗?2016-07-21 14628
-
细说关于自动驾驶那些事儿2017-05-15 7273
-
自动驾驶的到来2017-06-08 7498
-
UWB主动定位系统在自动驾驶中的应用实践2018-12-14 3331
-
车联网对自动驾驶的影响2019-03-19 3619
-
如何让自动驾驶更加安全?2019-05-13 3797
-
自动驾驶汽车的处理能力怎么样?2019-08-07 2939
-
为何自动驾驶需要5G?2020-06-08 4329
-
自动驾驶为什么需要5G2020-07-31 2796
-
UWB定位可以用在自动驾驶吗2020-11-18 3711
-
自动驾驶AI芯片现状分析2020-12-04 2839
-
乘坐自动驾驶汽车到底什么感觉?未来的汽车会是什么样的?2019-04-01 1864
-
自动驾驶芯片赛道的玩家众多 已形成百舸争流之势2019-11-20 779
-
真正的自动驾驶时代到来应该是什么样的?2021-04-29 3565
全部0条评论

快来发表一下你的评论吧 !
