

Transformer压缩部署的前沿技术:RPTQ与PB-LLM
描述
随着人工智能技术的迅速发展,Transformer在自然语言处理、机器翻译、问答系统等领域取得了显著的性能提升。然而,这些模型的部署面临着巨大的挑战,主要源于其庞大的模型尺寸和内存消耗。
在部署过程中,网络压缩是一种常用的解决方案,可以有效减小模型的体积,提高模型在移动设备等资源受限环境下的部署效率。其中,量化技术是将大模型中的浮点数参数转换为整数,并进行存储和计算的方法。由于Transformer的网络参数越来越多、计算量越来越大,对于存储和计算资源有限的边缘设备来说,模型部署带来了很大的挑战。
网络量化是一种常见的解决方案,通过将模型参数量化为整数,可以大幅度减少模型的存储空间和计算量,从而实现在边缘设备上高效部署Transformer。
后摩智能也在Transformer量化提出了一些领先的算法方案。在本文中,我们将重点介绍两种针对Transformer的量化方案:
RPTQ(Reorder-based Post-training Quantization)
PB-LLM(Partially Binarized Large Language Models)
这两种方法分别针对激活量化和权重量化,旨在实现极端低位量化,同时保持语言推理能力。
RPTQ:
量化激活通道的新思路
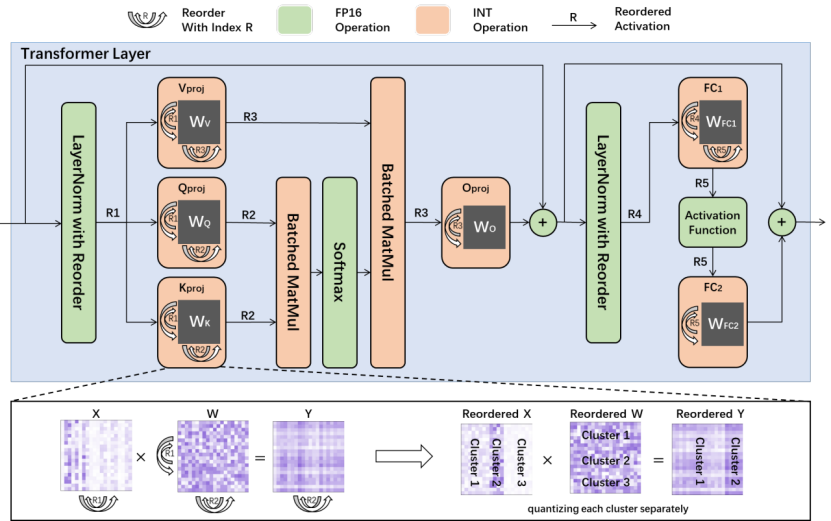
RPTQ(Reorder-based Post-training Quantization)是后摩智能团队与华中科技大学等合作单位提出的一种全新的量化方法,旨在解决量化Transformer时激活通道之间的数值范围差异问题。
相较于以往的研究,RPTQ首次将3位激活引入了LLMs,实现了显著的内存节省,例如在量化OPT-175B模型方面,内存消耗降低了高达80%。RPTQ的关键思想是通过重新排列激活通道并按簇量化,从而减少通道范围差异的影响。同时,通过操作融合,避免了显式重新排序的操作,使得RPTQ的开销几乎为零。通过这种方法,RPTQ有效地解决了激活通道数值范围差异导致的量化误差问题。
PB-LLM:
实现极端低位量化的新突破
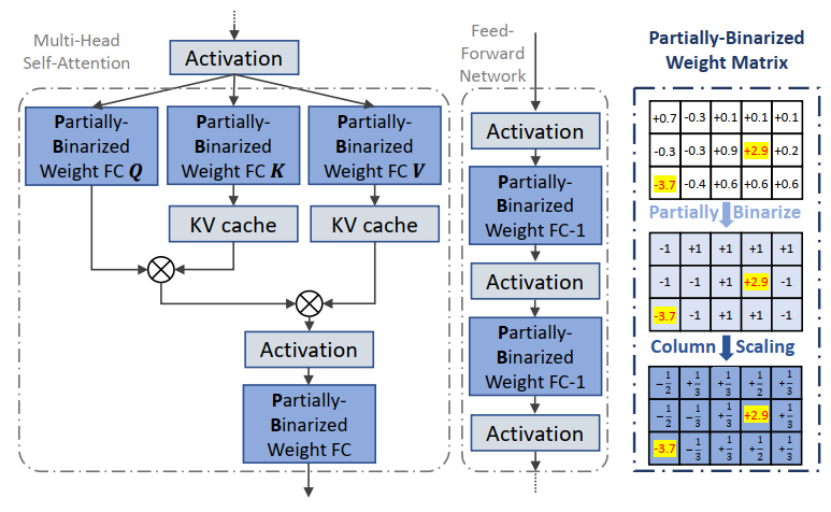
PB-LLM(Partially Binarized Large Language Models)是后摩智能团队与伊利诺伊理工和伯克利大学等单位合作提出的另一种创新性量化方法,主要针对权重量化。目前该篇论文已被接收至ICLR 2024,ICLR 以介绍和发布人工智能、统计学和数据科学领域深度学习的尖端研究而闻名,被认为是“深度学习的顶级会议”。
相较于传统的二值化方法,PB-LLM采用了部分二值化的策略,即将一部分显著权重分配到高位存储,从而在实现极端低位量化的同时,保持了Transformer的语言推理能力。通过对显著权重的充分利用,PB-LLM取得了显著的性能提升,为Transformer的内存消耗和计算复杂度提供了有效的解决方案。这是学术界首次探索对Transformer权重数值二值化的工作。
后摩智能的技术优势:突破性内存计算技术驱动AI发展
后摩智能作为大算力存算一体领域的先行者,凭借着RPTQ和PB-LLM等创新性量化方法的提出,取得了在大型语言模型中实现极端低位量化的突破。同时,后摩智能团队在内存计算领域拥有深厚的研究实力和丰富的实践经验,与行业内多家顶尖机构展开了广泛的合作。这使得后摩智能得以不断推动内存计算技术的发展,为人工智能技术的应用提供了更多创新性解决方案。
总的来说,后摩智能的RPTQ和PB-LLM等突破性量化方法为解决大型语言模型部署中的内存消耗和计算复杂度问题提供了有效的解决方案。随着内存计算技术的不断演进,后摩智能将继续致力于推动人工智能技术的发展,实现万物智能的愿景。
审核编辑:刘清
-
纵观全球前沿技术 博览行业领先精品2011-01-05 1999
-
物联网最新前沿技术应用大赏(图文)2012-08-20 6462
-
FPGA前沿技术更新2015-10-16 4554
-
电磁效应领域基础与前沿技术 主题论坛2017-11-23 6559
-
UWB技术前沿2021-07-26 2692
-
影响未来的六大前沿技术2011-05-06 2176
-
IDF 2011展示“互联计算”前沿技术2011-05-07 690
-
奇元裕办理半导体前沿技术论坛 探讨大尺寸硅片及3D传感和VCSEL工艺前沿技术2018-04-27 1555
-
浅析机器学习的前沿技术及技术趋势2018-11-25 6710
-
机器人领域的九大前沿技术2019-05-30 7621
-
基于Transformer的大型语言模型(LLM)的内部机制2023-06-25 2768
-
transformer模型详解:Transformer 模型的压缩方法2023-07-17 3875
-
LLM的Transformer是否可以直接处理视觉Token?2023-11-03 1070
-
llm模型本地部署有用吗2024-07-09 2051
-
MediaTek在MWC 2025展示前沿技术2025-04-08 1265
全部0条评论

快来发表一下你的评论吧 !
