

基于Transformer模型的压缩方法
描述
0. 这篇文章干了啥?
基于Transformer的模型已经成为各个领域的主流选择,包括自然语言处理(NLP)和计算机视觉(CV)领域。大部分拥有数十亿参数的大型模型都基于Transformer架构,但其异常庞大的规模给实际开发带来了挑战。例如,GPT-3模型有1750亿个参数,需要约350GB的存储空间(float16)。参数的数量庞大以及相关的计算开销要求设备具有极高的存储和计算能力。直接部署这样的模型会产生巨大的资源成本,特别是在手机这样的边缘设备上的模型部署变得不切实际。
模型压缩是减少Transformer模型开发成本的有效策略,包括修剪、量化、知识蒸馏、高效架构设计等各种类别。网络修剪直接删除冗余组件,如块、注意力头、FFN层或个别参数。通过采用不同的修剪粒度和修剪标准,可以派生出不同的子模型。量化通过用较低位表示模型权重和中间特征来减少开发成本。例如,当将一个全精度模型(float32)量化为8位整数时,存储成本可以减少四分之一。根据计算过程,可以分为后训练量化(PTQ)或量化感知训练(QAT),其中前者只产生有限的训练成本,对于大型模型更有效。知识蒸馏作为一种训练策略,将知识从大模型(教师)转移到较小模型(学生)。学生通过模拟模型的输出和中间特征来模仿教师的行为。还可以直接降低注意力模块或FFN模块的计算复杂性来产生高效的架构。
因此,这篇文章全面调查了如何压缩Transformer模型,并根据量化、知识蒸馏、修剪、高效架构设计等对方法进行分类。在每个类别中,分别研究了NLP和CV领域的压缩方法。
下面一起来阅读一下这项工作~
作者:Yehui Tang, Yunhe Wang, Jianyuan Guo, Zhijun Tu, Kai Han, Hailin Hu, Dacheng Tao
2. 摘要
基于Transformer架构的大型模型在人工智能领域中发挥着日益重要的作用,特别是在自然语言处理(NLP)和计算机视觉(CV)领域。模型压缩方法降低了它们的内存和计算成本,这是在实际设备上实现Transformer模型的必要步骤。鉴于Transformer的独特架构,具有替代注意力和前馈神经网络(FFN)模块,需要特定的压缩技术。这些压缩方法的效率也至关重要,因为通常不现实在整个训练数据集上重新训练大型模型。这项调查全面审查了最近的压缩方法,重点关注它们在Transformer模型中的应用。压缩方法主要分为剪枝、量化、知识蒸馏和高效架构设计。在每个类别中,我们讨论了CV和NLP任务的压缩方法,突出了共同的基本原理。最后,我们深入探讨了各种压缩方法之间的关系,并讨论了该领域的进一步发展方向。
3. 压缩方法总结
Transformer模型的代表性压缩方法总结。
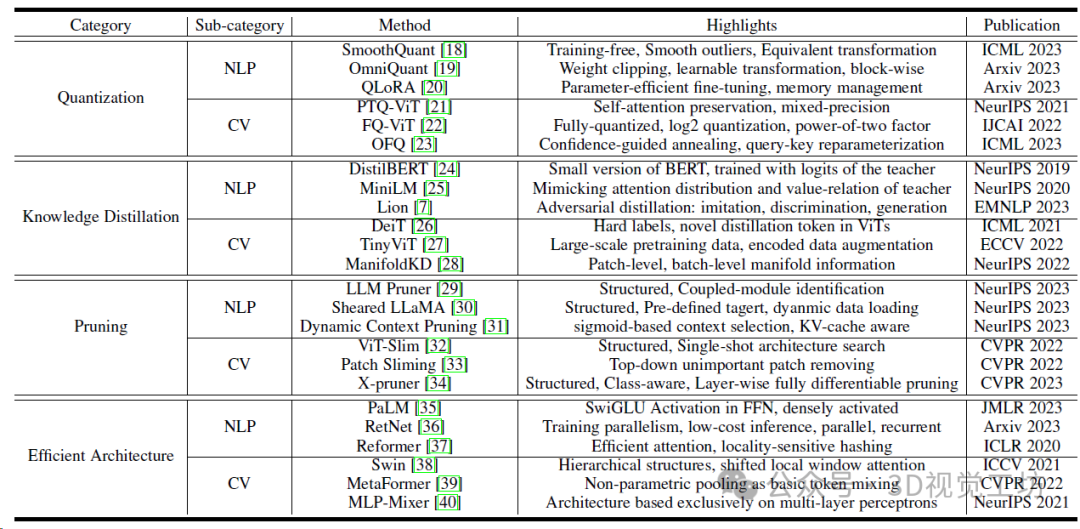
基于Transformer的视觉模型的不同PTQ(Post-training quantization)和QAT(Quantization-aware training)方法的比较。W/A表示权重和激活度的位宽,结果显示在ImageNet-1k验证集上的精确度最高。*代表混合精度。
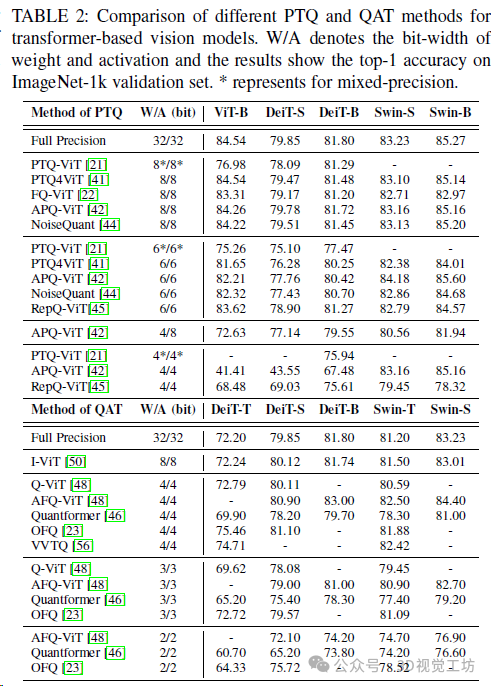
4. 模型量化
量化(Quantization)是在各种设备上部署 Transformer 的关键步骤,特别是在为低精度算术设计专用电路的 GPU和 NPU 上。在量化过程中,浮点张量被转换为具有相应量化参数(比例因子 s和零点 z)的整数张量,然后整数张量可以被量化回浮点数,但与原始相比会导致一定的精度误差。
Transformer量化总结。顶部展示了计算机视觉和自然语言处理现有作品中解决的不同问题,底部显示了标准transformer块的正常INT8推理过程。
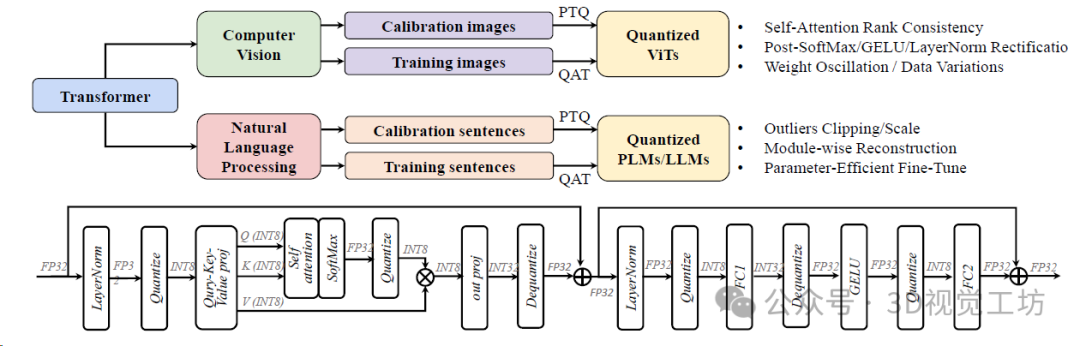
在NVIDIA A100-80GB GPU上使用Faster Transformer时ViT和OPT的推理延迟。
5. 知识蒸馏
知识蒸馏(Knowledge distillation,KD)旨在通过从教师网络中蒸馏或传递知识来训练学生网络。这篇文章主要关注的蒸馏方法是:实现紧凑学生模型的,同时与繁重的教师模型相比保持令人满意的性能。学生模型通常具有较窄且较浅的架构,使它们更适合部署在资源有限的系统上。并主要介绍基于 logits 的方法(在 logits 级别传递知识)以及基于 hint 的方法(通过中间特征传递知识)。
用于大型Transformer模型的知识蒸馏分类。
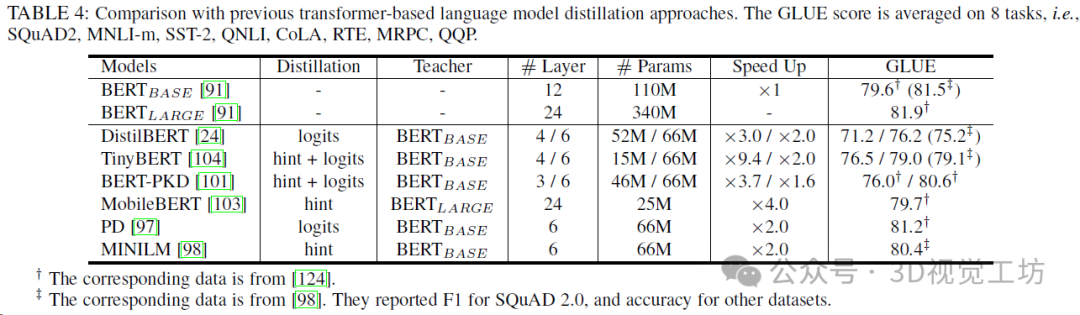
与以前基于transformer的语言模型蒸馏方法的比较,GLUE得分是8个任务的平均值。
6. 模型剪枝
模型剪枝包括修剪和模型训练的顺序,结构规范以及确定修剪参数的方式。下面总结了Transformer模型剪枝方法的分类。
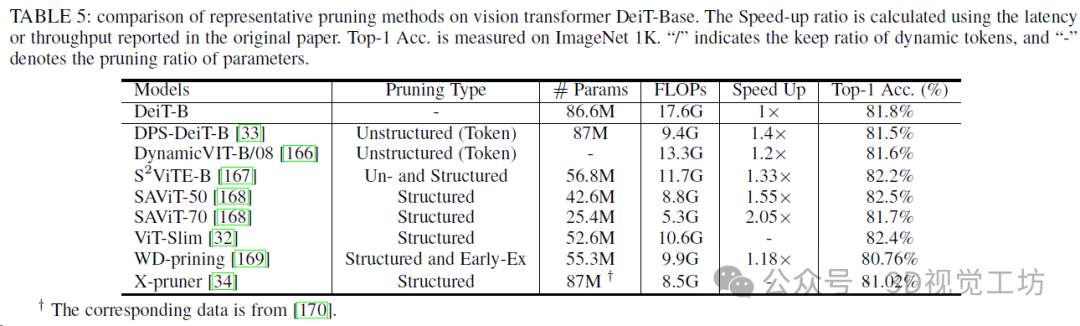
视觉转换库典型剪枝方法的比较。
大型语言Transformer上典型剪枝方法的比较。
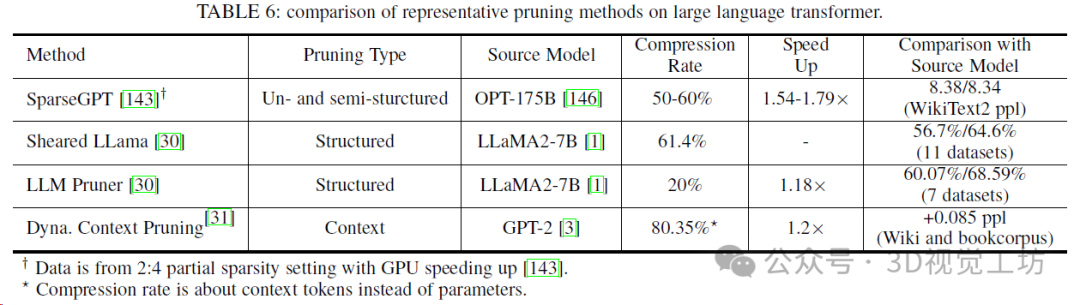
几种具有代表性的基于Transformer的LLM和LVM的模型卡,带有公开的配置详细信息。
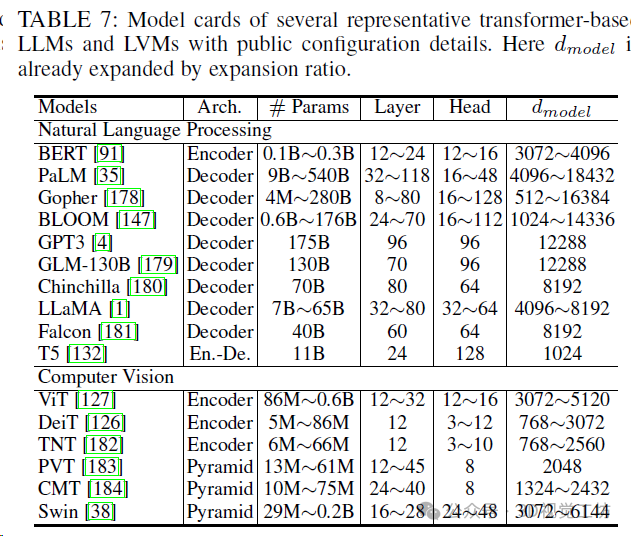
从训练并行化(TP)、推理成本(时间)和内存复杂性(内存)进行模型比较。N和d分别表示序列长度和特征维数。
7. 其他压缩方法
除了量化、蒸馏、修剪和新颖的网络架构之外,还有几种其他模型压缩和加速方法。
张量分解。 张量或矩阵分解旨在将大张量或矩阵分解为较小的张量或矩阵,以节省参数数量和计算成本。这种方法首先被引入到全连接层和卷积网络的压缩中。至于大型语言模型,张量分解被用于简化模型的权重或嵌入层。
早期退出。 早期退出可以动态为每个输入样本分配不同的资源并保持原始性能,这在信息检索系统和卷积网络中已经成功使用。许多早期退出技术已被提出用于仅编码器的变压器。早期退出的关键问题是确定何时退出。现有的作品主要利用内在的置信度度量、提前路由或训练一个早期退出分类器。
猜测采样。 猜测采样是一种特殊的Transformer解码加速方法,通过并行计算几个令牌来进行。在大型语言模型中,解码K个令牌需要模型的K次运行,这是缓慢的。利用从较小模型生成的参考令牌,猜测采样并行运行这些令牌可以显著加快解码过程。此外,拒绝方案可以保持原始LLM的分布,从而理论上实现猜测采样的无损。
8. 总结 & 未来趋势
这篇综述系统地调查了Transformer模型的压缩方法。与其他架构(如CNN或RNN)不同,Transformer具有独特的架构设计,具有替代注意力和FFN模块,因此需要专门定制的压缩方法以获得最佳的压缩率。此外,对于这些大型模型,压缩方法的效率变得特别关键。某些模型压缩技术需要大量的计算资源,这可能对这些庞大的模型来说是不可行的。本调查旨在涵盖与Transformer相关的大部分最近的工作,并阐述其压缩的全面路线图。随后,深入探讨了各种方法之间的相互关系,解决了后期挑战,并概述了未来研究的方向。
不同压缩方法之间的关系。 不同的压缩方法可以一起使用,以获得极其高效的架构。常见的顺序是首先定义一个具有高效操作的新架构。然后删除多余的组件(例如注意力头、层),以获得一个较小的模型。对于实际硬件实现,将权重或激活量量化为较低的位数是必不可少的。所需位数的选择不仅取决于误差的容忍度,还取决于硬件设计。例如,
训练高效的压缩策略。 与压缩传统模型不同,对压缩方法的计算成本的重视程度增加了。目前,大型Transformer正在使用大量的计算资源在庞大的数据集上进行训练。例如,Llama2在数千个GPU上训练了2万亿个令牌,持续了几个月。在预训练期间使用相当的计算资源进行微调是不切实际的,特别是当原始数据通常是不可访问的。因此,训练后的高效压缩方法的可行性变得更加可行。然而,对于较低的位数(例如4位),量化模型仍然会遭受显著的性能降低。值得注意的是,极低位模型,例如二进制Transformer,在传统的小型模型中已经得到了广泛的探索,但在大型模型的背景下仍然相对未知。
对于修剪来说, 后期训练的挑战与修剪粒度紧密相关。尽管非结构化的稀疏性可以在最小微调要求下实现高压缩率,但类似的策略难以转移到结构性修剪中。直接删除整个注意力头或层将导致模型架构的重大改变和因此准确性的显著降低。如何识别有效权重以及如何有效地恢复性能都是洞察力方向。识别有效权重和恢复表示能力的有效策略是解决这些挑战的关键研究方向。
超越Transformer的高效架构。 在现实世界的应用中,Transformer架构的输入上下文可以延伸到极长的长度,包括NLP中的序列文本(例如,一本拥有数十万字的书)或CV中的高分辨率图像。基础注意力机制对输入序列长度的复杂度呈二次复杂度,对于长序列输入构成了重大的计算挑战。许多研究通过减少注意力的计算成本来解决这个问题,采用了稀疏注意力、局部注意力等技术。然而,这些注意力压缩策略通常会损害表示能力,导致性能下降。
新兴的架构, 如RWKV和RetNet采用了类似于RNN的递归输出生成,有效地将计算复杂度降低到O(N)。这一发展有望在探索更高效模型的过程中进一步发展。对于计算机视觉任务,即使是没有注意力模块的纯MLP架构也可以实现SOTA性能。过仔细研究它们的效率、泛化性和扩展能力,探索新的高效架构是有希望的。
审核编辑:黄飞
-
如何使用MATLAB构建Transformer模型2025-02-06 6686
-
大语言模型背后的Transformer,与CNN和RNN有何不同2023-12-25 6835
-
【大语言模型:原理与工程实践】大语言模型的基础技术2024-05-05 1330
-
你了解在单GPU上就可以运行的Transformer模型吗2022-11-02 2143
-
压缩模型会加速推理吗?2023-01-29 592
-
基于压缩感知理论的稀疏信道估计方法2018-02-04 1232
-
Transformer模型的多模态学习应用2021-03-25 12041
-
使用跨界模型Transformer来做物体检测!2021-06-10 3056
-
Microsoft使用NVIDIA Triton加速AI Transformer模型应用2022-04-02 2615
-
Transformer常用的轻量化方法2022-10-25 7576
-
基于Transformer的大型语言模型(LLM)的内部机制2023-06-25 2607
-
基于 Transformer 的分割与检测方法2023-07-05 2214
-
transformer模型详解:Transformer 模型的压缩方法2023-07-17 3763
-
使用PyTorch搭建Transformer模型2024-07-02 3525
-
Transformer语言模型简介与实现过程2024-07-10 4135
全部0条评论

快来发表一下你的评论吧 !
