

大模型Reward Model的trick应用技巧
人工智能
描述
引入
在大家搞RLHF中经常遇到的一个核心的问题是,RM的水平不够好没法训练得到想要的效果,其背后两大类基本的原因是:1.数据质量低。2.模型泛化能力差。
复旦MOSS这篇技术报告,从这两个问题入手,提出了一系列方法优化和提升。
核心问题
展开来讲的话,关于1.数据质量低 2.模型泛化能力差这两个问题具体指的是:
一、数据质量低:数据集中的错误和模糊的偏好对(pairs),可能导致奖励模型(RM)无法准确捕捉人类的偏好。你通过数据透传给你的模型,一会儿向左,一会儿向右,模型也要学懵。
二、泛化能力差:奖励模型在特定分布上训练后,很难泛化到该分布之外的例子,且不适合迭代式的RLHF训练(提升RLHF的重要路径之一)。你的模型训练得到了一个二极管,对于自己相信的东西表现的非常极端,对于没见过的东西就傻眼了。
针对这两类问题,作者提出了两个视角的方法,分别从数据角度和算法角度出发。
一、数据角度:使用多个奖励模型的输出,增加数据度量的信息源,用这种方法来量化数据中偏好的强度信息,并通过这种方法来识别和纠正错误或模糊的偏好对。对于不同质量水平,模糊度水平的数据,采取了不一样的措施,有翻转,软标签,适应性margin等具体方法,后面具体展开讲解。
二、算法角度:借助对比学习和元学习的方法。增加对比学习的loss,对比学习通过增强模型区分能力,来增强RM的对好坏的区分水平。元学习则使奖励模型能够维持区分分布外样本的细微差异,这种方法可以用于迭代式的RLHF优化。
数据视角
在论文中,"Measuring the Strength of Preferences"(测量偏好强度)部分提出了一种基于多奖励模型投票的方法来量化数据中偏好的强度。这种方法的具体步骤如下:
1.训练多个奖励模型:使用相同的偏好数据集,随机化训练顺序,训练多个奖励模型。这些模型可以是相同的结构,但初始化权重不同,以增加多样性。
2.计算偏好强度:对于每一个pair,例如,两个由SFT模型生成的输出和,使用这些奖励模型计算每个模型对这两个输出的奖励分数 和 。然后,计算每个比较对的偏好强度,其中是被选择的输出,是被拒绝的输出。
计算平均值和标准差:使用所有奖励模型的分数来计算偏好强度的平均值和标准差。这些统计量可以帮助评估偏好的一致性和强度。
分析偏好强度分布:通过观察偏好强度的平均值和标准差的分布,可以识别出数据集中可能存在的错误或模糊偏好。例如,如果偏好强度的平均值接近0,可能表明偏好标签不正确;如果标准差很大,可能表明偏好差异不明显,模型在这些数据上可能不够鲁棒。
作者给了一个分布分析的例子,分别是前面提到的这个度量的均值和方差通过10个模型得到的分布。
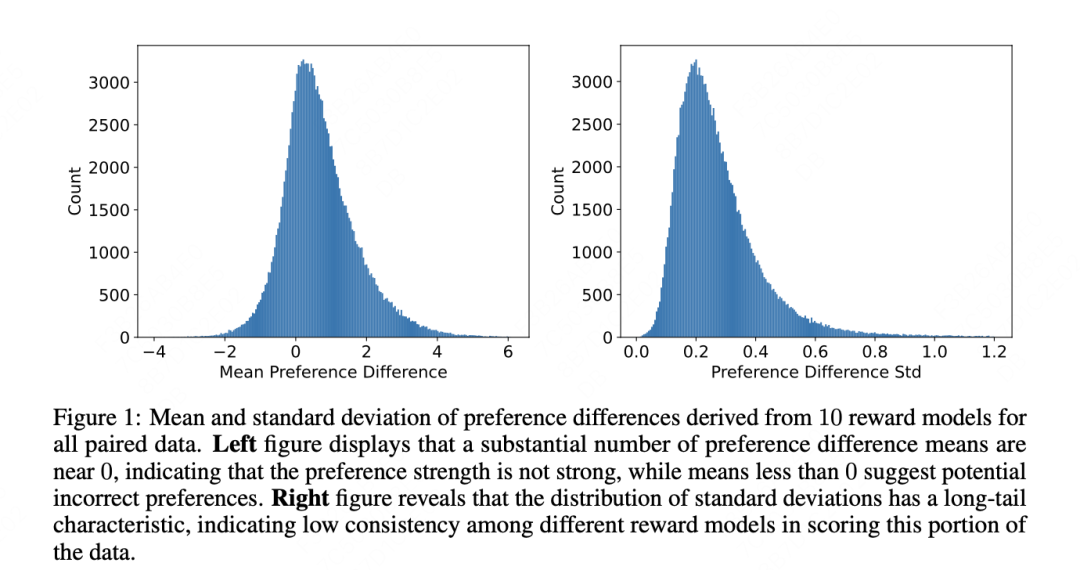
可以看出数据的区分性比较强,并且随着的上升,和GPT4标注结果的一致性也在上升。
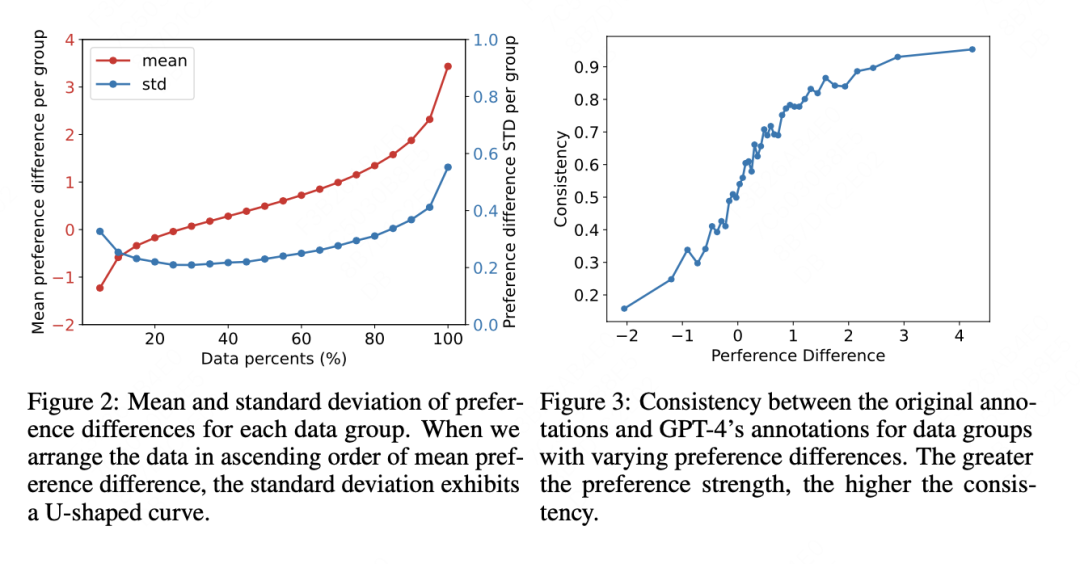
通过如上的方法就可以把数据大概分开,我们划分为3类进行分析。
1.低强度的偏好数据的负面影响:研究发现,数据集中偏好强度最低的20%的数据对模型在验证集上的性能有负面影响。这些数据的偏好强度平均值小于0,表明这些数据可能包含错误的偏好标签。
2.中等强度偏好数据的中立影响:偏好强度在20%到40%之间的数据,在训练后,模型在验证集上的预测准确率大约为0.5。这些数据的偏好强度平均值接近0,表明这些数据的偏好差异不大,模型在这些数据上的学习效果一般。
3.高强度的偏好数据的积极影响:剩余的数据(偏好强度最高的60%)显著提高了模型的性能。然而,仅使用偏好强度最高的10%的数据训练模型时,并没有达到最佳性能。这可能是因为这些数据过于强烈,导致模型可能过度拟合这些数据。
归纳出偏好强度信息后,我们可以根据偏好强度的测量结果,可以对数据集进行分类,并对不同类别的数据采取不同的处理策略。
对于低强度的偏好数据,隐含标签错误的可能性,通过翻转偏好对的标签可以有效地提高模型性能。对于中强度的,比较模糊的偏好数据,应用软标签和适应性边距可以避免模型过度拟合。对于高强度的偏好数据,使用软标签和适应性边距的组合特别有效。
具体的三个手段:反转,即为标签倒置,软标签是不使用0和1的hard lable,用度量偏好差异的作为软标签,就是来回归 ,并且增加了这样的自适应参数。

adaptive margin
一种让同类聚集,异类区分度增大的经典方法,来自于人脸识别的经典方法。

作者给了这几种方法的详细实验过程:包含了reward,loss,ppl,输出len等角度的度量。
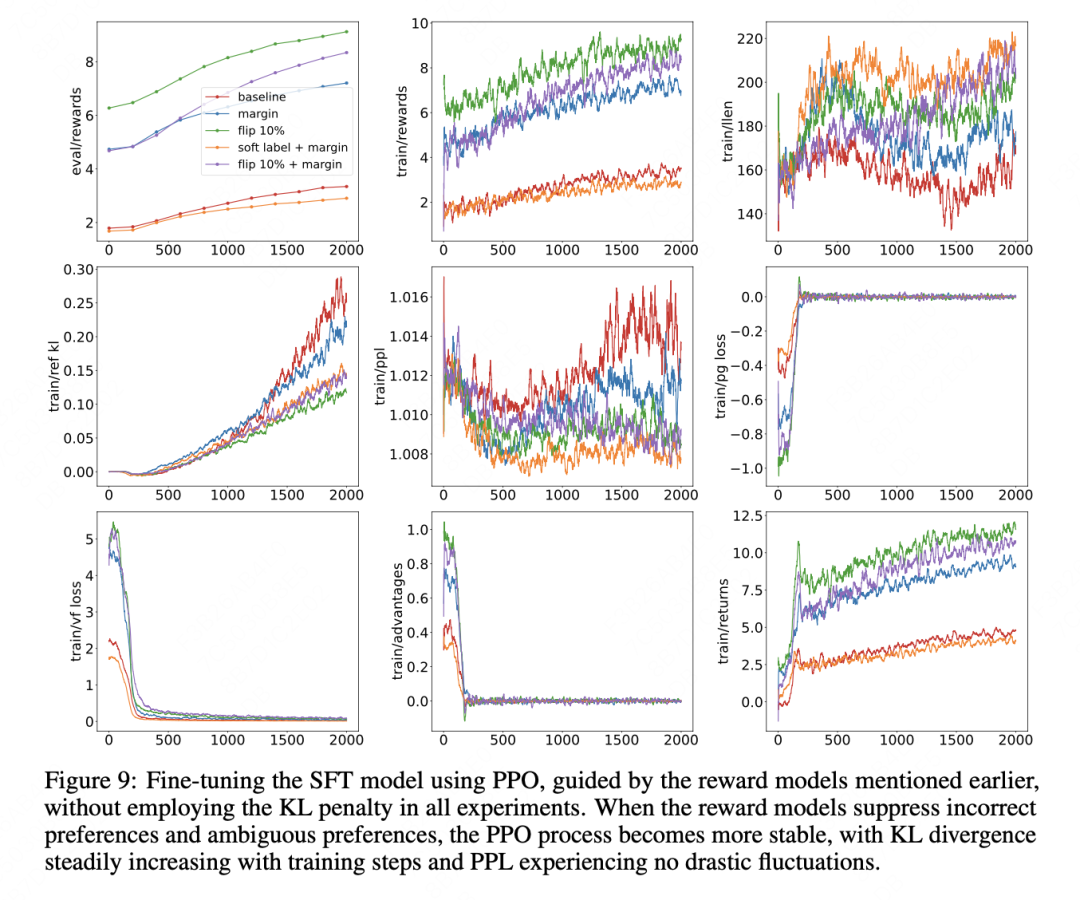
整体看起来,软标签适用在中上强度的偏好数据,margin方法在所有强度数据都适用。
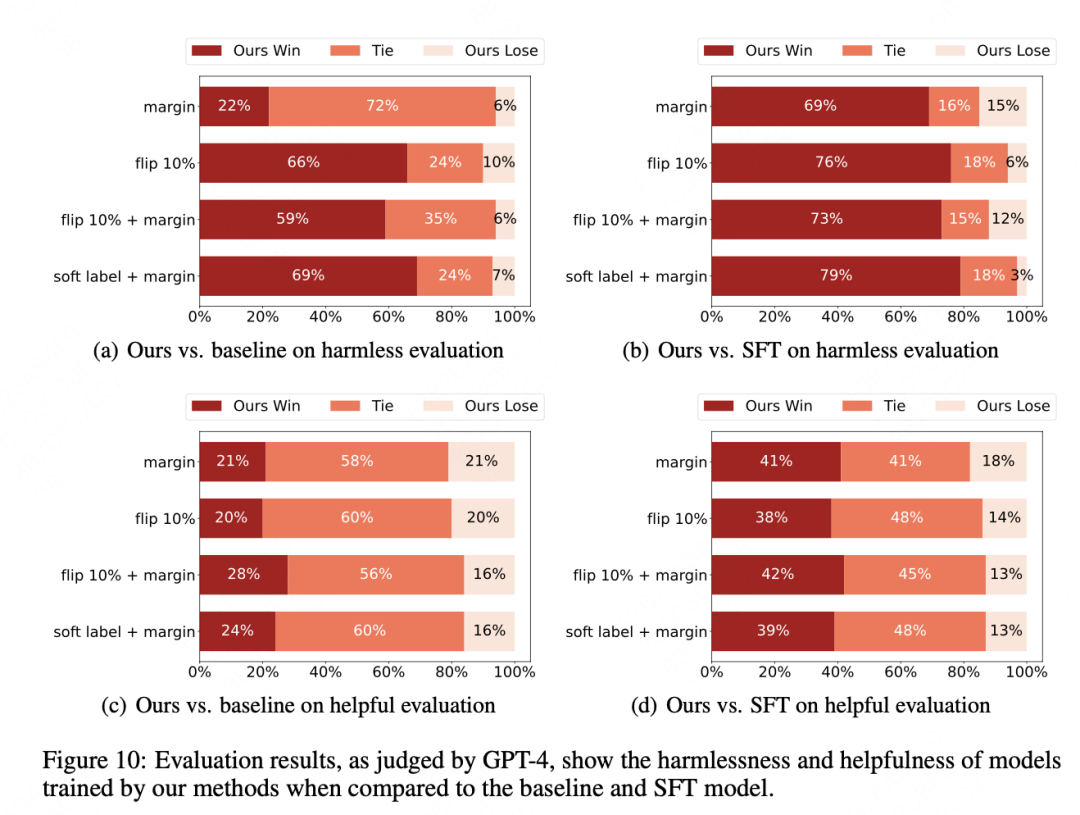
算法视角
在论文的 "Preference Generalization and Iterated RLHF"(偏好泛化和迭代RLHF)部分,作者们提出了两种主要的方法来提高奖励模型(Reward Model, RM)的泛化能力,使其能够在分布变化的情况下仍然能够有效地区分不同的响应。具体做法如下:
一、对比学习(Contrastive Learning):
选择正负样本:在模型上接入对比学习损失。
形式很简单,其核心就是如何构造对比学习的学习方法。有两种方法:1.直接学习偏好对(Preference Pairs)的表征,也就是最普通的对比学习。2.学习前文提到的偏好差异(Preference Difference),,这种差异本质上也是一种对比的度量。
作者选取两种对比学习swAV和simcse,交叉了两种学习方式,得到了如下的实验结果。
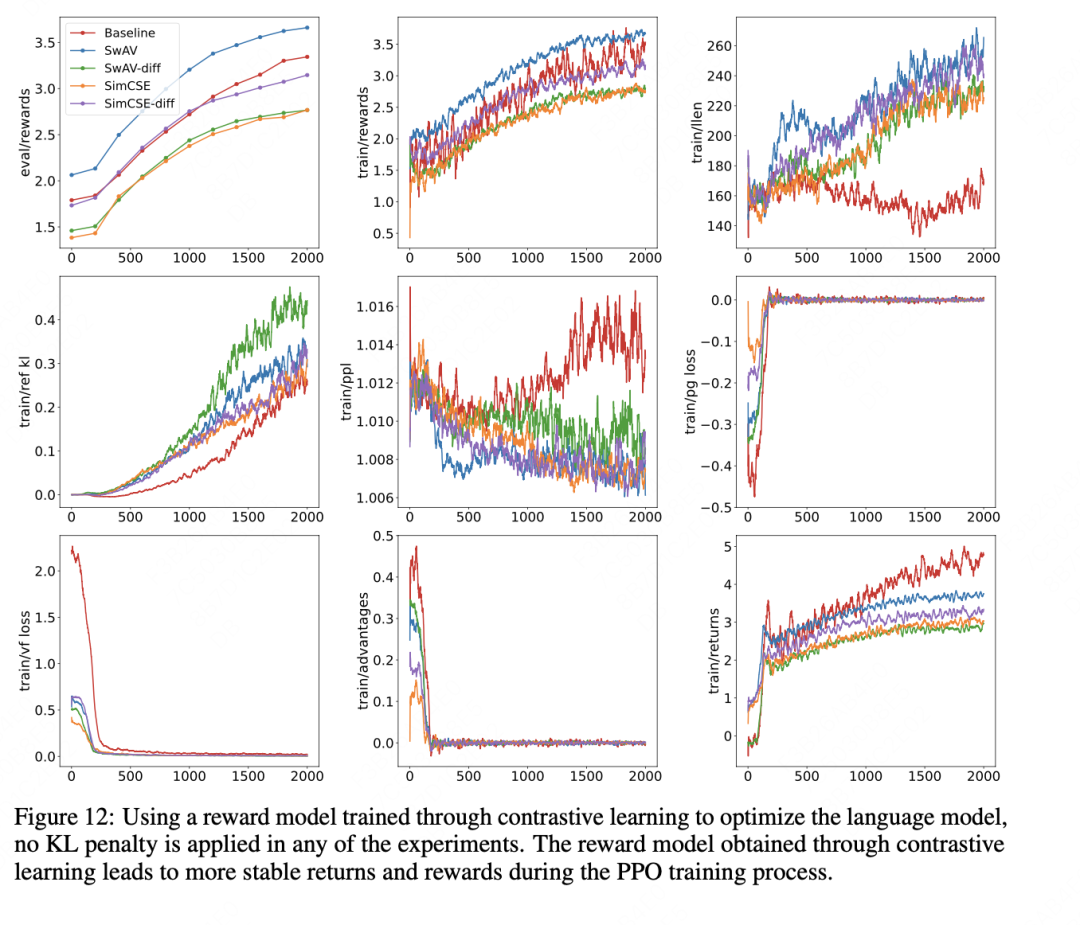
二、MetaRM(Meta Reward Model)
提出了一种名为MetaRM的方法,通过元学习来对齐原始偏好对与分布变化。MetaRM的关键思想是在训练阶段最小化原始偏好对的损失,同时最大化对从新分布中采样的响应的区分能力。
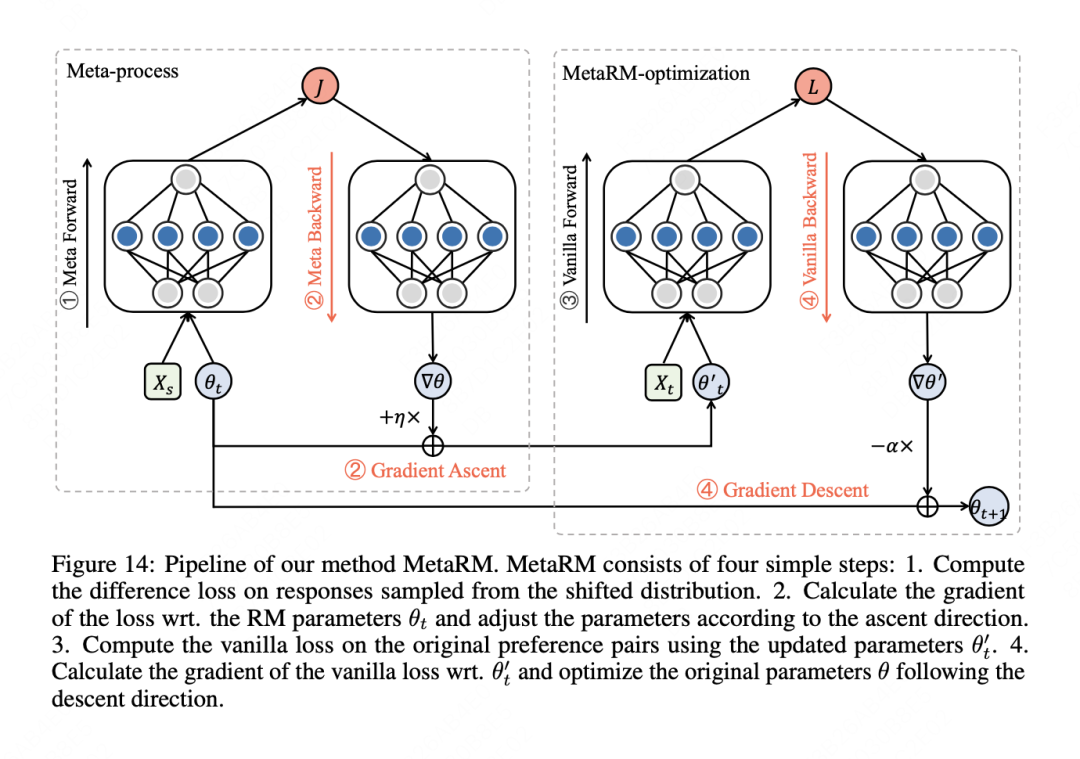
训练过程:MetaRM的训练过程包括四个步骤:计算从新分布中采样的响应的差异损失,计算损失相对于RM参数的梯度并更新参数,计算原始偏好对的损失,以及计算损失相对于更新后的参数的梯度并优化原始参数。
具体,MetaRM 的算法包括以下步骤:
1.从偏好对数据集 中采样一个batch 。
2.从元数据集 中采样一个batch 。
3.在 上计算差异损失 。
4.使用元学习更新奖励模型的参数 。
5.在 上计算原始损失 。
6.使用原始损失的梯度更新奖励模型的参数 θt。
其优化目标是通过最大化差异损失函数 和最小化原始损失函数 来训练奖励模型。这样,奖励模型既能学习到原始偏好对,又能适应策略模型输出分布的变化。

通过这些方法,奖励模型能够更好地捕捉数据中细微的偏好差异,从而在面对新分布的数据时保持其区分能力。这使得奖励模型能够在迭代的RLHF过程中更稳定地优化语言模型,即使在模型输出分布发生变化时也能保持其指导优化的能力。
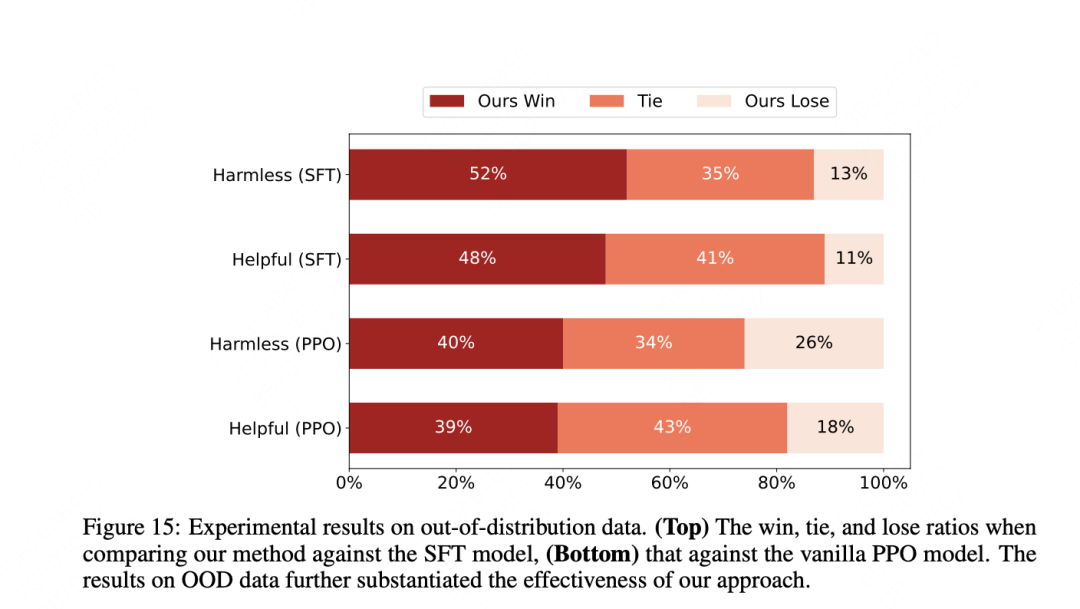
主要实验结果如图所示:MetaRM 在分布内和分布外任务评估中都显示出了优越的性能。在分布内任务中,MetaRM 在多个回合的 PPO 训练后,其性能显著优于基线模型。
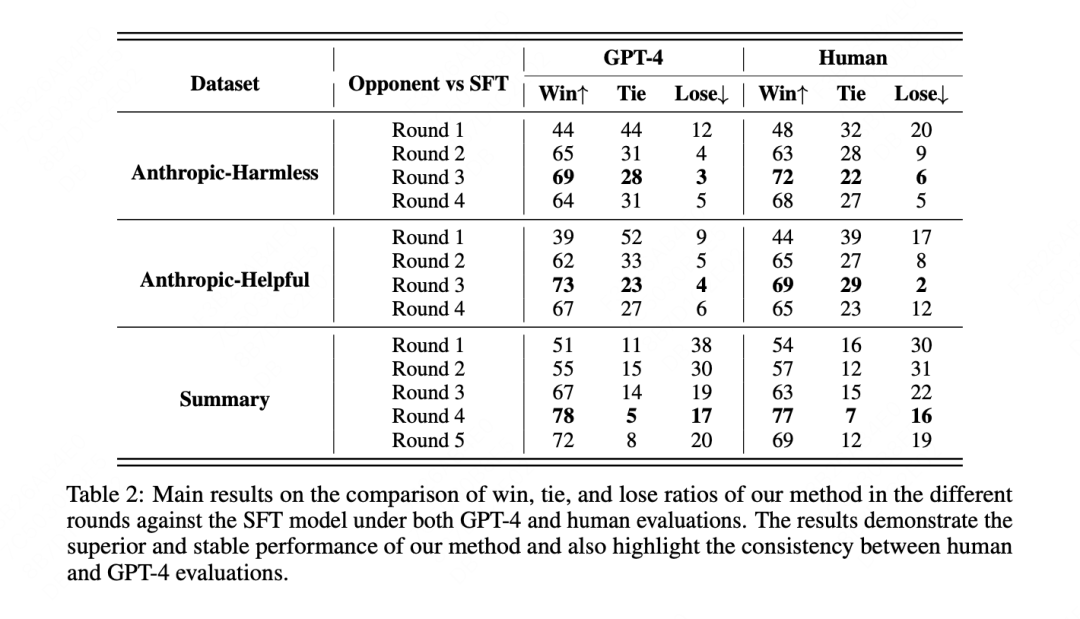
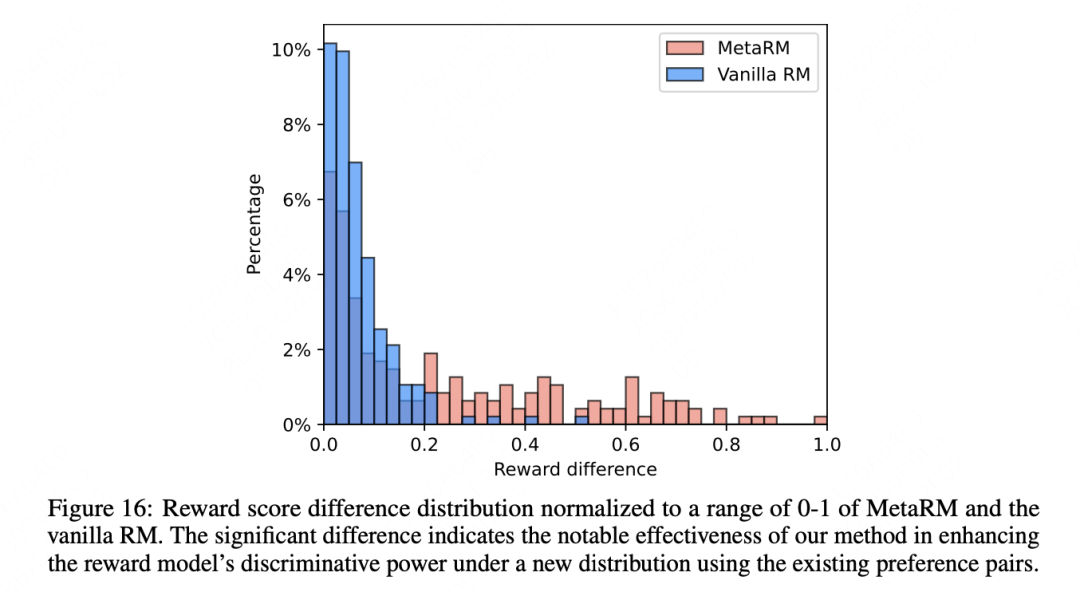
另外在OOD上的表现做了单独的分析,在分布外任务中,MetaRM 继续优于基线模型,表明其方法能够有效地在新领域实现对齐,而无需对一组query进行成本高昂的重新标注。
总结
总结来说,作者们在报告中提出了一系列方法来解决开头提到的核心问题,如何增加RM的泛化能力,从数据和算法角度,分别提出了两个问题核心问题和对应的解决方法,旨在提高奖励模型在处理错误偏好数据和泛化到新分布数据时的性能。
审核编辑:黄飞
-
BLE MESH 智能开关开发 情景模式(睡眠、明亮) 蓝牙model如何分配,如何配置model2025-02-12 5003
-
拆解大语言模型RLHF中的PPO算法2023-12-11 4234
-
keras顺序模型与函数式模型2023-08-18 659
-
Cycle Model Studio 9.2版用户手册2023-08-12 715
-
电子电路仿真基础:什么是热动态模型(Thermal Dynamic Model)2023-02-14 2807
-
文本分类中处理样本不均衡和提升模型鲁棒性的trick2022-10-11 1983
-
周易AIPU Model Zoo模型list2021-08-14 3847
-
关于基于模型的设计加快NASA GNC算法开发教程和应用2019-09-18 4174
-
IC设计基础:说说wire load model2018-05-21 16311
-
ORCAD 17.0 PSpice Model Editor 模型编辑器无法使用2016-03-16 10330
-
labview arima model的模型怎么建立2013-02-18 2061
-
击落模型定位器电路 (Downed Model Locato2010-01-09 883
全部0条评论

快来发表一下你的评论吧 !
