

第二届大会回顾第12期 | ClarifyGPT: 基于交互式需求澄清的大模型代码生成框架
描述
演讲嘉宾 | 石 琳
回顾整理 | 廖 涛
排版校对 | 李萍萍
嘉宾介绍
开发者工具分论坛
石琳,北京航空航天大学软件学院教授,CCF高级会员,2022年度中国科学院软件研究所杰出青年科技人才。研究方向为智能软件工程,包括代码智能、智能需求工程、经验软件工程、开源软件、可信AI等。曾在软件工程、人工智能领域的高水平国际会议发表论文50余篇,三次获得杰出论文奖;主持参与多项国家自然科学基金项目、国家重点研发项目等;担任多个国际知名会议期刊审稿人。
视频回顾
打开哔哩哔哩APP,观看更清晰视频
正文内容
随着AI大模型能力的大幅提升,软件开发已经逐步走向新智能化时代。然而,目前代码大模型在可靠性、隐私和合规以及用户意图识别等方面仍存在一定局限性。如何基于交互式需求澄清方法,让大模型更好地理解用户意图,并给出更准确的答案?北京航空航天大学教授石琳在第二届OpenHarmony技术大会上进行了精彩分享。

2022年11月,OpenAI发布ChatGPT,利用GitHub数据与RLFH强化学习技术,在辅助编程取得进展;2023年1月,微软Copilot平台用户超过1亿,CEO表示Copilot很快就会替代程序员完成80%的代码开发。在GitHub的报告中,使用Copilot的开发者的开发效率几乎提升了一倍,一个用Copilot的初学者就能够像专业程序员一样,从零开始开发出最小可行产品程序。此外,清华大学推出的ChatDev项目,支持多个智能体分工合作,能够根据用户指令生成休闲小游戏、效率管理工具、绘画板、数学计算器、网络爬虫等软件。
通过前文可知,代码大模型在软件开发方面“一鸣惊人”,给开发者们带来了极大的便利。但是,代码大模型的快速发展同时也带来了新的问题,如:
模型问题:可靠性、幻觉、更新、形式重于内容
数据问题:数据演化、质量问题、安全问题、隐私和合规
应用问题:用户意图不明确、复杂问题抽象和分解、项目上下文、领域专业知识、遗留系统维护

其中,用户的意图表述不明确是代码大模型在实践中遇到的巨大阻碍。开发者想写出一个清晰明确且全面的Prompt并不容易。既然开发者写的Prompt不清晰,有没有办法让大模型帮开发者改写?目前,业界已经有一些尝试,例如GPT Engineer。GPT Engineer是一个基于需求描述自动生成项目源码的开源项目,主打轻量,灵活生成项目源码,可以在AI生成与人工生成之间进行切换。在接收到Prompt时,GPT Engineer不会直接生成代码,而是先梳理有哪些事项需要用户进一步澄清,然后让用户把需要澄清的事项输入后,再进一步生成代码。然而,GPT Engineer经常会问一些在Prompt中已经提供了答案的问题,对用户造成困扰。
如何找到Prompt中“不清楚”的地方,从而进行精准提问?石琳教授所在团队提出了ClarifyGPT工具。ClarifyGPT会先识别是否应该提问,再利用大模型生成问题。
ClarifyGPT的模块1:基于测试结果的代码多样性评价模块
如何判断是否应该向用户做Prompt澄清呢?这里我们从代码大模型的输出结果出发,提出一个基本假设:如果Prompt清晰,大模型生成的代码应该行为一致;如果Prompt模糊,大模型生成的代码可能五花八门。因此,ClarifyGPT会先通过种子输入进行代码多样性测试,并基于测试结果判断是否要做向用户做Prompt的澄清。
具体而言,(1)先进行种子测试输入初始化。构建prompt用于生成种子输入,Prompt包含三部分:Instruction,Demonstrations,Query。将Prompt输入LLM中生成一些测试输入,并用它们初始化一个种子池;(2)再进行类型感知的测试输入变异(采用了标准的基于变异的模糊流程)。在每次迭代时,从种子池中随机选择一个输入;对于选定的输入,我们检查其数据类型并执行与其类型一致的单个变异操作以创建新的测试用例;完成一轮突变后,我们将新生成的输入添加到种子池中,并重复上述过程,直到获得所需的生成输入数量。
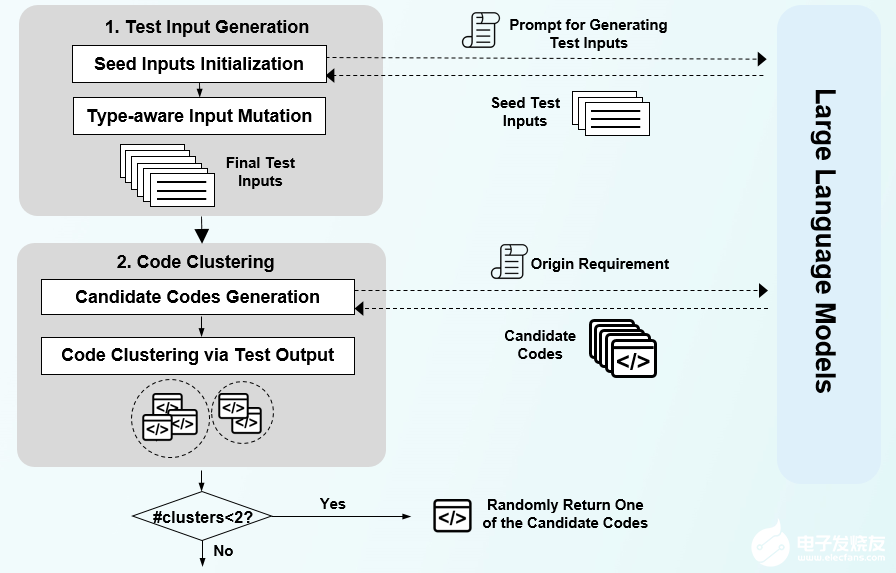
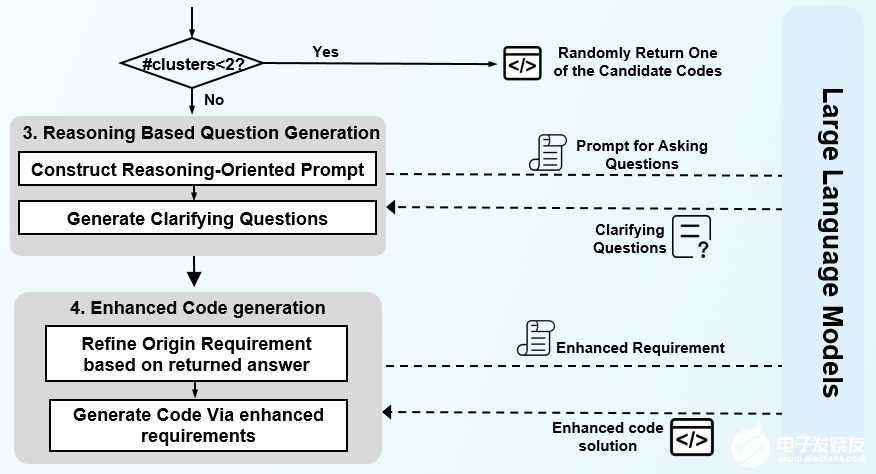
ClarifyGPT的模块2:基于推理的LLM问题生成模块
在确定了需要向用户做Prompt澄清后,应该问什么内容呢?为了解决这个以问题,ClarifyGPT会进一步分析代码的细节差异,区分不一致的代码,比较solution的不同点,再基于推理进行LLM问题生成。
具体而言,首先生成中间推理步骤(分析导致歧义的因素),然后基于这些中间推理步骤产生最终结果(有针对性的澄清问题)。此外,ClarifyGPT鼓励LLM进行“超前规划”,使他们能够更好地利用他们的推理和理解能力来提高生成问题的质量。
经过评测,ClarifyGPT将GPT-4在MBPP-sanitized上的表现(Pass@1)从70.96%提高到80.8%;将MBPP-ET的性能从51.52%提高到60.19%。相对改善平均为15.35%,优于基线。且增加Prompt中示例的数量会带来ClarifyGPT性能提升。
ClarifyGPT是一个交互式代码生成框架,会引导用户先澄清意图,再利用大模型帮助用户生成代码。后续,ClarifyGPT也会在其他生成类任务上进行进一步的研究和探索。
大模型加速了研发人员的工作效率,但同时也提出了新的挑战。我们必须大胆尝试LLM在改进软件开发方面的潜力,但同时也要谨慎行事,不要忘记工程思维、严谨性和经验验证的基本原则。 【材料分享】 [1] 论文原文下载 http://arxiv.org/abs/2310.10996 [2] 开源原型工具 https://github.com/ClarifyGPT/ClarifyGPT (点击阅读原文可跳转)
E N D
关注我们,获取更多精彩。
审核编辑 黄宇
- 相关推荐
- 热点推荐
- AI
- 代码
- OpenHarmony
- 大模型
-
第二届大会回顾第24期 | 面向OpenHarmony的软件工程研究:机遇与挑战2024-08-07 2381
-
报名开启!第二届OpenHarmony开发者大会2024重磅来袭!2024-05-14 2547
-
实地探展 | 别样视角一站式感受第二届OpenHarmony技术大会2023-11-14 766
-
大咖金句 | 第二届OpenHarmony技术大会演讲集锦2023-11-06 1002
-
高能有料 | 第二届OpenHarmony技术大会议程速递2023-11-01 869
-
亮点剧透 | 第二届开放原子开源基金会 OpenHarmony技术大会精彩来袭2023-10-27 1098
-
Imagination出席第二届国际人机交互大会,展示汽车人机交互前沿技术2019-04-25 3850
-
第二届宝安产业发展博览会2017-07-13 2261
-
第二届“114论坛”渐近,东莞“智能制造”气息愈发浓烈2016-11-01 4479
-
第二届中国IOT大会全程精彩回顾2016-01-04 40
-
西安邮电大学2014年通院第二届电子设计题目2015-08-07 3647
-
【PCB设计】电子发烧友第二届PCB Layout大赛 Tmike 作品2014-11-24 3761
-
【PCB设计】电子发烧友第二届PCB Layout大赛2014-10-31 35130
全部0条评论

快来发表一下你的评论吧 !
