

字节发布机器人领域首个开源视觉-语言操作大模型,激发开源VLMs更大潜能
描述
还在苦苦寻找开源的机器人大模型?试试RoboFlamingo!
近年来,大模型的研究正在加速推进,它逐渐在各类任务上展现出多模态的理解和时间空间上的推理能力。机器人的各类具身操作任务天然就对语言指令理解、场景感知和时空规划等能力有着很高的要求,这自然引申出一个问题:能不能充分利用大模型能力,将其迁移到机器人领域,直接规划底层动作序列呢?
对此,ByteDance Research 基于开源的多模态语言视觉大模型 OpenFlamingo 开发了开源、易用的 RoboFlamingo 机器人操作模型,只用单机就可以训练。使用简单、少量的微调就可以把 VLM 变成 Robotics VLM,从而适用于语言交互的机器人操作任务。
OpenFlamingo 在机器人操作数据集 CALVIN 上进行了验证,实验结果表明,RoboFlamingo 只利用了 1% 的带语言标注的数据即在一系列机器人操作任务上取得了 SOTA 的性能。
随着 RT-X 数据集开放,采用开源数据预训练 RoboFlamingo 并 finetune 到不同机器人平台,将有希望成为一个简单有效的机器人大模型 pipeline。论文还测试了各种不同 policy head、不同训练范式和不同 Flamingo 结构的 VLM 在 Robotics 任务上微调的表现,得到了一些有意思的结论。

项目主页:https://roboflamingo.github.io/
代码链接:
https://github.com/RoboFlamingo/RoboFlamingo
论文链接:
https://arxiv.org/abs/2311.01378
研究背景
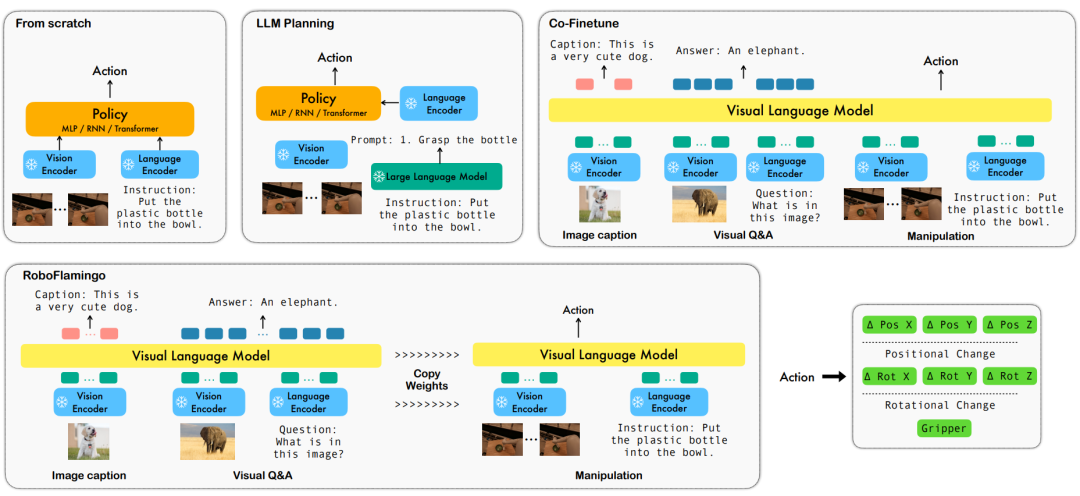
基于语言的机器人操作是具身智能领域的一个重要应用,它涉及到多模态数据的理解和处理,包括视觉、语言和控制等。近年来,视觉语言基础模型(VLMs)已经在多个领域取得了显著的进展,包括图像描述、视觉问答和图像生成等。然而,将这些模型应用于机器人操作仍然存在一些挑战,例如如何将视觉和语言信息结合起来,如何处理机器人操作的时序性等。
为了解决这些问题,ByteDance Research 的机器人研究团队利用现有的开源 VLM,OpenFlamingo,设计了一套新的视觉语言操作框架,RoboFlamingo。其中 VLM 可以进行单步视觉语言理解,而额外的 policy head 模组被用来处理历史信息。只需要简单的微调方法就能让 RoboFlamingo 适应于基于语言的机器人操作任务。
RoboFlamingo 在基于语言的机器人操作数据集 CALVIN 上进行了验证,实验结果表明,RoboFlamingo 只利用了 1% 的带语言标注的数据即在一系列机器人操作任务上取得了 SOTA 的性能(多任务学习的 task sequence 成功率为 66%,平均任务完成数量为 4.09,基线方法为 38%,平均任务完成数量为 3.06;zero-shot 任务的成功率为 24%,平均任务完成数量为 2.48,基线方法为 1%,平均任务完成数量是 0.67),并且能够通过开环控制实现实时响应,可以灵活部署在较低性能的平台上。
这些结果表明,RoboFlamingo 是一种有效的机器人操作方法,可以为未来的机器人应用提供有用的参考。
方法
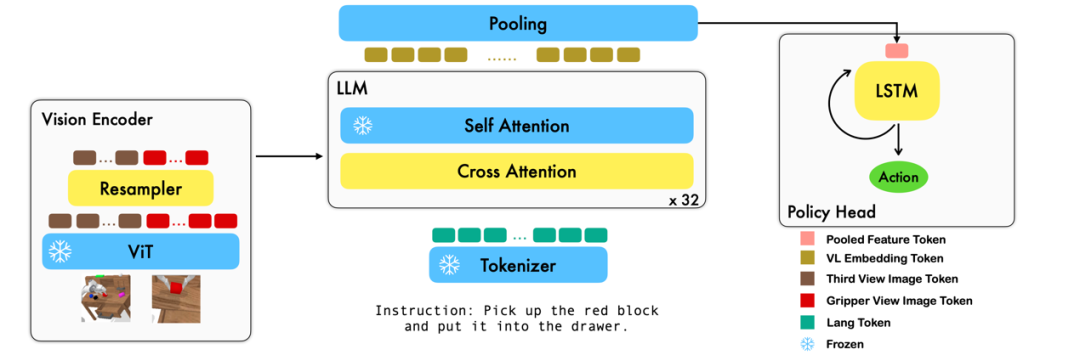
本工作利用已有的基于图像 - 文本对的视觉语言基础模型,通过训练端到端的方式生成机器人每一步的 relative action。模型的主要模块包含了 vision encoder,feature fusion decoder 和 policy head 三个模块。
Vision encoder 模块先将当前视觉观测输入到 ViT 中,并通过 resampler 对 ViT 输出的 token 进行 down sample。
Feature fusion decoder 将 text token 作为输入,并在每个 layer 中先将 vision encoder 的 output 作为 query 进行 cross attention,之后进行 self attention 以完成视觉与语言特征的融合。
最后,对 feature fusion decoder 进行 max pooling 后将其送入 policy head 中,policy head 根据 feature fusion decoder 输出的当前和历史 token 序列直接输出当前的 7 DoF relative action,包括了 6-dim 的机械臂末端位姿和 1-dim 的 gripper open/close。
在训练过程中,RoboFlamingo 利用预训练的 ViT、LLM 和 Cross Attention 参数,并只微调 resampler、cross attention 和 policy head 的参数。
实验结果
数据集:
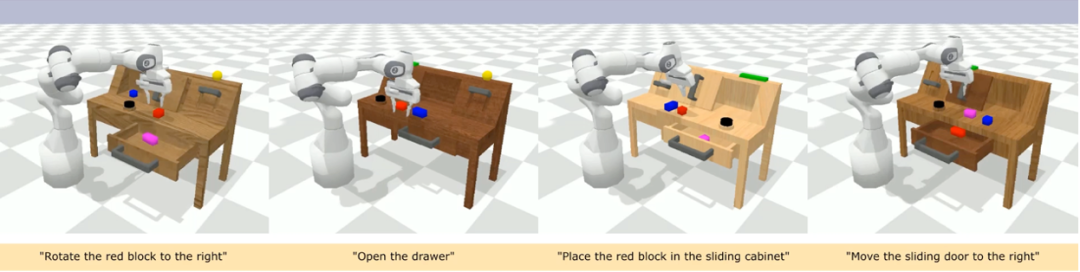
CALVIN(Composing Actions from Language and Vision)是一个开源的模拟基准测试,用于学习基于语言的 long-horizon 操作任务。与现有的视觉 - 语言任务数据集相比,CALVIN 的任务在序列长度、动作空间和语言上都更为复杂,并支持灵活地指定传感器输入。CALVIN 分为 ABCD 四个 split,每个 split 对应了不同的 context 和 layout。
定量分析:
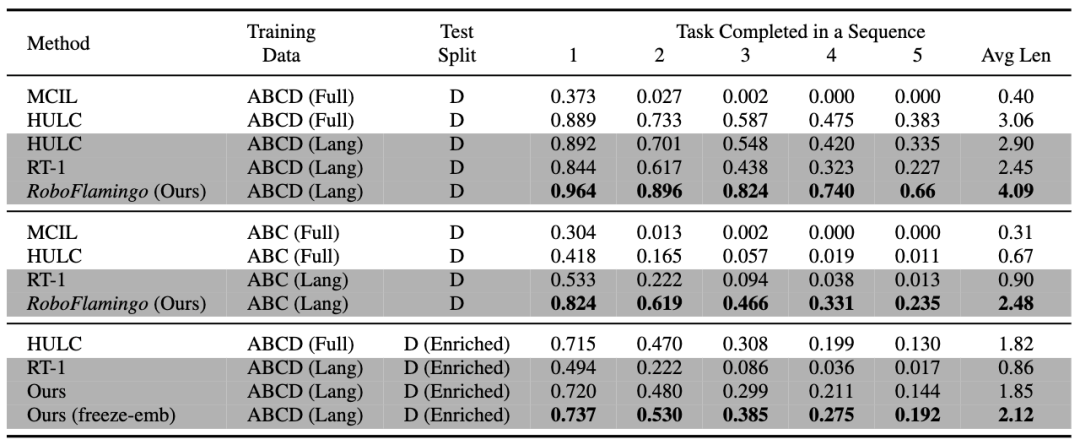
RoboFlamingo 在各设置和指标上的性能均为最佳,说明了其具有很强的模仿能力、视觉泛化能力以及语言泛化能力。Full 和 Lang 表示模型是否使用未配对的视觉数据进行训练(即没有语言配对的视觉数据);Freeze-emb 指的是冻结融合解码器的嵌入层;Enriched 表示使用 GPT-4 增强的指令。
消融实验:
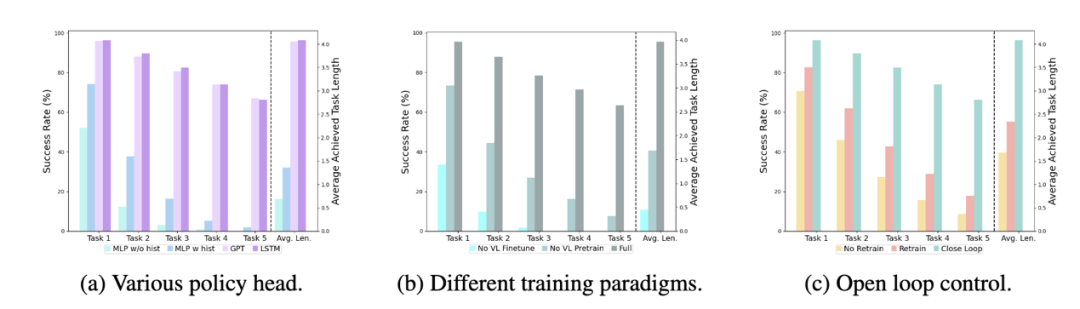
不同的 policy head:
实验考察了四种不同的策略头部:MLP w/o hist、MLP w hist、GPT 和 LSTM。其中,MLP w/o hist 直接根据当前观测预测历史,其性能最差,MLP w hist 将历史观测在 vision encoder 端进行融合后预测 action,性能有所提升;GPT 和 LSTM 在 policy head 处分别显式、隐式地维护历史信息,其表现最好,说明了通过 policy head 进行历史信息融合的有效性。
视觉-语言预训练的影响:
预训练对于 RoboFlamingo 的性能提升起到了关键作用。实验显示,通过预先在大型视觉-语言数据集上进行训练,RoboFlamingo 在机器人任务中表现得更好。
模型大小与性能:
虽然通常更大的模型会带来更好的性能,但实验结果表明,即使是较小的模型,也能在某些任务上与大型模型媲美。
指令微调的影响:
指令微调是一个强大的技巧,实验结果表明,它可以进一步提高模型的性能。






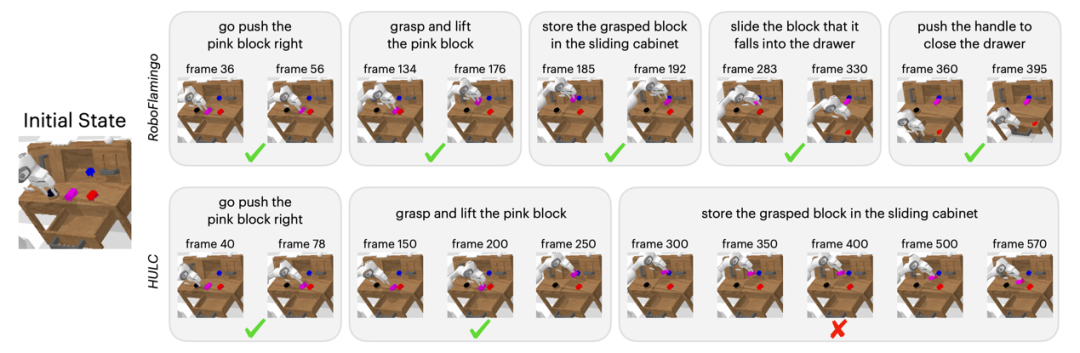
定性结果相较于基线方法,RoboFlamingo 不但完整执行了 5 个连续的子任务,且对于基线页执行成功的前两个子任务,RoboFlamingo 所用的步数也明显更少。
总结本工作为语言交互的机器人操作策略提供了一个新颖的基于现有开源 VLMs 的框架,使用简单微调就能实现出色的效果。RoboFlamingo 为机器人技术研究者提供了一个强大的开源框架,能够更容易地发挥开源 VLMs 的潜能。工作中丰富的实验结果或许可以为机器人技术的实际应用提供宝贵的经验和数据,有助于未来的研究和技术发展。
-
基于开源鸿蒙打造的机器人操作系统M-Robots OS 2.0版本正式发布2026-05-27 535
-
开源鸿蒙机器人操作系统M-Robots OS 2.0重磅发布2026-05-23 617
-
全国首个开源鸿蒙机器人操作系统 M-Robots OS 正式开源2025-07-24 1355
-
大象机器人携手进迭时空推出 RISC-V 全栈开源六轴机械臂产品2025-04-25 7431
-
开源鸿蒙助力人形机器人产业发展2025-04-23 1777
-
全国首个基于开源鸿蒙的机器人操作系统M-Robots OS正式发布,中国机器人产业进入“群体智能”新时代2025-04-09 1592
-
英伟达GROOT N1 全球首个开源人形机器人基础模型2025-03-20 2515
-
Al大模型机器人2024-07-05 2477
-
机器人基于开源的多模态语言视觉大模型2024-01-19 1156
-
ROS让机器人开发更便捷,基于RK3568J+Debian系统发布!2023-11-30 7214
-
ColorSky双足机器人开源项目2016-04-21 10646
全部0条评论

快来发表一下你的评论吧 !
