

RDMA RNIC虚拟化方案
描述
作者简介:KIKI,中国科学院计算技术研究所在读博士生
01引言
远程直接内存访问(Remote Direct Memory Access,RDMA)技术允许应用程序绕过操作系统内核,以零拷贝的方式和远程计算机进行网络通信,具有低延迟和高带宽的优势。RDMA协议主要包括Inifiband、RoCE以及iWARP。实现RDMA协议的I/O设备被称为RNIC。主流云服务提供商已经开始广泛部署RNIC,例如亚马逊云推出的弹性网络适配器(Elastic Network Adapter,ENA)[1]。同时,云服务提供商通过硬件虚拟化技术对物理资源进行池化管理,提升资源效率。
硬件虚拟化(Virtualization)技术是一种计算机资源管理技术,在各类计算机硬件(例如CPU、内存、存储、网络设备)上创建一个抽象层,将单个物理硬件资源模拟为多个虚拟资源。本文讨论针对RDMA网卡(RDMA Network Interface Controller,RNIC)的虚拟化技术,即将一个RNIC模拟为多个RNIC供虚拟机(Virtual Machine,VM)使用。根据实现方式,I/O虚拟化可以分为直通,全虚拟化、半虚拟化以及基于硬件辅助的全虚拟化。
RNIC虚拟化方案既要维持RDMA的高性能优势,又要满足云环境的部署要求。RDMA网络相对于传统TCP网络的性能优势包括更低的延迟、更高的带宽以及更低的CPU占用,因此针对RNIC的虚拟化方案首先应该尽可能降低虚拟化引入的RDMA性能开销。同时,云计算对虚拟实例之间的隔离性,虚拟实例的可迁移性以及虚拟实例的可管控性都有比较高的要求。本文针对虚拟机和容器两种实体的典型RDMA虚拟化技术进行了调研,并且对相关领域的研究内容进行了总结和展望。
02背景知识介绍
RDMA关键特征简介
如Figure 1所示,RDMA技术采用了控制路径(Control path)-数据路径(Data path)分离的思想。RDMA的控制面包括设备管理,Queue Pair、Completion Queue、Memory Region等资源的管理,以及异常处理等功能。RDMA的数据面包括请求的发起以及请求的完成确认。RDMA用户态的库向应用提供统一的、标准的动词(Verbs)接口。Verbs接口定义了控制面和数据面的具体内容,因此Verbs接口也可以进一步分为控制Verbs和数据Verbs。控制Verbs都会经过内核态RNIC驱动的转发到达RNIC内部的控制Verbs处理单元。控制Verbs和内核驱动交互的过程涉及系统调用和上下文切换,被认为是慢路径。数据Verbs通过内存映射I/O的方式直接和RNIC内部的数据Verbs处理单元交互。数据Verbs直接访问RNIC的过程被认为是快路径。RDMA的数据传输性能取决于数据Verbs的实现。
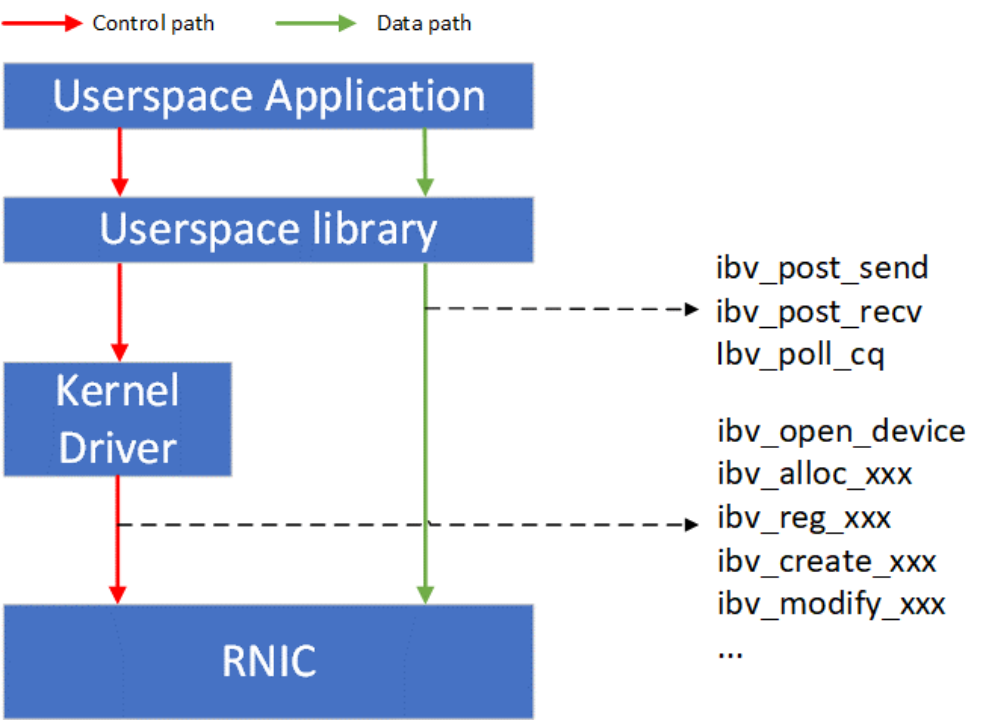
Figure 1 RDMA控制和数据路径
RDMA数据Verbs的高性能依赖于数据传输过程中的零拷贝实现。零拷贝实现要求RNIC具有主动发起PCIe DMA直接读写应用缓冲区的能力。应用在RDMA数据传输中使用进程虚拟地址,然而PCIe DMA需要总线映射后的DMA地址。RNIC需要主动将应用缓冲区的虚拟地址翻译为DMA地址。在具体的实现中,RNIC会缓存应用进程页表的一部分到其管理的内存翻译表(Memory Translation Table,MTT)。在RDMA虚拟化的实现中,由于Guest OS中映射的DMA地址不一定连续,MTT表中的DMA地址需要由Hypervisor提供。
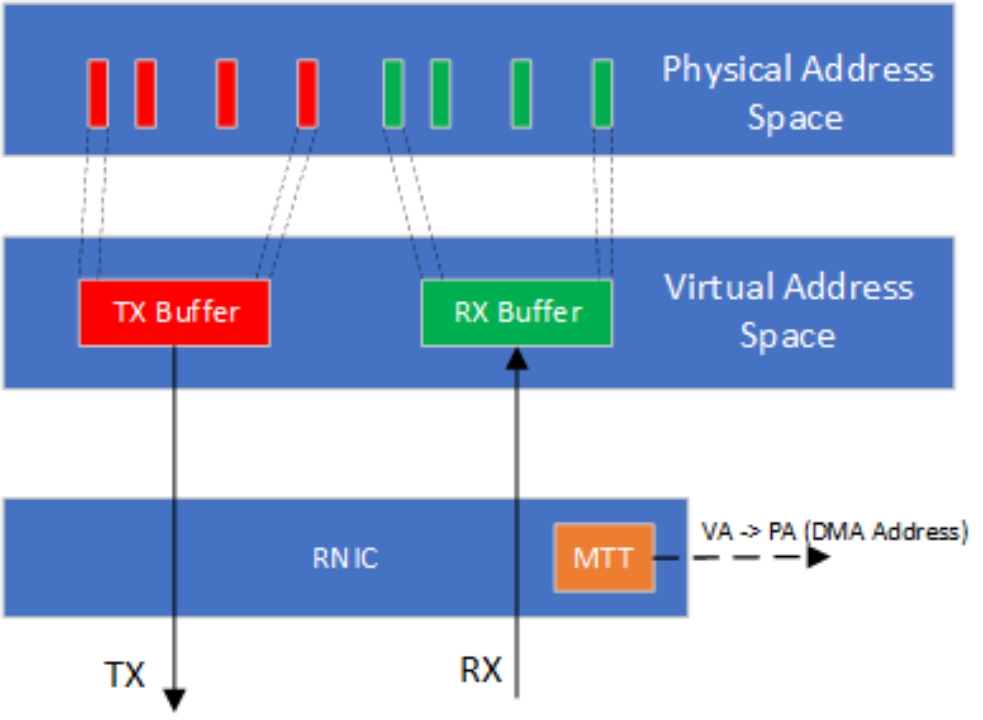
Figure 2 RNIC通过主动的内存翻译实现零拷贝传输
虚拟机和容器简介
虚拟化技术使软件应用程序能够运行在虚拟硬件(通过虚拟机和虚拟机监控程序(Virtual Machine Monitor,VMM)实现虚拟化)或虚拟操作系统(通过容器(Container)实现虚拟化)上。虚拟机(VM),也称为客户机,是一个软件模拟的硬件平台,为客户操作系统(Guest OS)提供虚拟操作环境。VMM也称为Hypervisor,是一个运行在实际主机(Host)的软件程序,监督虚拟机上客户操作系统的执行。Hypervisor包括Type 1和Type 2两类,其中Type 1 Hypervisor直接控制Host的硬件,而Type 2 Hypervisor通过Host操作系统间接控制硬件。目前主流的Hypervisor实现多属于Type2,包括KVM,VMware以及VirtualBox等。容器是一个虚拟运行时环境集合,包含执行目标软件应用所需的所有资源(例如文件系统、CPU、内存、进程空间以及网络接口等)。
容器可以看作是对操作系统的虚拟化(也有观点认为容器不能归类到虚拟化技术),并不模拟底层硬件。相对于虚拟机,容器更加轻量化,启动速度也更加快。容器引擎是运行容器的基础环境,主流实现包括Docker以及LXC等。在容器规模比较大的情况,需要使用诸如Docker Swarm或Kubernetes(K8s)等容器编排(Containter Orchestration)工具管理容器的部署。
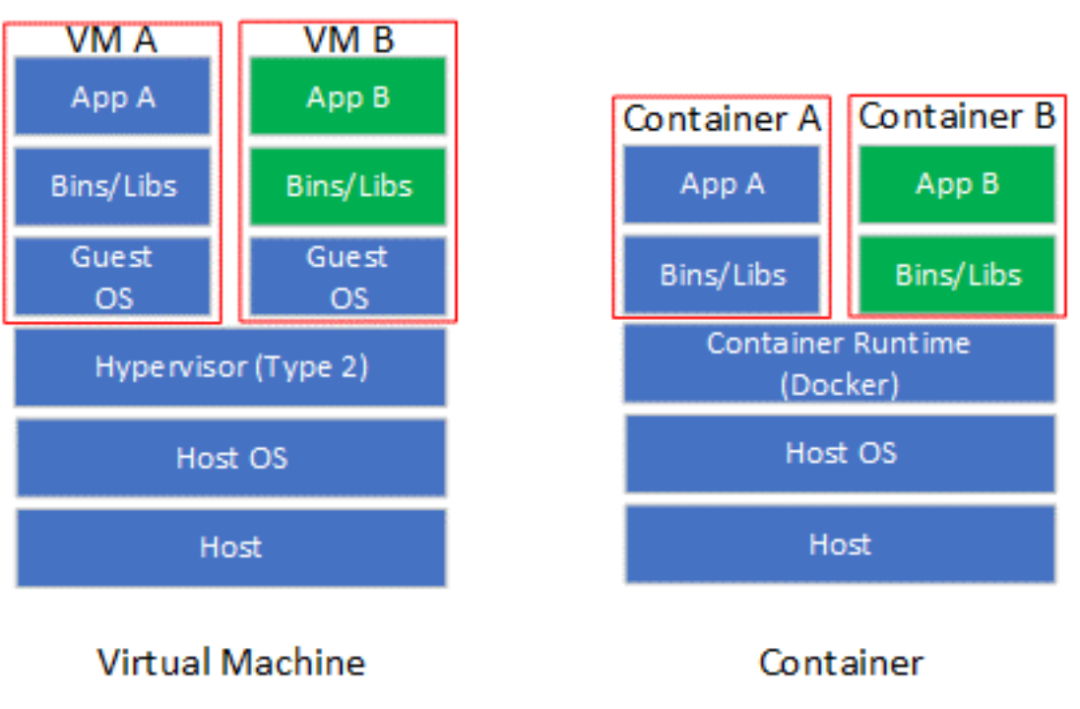
Figure 3 虚拟机和容器对比
03针对虚拟机的RDMA虚拟化技术
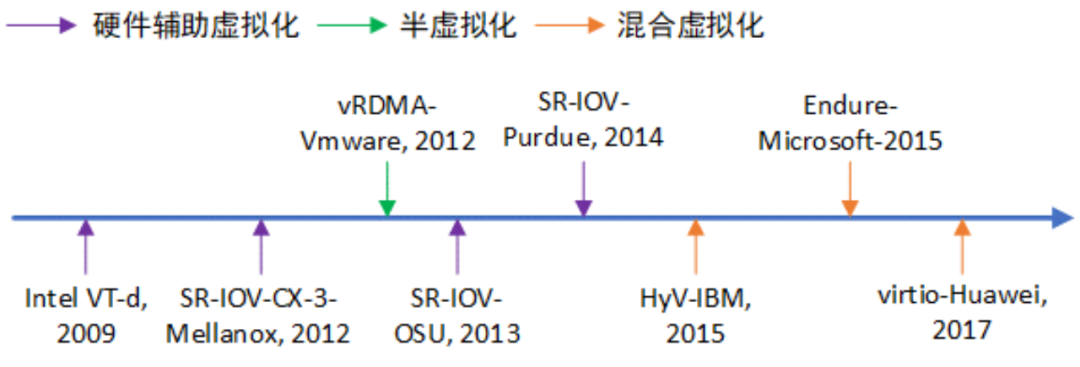
Figure 4 RDMA虚拟化技术发展历程
最基础的RNIC虚拟化方案是使用Hypervisor作为虚拟机和RNIC的唯一中间层,RDMA全部的数据和控制路径的全部请求都被Hypervisor截获、翻译以及执行,即全虚拟化I/O技术。如Figure 5所示,Hypervisor中的RDMA Proxy处理VM1和VM2的控制路径和数据路径。VM每次执行RDMA相关操作都需要通过VM-Exit将控制权交给VMM,VMM处理完后再通过VM-entry重新进入到VM。全虚拟化具有灵活可控的优势,不需要为VM提供专有驱动,且云计算的各类要求可以在RDMA Proxy中实现。VM Exit/Entry过程涉及从VM到Hypervisor之间的上下文切换,会产生相当大的性能开销。由于全虚拟化的性能开销较大,并未在工业界和学术界调查到基于全虚拟化技术的RNIC虚拟化方案。
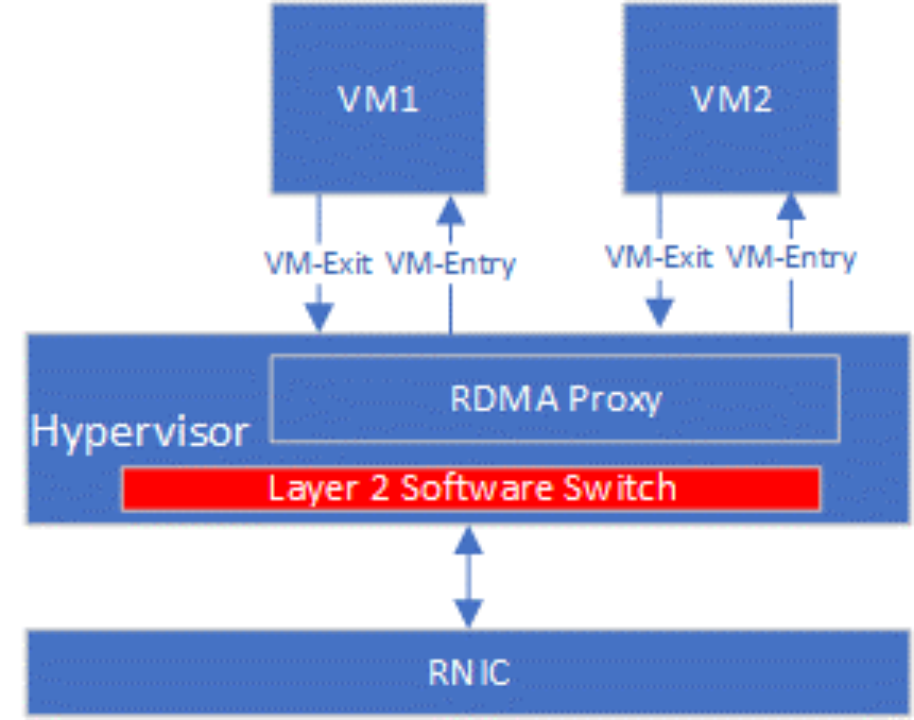
Figure 5 全虚拟化RDMA实现示意
另外一种纯软件实现的虚拟化技术是半虚拟化(Paravirtualization),其由前端驱动和后端驱动共同模拟实现。在客户机中运行的驱动程序称之为前端(Frontend),在主机上与前端通信的驱动程序称之为后端(Backend)。前端发送VM请求给后端,后端驱动处理完这些请求后再返回给前端。相对于全虚拟化,半虚拟化能够减少VM Exit/Entry次数,性能相对提升。VMware公司提出的vRDMA [2]属于半虚拟化RDMA方案,其整体架构如Figure 6所示。vRDMA向Guest OS的RDMA应用提供VMCI虚拟设备,libvrdma是VMCI虚拟设备的用户态驱动,vRDMA Driver是VMCI虚拟设备的用户态驱动。同时,VRDMA Driver也是半虚拟化框架中的前端驱动,后端驱动是Hypervisor中的vRDMA VMCI Endpoint。vRDMA VMCI Endpoin最终通过RDMA内核Verbs调用RDMA内核态驱动。
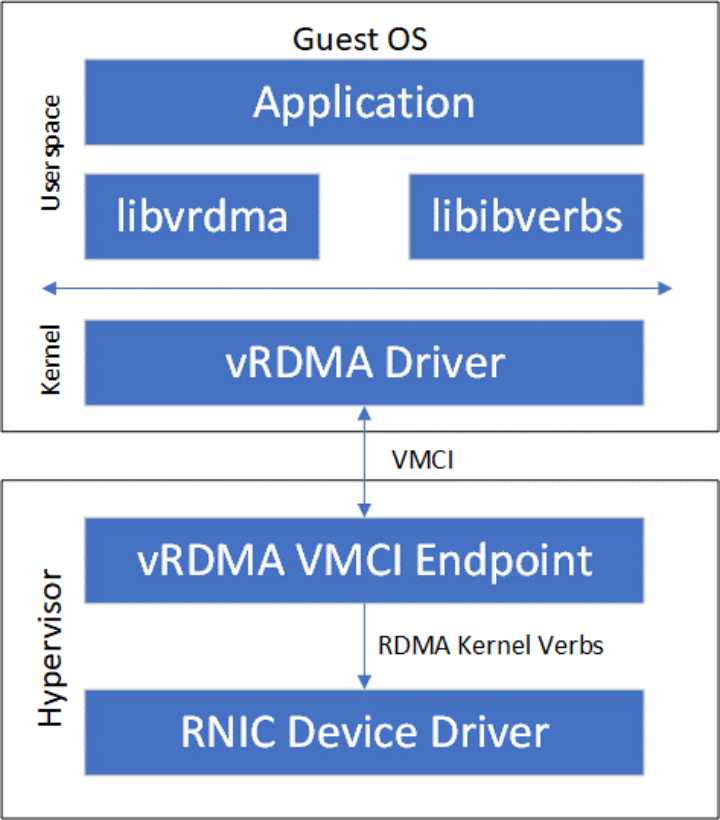
Figure 6 VMvare vRDMA实现架构
硬件辅助虚拟化包括直通和SR-IOV两种主流方案。RNIC以一个PCIe设备的形式接入到现有系统,因此最基础的硬件辅助RNIC虚拟化方案是采用Intel VT-D或者AMD Vi技术将RNIC直接绑定到一个虚拟机,这种虚拟化方法也被称为直通(Passthrough)。直通方式能够使得虚拟机独占RNIC,RNIC性能可以实现零损耗。然而一台主机上会存在多个虚拟机,如果采用直通方式实现RNIC虚拟化,则主机上安装的RNIC数量需要和主机最大支持虚拟机数量相等。显然,直通方式的并不具备虚拟机层面的可扩展性。SR-IOV(Single Root Input/Output Virtualization)技术能够将一个物理PCIe设备模拟成多个虚拟的PCIe设备(基于SR-IOV引入的Virtual Function,VF),专门用于针对VM的网卡虚拟化。根据OSU大学公开的性能评估结果 [3],SR-IOV虚拟化RDMA的小消息延迟相对于非虚拟化RDMA只增加了0.5us~1us,大消息延迟和非虚拟化RDMA无明显差距。此外,基于SR-IOV的虚拟化RDMA和非虚拟化RDMA的可达带宽无明显差距。Purdue大学的Malek等人 [4]提出了针对SR-IOV虚拟化RDMA的参数(例如中断聚合阈值、共享接收队列水线)优化方法,进一步减小了SR-IOV虚拟化RDMA和非虚拟化RDMA的性能差距。仅就RDMA虚拟化的性能而言,SR-IOV可以被认为是最优的选择。然而SR-IOV并不灵活,不能满足云计算的可迁移性和可管控性要求。例如,Mellanox ConnextX-4/5/6系列RNIC在重新配置SR-IOV的VF数量时需要首先将VF数量清零 [5],清零意味着当前正使用VF的VM需要放弃其对应的虚拟RNIC。假设当前主机RNIC的SR-IOV配置了4个VF,因为业务需求需要从其他主机迁入一个VF,则需要将SR-IOV的VF数量重新配置为8,则当前4个VM都需要放弃其虚拟RNIC。此外,基于SR-IOV的虚拟化方案需要在RDMA网卡内部集成支持虚拟网络的2层交互模块(L2 Switch),在将VM从一个主机热迁移到另外一个主机时需要重新配置L2 Switch,硬件重配置通常被认为是不灵活的。
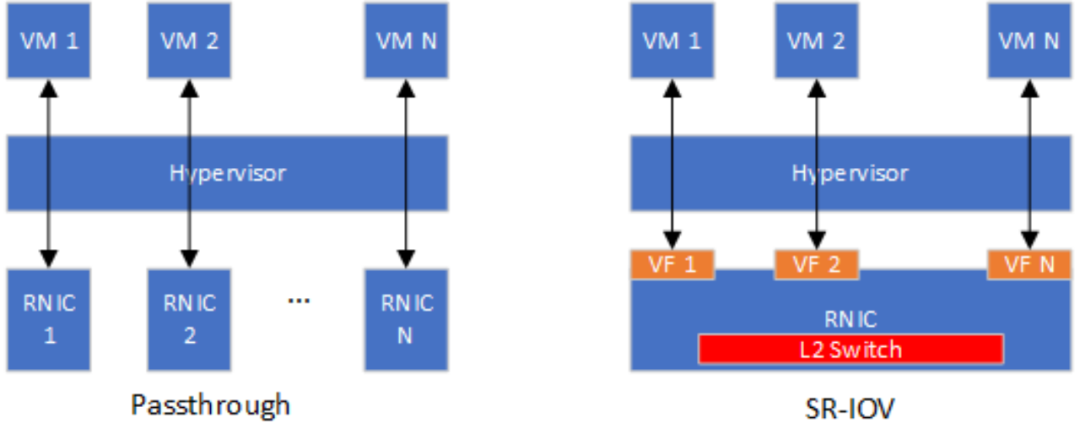
Figure 7 基于Passthrough和SR-IOV虚拟化方案对比
混合虚拟化利用了RDMA设计中的控制-数据路径分离的特点,对控制路径使用半虚拟化,对数据路径采用基于内存映射的硬件直通。IBM研究人员提出的HyV [6]是混合虚拟化的代表案例,相应的论文发表在2015年的VEE会议。在控制路径上,VM中的前端驱动拦截用户态驱动的ibv_create_qp, ibv_create_cq等控制Verbs转发到到Hypervisor中的后端驱动。后端驱动对接受到的控制Verbs调用实现VM层面的隔离、安全以及资源管控等要求后,将控制Verbs转发给RNIC设备驱动。在后端驱动中,内存映射相关的控制路径需要实现1)将RNIC提供的队列门铃映射到VM进程的地址空间;2)QP等资源占用的内存在后端驱动的地址空间分配,需要映射到VM进程的地址空间;3)VM进程数据缓冲区对应的Guest VA到Host PA映射需要同步到RNIC。在数据路径上,应用通过映射后的门铃和直接和RNIC交互,实现post_send,post_recv以及poll_cq。在具体实现上,HyV使用成熟的Virtio框架实现了控制路径的前后端驱动。实验评估显示HyV的性能和SR-IOV相近,在资源管理的灵活性上接近半虚拟化。微软提出的Endure(Enlighteded Network Direct On Azure) [7]以及华为提出的virtio-RDMA [8]都沿用了类似HyV的设计。在具体的实现上,Endure采用自定义的VMBus实现控制路径Guest-Host交互,而不是沿用virtio。Virtio-RDMA将HyV的前端驱动重新实现在Guest OS的用户态,减少上下文切换的次数。
以HyV为代表的RDMA混合虚拟化提出后,通过半虚拟化实现控制面和通过内存映射方式实现数据面直通硬件的方案已经成为共识。如何改造继续改造RDMA虚拟化方案,使得其更好地适应云计算特定的需求成为新的研究关注的。例如华为在SGICOMM 2021提出的MasQ [9],进一步在虚拟化控制面强化了租户隔离、安全隔离以及服务质量的设计,使得虚拟化RDMA能够在VPC(Virtual Private Cloud)网络部署。
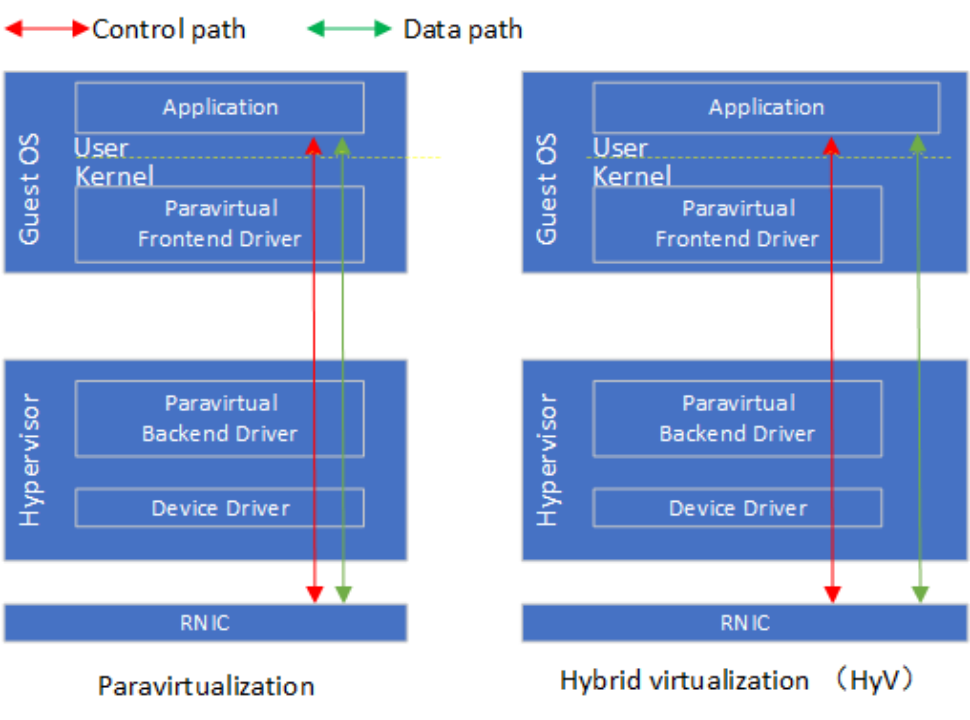
Figure 8 HyV混合虚拟化和半虚拟对比
04针对容器的RDMA虚拟化技术
容器可以看作是在主机操作系统上执行的进程,由主机操作系统提供资源隔离和命名空间(Namespace)的隔离。Namespace是Linux内核提供的资源隔离技术,可以实现网络、文件系统以及进程资源等的隔离。针对容器的RDMA虚拟化技术,本质上是在网络Namespace的基础上创建虚拟RDMA设备接口的过程。针对虚拟机的RDMA虚拟化技术是可以直接迁移到容器上的。Mellanox公司在2018年推出出了针对Docker容器网络设备SR-IOV和Passthrough插件 [10],该插件能够在容器内部创建虚拟RDMA设备或将物理设备绑定到某一个具体的容器。此外,Mellanox SR-IOV/Passthrough插件还利用网卡的的VLAN卸载功能对容器提供基于VLAN的虚拟网络支持。
SR-IOV能够提供良好的性能,但是不能完全满足云计算所需要的灵活性需求。特别地,容器对虚拟化方案的灵活性需求更高,现有研究工作主要从这个角度入手。微软的研究人员认为基于SR-IOV的虚拟化方案不能满足容器需要的便携性(Portability)要求。在基于SR-IOV的方案种,更新容器的IP需要同时更新网卡上的VLAN路由表。此外,基于SR-IOV的方案使得容器可以直接访问物理RDMA网卡,云服务提供商不能灵活地对容器的RDMA业务进行管控。
FreeFlow [11]是微软提出的容器虚拟化方案,该方案包括FreeFlow NetLib、FreeFlow Router以及FreeFlow Orchestrator。FreeFlow可以看作是半虚拟化设计,FreeFlow Netlib相当于容器内部的前端,而FreeFlow Router相当于主机上的后端。FreeFlow Netlib以标准的用户态Verbs API作为基础,从而保持对应用透明。FreeFlow Netlib通过劫持控制路径上的RNIC文件描述符请求,避免直接劫持Verbs API调用带来的RDMA数据结构序列化复杂度。FreeFlow Netlib将劫持到的RNIC文件描述符请求通过Unix Socket File Descriptor或者共享内存的方式转发到FreeFlow Router。FreeFlow Netlib和FreeFlow Router都是两个进程,通过Unix Socket File Descriptor可以实现两个进程之间的通信,但是这种通信方式延迟开销在5us以上,不能维持RDMA的低延迟要求。FreeFlow同时设计了基于共享内存的进程间通信方式,这种通信延迟低但是需要CPU资源轮询共享内存。FreeFlow Route是位于主机的一个进程,代替同一主机上的容器和物理RDMA网卡交互。为了实现数据路径上的零拷贝,FreeFlow Router将其内部的共享数据缓冲区(Shared Memory)和容器内应用缓冲区映射到同一块物理内存。为了实现这种映射,FreeFlow提供主动分配和被动重映射的方法。主动分配方法需要应用主动调用FreeFlow自定义的ibv_malloc和ibv_free接口分配和释放FreeFlow Router内部预留的Shared Memory。被动重映射需要FreeFlow Netlib在FreeFlow Router处理完内存注册请求后,将应用通过malloc申请的内存物理页重新映射到FreeFlow Router返回的Shared Memory。FreeFlow Orchestrator负责集群内全部容器的网络编排,例如编址、访问控制。此外,FreeFlow Orchestrator还需要管理容器内应用缓冲区虚拟地址到FreeFlow Router内部Shared Memory指针的映射关系。
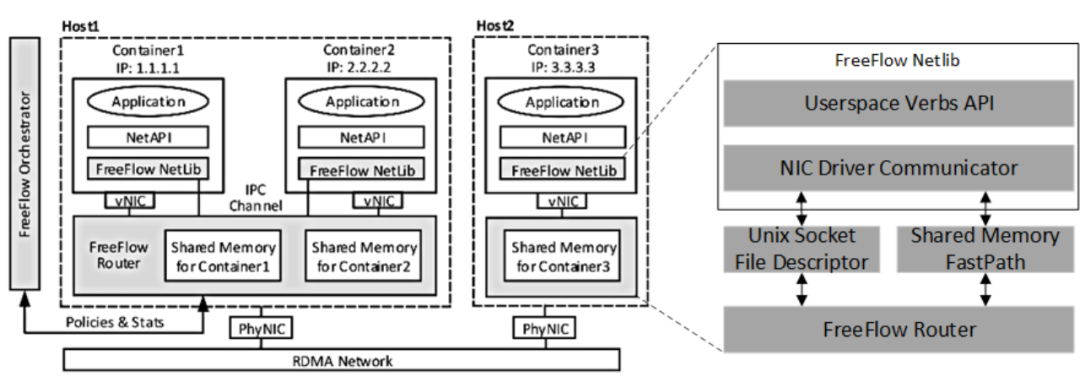
Figure 9 FreeFlow的总体架构
在标准的容器生产中,容器网络接口应遵循云原生计算基金会(Cloud Native Computing Foundation,CNCF)规定的容器网络接口(Container Network Interface,CNI)规范 [12],然而FreeFlow和CNI标准并不兼容。Mellanox在2021年推出了针对K8s容器编排平台的CNI插件RDMA CNI plugin [13],使得基于SR-IOV的RDMA网络设备资源池能够集成到K8s。Container Runtime (例如Docker)在创建容器时,先创建好Network Namespace (netns),然后调用RDMA CNI plugin为这个netns配置RDMA网络,其后再启动容器内的应用。
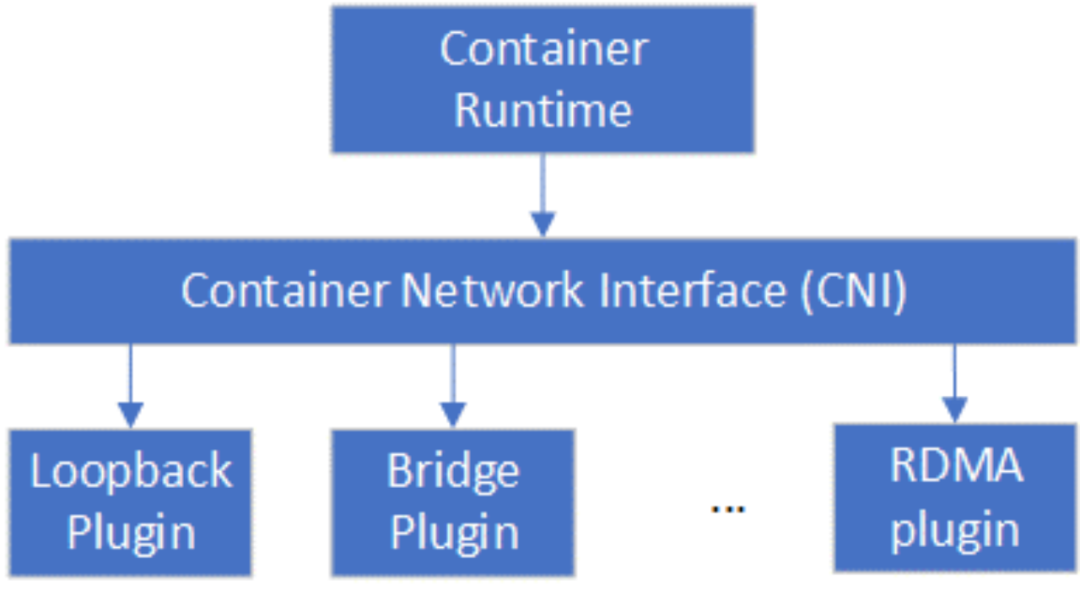
Figure 10 CNI插件关系图
05总结与展望
本文分别从虚拟机和容器2个方面阐述了对RDMA虚拟化的相关研究。从虚拟机角度来看,以HyV为代表的混合虚拟化方案利用了RDMA控制-数据分离的设计特征,能够在控制面的灵活性和数据面的性能上取得很好的权衡。未来的研究应该重点关注控制面的灵活性,面向云计算业务实际需求优化。从容器角度来看,容器和物理RDMA网卡之间的软件中间层比虚拟机更轻薄,但是容器网络的复杂性是要高于虚拟机的,同时容器的规模也要比虚拟机大。容器网络和容器规模要求网络2层交换层具有高灵活性,高可扩展性,因此目前主流的SR-IOV的容器虚拟化方案必须要在网卡硬件上实现满足容器部署需求的交换层。DPU上同时具备了灵活可编程网络引擎,RDMA引擎以及SR-IOV的支持,有潜力能够在性能、灵活性以及可扩展性层面取得比较好的权衡。
-
深入了解RDMA技术2023-12-26 5365
-
RDMA简介2之A技术优势分析2025-06-04 6660
-
u***server虚拟化识别加密狗解决方案2014-03-27 2255
-
虚拟化使用加密狗解决方案案例2014-06-30 5680
-
虚拟化方案识别加密狗技术介绍2014-08-08 2741
-
虚拟化使用加密狗及共享方案案例2014-09-23 3004
-
几种主要的虚拟化技术有什么不同?2019-08-14 2964
-
Minos嵌入式虚拟化方案分享2021-12-17 1141
-
数字电路实验的虚拟化设计方案2010-03-30 740
-
openEuler Summit 2021-云/虚拟化分论坛:混合多云管理平台—兼容虚拟化方案2021-11-10 2374
-
RDMA是什么?RDMA网卡有什么作用?2021-12-27 13496
-
RDMA技术简介 RDMA的控制通路和数据通路方案2023-04-10 2948
-
虚拟化技术是什么 虚拟化技术介绍2023-07-19 2038
-
Redis RDMA改造方案分析2023-08-16 4101
-
hyper v 虚拟化,hyper-v虚拟化:企业级虚拟化解决方案的全面解析2025-01-24 3182
全部0条评论

快来发表一下你的评论吧 !
