

高分工作!Uni3D:3D基础大模型,刷新多个SOTA!
描述
我们近期的工作:3D视觉大模型Uni3D在ICLR 2024的评审中获得了688分,被选为Spotlight Presentation

在本文中,我们第一次将3D基础模型成功scale up到了十亿(1B)级别参数量,并使用一个模型在诸多3D下游应用中取得SoTA结果。代码和各个scale的模型(从6M-1B)均已开源,欢迎大家关注和使用:
论文:https://https://arxiv.org/pdf/2310.06773
代码:https://https://github.com/baaivision/Uni3D

我们主要探索了3D视觉中scale up模型参数量和统一模型架构的可能性。在NLP / 2D vision领域,scale up大模型(GPT-4,SAM,EVA等)已经取得了很impressive的结果,但是在3D视觉中模型的scale up始终没有成功。我们旨在将NLP/2D中scale up的成功复现到3D表征模型上。

在这项工作中,我们提出了一个3D基础大模型Uni3D,直接将3D backbone统一为ViT(Vision Transformer),以此利用丰富和强大的2D预训练大模型作为初始化。Uni3D使用CLIP模型中的文本/图像表征作为训练目标,通过学习三个模态的表征对齐(点云-图像-文本)实现3D点云对图像和文本的感知。同时,通过使用ViT中成功的scale up策略,我们将Uni3D逐步 scale up,训练了从Tiny到giant的5个不同scale的Uni3D模型,成功地将Uni3D扩展到10亿级别参数。
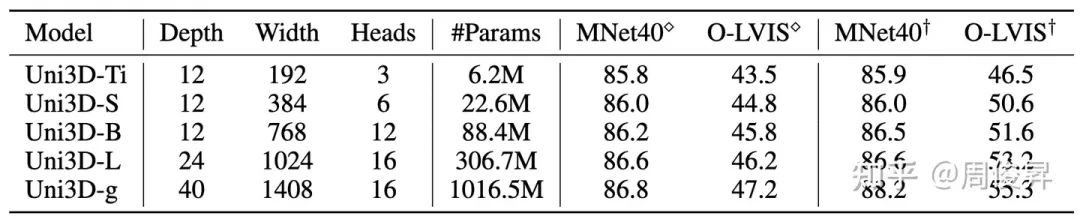
Uni3D模型不同scale下的参数量和zero-shot分类结果
Uni3D在多个3D任务上达到SoTA,如:zero-shot classification, few-shot classification,open-world understanding, open-world part segmentation.
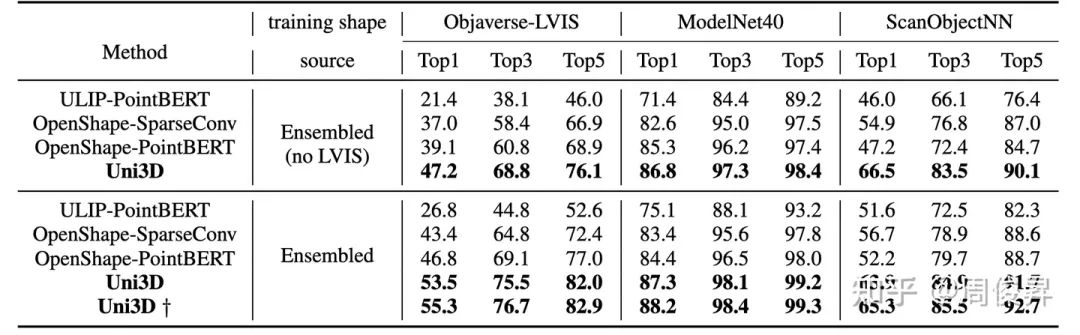
Zero-shot classification
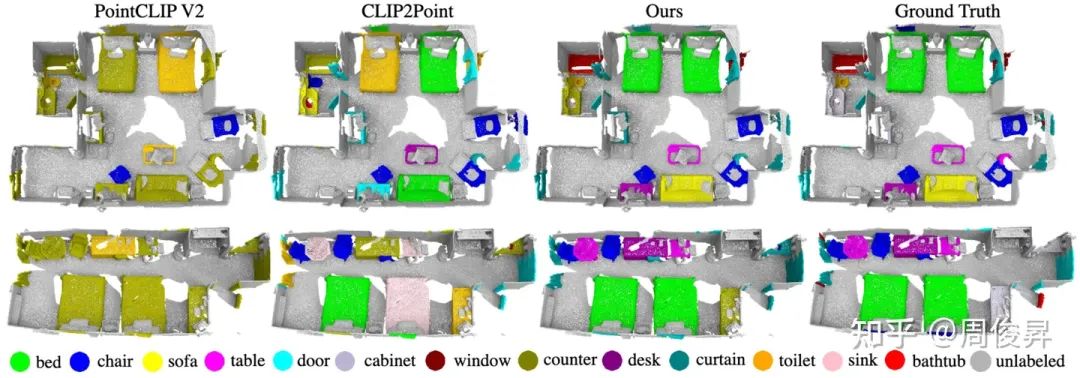
Real-world zero-shot recognition
由于学到了强大的多模态表征能力,Uni3D还能够做一些有意思的应用,如point cloud painting(点云绘画),text/image-based 3D shape retrieval(基于图像/文本的3D模型检索),point cloud captioning(点云描述):

Point cloud painting

Image-based 3D shape retrieval

Text-based 3D shape retrieval

Point cloud captioning.
-
Labview 3D模型2013-08-26 11677
-
Labview中如何导入3D 的模型2014-01-26 21069
-
3d模型问题2015-11-12 3212
-
如何创建3D模型?2019-09-17 2357
-
分享贴片3D模型2019-12-18 3238
-
浩辰3D软件中如何创建槽特征?3D模型设计教程!2020-09-28 1756
-
浩辰3D软件入门教程:如何比较3D模型2020-12-15 2638
-
AD的3D模型绘制功能介绍2021-01-14 4350
-
3D模型的基础介绍2021-01-28 2981
-
浩辰3D的「3D打印」你会用吗?3D打印教程2021-05-27 8356
-
AD软件3D模型2021-12-03 15691
-
3D扫描仪成热点:可生成任意3D模型2013-03-11 6007
-
3D模型2015-11-04 1902
-
PCB 3D模型和PCB 3D模型尺寸资料免费下载2018-11-12 3436
-
探索ICLR‘24 Spotlight中的首个十亿级别3D通用大模型2024-01-25 1382
全部0条评论

快来发表一下你的评论吧 !
