

未来十年:逻辑电路的发展趋势与前景展望
描述
到2034年高密度逻辑晶体管密度将从今天的283MTx/mm2增加到757MTx/mm2。 在 2024 年 SEMI 国际战略研讨会上,笔者从技术、经济和可持续发展的角度审视十年后逻辑电路将走向何方。 为了理解逻辑电路,笔者相信了解前沿逻辑器件的构成是有用的。TechInsights 提供了详细的封装分析报告,笔者为 10 种 7 纳米和 5 纳米级设备做了报告,包括英特尔和 AMD 微处理器、苹果A系列和M系列处理器,NVIDIA GPU和其他设备。图 1 说明了芯片区域的构成。
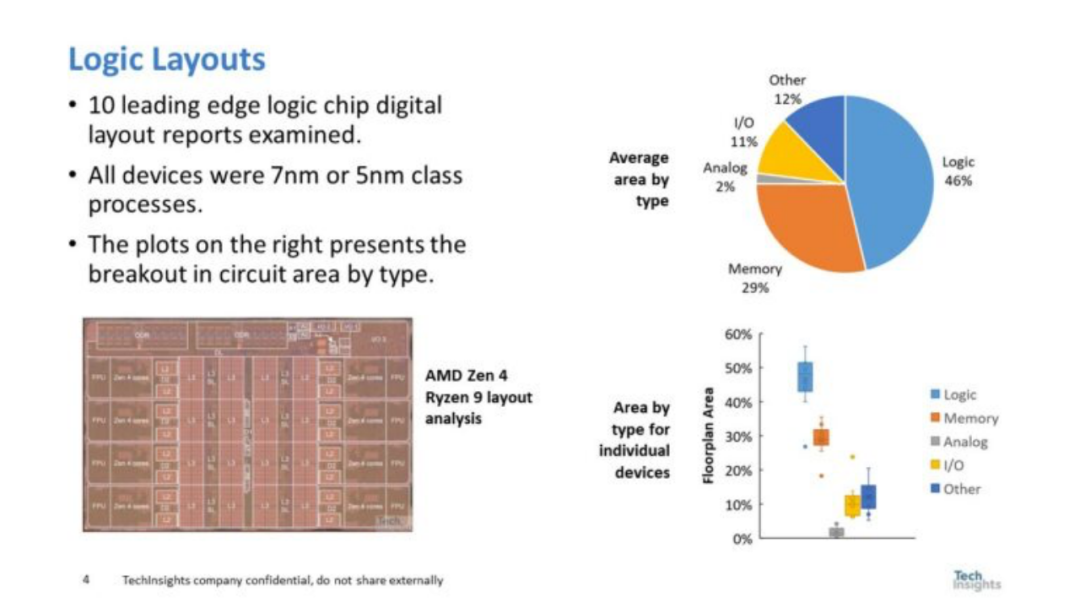
图 1. 逻辑布局
从图 1 中可以看出,逻辑部分占芯片面积略小于二分之一,内存部分略小于芯片面积的三分之一,而 I/O、模拟和其他部分则占平衡。有趣的是,实际测量的 SRAM 内存面积比笔者通常听到人们谈论的片上系统 (SOC) 产品的百分比要小得多。 单一逻辑几乎占据了芯片面积的一半,所以从逻辑部分开始设计是有意义的。逻辑设计是使用标准单元完成的,图 2 是标准单元的平面图。
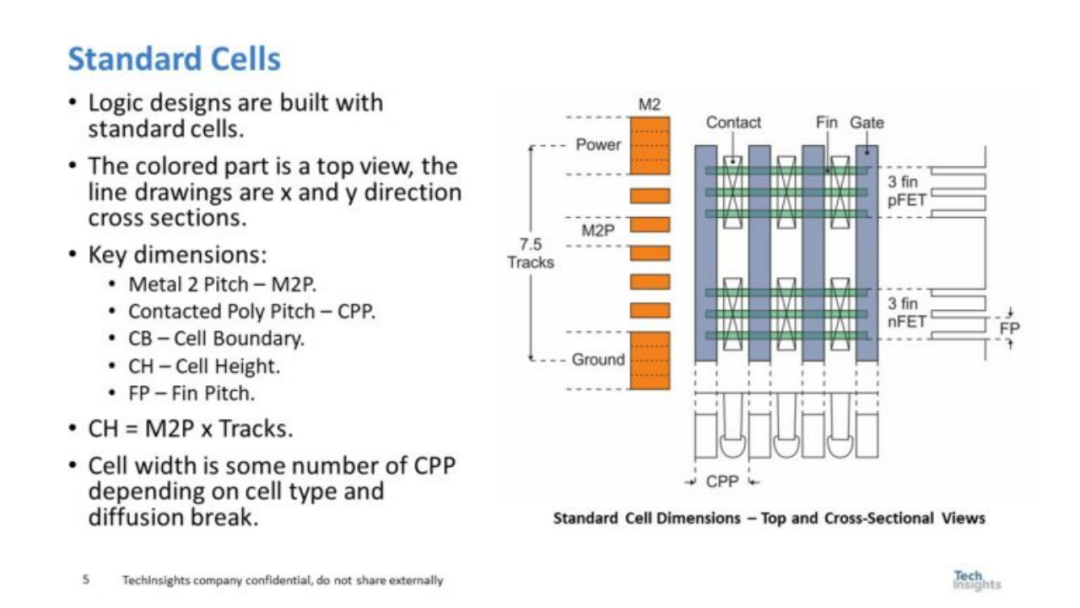
图 2. 标准单元
标准单元的高度通常被描述为Metal 2 Pitch(M2P)乘以磁道数,但从图的右侧看,器件结构的横截面图也必须与单元高度相匹配并受到设备物理的限制。依赖于接触多晶硅间距(CPP)的单元宽度也是如此,并且在图的底部可以看到再次受到物理约束的器件结构的横截面视图。 图 3 显示了确定单元宽度和单元高度缩放实际限制的分析结果。笔者有一个演示文稿详细介绍了缩放限制,在该演示文稿中,图 2 和图 3 之间有数十张幻灯片,但由于时间有限,笔者只能展示结论。

图 3. 逻辑单元缩放
单元宽度缩放取决于 CPP,图的左侧说明了 CPP 如何由栅极长度 (Lg)、接触宽度 (Wc) 和两个接触到栅极间隔物厚度 (Tsp) 组成。Lg 受泄漏限制,可接受泄漏的最小 Lg 取决于器件类型。具有控制无约束厚度沟道表面的单栅的平面器件被限制在大约30 nm。Fin FET和水平纳米片(HNS)约束沟道厚度(~5nm),分别有3个和4个栅极。最后,二维材料引入小于 1nm 沟道厚度的非硅材料,并且可以生产低至约 5 nm 的 Lg。由于寄生效应,Wc 和 Tsp 的扩展能力都有限。最重要的是,2D 器件可能会产生约 30 纳米的 CPP,而当今的 CPP 约为 50 纳米。 图的右侧示出了单元高度缩放。HNS提供单纳米片叠层代替多个鳍片。然后演变到具有CFET的堆叠器件消除了水平n-p间距,并堆叠nFet和pFET。目前150nm至200nm的电池高度可降低至约50nm。 CPP 和单元高度缩放的结合可以产生每平方毫米约 15 亿个晶体管 (MTx/mm2) 的晶体管密度,而当今的晶体管密度<300MTx/mm2。应该指出的是,2D 材料可能是 2030 年中后期的技术,因此 1,500 MTx/mm2不在此处讨论的时间范围内。
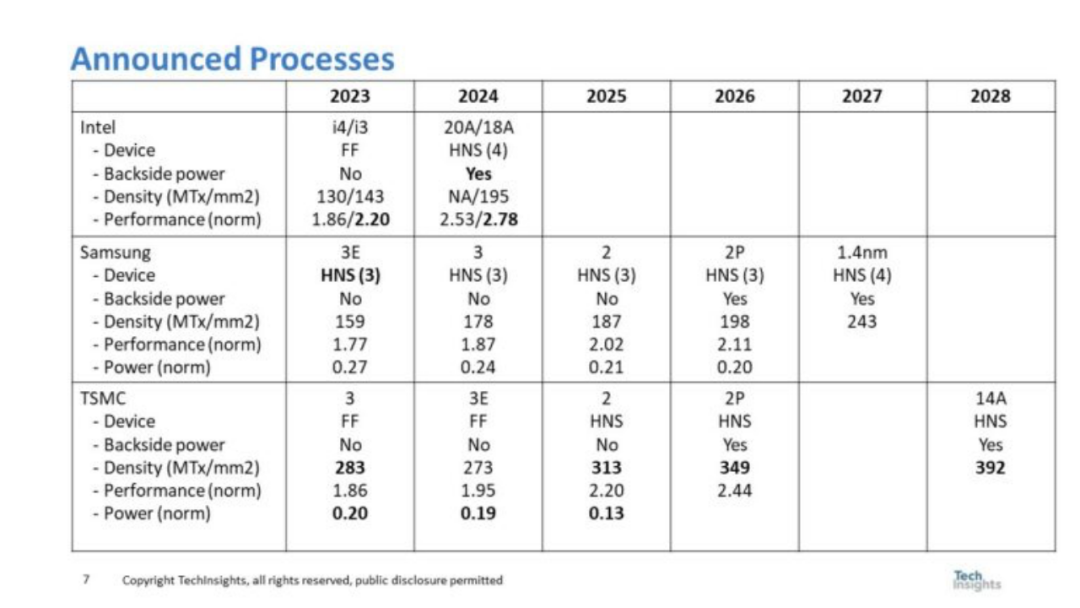
图 4. 三大巨头公布的流程
图 4 总结了英特尔、三星和台积电宣布的工艺进程。对于每个公司和年份,都会显示设备类型、是否使用背面电源、密度、功率和性能(如果有)。 在图 4 中,领先的性能和技术创新以粗体突出显示。三星是第一个在2023年投产HNS的公司,而英特尔直到2024年才会推出HNS,台积电直到2025年才会推出。英特尔是第一个在2024年将背面电源引入生产的公司,三星和台积电要到2026年才会引入背面电源。 笔者的分析得出结论,英特尔是i3的性能领先者,并维持这一状态所示期间,台积电有功率领先(英特尔数据不可用)和密度领先。
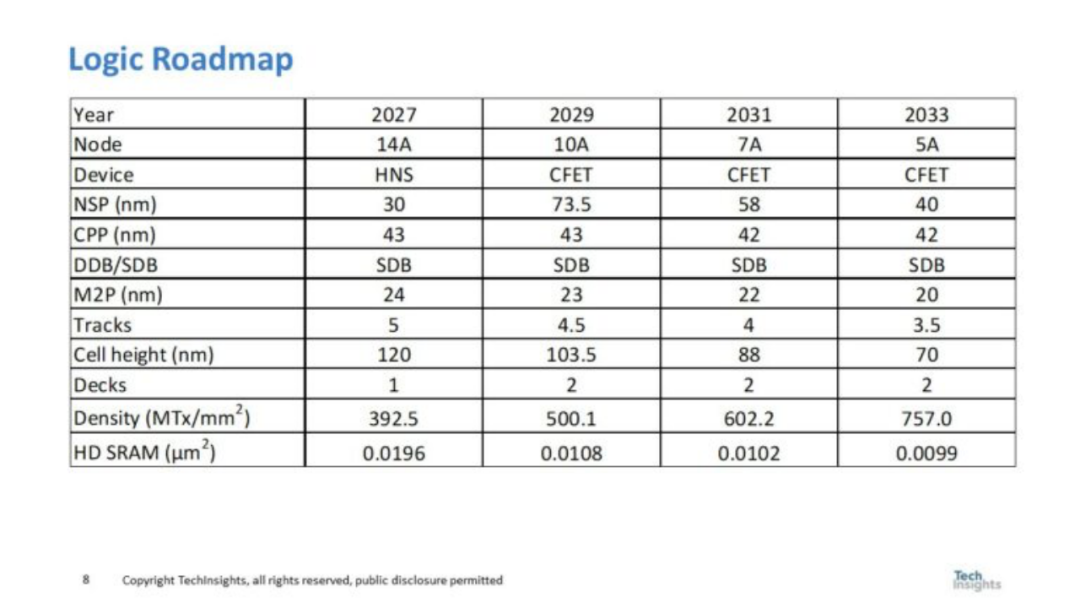
图 5. 逻辑路线图
图 5 展示了逻辑路线图,并包括预计的 SRAM 单元尺寸。从图 5 中,笔者预计 CFET 将在 2029 年左右推出,从而提高逻辑密度,并将 SRAM 单元尺寸缩小近一半(SRAM单元尺寸的缩放几乎停止在前沿)。笔者预计到 2034 年逻辑密度将达到757MTx/mm2。 逻辑晶体管密度预测和 SRAM 晶体管密度预测如图 6 所示。
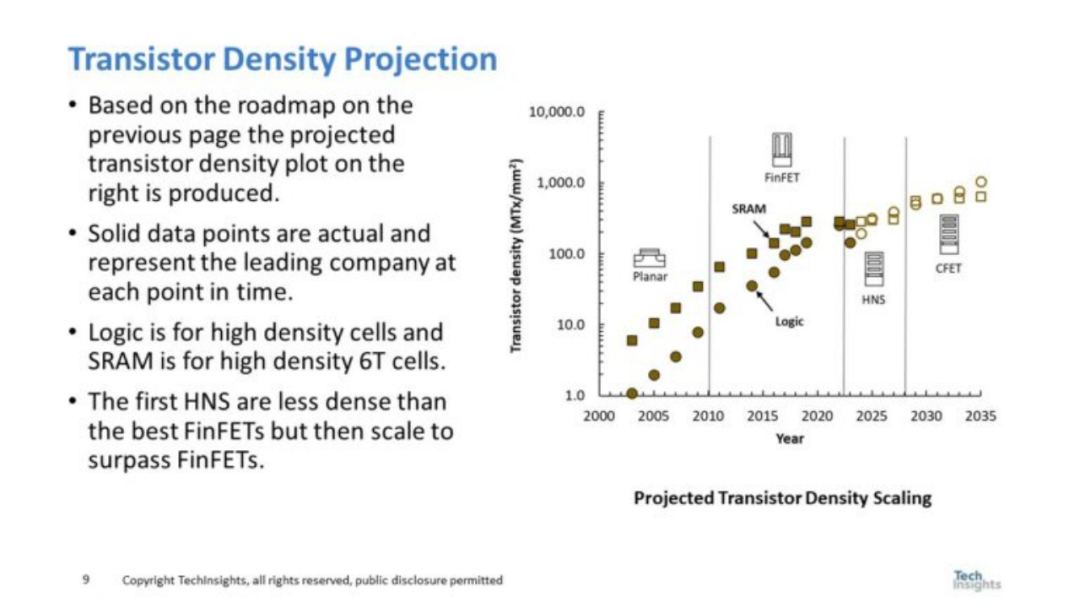
图 6. 晶体管密度预测
逻辑和SRAM的晶体管密度缩放都在变慢,但更大程度上SRAM和逻辑现在具有相似的晶体管密度。 图7 总结了台积电逻辑和 SRAM 相比的模拟缩放数据。模拟和 I/O 缩放也都比逻辑缩放慢。
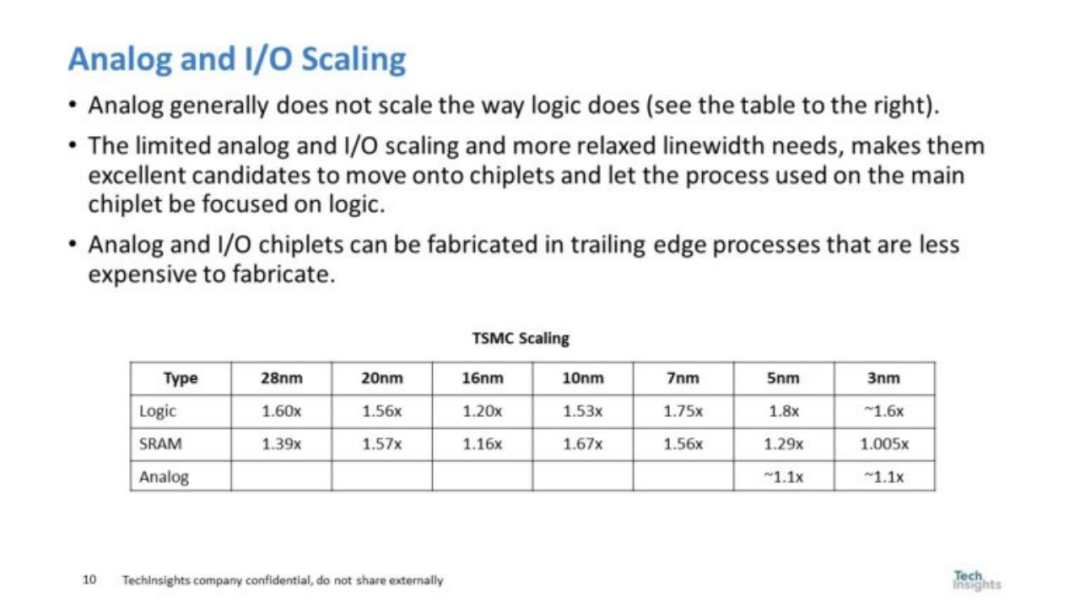
图 7. 模拟和 I/O 缩放
对于较慢的 SRAM 以及模拟和 I/O 扩展,一个可能的解决方案是小芯片。小芯片可以实现更便宜、更优化的工艺来制造 SRAM 和 I/O。
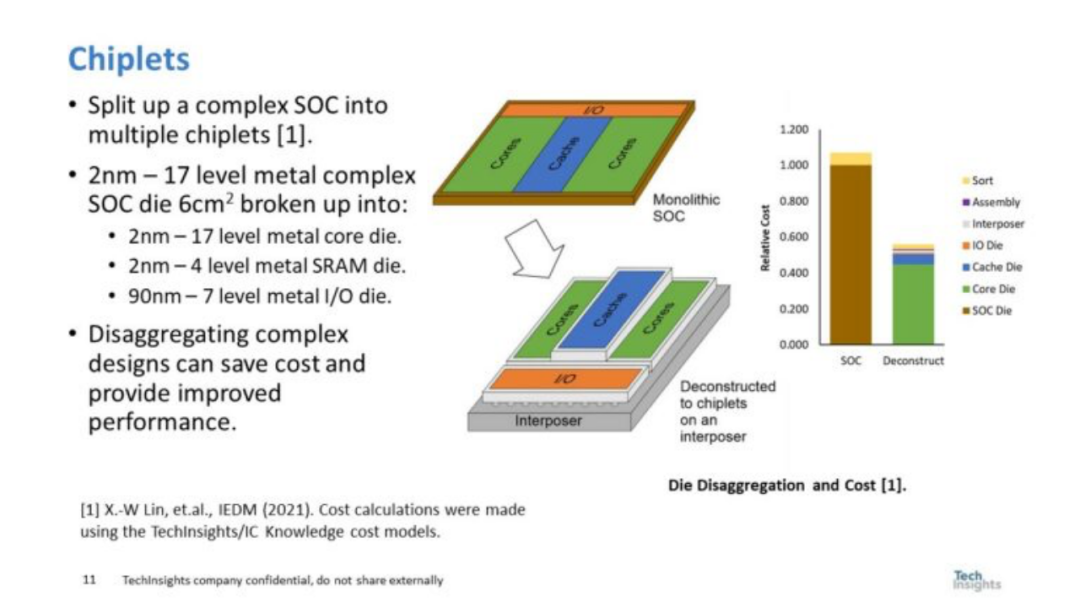
图 8. 小芯片
图8右侧的图形来自2021年我与Synopsys合作撰写的一篇论文。我们的结论是,即使考虑到增加的封装/组装成本,将大型SOC分解成小芯片也可以将成本降低一半。
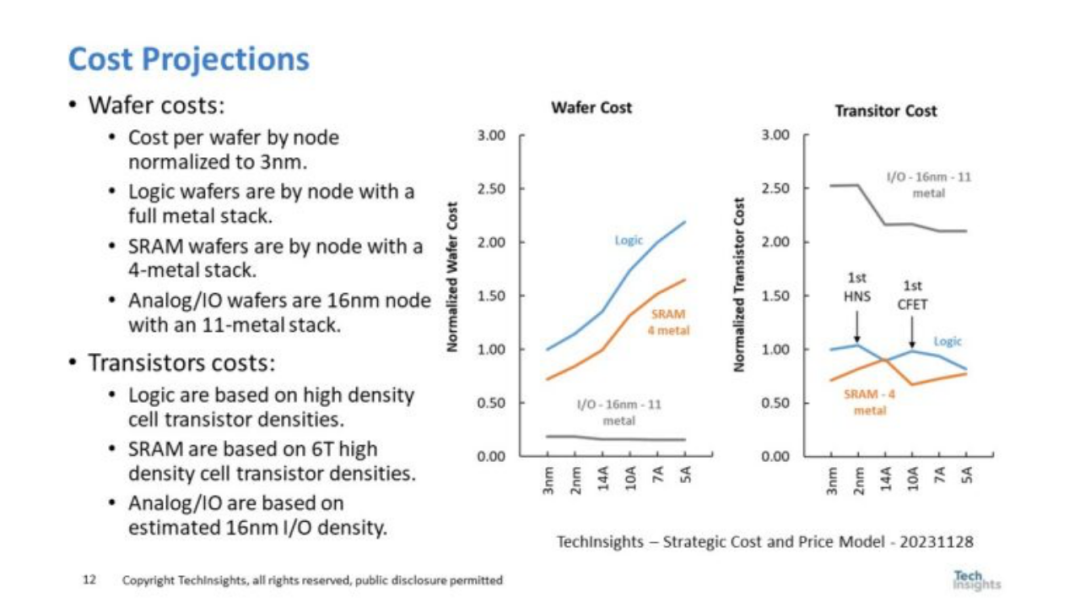
图 9. 成本预测
图 9 显示了逻辑、SRAM 和 I/O 的标准化晶圆和晶体管成本。右图显示了标准化晶圆成本。逻辑晶圆成本针对金属层数量不断增加的全金属堆栈。SRAM 晶圆具有相同的节点,但由于 SRAM 的布局更为规则,因此仅限于 4 个金属层。I/O晶圆成本基于16nm-11金属工艺。笔者选择 16nm 来获得成本最低的 FinFET 节点,以确保足够的 I/O 性能。 右图是晶圆成本换算成晶体管成本。有趣的是,I/O 晶体管非常大,即使在低成本 16nm 晶圆上,它们的成本也是最高的(I/O 晶体管尺寸基于 TechInsights 对实际 I/O 晶体管的测量)。 逻辑晶体管成本在 2nm 处上升,这是第一个台积电 HNS 片节点,其收缩幅度不大。我们预计第二代 HNS 节点在 14A 时的收缩会更大((这与台积电第一个FinFET节点类似)。同样,第一个CFET节点的成本也增加了一个节点的晶体管成本。除了一次性 CFET 缩小之外,由于缩小有限,SRAM 晶体管成本呈上升趋势。该分析的底线是,尽管 Chiplet 可以提供一次性的好处,但晶体管成本的降低幅度将会不大。

图10 结论
总之,笔者预测,到2034年高密度逻辑晶体管密度将从今天的283MTx/mm2增加到757MTx/mm2。由于CFET的变化,SRAM单元尺寸将从今天的0.0209um2缩小到0.0099um2。逻辑晶体管成本将降至0.82x,SRAM将增加到1.09x,L/0将增加到目前成本的0.83倍。
芯片巨头们已着手研发下一代CFET技术 英特尔(Intel) 和台积电将在国际电子元件会议(IEDM) 公布垂直堆叠式(CFET) 场效晶体管进展,使CFET 成为十年内最可能接替闸极全环电晶(GAA ) 晶体管的下一代先进制程。 英特尔的 GAA 设计堆叠式 CFET 晶体管架构是在 imec 的帮助下开发的,设计旨在增加晶体管密度,通过将 n 和 p 两种 MOS 器件相互堆叠在一起,并允许堆叠 8 个纳米片(RibbonFET 使用的 4 个纳米片的两倍)来实现更高的密度。目前,英特尔正在研究两种类型的 CFET,包括单片式和顺序式,但尚未确定最终采用哪一种,或者是否还会有其他类型的设计出现,未来应该会有更多细节信息公布。
此前在 2021 年的“英特尔加速创新:制程工艺和封装技术线上发布会”上,英特尔已经确认了 RibbonFET 将成历史,在其 20A 工艺上,将引入采用 Gate All Around(GAA)设计的 RibbonFET 晶体管架构,以取代自 2011 年推出的 FinFET 晶体管架构。新技术将加快了晶体管开关速度,同时实现与多鳍结构相同的驱动电流,但占用的空间更小。 虽然,大多数早期研究以学术界为主,但英特尔和台积电等半导体企业现在已经开始这一领域的研发,借此积极探索这种下一代先进晶体管技术。
审核编辑:黄飞
-
变阻器的未来发展趋势和前景如何?是否有替代品出现?2024-10-10 4318
-
DC电源模块的发展趋势和前景展望2024-04-18 1667
-
未来十年显示技术发展趋势2023-09-11 2958
-
消费升级下摩托车TBOX市场未来十年CAN数据应用发展趋势展望2022-09-01 6049
-
未来PLC的发展趋势将会如何?2021-07-05 3677
-
蜂窝手机音频架构的未来发展趋势是什么2021-06-08 2478
-
自动化测试技术发展趋势展望分析,不看肯定后悔2021-05-14 2612
-
电源模块的未来发展趋势如何2021-03-11 3167
-
展望未来十年 信通院发布ICT深度观察十大趋势2020-12-24 2816
-
灵动微对于未来MCU发展趋势分析2020-12-23 2381
-
盾构未来发展趋势和展望2020-11-03 1601
-
蓝牙技术未来的发展趋势2019-03-29 4045
-
您看好电动汽车的未来发展趋势吗?2017-04-26 7597
-
开关电源发展趋势及发展前景2016-03-20 4415
全部0条评论

快来发表一下你的评论吧 !
