

缓存大小对CPU性能的影响解析
存储技术
描述
CPU Cache是CPU高速缓冲存储器的简称,本文将其简称为"缓存"或者"Cache".
本篇首先从计算机的存储层次出发介绍计算机的性能瓶颈,然后以Intel处理器为例介绍缓存的发展,随后介绍缓存提升CPU性能的局部性原理,最后分析缓存大小对CPU性能的影响。
一、计算机性能的瓶颈
在冯诺依曼架构下,计算机存储器是分层次的,存储器的层次结构如下图所示,是金字塔形状。从上到下依次是寄存器、L1缓存、L2缓存,L3缓存主存(内存)、硬盘等等。
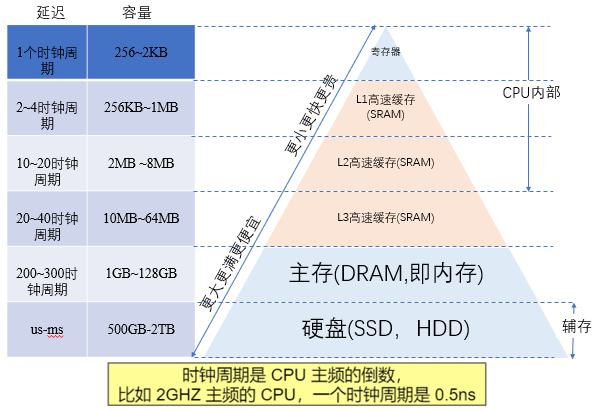
离CPU越近的存储器,访问速度越来越快,容量越来越小,每字节的成本也越来越昂贵。
如一个主频为3.0GHZ的CPU,寄存器的速度最快,可以在1个时钟周期内访问,一个时钟周期(CPU中基本时间单位)大约是0.3纳秒,内存访问大约需要120纳秒,固态硬盘访问大约需要50-150微秒,机械硬盘访问大约需要1-10毫秒。
电子计算机刚出来的时候,其实CPU是没有缓存Cache的,那个时候的CPU主频很低,甚至没有内存高,CPU都是直接读写内存的。随着时代的发展,技术的革新,从1980年代开始,差距开始迅速扩大,CPU的速度远远超过内存的速度,在冯诺依曼架构下,CPU访问内存的速度也就成了计算机性能的瓶颈!
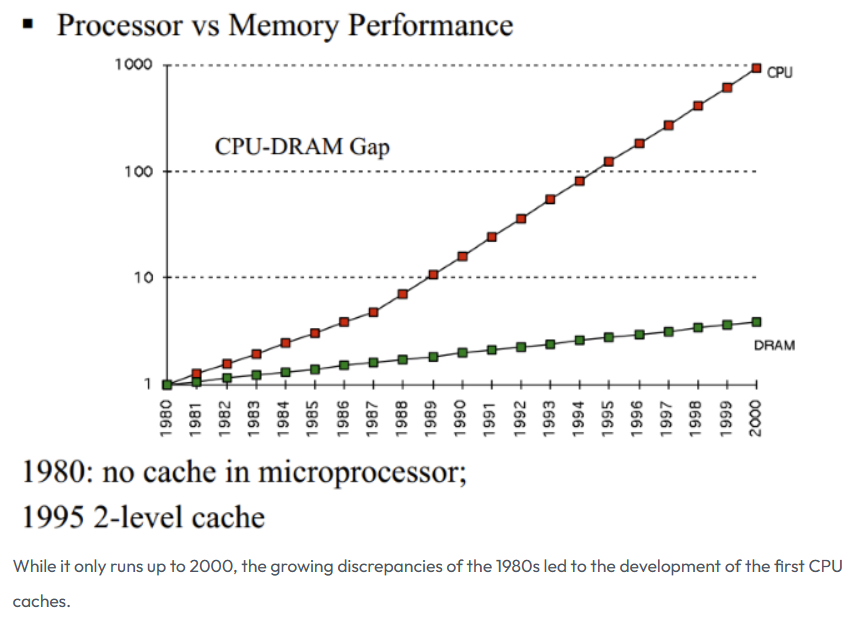
图片来源于:How L1 and L2 CPU Caches Work, and Why They're an Essential Part of Modern Chips
为了弥补CPU与内存两者之间的性能差异,也就是要加快CPU访问内存的速度,就引入了缓存CPU Cache,缓存的速度仅次于寄存器,充当了CPU与内存之间的中间角色。
二、缓存及其发展历史
缓存CPU Cache用的是 SRAM(Static Random-Access Memory)存储,也叫静态随机存储器。其只要有电,数据就可以保持存在,而一旦断电,数据就会丢失。
CPU Cache 通常分为大小不等的3级缓存,分别是 L1 Cache、L2 Cache 和 L3 Cache。常见的Cache典型分布图如下:
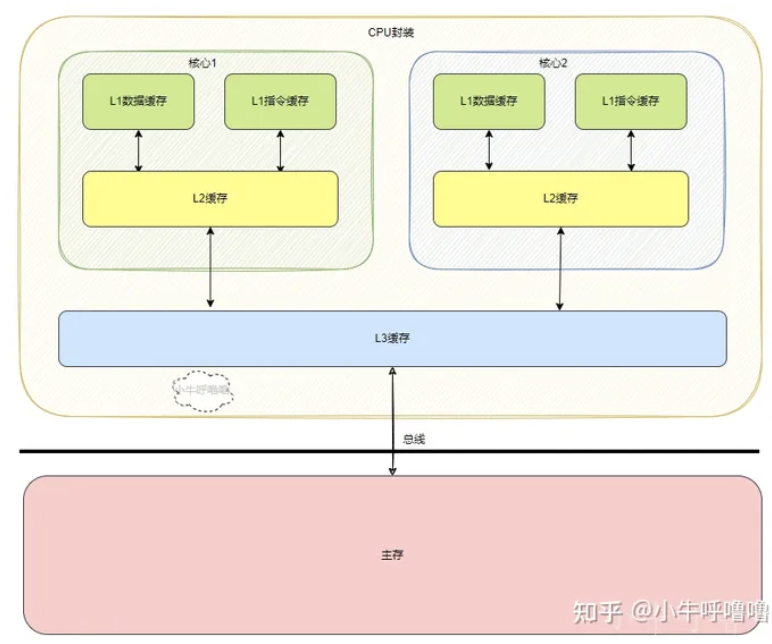
这里以intel系列为例,回顾Cache发展历史。
在80286之前,那个时候是没有缓存Cache的,那个时候的CPU主频很低,甚至没有内存高,CPU都是直接读写内存的。
从80386开始,这个CPU速度和内存速度不匹配问题已经开始展露,并且差距开始迅速扩大,慢速度的内存成为了计算机的瓶颈,无法充分发挥CPU的性能,为解决这个问题,Intel主板支持外部Cache,来配合80386运行。
80486将L1 Cache(大小8KB)放到CPU内部,同时支持外接Cache,即L2 Cache(大小从128KB到256KB),但是不分指令和数据。虽然L1 Cache大小只有8KB,但其实对那时候CPU来说够用了,我们来看一副缓存命中率与L1、L2大小的关系图:
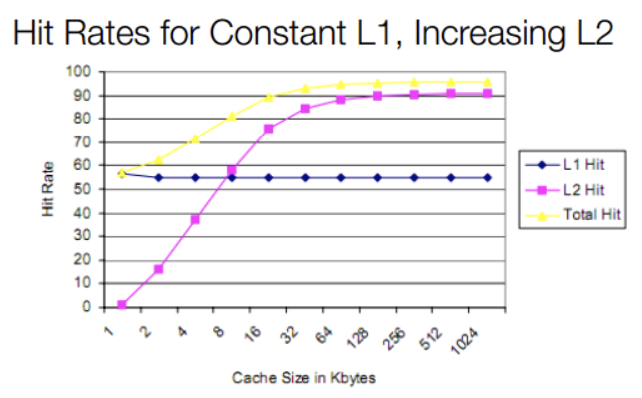
图片来源于:How L1 and L2 CPU Caches Work, and Why They're an Essential Part of Modern Chips。
从上图我们可以发现,增大L1 cache对于CPU来说好处不太明显,缓存命中率并没有显著提升,成本还会更昂高,所以性价比不高。而随着L2 cache 大小的增加,缓存总命中率会急剧上升,因此容量更大、速度较慢、更便宜的L2成为了更好的选择。
等到Pentium-1/80586,也就是我们熟悉的奔腾系列,由于Pentium采用了双路执行的超标量结构,有2条并行整数流水线,需要对数据和指令进行双重的访问,为了使得这些访问互不干涉,于是L1 Cache被一分为二,分为指令Cache和数据Cache(大小都是8K)【将数据和指令分别存取的存取结构叫做哈佛结构,区别于混在一起的冯·诺伊曼结构】,此时的L2 Cache还是在主板上,再后来Intel推出了[Pentium Pro]/80686,为了进一步提高性能,L2 Cache被正式放到CPU内部。
在CPU外面,DRAM内存还是那么一套内存,硬盘也是那么一套不区分指令和数据的硬盘。因而可以说x86 CPU是在内部采用哈佛结构、外部仍然是冯·诺伊曼结构。实际上除了少数单片机、DSP等设备,谁也不会最外层的存储设备都区分数据和指令。所以这种内部哈佛,外部冯·诺伊曼结构的做法似乎已经成了业界共识。
后来CPU多核时代来临,Intel的Pentium D、Pentium E系列,CPU内部每个核心都有自己的L1、L2 Cache,但他们并不共享,只能依靠总线来传递同步缓存数据。最后Core Duo酷睿系列的出现,L2 Cache变成多核共享模式,采用Intel的“Smart cache”共享缓存技术,到此为止,就确定了现代缓存的基本模式。
如今CPU Cache通常分为大小不等的3级缓存,分别是 L1 Cache、L2 Cache 和 L3 Cache,L3 高速缓存为多个 CPU 核心共用的,而L2则被每个核心单独占据,另外现在有的CPU已经有了L4 Cache,未来可能会更多。
三、缓存如何弥补CPU与内存的性能差异?
缓存主要是利用局部性原理来提升计算机的整体性能。因为缓存的性能仅次于寄存器,而CPU与内存两者之间的产生的分歧,主要是二者存取速度数量级的差距,尽可能多地让CPU去存取缓存,同时减少CPU直接访问主存的次数,这样计算机的性能就自然而然地得到巨大的提升。
所谓局部性原理,主要分为空间局部性与时间局部性:
时间局部性:被引用过一次的存储器位置在未来会被多次引用(通常在循环中)。
空间局部性:如果一个存储器的位置被引用,那么将来它附近的位置也会被引用。
缓存会把CPU最近访问主存(内存)中的指令和数据临时储存,因为根据局部性原理,这些指令和数据在较短的时间间隔内很可能会被以后多次使用到,其次是当从主存中取回这些数据时,会同时取回与其位置相邻的主存单元的存放的数据临时储存到缓存中,因为该指令和数据附近的内存区域,在较短的时间间隔内也可能会被多次访问。
当CPU去访问指令和数据时,首先去访问L1 Cache,如果命中,则会直接从对应的缓存中取数据,而不必每次去访问主存,如果没命中,会再去L2 Cache中找,依次类推,如果L3 Cache中不存在,就去内存中找。
四、L1缓存是不是越大越好?
L1增大,会提高L1的命中率,但L1缓存是不是越大越好?
4.1 增大L1对访问延迟的影响
一个实际的例子: 从Intel Sunny Cove (Core第10代) 开始L1 cache从32K (指令) +32K(数据) 的组合变成了32K (指令) +48K (数据) 的组合。这样的后果就是L1 cache的访问性能下降,从4个cycle变成5个cycle。增大L1会提高命中率,同时延迟也增加了。那么这一升一降对平均访问时间(AMAT)有什么影响呢?
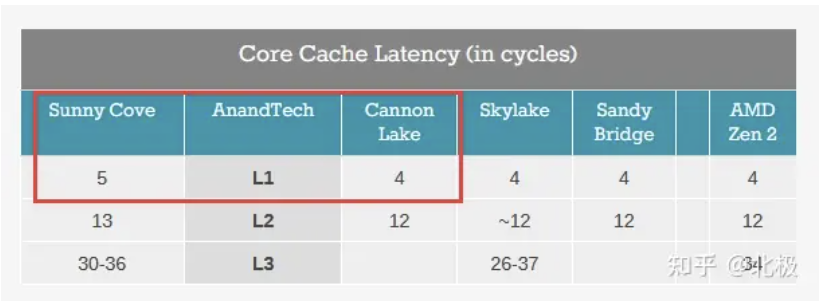
下面用一个简单的例子来说明一下L1访问时间对AMAT的影响。假设我们有三层的memory hierarchy (L1, L2, offchip RAM) ,其中L2访问时间为10 cycle,off-chip RAM访问时间为200 cycle。假设32KB L1-D的情况下L1,L2的hit rate大致为90%,9%,增加至48KB L1-D的Sunny Cove L1,L2 hit rate提升为95%,4%,那么对应的
Sunny Cove平均访问时间约为
0.95*5+0.04*10+0.01*200=7.15 cycle.
Sunny Cove之前的microarchitecture的平均访问时间约为
0.90*4+0.09*10+0.01*200=6.5 cycle.
简单的模型估算可以看出,即便增大L1 size可以提升L1 hit rate,然而L1访问延时的增加,还是会使得平均内存访问延时增加了~10%。这也是为什么L1 cache size长时间来没有太大改动的原因。
综上,L1大小将直接影响访问时间,而访问L1的时间又会直接影响到平均内存访问时间(average memory access time - AMAT),对整个CPU的性能产生巨大影响。
4.2 限制L1访问延时的原因是什么?
在系统启动过程中,仅在很早期启动阶段CPU处于实模式,开启paging之后,CPU接收的load/store指令对应的地址均为虚拟地址,在访问L1 cache的时候还需要经过虚拟地址VA到物理地址PA的转换。现代CPU通常采用virtual index physical tag的L1结构 。这种L1结构的一大好处就是可以在index cache set的时候同时访问TLB (相当于隐藏了部分L1访问延时),一个x64下的L1访问示意图如下所示。
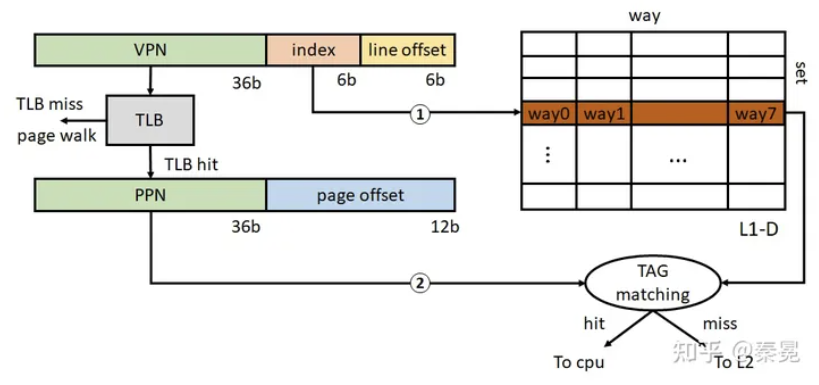
TLB:Translation lookaside buffer,即旁路转换缓冲,或称为页表缓冲
对于4KB大小的page,共有12bit page offset,其中低6bit为cacheline offset (64B cachelinesize),剩余6bit作为L1 index bits,这也就意味着L1只能限制于64个cache set。对于32KB L1-D,也就意味着其每个set对应8 way (32KB/64/64 = 8) 。Sunny Cove的48KB L1-D对应每个set12 way。由上图可以看出,L1访问延时的关键路径为TLB访问以及TLB hit之后对相应L1 cache set的TAG matching,由于cache set是简单的lookup,我们可以认为在TLB查询结束得到PPN的时候立即可以进行TAG matching。(TLB也是一个小的set-associatative cache,也需要进行TAG matching。因此访问时间要长于L1 set lookup)。因此,TLB的查询时间和L1的associativity (即图中的TAG matching)决定了L1的访问延时。
为了保证L1访问延时可以做的足够低,通常需要设计L1的associativity尽量小。因此在Sunny Cove之前通常为8 way。这里Sunny Cove增加了一个cycle的L1访问延时,不确定是由TLB的改动引起的还是L1 associativity由8 way增加到12 way。但是总的来说,我们可以看出L1为什么不能设计得很大,主要是由于virtual index physical tag的结构引起的。
另一方面,L1 cache 32kb 是算好能覆盖整个4KB页的,从第一代core到现在十代都是这么设计的。每个set有8个way,也就是说可以同时缓存8页,加大容量一方面提高延迟的同时可能会导致很大一部分way在很多时候是闲置浪费性能。
总的来说,增加cache line的大小,但是相应的cache miss的延迟会大大增加,尤其是考虑到L1会缓存虚拟地址,一旦miss意味着penalty会增加更多。另外如果增加wayness或者sets,会造成寻址延迟增高,也是得不偿失。
另外,L1 cache的替换以及prefetch策略都是很复杂的,这些也会导致延迟的提高对性能的影响会大于容量的提高。
4.3 苹果M1的L1为什么会比X-86的L1大?
为什么苹果的M1可以做到192KB的L1-I(128KB L1-D),同时保证3 cycle的访问延时呢?
首先一点苹果的最高主频相对Intel/AMD的desktop/server line的CPU要低一些,因此在时序上约束相对放松一些(主要是tag matching的comparator路径的关键路径)。其次一点,也是最关键的M1对应的MacOS采用的是16KB page而非x86的4KB page。
由上图可知如果扩大page size(16KB对应14bit),相当于增加了2bit的index bits,这样的话L1 cache set数目可以增加4倍(在保持associativity的前提下),因此M1的L1-I正好是Sunny Cove的4倍(192KB/48KB = 4)。M1的L1-D大小是128KB(4倍于32KB)。
对于问题中的L1 cache来讲,其实更多的是系统层面的取舍(page size增加也会导致内存浪费,内存碎片等问题,但是同时也会减轻页表的压力,增加TLB coverage)。不过也仅限于苹果,其M1的产品只是MacBook一个设备,可以做更多的定制,对于x86来讲,历史包袱和众多设备兼容性的问题,使其很难做到像苹果这种更加灵活的架构设计。
审核编辑:黄飞
-
高性能缓存设计:如何解决缓存伪共享问题2025-07-01 1081
-
什么是CPU缓存?它有哪些作用?2024-08-22 9806
-
cpu缓存的作用及原理是什么2023-08-21 5117
-
CPU缓存一致性协议解析2023-07-12 1752
-
关于CPU缓存的作用2022-03-30 5661
-
CPU缓存的作用及原理有哪些2021-08-27 13043
-
缓存如何工作,如何设计CPU缓存2020-11-19 3715
-
CPU缓存是什么意思_CPU缓存有什么作用2020-05-19 8793
-
如何检测cpu二级缓存是否损坏 详解二级缓存对CPU性能影响2018-08-14 11807
-
CPU缓存对性能的影响2010-11-13 3260
-
什么是CPU一级缓存/二级缓存?2010-02-04 1547
-
CPU一级缓存2009-12-24 643
全部0条评论

快来发表一下你的评论吧 !
