

Transformers的功能概述
电子说
描述
近年来,我们听说了很多关于Transformers的事情,并且在过去的几年里,它们已经在NLP领域取得了巨大成功。Transformers是一种使用注意力机制(Attention)显著改进深度学习NLP翻译模型性能的架构。它首次在论文Attention is all you need中被引入,并迅速确立为大多数文本数据应用的主导架构。
自那时以来,包括Google的BERT和OpenAI的GPT系列在内的众多项目已经在这个基础上进行了扩展,并发布了比现有最先进基准更好的性能结果。
在一系列的文章中,我将介绍Transformers的基础知识、其架构以及内部工作原理。我们将以自上而下的方式了解Transformers的功能。
在后续的文章中,我们将深入了解系统的运作细节。我们还将深入研究多头注意力(multi-head attention)的运作,这是Transformers的核心。
以下是本系列和接下来文章的快速摘要(共计四篇)。我的目标是理解事物的运作方式,而不仅仅是了解它是如何运作的。
功能概述 — 本文(Transformers的用途以及为什么它们比RNN更好。架构的组件,以及在训练和推断期间的行为)。
工作原理(内部操作端到端。数据如何流动以及执行了哪些计算,包括矩阵表示)。
多头注意力(贯穿整个Transformers的注意力模块的内部运作)。
为什么注意力提高性能(不仅仅是注意力在做什么,而是为什么它如此有效)。
后面三篇推文进行介绍。
为适合中文阅读习惯,阅读更有代入感,原文翻译后有删改。
1. 什么是Transformers
Transformers架构擅长处理本质上是顺序(sequential)的文本数据。它们将文本序列作为输入并生成另一个文本序列作为输出,例如将英语句子翻译成西班牙语。
(作者提供的图像)
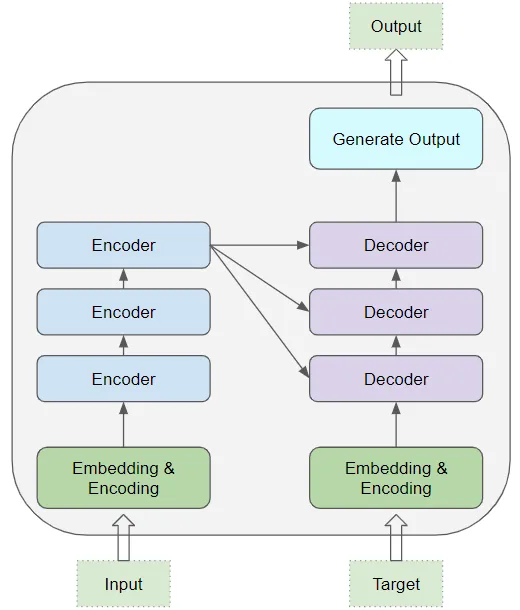
在其核心,它包含堆叠的编码器层(Encoder layers)和解码器层(Decoder layers)。
为避免混淆,我们将个体层称为编码器(Encoder)或解码器(Decoder)。
编码器堆栈和解码器堆栈分别有相应的嵌入层用于它们的输入。最后,有一个输出层用于生成最终输出。
(作者提供的图像)
所有编码器彼此相同。同样,所有解码器也是相同的。
(作者提供的图像)
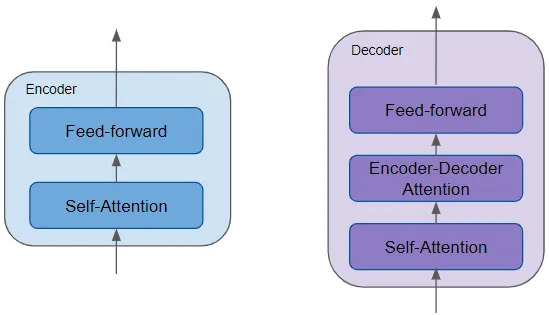
编码器包含非常重要的自注意力层,用于计算序列中不同单词之间的关系,以及一个前馈层。
解码器包含自注意力层和前馈层,以及第二个编码器-解码器注意力层。
每个编码器和解码器都有自己的权重集。
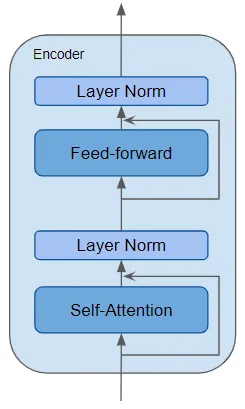
编码器是所有Transformers架构的定义性组件,是可重复使用的模块。除了上述两个层外,它还在这两个层周围具有残差跳过连接(Residual skip connections),并带有两个LayerNorm层。
(作者提供的图像)
Transformers架构有许多变体。有些Transformers架构根本没有解码器,完全依赖于编码器。
2. 注意力的作用是什么?
Transformers取得突破性性能的关键在于它对注意力的使用。
在处理一个单词时,注意力使模型能够关注输入中与该单词密切相关的其他单词。
例如,ball与blue和holding密切相关。另一方面,blue与boy无关。
Transformers架构通过将输入序列中的每个单词与其他每个单词相关联来使用自注意力。
例如,考虑两个句子:
The cat drank the milk because it was hungry.
The cat drank the milk because it was sweet.
在第一个句子中,it指的是cat,而在第二个句子中,它指的是milk。当模型处理it这个词时,自注意力为模型提供更多关于其含义的信息,以便它能将it与正确的词关联起来。

深色表示更高的注意力(作者提供的图像)
为了使其能够处理关于句子意图和语义的更多细微差别,Transformers为每个单词包含多个注意力分数。
例如,在处理it这个词时,第一个分数突出显示cat,而第二个分数突出显示hungry。因此,当它将it这个词解码成另一种语言时,它将在翻译的词中结合cat和hungry的一些方面。

(作者提供的图像)
3. 训练Transformers
在训练和推断期间,Transformers的工作稍有不同。
首先,让我们看看训练期间数据的流动。训练数据包括两个部分:
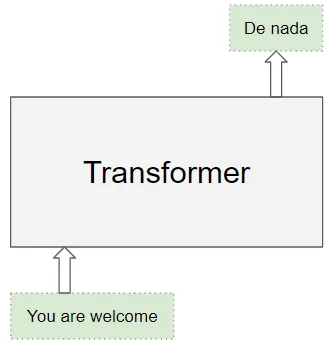
源序列或输入序列(例如,对于一个翻译问题,You are welcome是英语的源序列)
目标序列(例如,西班牙语中的De nada是目标序列)
Transformers的目标是通过使用输入和目标序列来学习如何输出目标序列。
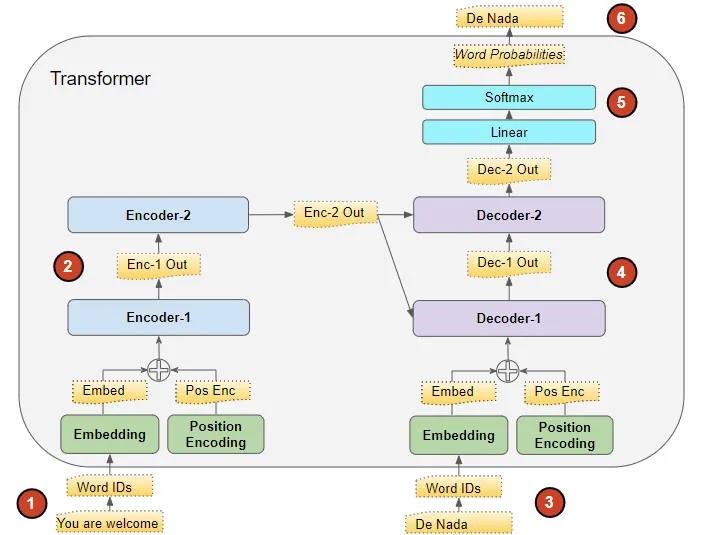
(作者提供的图像)
Transformers处理数据的步骤如下:
将输入序列转换为嵌入(带有位置编码)并馈送到编码器。
编码器堆栈处理此数据并生成输入序列的编码表示。
目标序列以句子开始标记为前缀,转换为嵌入(带有位置编码)并馈送到解码器。
解码器堆栈处理此数据以及编码器堆栈的编码表示,生成目标序列的编码表示。
输出层将其转换为单词概率和最终输出序列。
Transformers的损失函数将此输出序列与训练数据中的目标序列进行比较。这个损失用于在反向传播期间训练Transformers生成梯度。
4. 推断
在推断期间,我们只有输入序列,并没有目标序列传递给解码器。Transformers的目标是仅从输入序列中产生目标序列。
因此,就像在Seq2Seq模型中一样,我们在一个循环中生成输出,并将上一个时间步的输出序列馈送到下一个时间步的解码器,直到遇到句子结束标记。
与Seq2Seq模型的不同之处在于,在每个时间步,我们重新馈送迄今生成的整个输出序列,而不仅仅是最后一个单词。
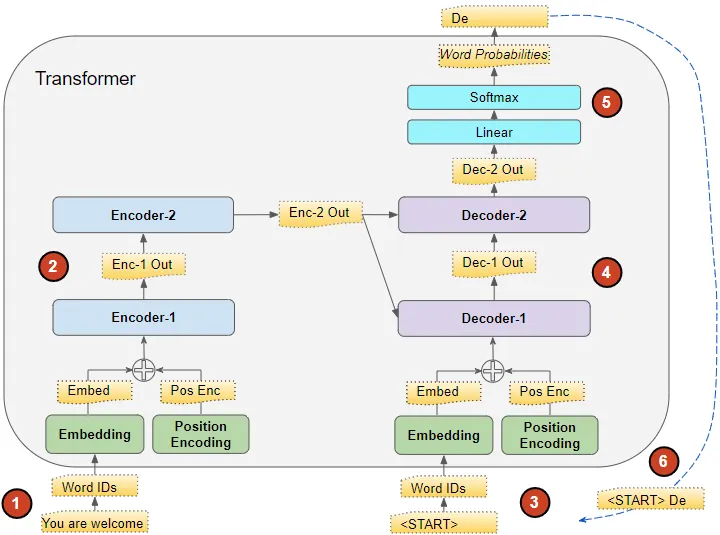
第一时间步后的推断流程(图像由作者提供)
推断期间数据的流动如下:
输入序列被转换为嵌入(带有位置编码)并馈送到编码器。
编码器堆栈处理此数据并生成输入序列的编码表示。
与目标序列不同,我们使用一个只有句子开始标记的空序列。这被转换为嵌入(带有位置编码)并馈送到解码器。
解码器堆栈处理此数据以及编码器堆栈的编码表示,生成目标序列的编码表示。
输出层将其转换为单词概率并生成输出序列。
我们将输出序列的最后一个词视为预测的词。该词现在填入解码器输入序列的第二个位置,其中现在包含一个句子开始标记和第一个单词。
返回到步骤#3。与以前一样,将新的解码器序列馈送到模型。然后取输出的第二个词并将其附加到解码器序列。重复此过程,直到预测到句子结束标记。请注意,由于编码器序列在每次迭代中不变,因此我们不必每次重复步骤#1和#2(感谢Michal Kučírka指出这一点)。
5. Teacher Forcing(强制教师)
在训练期间将目标序列馈送到解码器的方法被称为强制教师。我们为什么要这样做,这个术语是什么意思?
在训练期间,我们本可以使用与推断期间相同的方法。换句话说,循环运行Transformers,取输出序列的最后一个词,将其附加到解码器输入并在下一次迭代中馈送给解码器。最终,当预测到句子结束标记时,损失函数将比较生成的输出序列与目标序列,以便训练网络。
这种循环会导致训练时间更长,而且使训练模型变得更加困难。模型必须基于可能错误的第一个预测单词来预测第二个单词,依此类推。
相反,通过将目标序列馈送到解码器,我们可以说是在给予它一些提示,就像老师会做的一样。即使它预测了错误的第一个单词,它仍然可以使用正确的第一个单词来预测第二个单词,以防这些错误不断累积。
此外,Transformers能够在没有循环的情况下并行输出所有单词,从而大大加快训练速度。
6. Transformers用于什么?
Transformers非常灵活,用于大多数NLP任务,如语言模型和文本分类。它们经常用于序列到序列模型,适用于机器翻译、文本摘要、问答、命名实体识别和语音识别等应用。
有不同类型的Transformers架构用于解决不同的问题。基本的编码器层被用作这些架构的通用构建块,具体取决于正在解决的问题,使用不同的应用特定的头(heads)。
7. Transformers分类架构
例如,情感分析应用将接受文本文档作为输入。分类头采用Transformers的输出,并生成类标签的预测,如积极或消极情感。
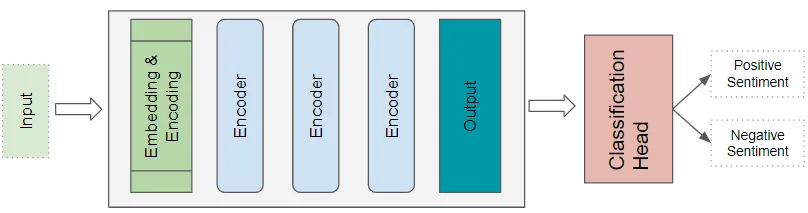
(作者提供的图像)
8. Transformers语言模型架构
语言模型架构将输入序列的初始部分,如文本句子,作为输入,并通过预测将跟随的句子生成新文本。语言模型头采用Transformers的输出,并为词汇表中的每个单词生成概率。概率最高的单词成为下一个句子中的预测输出。
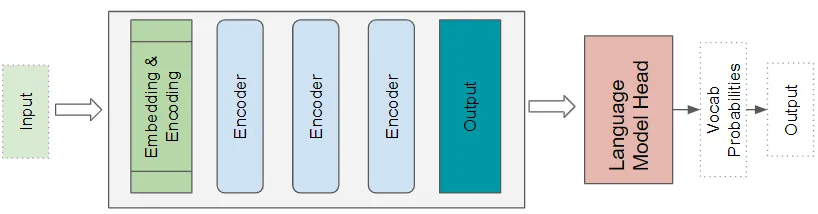
(作者提供的图像)
9. 它们为什么比循环神经网络(RNNs)更好?
在Transformers出现并取代它们之前,基于RNN的序列到序列模型是所有NLP应用的事实标准,而且表现良好。
基于RNN的序列到序列模型表现不错,当注意机制首次引入时,它被用于增强其性能。
然而,它们有两个限制:
难以处理在长句中分散分开的单词之间的长程依赖关系。
它们按照顺序逐个单词地处理输入序列,这意味着在完成时间步t-1的计算之前,它不能进行时间步t的计算。这减缓了训练和推断的速度。
顺便提一下,使用CNN,所有输出可以并行计算,这使得卷积速度更快。然而,它们在处理长程依赖性方面也有局限性:
在卷积层中,只有能够适应内核大小的图像的部分(如果应用于文本数据,则是单词)可以相互交互。对于相距较远的项,您需要具有许多层的更深的网络。Transformers架构解决了这两个限制。它完全摒弃了RNN,并仅依赖于注意力的好处。
它并行处理序列中的所有单词,从而大大加快了计算速度。
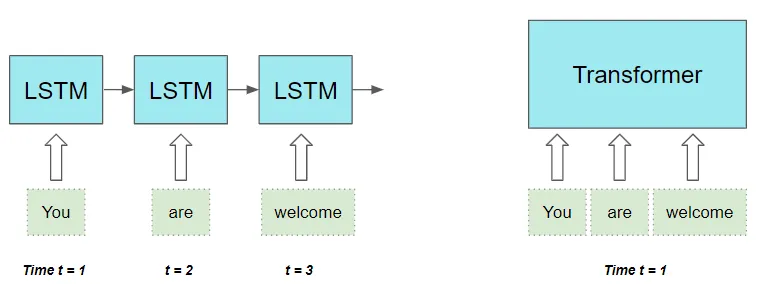
(作者提供的图像)
输入序列中单词之间的距离不重要。它在计算相邻单词和相距较远单词之间的依赖性方面同样出色。
现在我们对Transformers有了一个高层次的了解,我们可以在下一篇文章中深入了解其内部功能,了解它的工作细节。
来源:新机器视觉
审核编辑:汤梓红
-
TDK SMD Transformers E13 EMHV系列:高性能贴片变压器的卓越之选2025-12-26 1205
-
使用基于Transformers的API在CPU上实现LLM高效推理2024-01-22 4378
-
Transformers是什么意思?人工智能transformer怎么翻译?2023-08-22 5054
-
在线研讨会 | 释放 Vision Transformers、NVIDIA TAO 和最新一代 NVIDIA GPU 的潜力2023-06-16 1363
-
深度学习:transformers的近期工作成果综述2022-10-19 1479
-
CS5202AN功能概述2022-03-02 2831
-
GPIO的功能概述用途简析2022-02-16 980
-
GPIO多功能复用引脚概述2022-01-12 1664
-
W601的RTC时钟功能概述2022-01-10 1001
-
长按键处理功能概述2022-01-07 1005
-
MicroBlaze的特点与功能概述2018-11-28 4493
-
QorIQ三大功能概述(三)2018-06-28 3353
-
BJDEEN PULSE TRANSFORMERS2010-06-11 827
-
纽曼数码录音笔功能概述2009-12-22 1314
全部0条评论

快来发表一下你的评论吧 !
