

AI视频年大爆发!2023年AI视频生成领域的现状全盘点
描述
2023年,也是AI视频元年。过去一年究竟有哪些爆款应用诞生,未来视频生成领域面临的难题还有哪些?
过去一年,AI视频领域我们见证了,Gen-2、Pika等爆款产品的诞生。
来自a16z的Justine Moore,详细盘点了人工智能视频生成领域的现状、不同模型比较,以及还未解决的技术挑战。
接下来,一起看看这篇文章都讲了什么?
AI视频生成大爆发
2023年是AI视频取得突破的一年。不过,今年过去了一个月,暂未有公开的文本到视频的模型。
短短12个月,数十种视频生成产品受到了全球数以万计的用户的青睐。
不过,这些AI视频生成工具仍相对有限,多数只能生成3-4秒的视频,同时质量往往参差不齐,角色一致性等问题尚未解决。
也就是说,我们还远不能制作出一个只有文字提示,甚至多个提示的皮克斯级别的短片。
然而,我们在过去一年中在视频生成方面取得的进步表明,世界正处于一场大规模变革的早期阶段——与我们在图像生成方面看到的情况类似。
我们看到,文本到视频的模型在不断改进,图像到视频,以及视频到视频等分支也在蓬勃发展。
为了帮助了解这一创新的爆炸式增长,a16z追踪了到目前为止最需要关注的公司,以及该领域仍然存在的潜在问题。
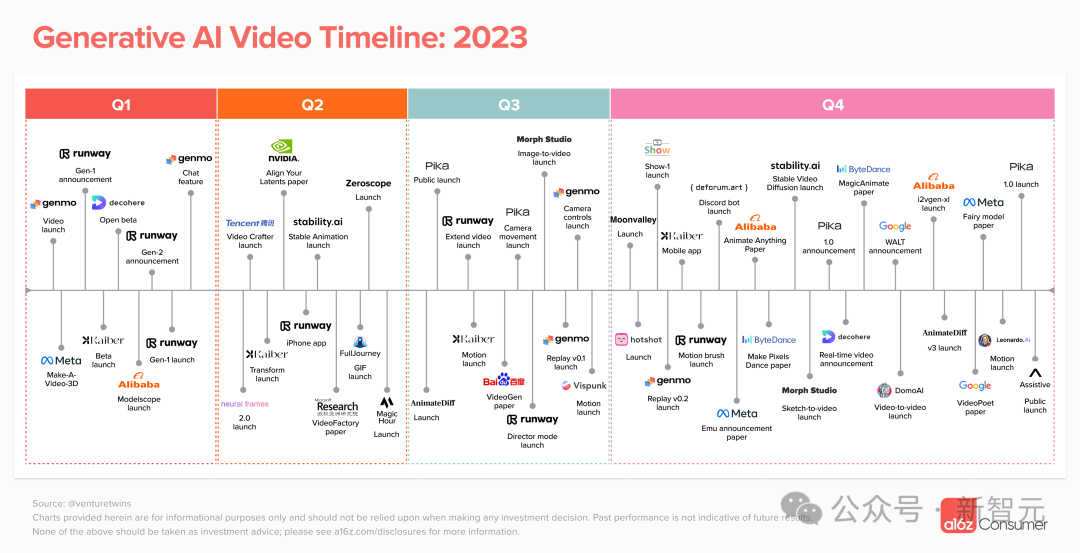
今天,你可以在哪里生成AI视频?
21个视频生成产品
今年到目前为止,a16z已经跟踪了21种公开产品。
虽然你可能听说过Runway、Pika、Genmo和Stable Video Diffusion,但还有许多其他的东西需要探索。
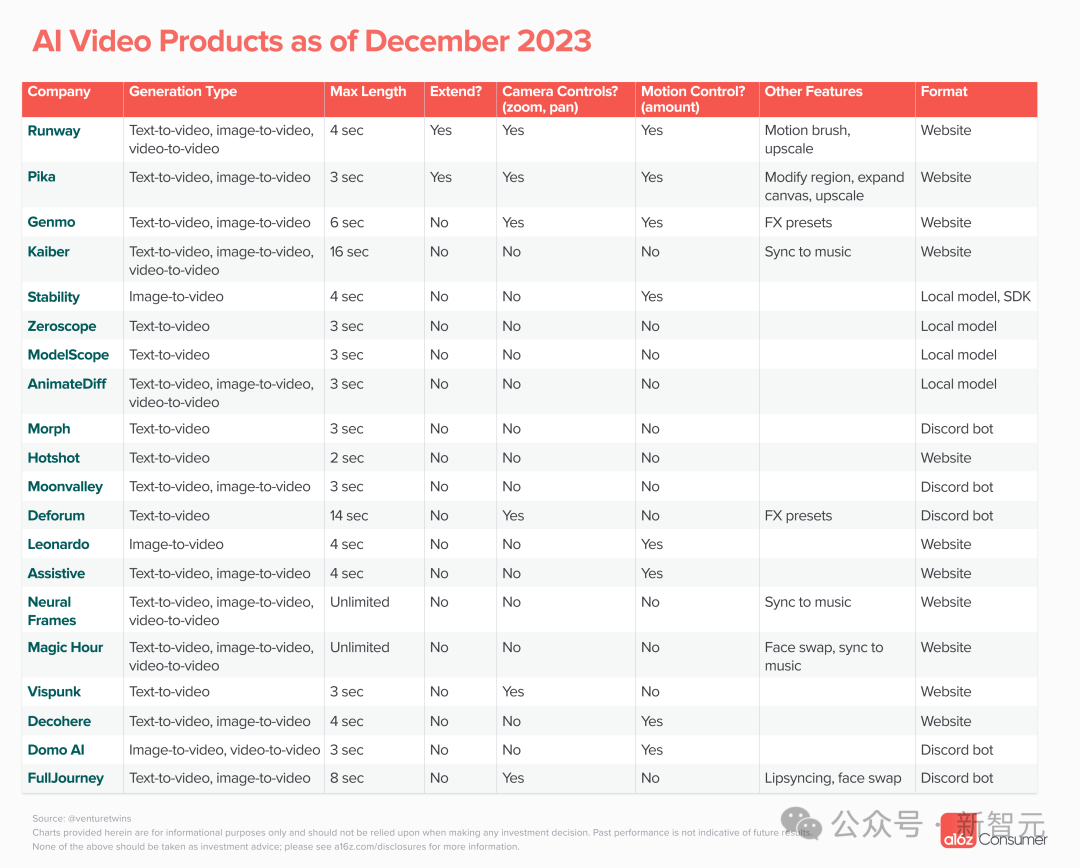
这些产品大多来自初创公司,其中许多都是从Discord bots,有以下几个优势:
不需要构建自己面向消费者的界面,只需专注于模型质量
可以利用Discord每月1.5亿活跃用户的基础进行分发
公共渠道为新用户提供了一种简便的方式,让他们获得创作灵感(通过查看他人的创作)
然而,随着技术成熟,我们开始看到越来越多的AI视频产品建立自己的网站,甚至是App。
随着Discord提供了一个很好的平台,但在纯生成之上添加的工作流而言,却是有限的,并且团队对消费者体验的控制很少。
值得注意的是,还有很大一部分人不使用Discord,因其觉得界面混乱让人困惑。
研究和技术
谷歌、Meta和其他公司在哪里?
在公开的产品列表中,他们显然没有出现--尽管你可能已经看到了他们发布的关于Emu Video、VideoPoet 和 Lumiere等模型的帖子。
到目前为止,大型科技公司基本上都不选择公开自家的AI视频产品。
取而代之的是,他们发表了各种相关的视频生成的论文,而没有选择视频演示。
比如,谷歌文本生成视频的模型Lumiere

这些公司有着巨大的分销优势,其产品拥有数十亿用户。
那么,他们为什么不放弃发布视频模型,而在这一新兴类别市场中夺取巨大份额。
最主要的原因还是,法律、安全和版权方面的担忧,往往使这些大公司很难将研究转化为产品,并推迟推出。如此一来,让新来者有机会获得先发优势。
AI视频的下一步是什么?
如果你曾使用过这些产品,便知道在AI视频进入主流产品之前,仍然有很大的改进空间。
有时会发现,AI视频工具可以将提示内容生成视频的「神奇时刻」,但这种情况相对较少见。更常见的情况是,你需要点击几次重新生成,然后裁剪或编辑输出,才能获得专业级别的片段。
这一领域的大多数公司都专注于解决一些核心的问题:
控制性:你能否同时控制场景中发生的事情,(比如,提示「有人向前走」,动作是否如描述的那样?)关于后一点,许多产品都增加了一些功能,允许你对镜头zoom或pan,甚至添加特效。
「动作是否如描述的那样」一直较难解决:这涉及到底层模型的质量问题(模型是否理解提示的含义并能按要求生成),尽管一些公司正在努力在生成前提供更多的用户控制。
比如,Runway的motion brush就是一个很好的例子,它允许用户高粱图像的特定区域并确定其运动方式。
时间一致性:如何让角色、对象和背景在帧之间保持一致,而不会变形为其他东西或扭曲?
在所有公开提供的模型中,这是一个非常常见的问题。
如果你今天看到一段时间连贯的视频,时长超过几秒,很可能是视频到视频,通过拍摄一段视频,然后用AnimateDiff prompt travel之类的工具来改变风格。
长度——制作长时间的短片与时间连贯性高度相关。
许多公司会限制生成视频的长度,因为他们不能确保几分钟后依然视频保持一致性。
如果当你看到一个超长的AI视频,要知道它们是由一堆短片段组成的。
尚未解决的问题
视频的ChatGPT时刻什么时候到来?
其实我们还有很长的路要走,需要回答以下几个问题:
1 当前的扩散架构是否适用于视频?
今天的视频模型是基于扩散模型搭建的:它们基本原理是生成帧,并试图在它们之间创建时间一致的动画(有多种策略可以做到这一点)。
他们对3D空间和对象应该如何交互没有内在的理解,这解释了warping / morphing。
2 优质训练数据从何而来?
与其他模态模型相比,训练视频模型更难,这主要是因为视频模型没有那么多高质量的训练数据可供学习。语言模型通常在公共数据集(如Common Crawl)上进行训练,而图像模型则在LAION和ImageNet等标记数据集(文本-图像对)上进行训练。
视频数据更难获得。虽然在YouTube和TikTok等平台上不乏公开可访问的视频,但这些视频没有标签,也不够多样化。
3 这些用例将如何在平台/模型之间进行细分?
我们在几乎每一种内容模态中看到的是,一种模型并不是对所有用例都「取胜」的。例如,MidTrik、Idegraph和Dall-E都有不同的风格,并擅长生成不同类型的图像。
如果你测试一下今天的文本到视频和图像到视频模式,就会发现它们擅长不同的风格、运动类型和场景构成。
谁将主导视频制作的工作流程?
而在许多产品之间,来回是没有意义的。
除了纯粹的视频生成,制作好的剪辑或电影通常需要编辑,特别是在当前的范例中,许多创作者正在使用视频模型来制作在另一个平台上创建的照片的动画。
从Midjourney的图像开始,在Runway或Pika上制作动画,然后在Topz上进行升级的视频并不少见。
然后,创作者将视频带到CapCut或Kapwing等编辑平台,并添加配乐和画外音,通常是在Suno和ElevenLabs等其他产品上生成的。
审核编辑:刘清
-
NVIDIA和ComfyUI携手简化本地AI视频生成工作流2026-03-14 2716
-
《AI Agent 应用与项目实战》----- 学习如何开发视频应用2025-03-05 2103
-
OpenAI推出AI视频生成模型Sora2024-12-12 1524
-
字节跳动自研视频生成模型Seaweed开放2024-11-11 1391
-
火山引擎推出豆包·视频生成模型2024-09-25 1203
-
MediaTek联合快手推出高效端侧视频生成技术2024-07-05 15330
-
阿里云视频生成技术创新!视频生成使用了哪些AI技术和算法2024-05-08 5077
-
新火种AI|围攻光明顶:Sora效应下的AI视频生成竞赛2024-03-16 1362
-
除了刷屏的Sora,国内外还有哪些AI视频生成工具2024-02-26 7435
-
OpenAI 在 AI 生成视频领域扔出一枚“王炸”,视频生成模型“Sora”2024-02-22 1111
-
openai发布首个视频生成模型sora2024-02-21 2387
-
OpenAI新年开出王炸,视频生成模型Sora问世2024-02-20 1524
-
OpenAI发布文生视频模型Sora,引领AI视频生成新纪元2024-02-19 1991
-
深圳云栖大会人工智能专场:探索视频+AI,玩转智能视频应用2018-03-30 4889
全部0条评论

快来发表一下你的评论吧 !
