

探索ICLR‘24 Spotlight中的首个十亿级别3D通用大模型
描述
智源视觉团队近期的工作:3D视觉大模型Uni3D在ICLR 2024的评审中获得了688分,被选为Spotlight Presentation。在本文中,作者第一次将3D基础模型成功scale up到了十亿(1B)级别参数量,并使用一个模型在诸多3D下游应用中取得SOTA结果。代码和各个scale的模型(从6M-1B)均已开源:
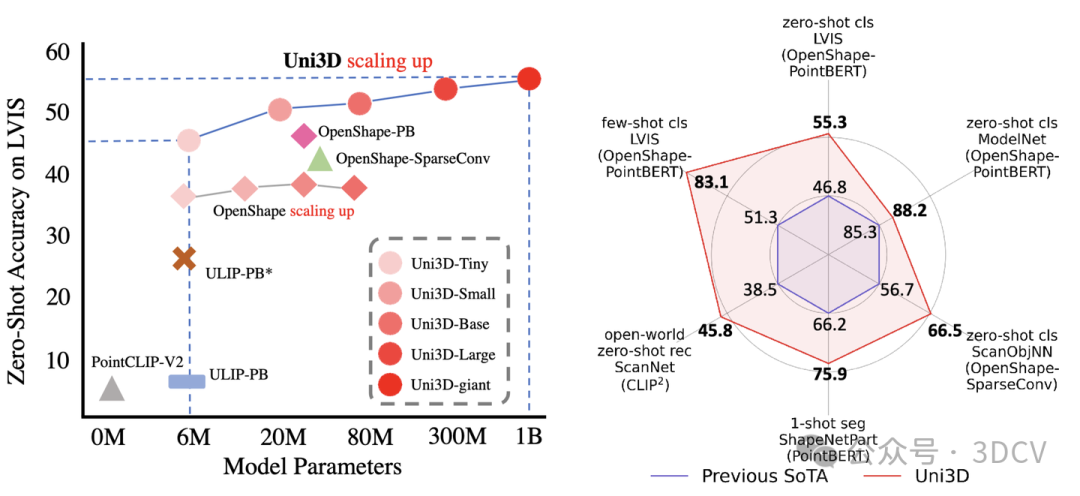
作者主要探索了3D视觉中scale up模型参数量和统一模型架构的可能性。在NLP / 2D vision领域,scale up大模型(GPT-4,SAM,EVA等)已经取得了很impressive的结果,但是在3D视觉中模型的scale up始终没有成功。Uni3D旨在将NLP/2D中scale up的成功复现到3D表征模型上。
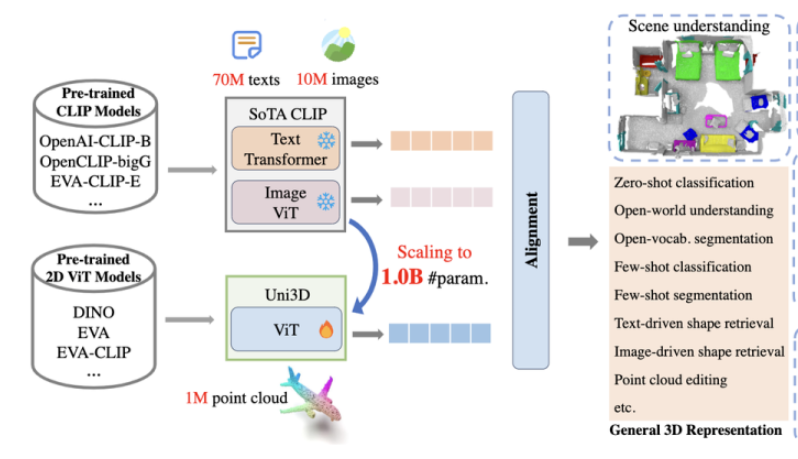
在这项工作中,作者提出了一个3D基础大模型Uni3D,直接将3D backbone统一为ViT(Vision Transformer),以此利用丰富和强大的2D预训练大模型作为初始化。Uni3D使用CLIP模型中的文本/图像表征作为训练目标,通过学习三个模态的表征对齐(点云-图像-文本)实现3D点云对图像和文本的感知。同时,通过使用ViT中成功的scale up策略,我们将Uni3D逐步 scale up,训练了从Tiny到giant的5个不同scale的Uni3D模型,成功地将Uni3D扩展到10亿级别参数。
下游应用:
Uni3D在多个3D任务上达到SoTA,如:zero-shot classification, few-shot classification,open-world understanding, open-world part segmentation.
零样本/少样本分类
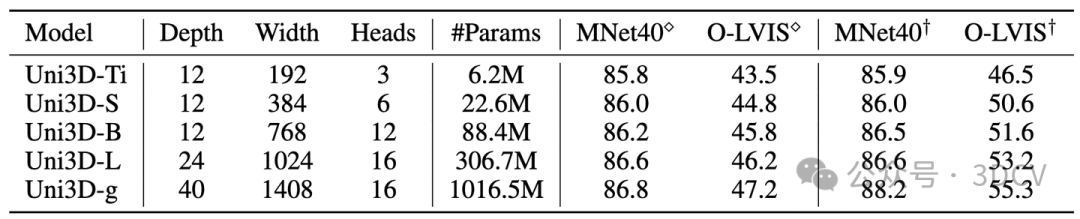
Uni3D在ModelNet上实现了88.2%的零样本分类准确率,甚至接近了有监督学习方法的结果(如PointNet 89.2 %);
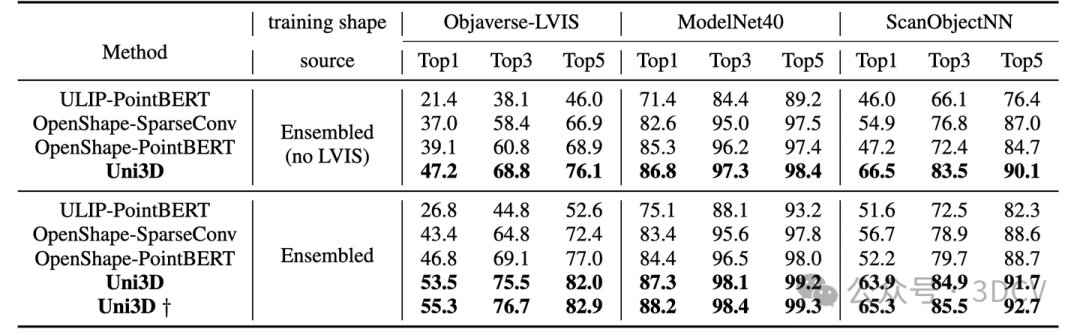
在最困难的Objaverse-LVIS基准下,Uni3D取得了55.3%的零样本分类准确率,大幅刷新了该榜单。
而在Objaverse-LVIS基准的少样本分类测试中,Uni3D实现了83.1%的准确率(16样本下),明显超过了以往的最先进基准OpenShape 32%。
开放世界的理解能力
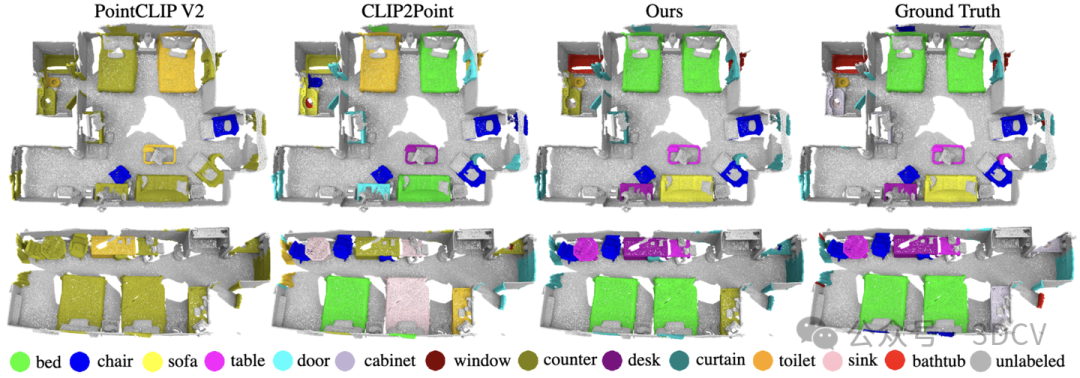
研究团队采用与CLIP2相同的设置在ScanNet测试集下探究Uni3D在现实场景下的零样本识别性能。与之前最先进的SOTA方法PointCLIP、PointCLIP V2 、CLIP2Point 和CLIP2 相比,Uni3D表现最佳。

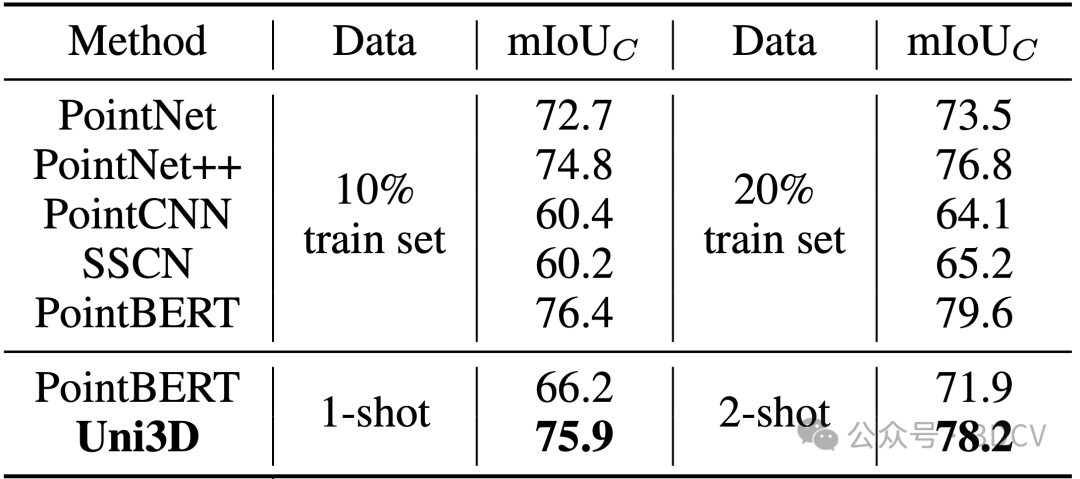
Uni3D在少样本点云部件分割任务上也展示出了卓越的性能。下表结果显示,在各种实验条件下,Uni3D的性能都明显优于Point-BERT等基线方法。即便只使用每类一个样本训练,Uni3D也达到了使用10%的训练数据的先前基线方法(如PointNet++,Point-BERT)的水平,在训练集的规模相对减少两个数量级的情况下,仍能显示出Uni3D更强的细粒度3D结构理解能力。
由于学到了强大的多模态表征能力,Uni3D还能够做一些有意思的应用,如point cloud painting(点云绘画),text/image-based 3D shape retrieval(基于图像/文本的3D模型检索),point cloud captioning(点云描述):
点云绘画:体现了在3D AIGC上的潜在能力
给定一个文本,Uni3D通过优化点云的颜色来提高点云和文本在特征空间的相似度,基于此实现文本操控的点云内容创作和点云绘画。

文本驱动/图像驱动的三维形状检索:体现在构建多模态检索库上的潜在能力
Uni3D通过学习到的统一的三维多模态表示,具有感知多个2D/语言信号的能力,可以通过图像或文本输入从大型3D数据集中检索三维形状。这是通过计算查询图像/文本提示的embedding与3D形状的embedding入之间的余弦相似度来实现了对查询的最相似3D形状的获取。
Uni3D 还可根据输入文本来检索 3D 形状
将之前已经成熟的“文搜图/图搜图”扩展到“文搜3D/图搜3D”,这使得检索互联网上大规模未标定的繁杂三维模型成为可能,为相关三维领域从业者、创作者搜集素材提供实用工具。
Uni3D 还可给定点云生成对应的文本描述
Uni3D扩展为Text-to-3D generation tasks的评测指标
在text-to-3D研究领域,目前量化度量仍然是一个较难的问题。目前的量化指标都是将生成的3D模型渲染为2D图片,利用2D指标衡量生成质量。然而由于渲染角度互相独立以及3D模型自遮挡等问题,2D评价指标难以完全真实反映出3D生成模型的真实能力。如下图,生成的3D模型有明显的3D不一致性问题,但是单独看其中大部分的视角渲染图片都是正常的物体,导致2D评价指标往往难以反映生成3D模型的不一致问题。
作者团队近期推出的Text-to-3D generation 工作GeoDream提出利用目前最大最强的3D基础模型Uni3D,直接对3D模型进行评估,避免渲染带来的视角问题。相应的评价指标代码也开源到GeoDream的代码库中 (https://github.com/baaivision/GeoDream) 。
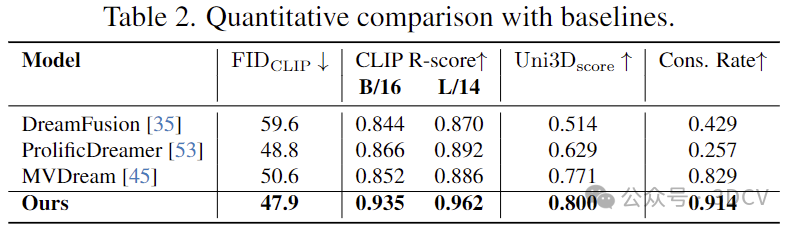
量化比较:在生成质量和语义保持性的量化测试上,GeoDream相比于之前方法取得显著提升。在基于渲染2D图片的量化指标(FID,CLIP-Score)和直接在3D空间度量生成的3D资产量化指标(Uni3D-Score)上均有提升,说明GeoDream渲染的图片和3D结构均有优势。
审核编辑:黄飞
-
ad19中3d模型不显示?2024-04-24 2470
-
LABVIEW如何驱动3D模型2013-02-28 9049
-
Labview 3D模型2013-08-26 11426
-
Labview中如何导入3D 的模型2014-01-26 21069
-
3d模型问题2015-11-12 3131
-
分享贴片3D模型2019-12-18 3091
-
浩辰3D软件中如何创建槽特征?3D模型设计教程!2020-09-28 1646
-
浩辰3D软件入门教程:如何比较3D模型2020-12-15 2517
-
AD的3D模型绘制功能介绍2021-01-14 4198
-
3D模型的基础介绍2021-01-28 2864
-
3D设计软件中怎么创建风扇叶模型?浩辰3D基础教程2021-06-04 5165
-
3D模型2015-11-04 1768
-
3D技术的应用探索3D机器视觉库2016-03-22 1036
-
关于 AD 中如何创建 3D 模型及设计教程 Ver1.02018-01-25 1821
-
高分工作!Uni3D:3D基础大模型,刷新多个SOTA!2024-01-30 2059
全部0条评论

快来发表一下你的评论吧 !
