

数据中心能够完全满足AI规模应用的要求呢?
电子说
描述
数智时代的最大特点,就是AI人工智能的广泛应用。
进入21世纪以来,移动通信、光通信、云计算、大数据等ICT技术蓬勃发展,推动了企业的数字化转型。数据,变成了企业最核心的资产。
企业将这些数据资产全部存储并运行在数据中心之上。随着数字化的不断深入,数据规模变得越来越庞大。
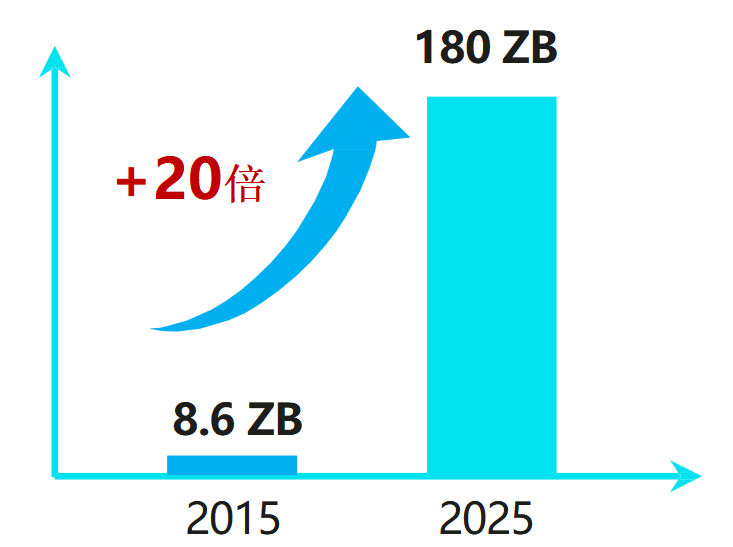
2025年新增的数据量将达到180ZB
(数据来源:华为GIV)
传统的软件算法,根本无法处理如此海量的数据(更何况,其中95%以上都是语音、视频等非机构化数据)。于是,我们找来了能力更强的帮手,那就是——AI(人工智能)。
AI可以完成海量无效数据的筛选和有用信息的自动重组,从而大幅提升数据价值的挖掘效率,帮助用户更高效地进行决策。
然而,想要利用好这个神器,我们需要三大要素的支持,那就是算法、算力和数据。
AI算法强不强,训练是关键。深度学习的算法训练,离不开海量的样本数据,以及高性能的计算能力。
在存储能力方面,从HDD(机械硬盘)到SSD(高速闪存盘),再到SCM(存储级内存),介质时延降低了100倍以上,可以满足高性能数据实时存取需求。
在计算能力方面,从CPU到GPU,再到专用的AI芯片,处理数据的能力也提升了100倍以上。
那么,这是否意味着数据中心能够完全满足AI规模应用的要求呢?
别急着说是,我们不能忘了一个重要的性能制约因素,那就是——网络通信能力。

事实上,网络通信能力确实拖了存储能力和计算能力的后腿。数据显示,在存储介质和计算处理器演进之后,网络通信时延已经成为了数据中心性能提升的瓶颈。通信时延在整个存储E2E(端到端)时延中占比,已经从10%跃迁到60%以上。
也就是说,宝贵的存储介质有一半以上的时间是在等待通信空闲;而昂贵的处理器,也有一半时间在等待通信同步。
网络通信能力,已经在数据中心形成了木桶效应,变成了木桶的短板。
█ 数据中心通信网络,到底出了什么问题?
上世纪70年代,TCP/IP和以太网技术相继诞生。
它们成本低廉、结构简单,为互联网的早期发展做出了巨大贡献。
但是,随着网络规模的急剧膨胀,传统TCP/IP和以太网技术已经跟不上时代的步伐,它们落后的架构设计,反而制约了互联网的进一步发展。
2010年后,数据中心的业务类型逐渐聚焦为三种,分别是高性能计算业务(HPC),存储业务和一般业务。
这三种业务,对于网络有不同的诉求。比如HPC业务的多节点进程间通信,对于时延要求非常高;而存储业务,对通信可靠性的要求非常高,网络需要实现绝对的0丢包;一般业务的规模巨大,扩展性强,要求网络低成本易扩展。
传统以太网可以适用于一般业务,但是无法应对高性能计算和存储业务。于是,业界发展出了Infiniband(直译为“无限带宽”技术,缩写为IB)网络,应对有低时延要求的网络IPC通信;发展出了FC(Fibre Channel,光纤通道)网络,提供高可靠0丢包的存储网络。
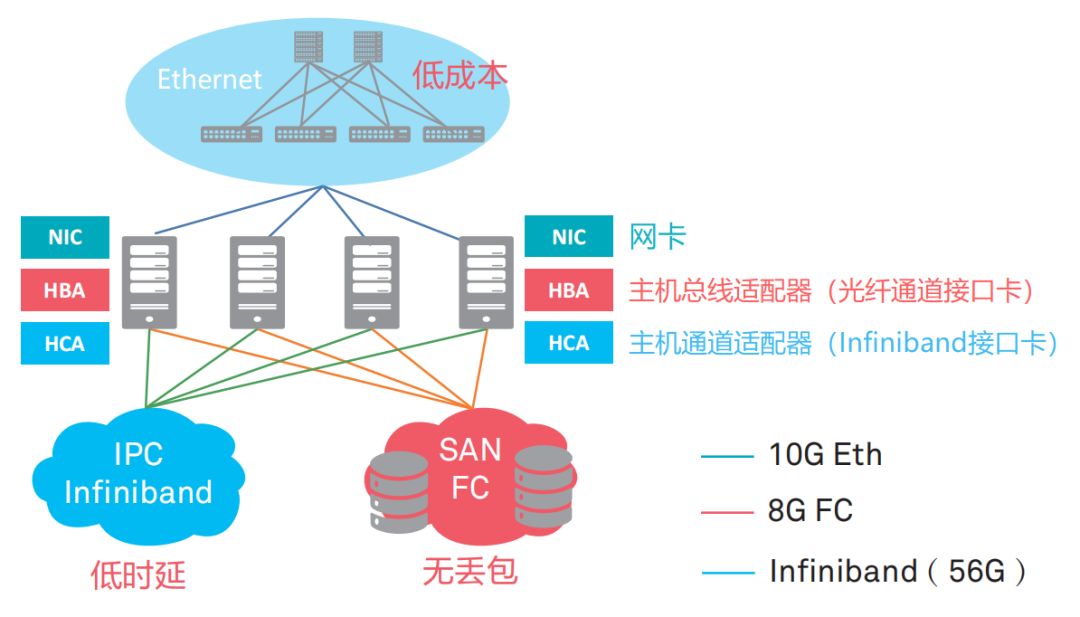
IB专网和FC专网的性能很强,但是价格昂贵,是以太网的数倍。而且,两种专网需要专人运维,会带来更高的维护成本。
是不是有办法,将三种网络的优势进行结合呢?有没有一种网络,可以同时实现高吞吐、低时延和0丢包?
这里,我先卖个关子,不揭晓答案。我们回过头来,看看TCP/IP协议栈的痛点。
传统的TCP/IP协议栈,实在是太老了。它的很多致命问题,都是与生俱来的。比如说它的时延,还有它对CPU的占用。
为了解决问题,专家们提出了一种新型的通信机制——RDMA(Remote Direct Memory Access,远程直接数据存取),用于取代TCP/IP。
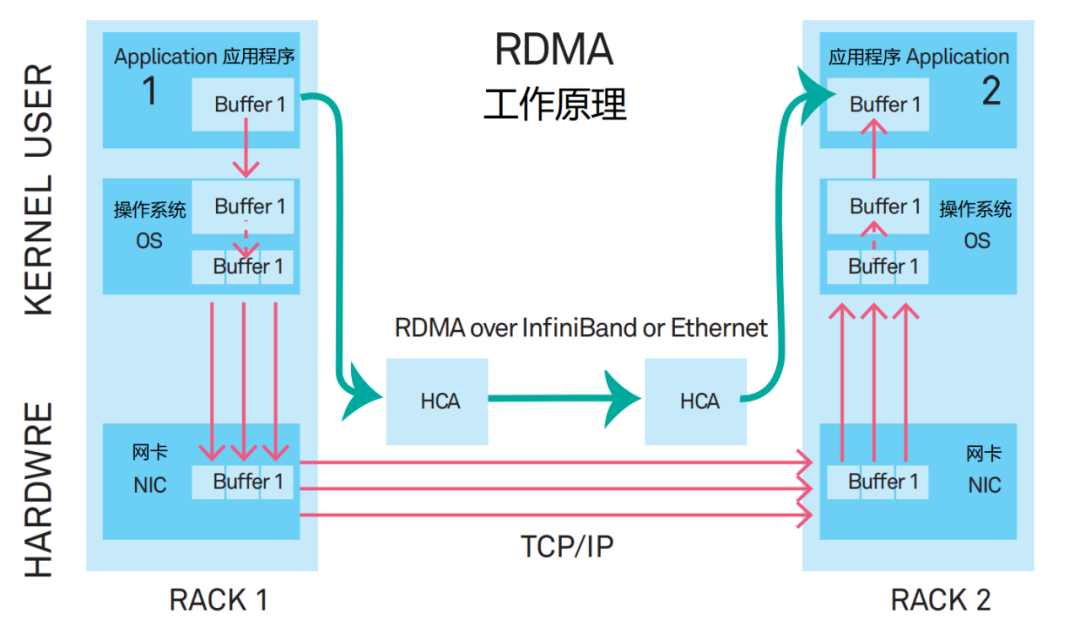
RDMA相当于是一个快速通道技术,在数据传输时延和CPU占用率方面远远强于TCP/IP,逐渐成为主流的网络通信协议栈。
RDMA有两类网络承载方案,分别是专用InfiniBand和传统以太网络。

InfiniBand是一种封闭架构,交换机是特定厂家提供的专用产品,采用私有协议,无法兼容现网,加上对运维的要求过于复杂,并不是用户的合适选择。
除了InfiniBand之外,那就只剩下传统以太网了。
那比较尴尬的是,RDMA对丢包率的要求极高。0.1%的丢包率,将导致RDMA吞吐率急剧下降。2%的丢包率,将使得RDMA的吞吐率下降为0。
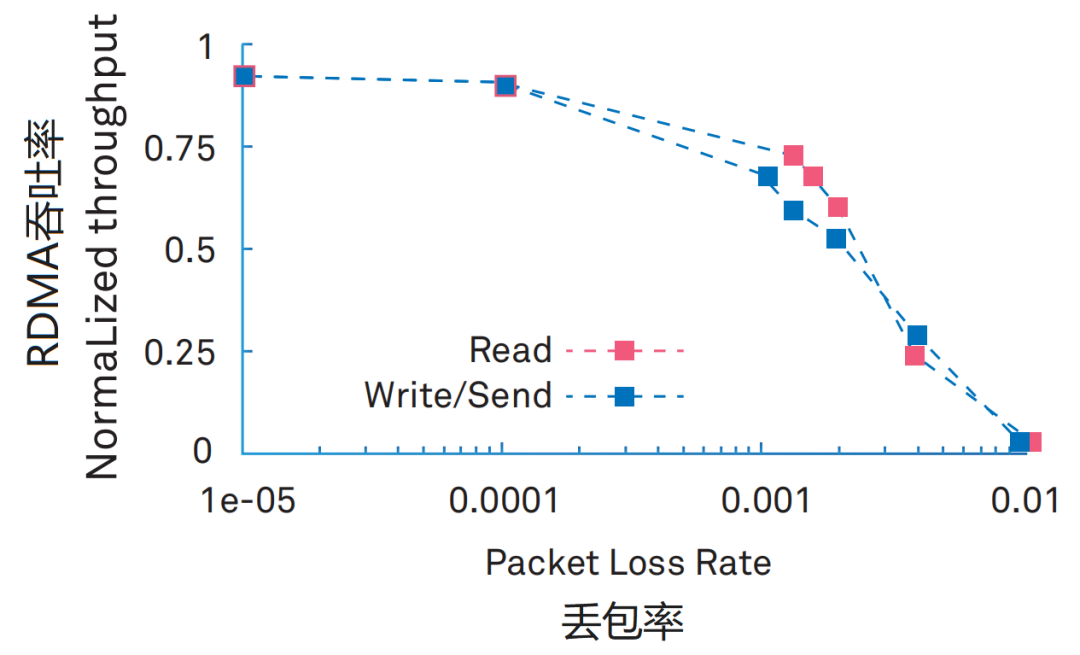
而传统以太网,工作机制是“尽力而为”,丢包是家常便饭。
又回到了前面那个问题:我们究竟有没有0丢包、高吞吐的新型开放以太网,用于支撑低延时RDMA的高效运行呢?
Duang!答案揭晓——
办法当然是有的,那就是来自华为的超融合数据中心网络智能无损技术。
█ 华为的零丢包秘技
华为的智能无损技术到底有何神通,可以解决困扰传统以太网已久的丢包问题?
其实,想要实现零丢包,首先要搞清楚网络为什么会产生丢包。
网络丢包的基本原因其实很简单,就是发生了溢出——网络流量超过了数据中心交换机的处理和缓存能力。
应对溢出,业界通用的做法,就是控制发送端的发送速度,从而避免超过交换机处理能力的拥塞形成。
具体来说,就是在交换机端口设置报文缓存队列,一旦队列长度超过某一个阈值(拥塞水线),对拥塞报文进行拥塞标记,流目的端向源端发送降速信号,即显式拥塞通知ECN(Explicit Congestion Notification)。
源端收到通知,从而降低发送速度,规避拥塞。
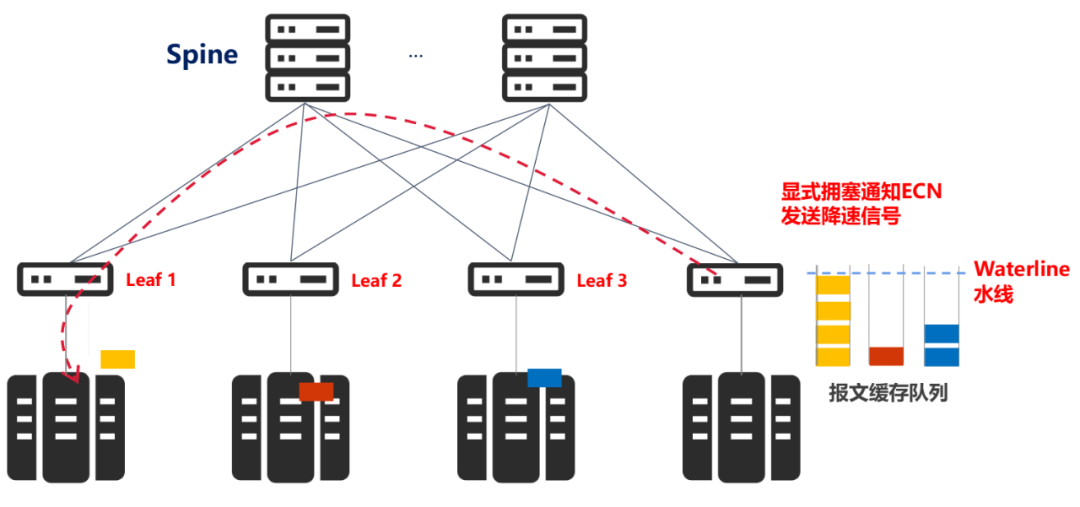
我们可以看出,这个阈值的设置非常关键。它决定了对报文进行拥塞标记的时机,是网络中是否会发生拥塞的决定性因素。
阈值的设置,是一门非常深的学问。
如果设置太保守,就会降速太多,影响系统吞吐能力。如果设置太激进,则无法达到无损的效果。
更关键的是,网络的业务类型是多样且变化的,有时候需要高吞吐,有时候又需要低时延。即便是有经验的专家,好不容易花了几天的时间,设置好了最佳水线位置,结果它又变了,咋整?
于是,华为想到了最适合干这个活的角色,那就是——AI。
早在2012年,华为为了应对未来数据洪水挑战,投入了数十个科学家,启动新一代无损网络的研究。
经过多年的潜心钻研和探索,他们搞出了独具创新的iLossless智能无损算法方案。这是一个通过人工智能实现网络拥塞调度和网络自优化的AI算法。
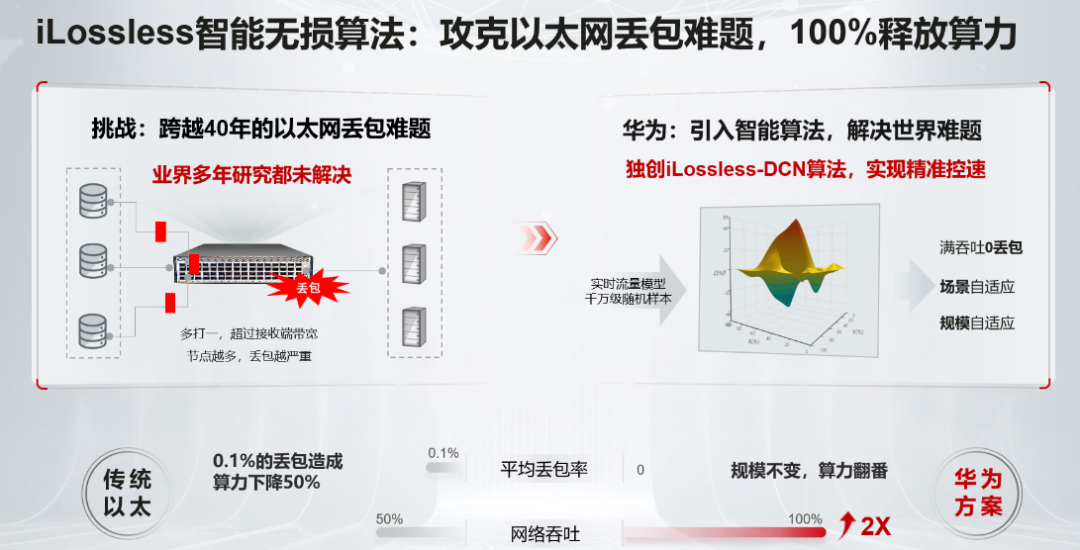
华为iLossless智能无损算法以Automatic ECN为核心,并首次在超高速数据中心交换机引入深度强化学习DRL(Deep Reinforcement Learning)。
对比传统静态阈值配置僵化,无法动态适应网络变化的缺点,Automatic ECN为以太网的流量调度提供了智能预测能力,可以根据当前流量状态精准预测下一刻的拥塞状态,提前做好预留和准备。
基于iLossless智能无损算法,华为发布了超融合数据中心网络CloudFabric 3.0解决方案,引领智能无损进入1.0时代。
2022年,华为超融合数据中心网络继续探索,提出了更强大的智能无损网算一体技术和创新直连拓扑架构,可实现270k大规模算力枢纽网络(组网规模4倍于业界,可助力构建E级和10E级大型和超大型算力枢纽),时延在智能无损1.0的基础上,可进一步降低25%。
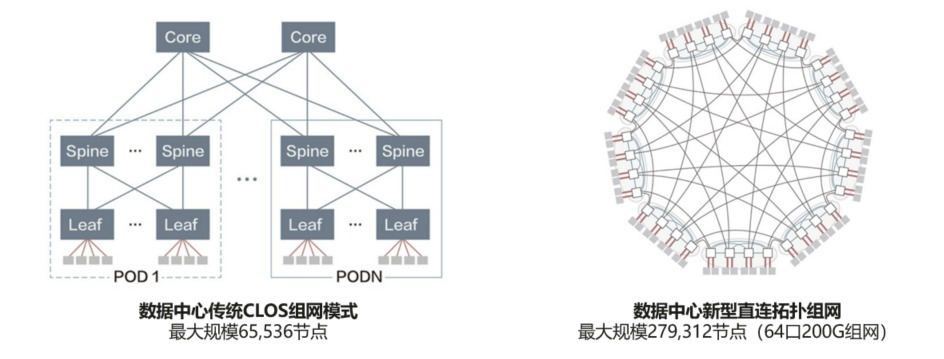
华为的智能无损2.0,基于在网计算(In-network computing)和拓扑感知(Topology-Aware Computing)实现网络和计算协同。一方面,网络参与计算信息的汇聚和同步,减少计算信息同步的次数;另一方面,通过调度确保计算节点就近完成计算任务,减少通信跳数,进一步降低应用时延。
以MPI_allreduce为例,相比传统网络仅做数据转发不参与计算过程,华为超融合数据中心网络可有效降低时延,提升计算效率27%。
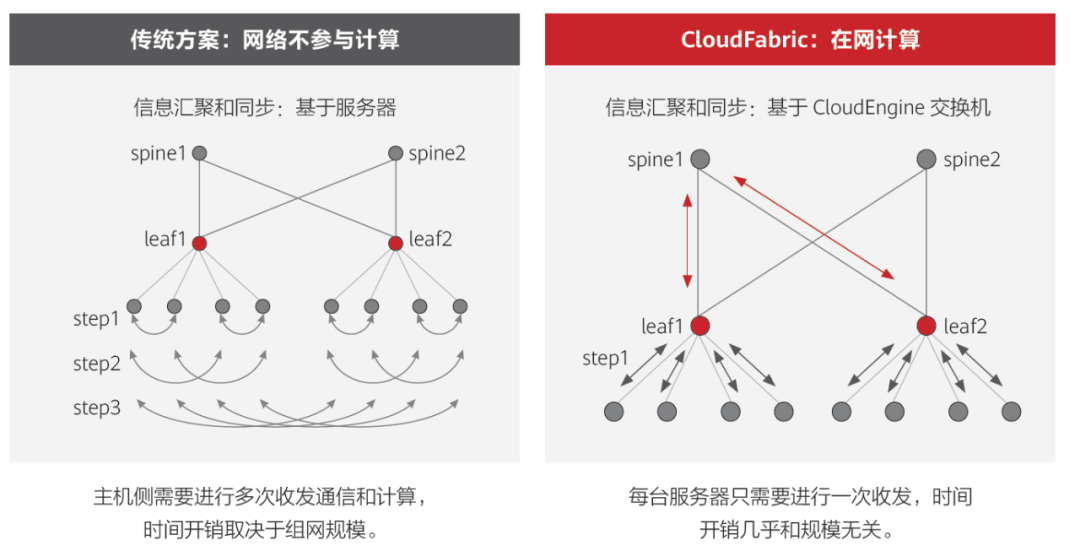
华为超融合数据中心网络解决方案,为数据中心构建了统一融合网络,取代了此前的三种不同类型网络(LAN、SAN、IPC),大幅减少了网络建设成本和运维成本,总成本TCO下降了53%。AI业务的运行效率,则提升了30%以上。
█ 智能无损技术的积累沉淀
近年来,华为围绕智能无损网络和iLossless智能无损算法,接连发布了多个产品和解决方案。
2018年10月,华为就发布了AI Fabric极速以太网解决方案,帮助客户构建与传统以太网兼容的RDMA网络,引领数据中心网络进入极速无损的高性能时代。
2019年1月,华为又发布了业界首款面向AI时代的数据中心交换机CloudEngine 16800,承载了iLossLess智能无损交换算法,实现流量模型自适应自优化,从而在零丢包的基础上,获得更低时延和更高吞吐的网络性能。
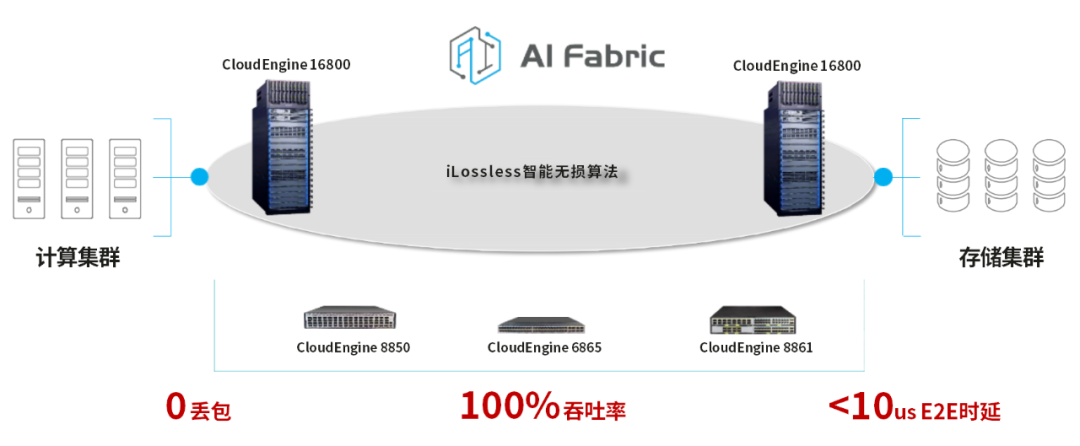
2021年6月,华为发布全无损以太存储网络解决方案(NoF+)。该方案基于OceanStor Dorado全闪存存储系统和CloudEngine数据中心存储网络交换机构建,可实现存储场景端到端数据加速,充分释放全闪存性能潜力。
除了自身积极进行技术研究和产品化之外,华为还积极推动相关技术标准的成熟。
2021年8月,华为发布的智能无损技术论文《ACC: Automatic ECN Tuning for High-Speed Datacenter Networks》(高性能数据中心网络中的ECN动态调优)入选全球网络通信顶级会议ACM SIGCOMM 2021,得到业界专家的一致认可,具有世界级技术影响力。
在华为主导下,IEEE 802成立了Nendica(“Network Enhancements for the Next Decade” Industry Connections Activity)工作组,联合业界共同探讨以太网技术标准发展的新方向,为智能无损网络技术发展提供了理论研究的开放土壤。
█ 智能无损技术的落地实践
经过实际项目验证并获得客户认可的技术,才是可靠的技术。
华为的超融合数据中心网络CloudFabric 3.0解决方案,已经在金融、政府、超算中心、智算中心等客户广泛应用。包括中国银行、云南农信、华夏银行、湖北移动、中科院高能物理研究所、武汉人工智能计算中心、鹏城实验室等在内的众多高端用户,都是华为智能无损技术的使用者。
中国银行联合华为打造的新一代智能无损存储网络“RoCE-SAN”,结合中行具体的应用场景,实现了智能缓存管理、逐流精准控速、故障高可用秒级切换的技术创新突破,满足金融级高可用存储网络要求。
中科院高能物理研究所通过与华为的联合创新,采用零丢包以太网技术,构建了由数万颗CPU核构成的跨地域的高性能计算环境,很好地满足了高能物理领域对算力的需求。
某互联网巨头布局无人驾驶,无人驾驶技能的训练涉及到大量的AI计算:1天采集的数据,需要几百的GPU服务器7天才能训练完,严重影响无人驾驶的上市时间。通过华为的智能无损技术,最终使得整体训练的时长缩短40%,加速无人驾驶的商用进程。
除了丰富的行业落地案例,华为智能无损技术还获得了大量的行业奖项:
2018年6月,日本Interop展Best of Show Award金奖
2020年12月,中国银行业金融科技应用成果大赛“最佳解决方案奖”
2021年4月,日本Interop展Best of Show Award 2020银奖
2021年5月,2021数博会领先科技成果奖之“黑科技”类别
2021年10月,高性能计算领域 “融合架构创新奖”
2022年3月,中国通信学会科学技术奖特等奖
……
这些来自专业领域的认可,更加证明了华为基于智能无损技术的超融合数据中心网络解决方案,在领导力和先进性方面居于行业领先地位。
█ 结语
从逻辑上来看,华为基于智能无损技术的超融合数据中心网络解决方案,是将AI技术在数据中心进行落地,用AI赋能数据中心,再用数据中心,去支撑AI应用。这是一种非常有趣的良性循环,引领了整个ICT行业的智能化潮流。
这个方案是为算力时代量身定制的,可以很好地满足算力时代计算、存储、业务等多种场景数据流通的需要。
放眼未来,AI与数据中心的深度融合,将完美支撑企业数字化转型所需的算力需求,加速数据存储和处理过程,帮助企业快速决策,加快迈入数智时代。
本着“将通信科普到底”的原则,今天,我再继续聊一下这个话题。
故事还是要从头开始说起。
1973年夏天,两名年轻的科学家(温顿·瑟夫和罗伯特卡恩)开始致⼒于在新⽣的计算机⽹络中,寻找⼀种能够在不同机器之间进行通讯的⽅法。
不久后,在一本黄⾊的便签本上,他们画出了TCP/IP协议族的原型。
几乎在同时,施乐公司的梅特卡夫和博格思,发明了以太网(Ethernet)。
我们现在都知道,互联网的最早原型,是老美搞出来的ARPANET(阿帕网)。
ARPANET最开始用的协议超烂,满足不了计算节点规模增长的需求。于是,70年代末,大佬们将ARPANET的核心协议替换成了TCP/IP(1978年)。
进入80年代末,在TCP/IP技术的加持下,ARPANET迅速扩大,并衍生出了很多兄弟姐妹。这些兄弟姐妹互相连啊连啊,就变成了举世闻名的互联网。
可以说,TCP/IP技术和以太网技术,是互联网早期崛起的基石。它们成本低廉,结构简单,便于开发、部署,为计算机网络的普及做出了巨大贡献。
但是后来,随着网络规模的急剧膨胀,传统TCP/IP和以太网技术开始显现疲态,无法满足互联网大带宽、高速率的发展需求。
最开始出现问题的,是存储。
早期的存储,大家都知道,就是机器内置硬盘,通过IDE、SCSI、SAS等接口,把硬盘连到主板上,通过主板上的总线(BUS),实现CPU、内存对硬盘数据的存取。
后来,存储容量需求越来越大,再加上安全备份的考虑(需要有RAID1/RAID5),硬盘数量越来越多,若干个硬盘搞不定,服务器内部也放不下。于是,就有了磁阵。
磁阵就是专门放磁盘的设备,一口子插几十块那种。
硬盘数据存取,一直都是服务器的瓶颈。开始的时候,用的是网线或专用电缆连接服务器和磁阵,很快发现不够用。于是,就开始用光纤。这就是FC通道(Fibre Channel,光纤通道)。
2000年左右,光纤通道还是比较高大上的技术,成本不低。
当时,公共通信网络(骨干网)的光纤技术处于在SDH 155M、622M的阶段,2.5G的SDH和波分技术才刚起步,没有普及。后来,光纤才开始爆发,容量开始迅速跃升,向10G(2003)、40G(2010)、100G(2010)、400G(现在)的方向发展。
光纤不能用于数据中心的普通网络,那就只能继续用网线,还有以太网。
好在那时服务器之间的通信要求还没有那么高。100M和1000M的网线,勉强能满足一般业务的需求。2008年左右,以太网的速率才勉强达到了1Gbps的标准。
2010年后,又出幺蛾子。
除了存储之外,因为云计算、图形处理、人工智能、超算还有比特币等乱七八糟的原因,人们开始盯上了算力。
摩尔定律的逐渐疲软,已经无法支持CPU算力的提升需求。牙膏越来越难挤,于是,GPU开始崛起。使用显卡的GPU处理器进行计算,成为了行业的主流趋势。
得益于AI的高速发展,各大企业还搞出了AI芯片、APU、xPU啊各自五花八门的算力板卡。
算力极速膨胀(100倍以上),带来的直接后果,就是服务器数据吞吐量的指数级增加。
除了AI带来的变态算力需求之外,数据中心还有一个显著的变化趋势,那就是服务器和服务器之间的数据流量急剧增加。
互联网高速发展、用户数猛涨,传统的集中式计算架构无法满足需求,开始转变为分布式架构。
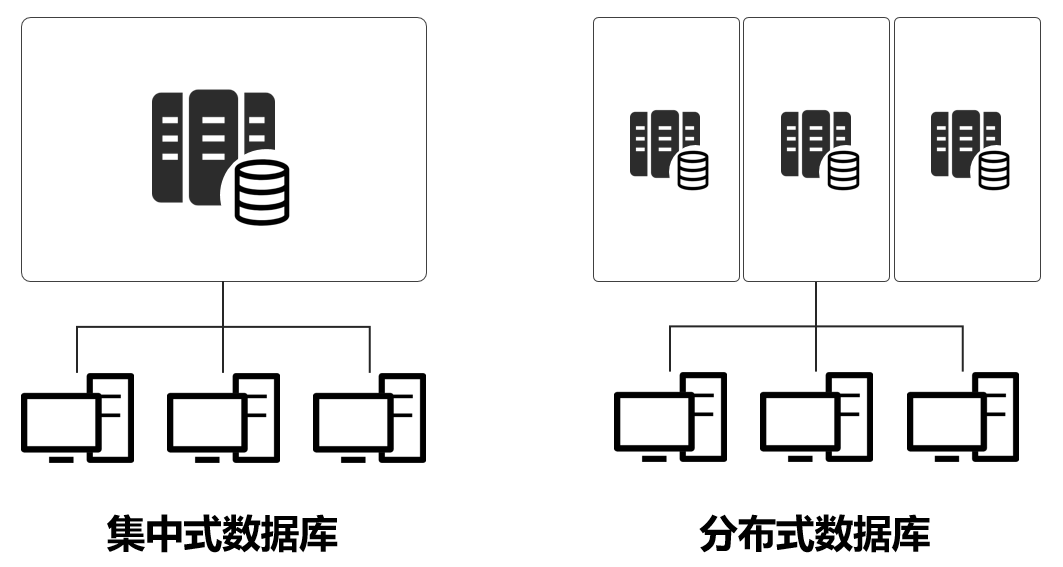
举例来说,现在618,大家都在血拼。百八十个用户,一台服务器就可以,千万级亿级,肯定不行了。所以,有了分布式架构,把一个服务,放在N个服务器上,分开算。
分布式架构下,服务器之间的数据流量大大增加了。数据中心内部互联网络的流量压力陡增,数据中心与数据中心之间也是一样。
这些横向(专业术语叫东西向)的数据报文,有时候还特别大,一些图形处理的数据,包大小甚至是Gb级别。
综上原因,传统以太网根本搞不定这么大的数据传输带宽和时延(高性能计算,对时延要求极高)需求。所以,少数厂家就搞了一个私有协议的专用网络通道技术,也就是Infiniband网络(直译为“无限带宽”技术,缩写为IB)。
FC vs IB vs 以太网
IB技术时延极低,但是造价成本高,而且维护复杂,和现有技术都不兼容。所以,和FC技术一样,只在特殊的需求下使用。
算力高速发展的同时,硬盘不甘寂寞,搞出了SSD固态硬盘,取代机械硬盘。内存嘛,从DDR到DDR2、DDR3、DDR4甚至DDR5,也是一个劲的猥琐发育,增加频率,增加带宽。
处理器、硬盘和内存的能力爆发,最终把压力转嫁到了网卡和网络身上。
学过计算机网络基础的同学都知道,传统以太网是基于“载波侦听多路访问/冲突检测(CSMA/CD)”的机制,极容易产生拥塞,导致动态时延升高,还经常发生丢包。
TCP/IP协议的话,服役时间实在太长,都40多年的老技术了,毛病一大堆。
举例来说,TCP协议栈在接收/发送报文时,内核需要做多次上下文切换,每次切换需要耗费5us~10us左右的时延。另外,还需要至少三次的数据拷贝和依赖CPU进行协议封装。
这些协议处理时延加起来,虽然看上去不大,十几微秒,但对高性能计算来说,是无法忍受的。
除了时延问题外,TCP/IP网络需要主机CPU多次参与协议栈内存拷贝。网络规模越大,带宽越高,CPU在收发数据时的调度负担就越大,导致CPU持续高负载。
按照业界测算数据:每传输1bit数据需要耗费1Hz的CPU,那么当网络带宽达到25G以上(满载)的时候,CPU要消费25GHz的算力,用于处理网络。大家可以看看自己的电脑CPU,工作频率是多少。
那么,是不是干脆直接换个网络技术就行呢?
不是不行,是难度太大。
CPU、硬盘和内存,都是服务器内部硬件,换了就换了,和外部无关。
但是通信网络技术,是外部互联技术,是要大家协商一起换的。我换了,你没换,网络就嗝屁了。
全世界互联网同时统一切换技术协议,你觉得可不可能?
不可能。所以,就像现在IPv6替换IPv4,就是循序渐进,先双栈(同时支持v4和v6),然后再慢慢淘汰v4。
数据中心网络的物理通道,光纤替换网线,还稍微容易一点,先小规模换,再逐渐扩大。换了光纤后,网络的速度和带宽上的问题,得以逐渐缓解。
网卡能力不足的问题,也比较好解决。既然CPU算不过来,那网卡就自己算呗。于是,就有了现在很火的智能网卡。某种程度来说,这就是算力下沉。
搞5G核心网的同事应该很熟悉,5G核心网媒体面网元UPF,承担了无线侧上来的所有业务数据,压力极大。
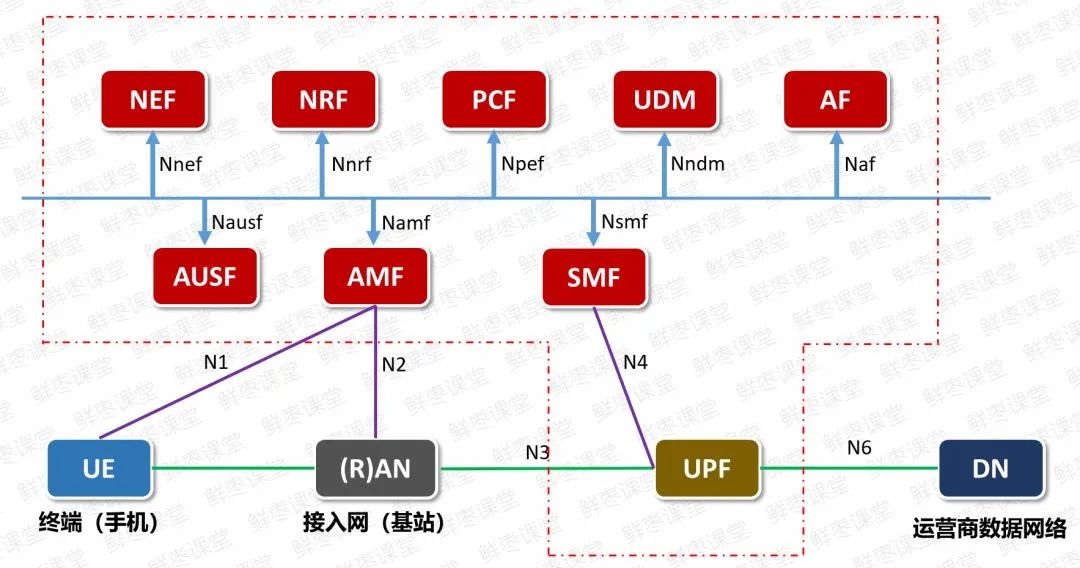
现在,UPF网元就采用了智能网卡技术,由网卡自己进行协议处理,缓解CPU的压力,流量吞吐还更快。
如何解决数据中心通信网络架构的问题呢?专家们想了半天,还是决定硬着头皮换架构。他们从服务器内部通信架构的角度,重新设计一个方案。
在新方案里,应用程序的数据,不再经过CPU和复杂的操作系统,直接和网卡通信。
这就是新型的通信机制——RDMA(Remote Direct Memory Access,远程直接数据存取)。
RDMA相当于是一个“消灭中间商”的技术,或者说“走后门”技术。
RDMA的内核旁路机制,允许应用与网卡之间的直接数据读写,将服务器内的数据传输时延降低到接近1us。 同时,RDMA的内存零拷贝机制,允许接收端直接从发送端的内存读取数据,极大的减少了CPU的负担,提升CPU的效率。 RDMA的能力远远强于TCP/IP,逐渐成为主流的网络通信协议栈,将来一定会取代TCP/IP。
RDMA有两类网络承载方案,分别是专用InfiniBand和传统以太网络。
RDMA最早提出时,是承载在InfiniBand网络中。
但是,InfiniBand是一种封闭架构,交换机是特定厂家提供的专用产品,采用私有协议,无法兼容现网,加上对运维的要求过于复杂,并不是用户的合理选择。
于是,专家们打算把RDMA移植到以太网上。
比较尴尬的是,RDMA搭配传统以太网,存在很大问题。
RDMA对丢包率要求极高。0.1%的丢包率,将导致RDMA吞吐率急剧下降。2%的丢包率,将使得RDMA的吞吐率下降为0。
InfiniBand网络虽然贵,但是可以实现无损无丢包。所以RDMA搭配InfiniBand,不需要设计完善的丢包保护机制。 现在好了,换到传统以太网环境,以太网的人生态度就是两个字——“摆烂”。以太网发包,采取的是“尽力而为”的原则,丢包是家常便饭,丢了就再传。
于是,专家们必须解决以太网的丢包问题,才能实现RDMA向以太网的移植。再于是,就有了前天文章提到的,华为的超融合数据中心网络智能无损技术。
说白了,就是让以太网做到零丢包,然后支撑RDMA。有了RDMA,就能实现超融合数据中心网络。
关于零丢包技术的细节,我不再赘述,大家看前天那篇文章(再给一遍链接:这里)。
值得一提的是,引入AI的网络智能无损技术是华为的首创,但超融合数据中心,是公共的概念。除了华为之外,别的厂家(例如深信服、联想等)也讲超融合数据中心,而且,这个概念在2017年就很热了。
什么叫超融合?
准确来说,超融合就是一张网络,通吃HPC高性能计算、存储和一般业务等多种业务类型。处理器、存储、通信,全部都是超融合管理的资源,大家平起平坐。
超融合不仅要在性能上满足这些低时延、大带宽的变态需求,还要有低成本,不能太贵,也不能太难维护。
未来,数据中心在整体网络架构上,就是叶脊网络一条路走到黑(到底什么是叶脊网络?)。路由交换调度上,SDN、IPv6、SRv6慢慢发展。微观架构上,RDMA技术发展,替换TCP/IP。物理层上,全光继续发展,400G、800G、1.2T…
我个人臆测,目前电层光层的混搭,最终会变成光的大一统。光通道到全光交叉之后,就是渗透到服务器内部,服务器主板不再是普通PCB,而是光纤背板。芯片和芯片之间,全光通道。芯片内部,搞不好也是光。
光通道是王道
路由调度上,以后都是AI的天下,网络流量啊协议啊全部都是AI接管,不需要人为干预。大量的通信工程师下岗。
审核编辑:刘清
-
适用于数据中心和AI时代的800G网络2025-03-25 2749
-
睿海光电以高效交付与广泛兼容助力AI数据中心800G光模块升级2025-08-13 744
-
数据中心子系统的组成2011-11-11 5877
-
数据中心的健康检查(电气篇)2016-03-18 3648
-
锐捷助互联网数据中心网络自动化、可视化运维2017-01-25 5630
-
请问光学模块如何进化以满足数据中心需求?2018-05-23 2431
-
数据中心的建设也看重风水2019-08-07 3207
-
数据中心光互联解决方案2020-07-03 3334
-
未来数据中心与光模块发展假设2020-08-07 3040
-
ARM是如何满足数据中心需求的2021-02-01 1706
-
数据中心是什么2021-07-12 2169
-
什么是数据中心2021-09-15 2347
-
数据中心UPS系统的选择与规模2010-12-29 961
-
适用于数据中心和 AI 时代的网络2023-10-27 1506
-
意法半导体为超大规模AI数据中心破解供电难题2026-04-07 552
全部0条评论

快来发表一下你的评论吧 !
