

Versal FPGA中的浮点计算单元DSPFP32介绍
描述
Versal FPGA中最新的DSP原语DSP58,它在最新的DSP48版本上已经有了许多改进,主要是从27x18有符号乘法器和48位后加法器增加到了27x24和58位。但除此之外,DSP58还有两种额外的操作模式,分别称为DSPCPLX和DSPFP32。本文将重点介绍其中的DSPFP32,它是一个硬化的浮点加法器和乘法器。
DSPFP32包括一个单精度浮点加法器和乘法器。它们可以独立使用,也可以组合为乘累加操作。
下图展示了DSPFP32的内部架构:
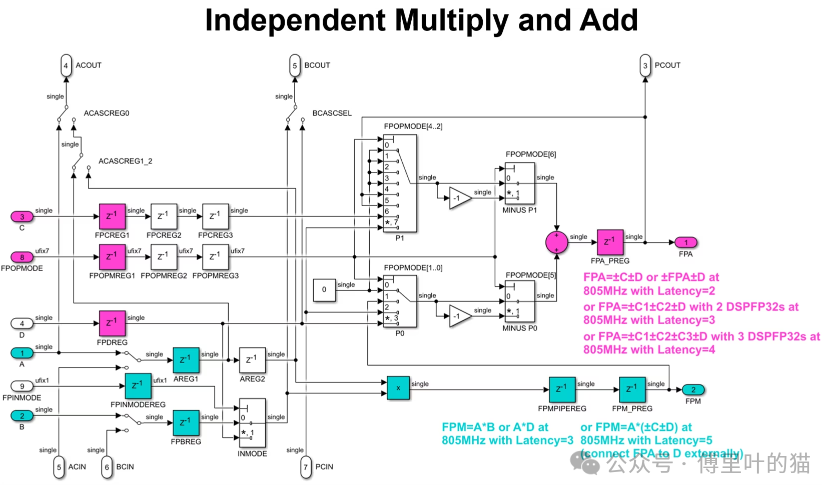
DSPFP32在某种程度上类似于DSP58,真正的区别,除了使用单精度浮点数而不是定点数之外,还有两个输出FPA和FPM,而不仅仅是后加法器P端口,以及没有预加法器。这个图展示了FP32加法器和乘法器独立使用,颜色高亮表示实现805MHz最大可能速度所需的最小流水线数量。你基本上在每个DSP58中得到一个延迟为2的FP32加法器和一个延迟为3的乘法器。加法器的两个输入操作数的符号可以选择性地反转,这些操作数有多种选择,包括ZERO、C、D和PCIN输入,以及FPA输出本身,可以用来构建累加器。
PCIN/PCOUT级联链允许你级联多个DSPFP32加法器,构建超过两项的求和。如果你使用fabric routing将FPA输出外部连接到B输入,你可以在5个时钟周期的延迟下计算类似FPM=A*(C+D)的东西。 第二张图显示了FP32乘法器和加法器内部连接为MAC,因此可以在4个时钟周期的延迟下计算FPA=C+AB或FPA=FPA+AB。C和FPOPMODE输入路径中的可选额外流水线寄存器可用于补偿乘法器路径的额外延迟,以便整个MAC对所有数据输入的总延迟为4个时钟周期。
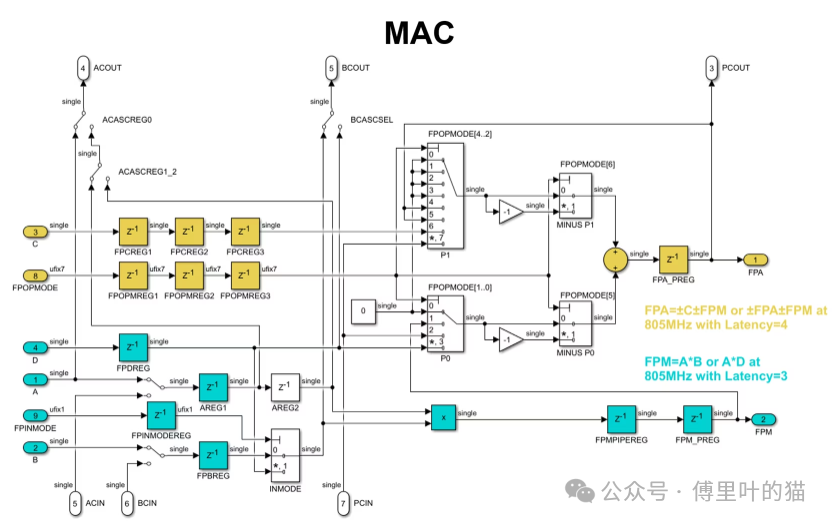
虽然这些图中没有显示,但FPA和FPM都可以路由到PCOUT端口,因此使用P级联输出从相邻的DSP借用一个乘法器,你也可以在四个时钟周期的延迟内计算FPA=C+A1B1+A2B2,因此可以用4个DSPFP32和没有其他fabric资源构建一个完整的复数乘法器加一个复数加法器。
在早期的FPGA系列中,浮点设计总是可能的,Xilinx多年来一直提供基于fabric的软浮点IP,但硬化的DSPFP32现在提供了使用单个DSP58原语和几乎没有fabric资源的选项,具有更低的延迟(3-4个时钟周期而不是8-11个),更低的功耗和高达805MHz的时钟速度,在最快的两个速度等级中。
审核编辑:刘清
-
DS1302介绍2021-07-19 1948
-
EFR32介绍2021-07-23 2464
-
ISO14443介绍2021-07-27 1989
-
FDC2214介绍2021-08-12 3253
-
LCD1602介绍2022-03-01 2427
-
STM32F4浮点单元介绍2023-09-12 517
-
温度传感器 LM35介绍2009-12-02 30350
-
功率计量芯片HLW8012介绍及应用2015-11-20 3490
-
CP5612介绍安装调试驱动说明2016-06-08 2610
-
MultiSIM9介绍和虚拟仪器使用2017-03-28 1295
-
浮点运算单元的FPGA实现2018-04-10 1606
-
IAR for STM8介绍、 下载、安装与注册2020-03-20 7156
-
如何在FPGA上实现复数浮点的计算2020-12-22 727
-
STM32U5介绍2023-09-19 906
-
M7介绍_202106152021-08-31 732
全部0条评论

快来发表一下你的评论吧 !
