

从基本原理到应用的SLAM技术深度解析
机器视觉
描述
本篇综述是本人与知乎的一位大佬博主华神共同完成的。在这里感谢华神的帮助,同时希望本篇能为在SLAM道路上探索的同僚们尽些绵薄之力,欢迎各位一同探讨和进步。
01 引言:SLAM概念与结构
1.1 SLAM概述
首先,本人认为需要思考一个问题:为什么要做SLAM?SLAM技术可以解决什么问题?简单的引入。 这个问题的回答可以是:1.大部分的路径规划需要基础地图;2.定位时,为消除IMU、Wheel Odometry等里程计模型的“误差累加”特性引入观测参考;3. 提供一个全局表征(frame、origin)的参考,等。 再回到SLAM概念的定义:SLAM(Simultaneous Localization and Mapping)是以定位和建图两大技术为目标的一个研究领域。目前主流的slam技术为激光slam(基于激光雷达)和视觉slam(基于单/双目摄像头),实现上主要分为基于滤波 (Filter-Based) 的SLAM和基于图优化(Graph-Based)的SLAM。归结其本质,其实就是——State Estimation in Robotics
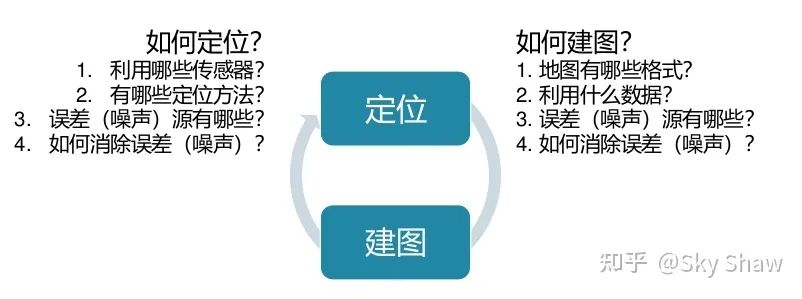
1.2 SLAM结构
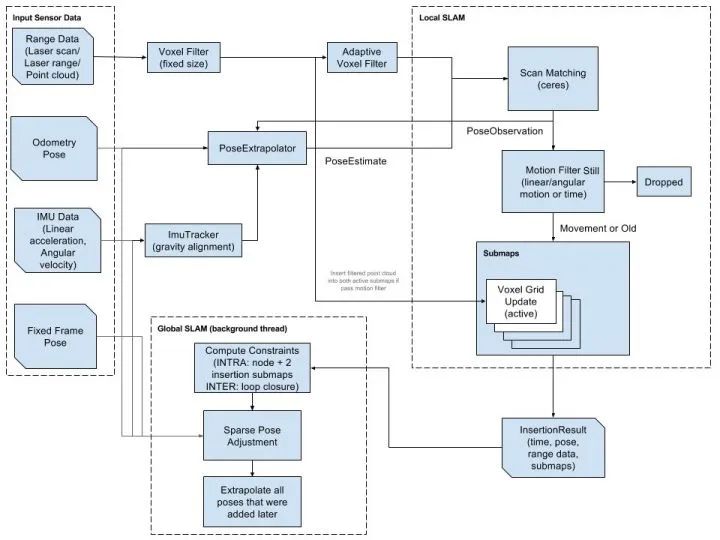
▲ 此处以cartographer框架为例
1.2.1 数据预处理
Sensor data的的接收;
多传感器数据同步;
传感器数据预处理(无效值去除、序列检查、点云遮挡点与平行点去除、坐标系处理,etc);
点云去畸变处理(运动畸变,重力对齐,etc);
1.2.2 前端LIO
基于sensor-tracker形式的pose-extrapolator;
点云注册&配准;
e,g, CSM:Correlative Scan Matcher & Ceres Scan Matcher;
1.2.3 后端Refinement
基于前端LIO选择的key nodes形成位姿图;
利用多传感器数据计算约束实现位姿图的优化(e,g, 基于Google Ceres构建Pose Graph,利用node-submap constraints & submap-submap constraints & node-node constraints作为edges,scan-pose为node);
基于SPA加速的后端优化;
1.2.4 闭环检测
根据key node搜索neighbor key nodes,尝试进行点云配准(scan2scan or scan2map);
e,g, LoopClosure:Correlative Scan Matcher & Branch and Bound;
1.2.5 地图构建保存与显示
pbstream文件:建图轨迹信息保存与加载;
根据优化后的key nodes和对应的point cloud生成点云地图;
基于RangefindersRayCasting的概率栅格地图的构建、更新和扩展。
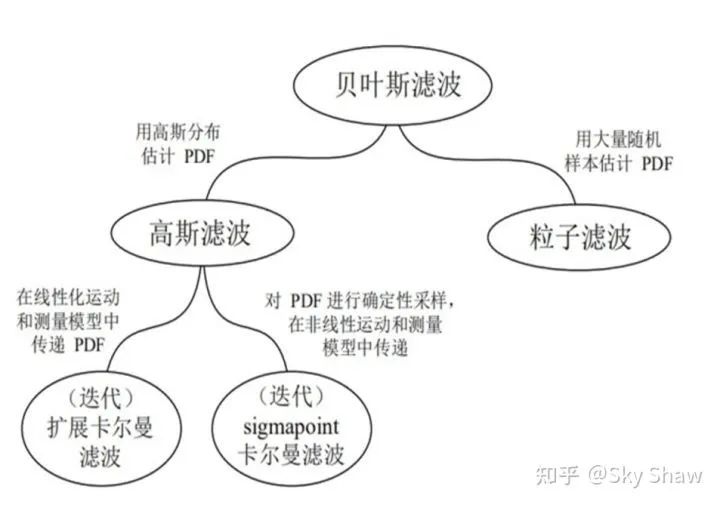
1.3 基于滤波的传感器融合算法方案
归结基于滤波的定位算法的核心技术,其实就是贝叶斯滤波或者其衍生算法。整体上的流程大抵都是基于上一时刻的状态量,通过控制量输入和运动方程的推演获取预测的状态量,再由相关传感器的观测对预测进行融合“补偿”。

目前常见的应用在SLAM系统中的滤波算法主要有以下几种:
Bayesian Filter;
Kalman Filter;
Particle Filter(adaptive Monte Carlo Localization);
Extended Kalman Filter;
Iterated Extended Kalman Filter;
Error-State Kalman Filter;
Multi-State Constraint Kalman Filter;
1.4 基于优化的传感器融合算法方案
归结基于优化的定位算法的核心技术,其实就是最小二乘,但应用在SLAM技术中,其关键的地方在于:如何设计与建立SLAM的problem structure:

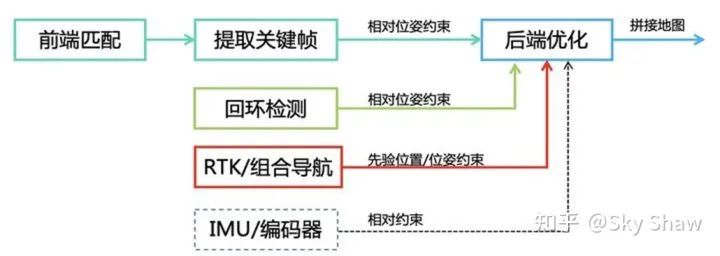
也就是上述的目标函数是由哪些部分构成的?残差项有哪些?还是以cartographer为例,残差项可以包含关键帧之间的odom约束,关键帧与submap之间的约束(intra和inter),landmark引入产生的约束,等等。以上一起由通过不同的残差项权重整合在一起,共同组成后端优化的目标函数。 那么除去这些呢,还可以引入哪些约束来优化整体的优化结构?或者又有什么方式可以优化优化的处理过程?
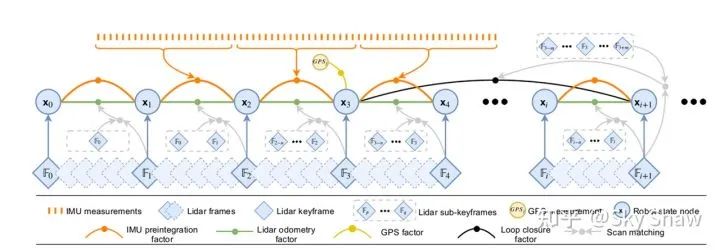
▲ lio-sam中的因子图结构 目前常见的应用在SLAM系统中的优化库主要有以下几种:
G2o;
Ceres;
Gtsam;
Isam;
各个优化库的使用和特点就不在此处进行说明了,感兴趣的小伙伴可以自行网上查阅资料~
1.5 地图构建的基本原理
地图可以根据具体的应用场景和功能特性简单地分为几种:
语义地图;
基于概率更新的占栅格地图(黑白灰三色图);
3D点云地图(稀疏、稠密);
基于TSDF的占栅格地图(或点云地图?)
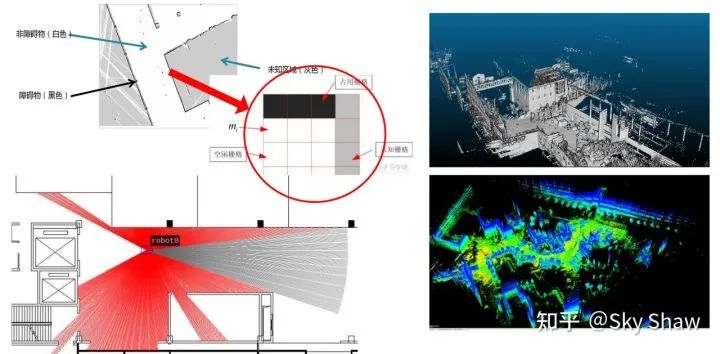
2D栅格地图的基本原理大抵会涉及以下几个技术点:
栅格地图的生成与维护;
概率更新算法;
Bresenham画线算法;
而与栅格地图特性相对应的是基于TSDF(Truncated Signed Distance Function)原理生成的栅格地图,TSDF生成的地图最大的特性就是生成的地图边界是可以保证单像素级别的,而基于概率更新的栅格地图的边界往往都会由多个像素“混合”在一起。
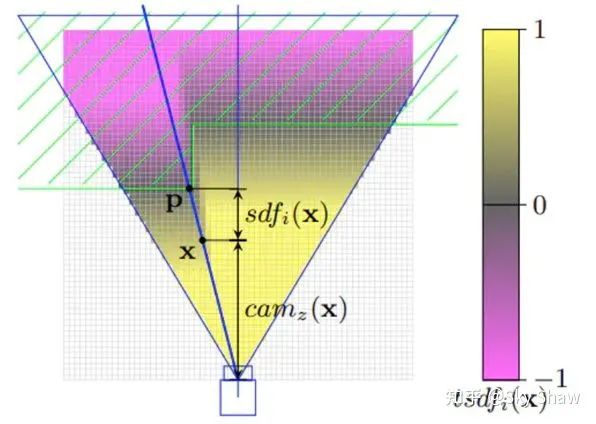
▲ TSDF示意图

▲ TSDF定义与栅格生成方法
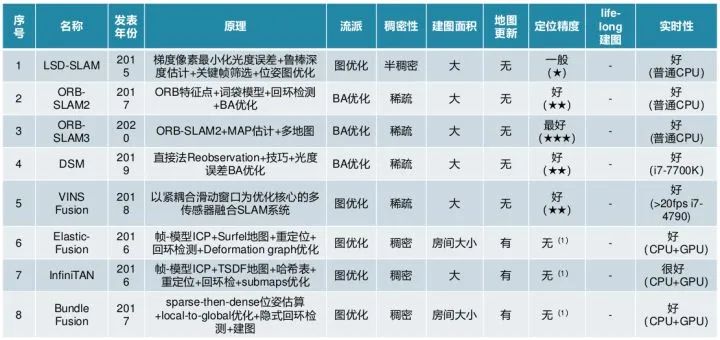
02 激光SLAM主流方案
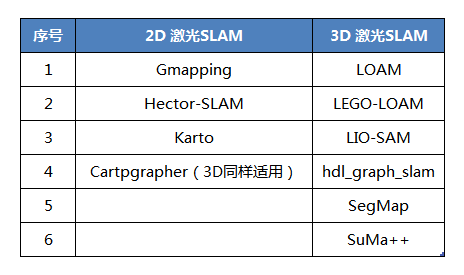
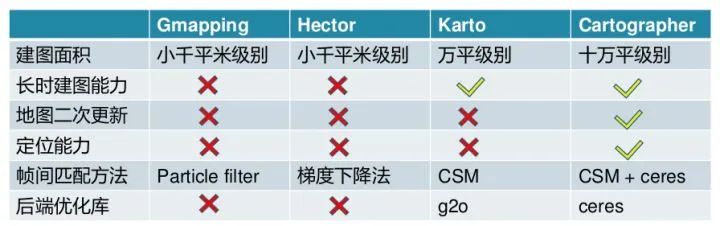
2.1 Gmapping
简介:基于粒子滤波框架的激光SLAM,RBpf粒子滤波算法,即将定位和建图过程分离,先进行定位再进行建图,结合里程计和激光信息,每个粒子都携带一个地图,构建小场景地图所需的计算量较小,精度较高。但在高分辨率建图时,在静止状态下更新不好,存在震荡并noise过多。
Github链接: https://github.com/ros-perception/openslam_gmapping https://github.com/ros-perception/slam_gmapping 相关论文: Giorgio Grisetti, Cyrill Stachniss, and Wolfram Burgard: Improved Techniques for Grid Mapping with Rao-Blackwellized Particle Filters, IEEE Transactions on Robotics, Volume 23, pages 34-46, 2007. Giorgio Grisetti, Cyrill Stachniss, and Wolfram Burgard: Improving Grid-based SLAM with Rao-Blackwellized Particle Filters by Adaptive Proposals and Selective Resampling, In Proc. of the IEEE International Conference on Robotics and Automation (ICRA), 2005.
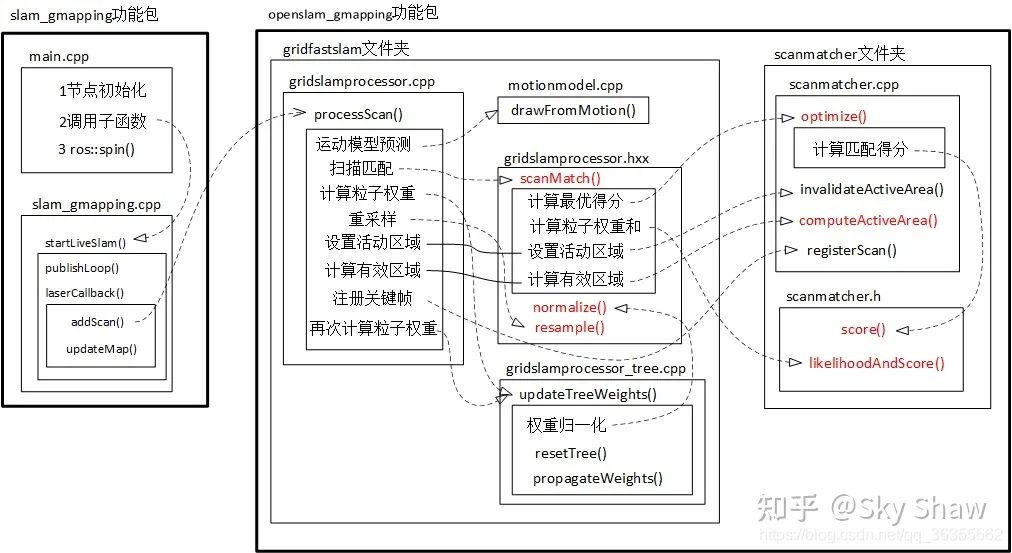
2.2 Hector_SLAM
简介:利用优化方法进行帧间匹配的激光slam算法,search space不大,不需要里程计信息,代码较短。且只处理scan的endpoints(不利用laser scan structure),故而可利用IMU调整laser scan attitude。缺点是在雷达频率不够的设备上效果不佳,快速转向时容易错误匹配;没有loop closure故而若累计误差过大,HectorSLAM没有地图调整能力,且帧间优化匹配时也是全局地图上进行,cpu资源消耗大。 Github链接: https://github.com/tu-darmstadt-ros-pkg/hector_slam 相关论文: Kohlbrecher, Stefan , et al. “A flexible and scalable slam system with full 3d motion estimation.” 2011 IEEE International Symposium on Safety, Security, and Rescue Robotics IEEE, 2011.
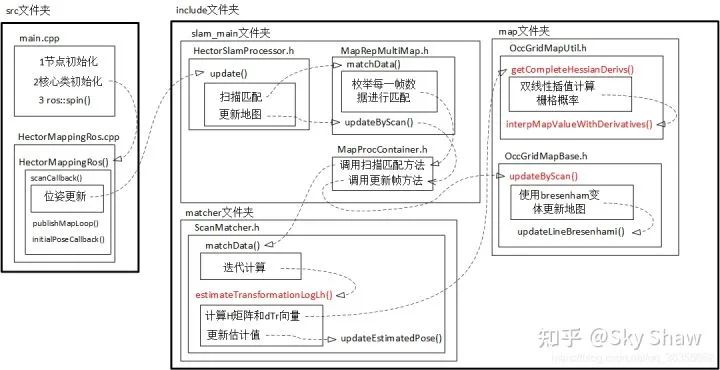
2.3 Karto
简介:基于图优化的SLAM,包含回环检测,适用于大面积建图。前端帧匹配采取的的是correlative scan matcher的方式进行粗、精两次匹配, 回环检测上karto没有submap的概念,全部以keyScan的形式存储在Mapper-sensor-Manager中,keyScan的插入依据pose的距离窗口生成localMap进行匹配。local与gloal的loop closure依据graph的结构和Mapper-sensor-Managerss顺序存储分配的ID信息,选择candidates生成localMap进行匹配,依据score进一步确定闭环。 Github链接: https://github.com/ros-perception/open_karto https://github.com/ros-perception/slam_karto 相关论文: Olson, E. B. . “Real-time correlative scan matching.” Robotics and Automation, 2009. ICRA '09. IEEE International Conference on IEEE, 2009. Konolige, Kurt , et al. “Efficient sparse pose adjustment for 2D mapping.” 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems IEEE, 2010.
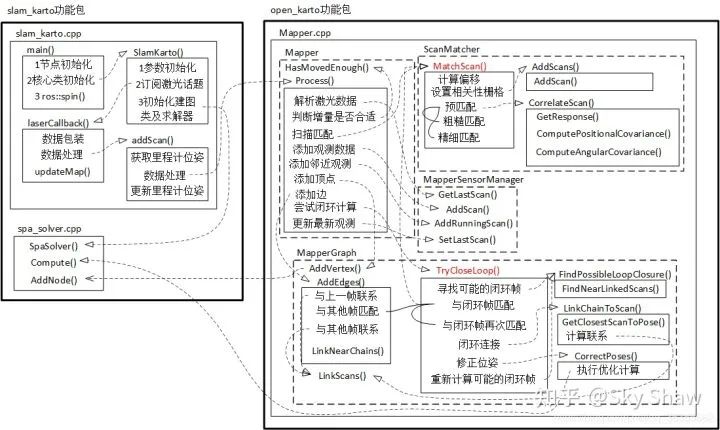
2.4 Cartographer
简介:基于图优化的SLAM,源自谷歌,代码优美,是非常完整的激光slam系统,包含相对鲁棒的前端,基于submap和node约束独立的pose graph后端及各类评测工具。模块化、系统化、工程化程度很高, 封装很完善。可将其视为升级版本的Karto的顶配豪华版本,搭载了传感器同步、位姿外推器、激光数据预处理(去畸变、重复点云删除)功能,前端帧匹配上融合使用了karto的暴力匹配csm和hector的基于LM的梯度优化方法匹配,由于引入了submap的概念,后端回环检测上使用分支定界的方法进行快速搜索,后端优化过程基于SPA完成。同时carto还开放了landmark、GPS等数据融合的接口,提供了地图续扫和定位的功能。 Github链接: https://github.com/cartographer-project/cartographer 相关论文: Hess, Wolfgang , et al. “Real-Time Loop Closure in 2D LIDAR SLAM.” 2016 IEEE International Conference on Robotics and Automation (ICRA) IEEE, 2016.
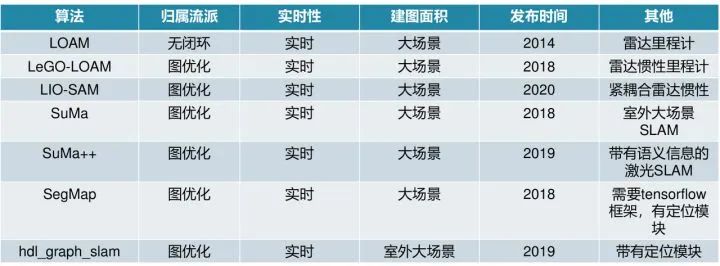
2.5 LOAM方案
简介:经典制作,长期霸榜kitti odometry门类第一,也衍生很多相关SLAM算法,如A-LOAM、LeGO-LOAM等。其主要思想是通过两个算法:一个高频激光里程计进行低精度的运动估计,即使用激光雷达做里程计计算两次扫描之间的位姿变换;另一个是执行低频但是高精度的建图与校正里程计,利用多次扫描的结果构建地图,细化位姿轨迹。在点云匹配与特征提取时,由于scan-to-scan匹配精度低但速度快, map-to-map匹配精度高但是速度慢,创新性使用scan-to-map来兼具精度与速度,这种思路给后续很多基于激光里程计或多传感器融合框架提供思路。原本的LOAM没有IMU辅助,不带有回环检测,因而不可避免引起漂移。沿着此思路,产生了很多算法如LeGO-LOAM, LINS, LIO-Mapping, LIO-SAM等。 Github链接: LOAM中文注解版:https://github.com/cuitaixiang/LOAM_NOTED 相关论文: Ji Zhang and Sanjiv Singh. “LOAM: Lidar Odometry and Mapping in Real-time.” Proceedings of Robotics: Science and Systems Conference, 2014.
2.6 LeGo-LOAM方案
简介:在LOAM的基础上细化了特征提取与优化,带有回环功能。可以在低功耗嵌入式系统上实现实时姿态估计。主要也是由一个高频低精度激光里程计与一个低频高精度建图回环检测组成。区别在于LeGO-LOAM在LOAM基础上采用地面分割方式将点云分为地面点与非地面点,进一步缩小特征提取范围,以加快计算速度,能够在嵌入式设备上实时运行;在建图模块添加了位姿图与回环检测,解决了LOAM没有后端优化的弊端,提供建图效率,其效果对比如下图。 Github链接: LeGo-LOAM中文注解版:https://github.com/wykxwyc/LeGO-LOAM_NOTED/tree/master/src 相关论文: T. Shan and B. Englot, “LeGO-LOAM: Lightweight and Groundoptimized Lidar Odometry and Mapping on Variable Terrain,”IEEE/RSJ International Conference on Intelligent Robots and Systems,pp. 4758-4765, 2018.

2.7 LIO-SAM方案
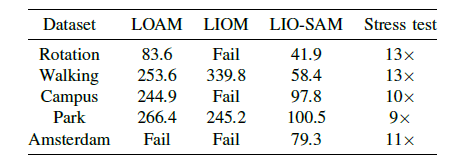
简介:这是LeGO-LOAM作者新作,通过平滑和匹配的紧密耦合激光雷达惯性SLAM框架。LIO-SAM在因子图(factor graph)上方制定了激光雷达惯性里程表,从而可以将不同来源的大量相对和绝对测量值(包括回路闭合)作为因子合并到系统中,通过惯性测量单元(IMU)预积分的估计运动使点云偏斜,并为激光雷达里程计优化提供了初始预测。为了确保实时高性能,将之前的激光雷达扫描边缘化以进行姿势优化,而不是将激光雷达扫描与全局地图匹配。选择性地引入关键帧以及以有效的滑动窗口将新的关键帧注册到固定大小的先验“子关键帧”集合中,在局部范围而不是全局范围内进行扫描匹配。 算法可以添加不同的模块,组合不同的方案。当同时禁用GPS和闭环检测时,此方法称为LIO-odom,它仅利用IMU预积分和激光雷达里程计因子;当添加GPS因子时,则将此方法称为LIO-GPS;若使用IMU、激光雷达里程计、GPS、回环检测时则称之为LIO-SAM方法。 Github链接: https://github.com/TixiaoShan/LIO-SAM 相关论文: T. Shan and B. Englot, “LIO-SAM: Tightly-coupled Lidar Inertial Odometry via Smoothing and Mapping,”IEEE/RSJ International Conference on Intelligent Robots and Systems”,2020. 性能介绍:在论文作者录制的数据集上,对比了LOAM、LIOM与自身几种组合方案的建图效果如下左图所示,也比较了几种算法在平移误差及处理单帧数据时所耗时间如右图所示,由此可见LIO-SAM处理速度较LOAM提高很多,精度上也有一定提高。

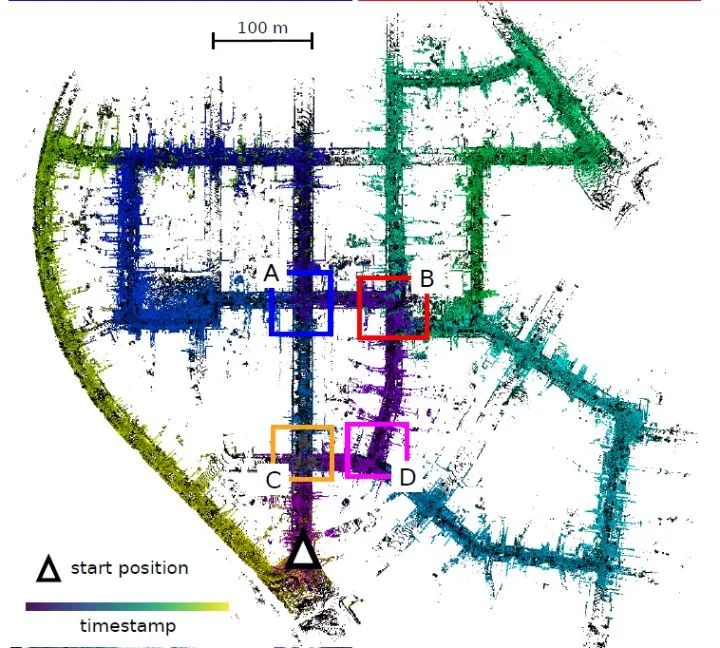
2.8 hdl_graph_slam方案
简介:这是一个基于图优化的3D激光SLAM框架,主要由激光里程计、回环检测以及后端图优化构成,同时融合了IMU、GPS以及地面检测的信息作为图的额外约束。算法首先读入激光雷达的点云数据,然后将原始的点云数据进行预滤波,经过滤波后的数据分别给到点云匹配里程计以及地面检测节点,两个节点分别计算连续两帧的相对运动和检测到的地面的参数,并将这两种消息送到hdl_graph_slam节点进行位姿图(pose graph)的更新以及回环检测,并发布地图的点云数据。hdl_graph_slam在资源消耗、代码复杂度等方面具有优势,且带有定位模块,右图显示了带GPS的室外建图结果。 Github链接: https://github.com/koide3/hdl_graph_slam 相关论文: Kenji Koide, Jun Miura, and Emanuele Menegatti, “A Portable 3D LIDAR-based System for Long-term and Wide-area People Behavior Measurement”, Advanced Robotic Systems, 2019


2.9 SegMap方案
原理介绍:这是一种基于3D点云中线段提取的方式去建图与定位的解决方案。将三维点云进行分割,把不同的环境目标划分为不同的段(segment),从而提出了一种新的地图表达方法:Segmap。相比于现有仅用来做定位的特征提取器,Segmap利用了数据驱动(深度学习)的描述子提取了语义特征信息。在语义信息层进行数据处理大大减小了计算量,较小维度的语义特征描述子解决了单机器人与多机器人系统的实时数据压缩问题。这种利用CNN语义信息的3D激光SLAM框架,在多机器人全局路径规划场景时比传统SLAM更具有优势。 Github链接: https://github.com/ethz-asl/segmap 相关论文: R. Dubé, A. Cramariuc, D. Dugas, J. Nieto, R. Siegwart, and C. Cadena. “SegMap: 3D Segment Mapping using Data-Driven Descriptors.” Robotics: Science and Systems (RSS), 2018. R. Dubé, MG. Gollub, H. Sommer, I. Gilitschenski, R. Siegwart, C. Cadena and , J. Nieto. “Incremental Segment-Based Localization in 3D Point Clouds.” IEEE Robotics and Automation Letters, 2018. R. Dubé, D. Dugas, E. Stumm, J. Nieto, R. Siegwart, and C. Cadena. “SegMatch: Segment Based Place Recognition in 3D Point Clouds.” IEEE International Conference on Robotics and Automation, 2017.
2.10 SuMa方案
原理介绍:此算法使用Surfel地图去实现前端里程计和闭环检测,此前Surfel地图曾被用在RGBD-SLAM中,第一次被用在在室外大场景三维SLAM中。Surfel地图最早是用在基于RGB-D相机的三维重建任务中的。SuMa的整体流程就是先处理点云把点云从三维展开成二维,然后生成局部地图用来给当前帧做匹配,接着通过ICP方法进行位姿更新,然后更新surfel地图,最后做闭环检测与后端优化。 Github链接: https://github.com/jbehley/SuMa 相关论文: J. Behley, C. Stachniss. Efficient Surfel-Based SLAM using 3D Laser Range Data in Urban Environments, Proc. of Robotics: Science and Systems (RSS), 2018.
2.11 SuMa++
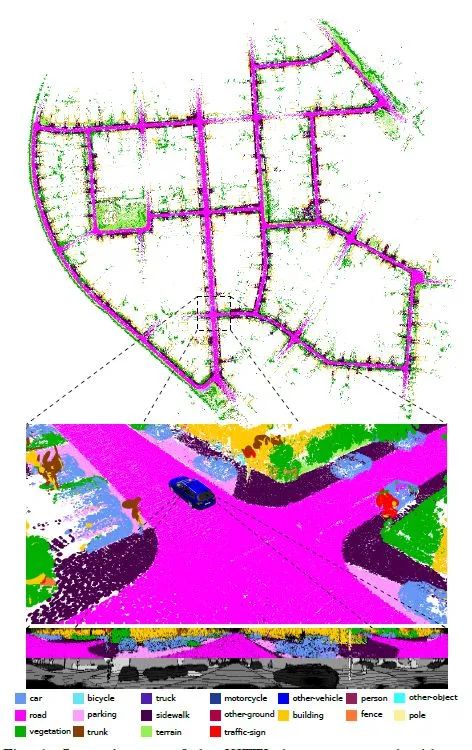
原理介绍:这是一种新的基于语义信息的激光雷达SLAM系统,可以更好地解决真实环境中的定位与建图问题。该系统通过语义分割激光雷达点云来获取点云级的密集语义信息,并将该语义信息集成到激光雷达SLAM中来提高激光雷达的定位与建图精度。通过基于深度学习的卷积神经网络,可以十分高效地在激光雷达“范围图(range image)”上进行语义分割,并对整个激光雷达点云进行语义标记。通过结合几何深度信息,进一步提升语义分割的精度。基于带语义标记的激光雷达点云,此方法能够构建带有语义信息且全局一致的密集“面元(surfel)”语义地图。基于该语义地图,也能够可靠地过滤移除动态物体,而且还可以通过语义约束来进一步提高投影匹配ICP的位姿估计精度。 Github链接: https://github.com/PRBonn/semantic_suma 相关论文: Chen, Xieyuanli & Milioto, Andres & Palazzolo, Emanuele & Giguère, Philippe & Behley, Jens & Stachniss, Cyrill. SuMa++: Efficient LiDAR-based Semantic SLAM. 4530-4537. (IROS 2019).
03 视觉SLAM主流方案
以视觉传感器作为主要感知方式的SLAM称为视觉SLAM 。按照建图稀疏程度来分,视觉SLAM技术可以分为稀疏SLAM、半稠密SLAM和稠密SLAM。虽然同为SLAM系统,但它们的侧重点并不完全一样。 SLAM 系统最初的设想是为机器人提供在未知环境中探索时的定位和导航能力,其核心在于实时定位。以定位为目的,需要建立周围环境的路标点地图,进而确定机器人相对路标点的位置,这里的路标点地图即稀疏地图,地图服务于定位。 但随着算法和算力的进步,SLAM逐渐被用于对环境的重建,也即把所有看到的部分都完整的重建出来,此时,SLAM所建立的地图必须是稠密的,而SLAM系统的首要任务也从定位转变为了建立环境的精确稠密地图。这种首要任务的差异最终会反映在SLAM系统的技术方案上,稠密SLAM系统对精度的评价也从“定位精度”转变为“建图精度”。此外,相比于稀疏SLAM系统,稠密SLAM的建图部分要消耗大得多的算力,通常都需要GPU加速来达到实时性。
3.1 LSD-SLAM 方案
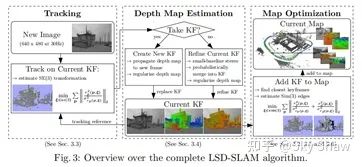
LSD-SLAM 即 Large-Scale Direct SLAM,兼容单目相机和双目相机。LSD-SLAM是一种基于光流跟踪的直接法SLAM,但是实现了半稠密建图,建图规模大,可以在线实时运行。作者有创见地提出了像素梯度与直接法的关系,并利用这种关系实现了简单直接法所无法实现的半稠密重建。作为一种基于关键帧的SLAM系统,LSD-SLAM的主要处理流程为:
通过直接法对相机位姿进行追踪,当当前帧所包含的信息与最后一个关键帧有足够差别时,建立新的关键帧。
对当前关键帧的深度信息进行估计,对于双目LSD-SLAM,首先根据左右图像的视差估计深度,然后结合不同时序的帧优化深度。
对全局的关键帧进行位姿图优化,获得全局一致的地图。
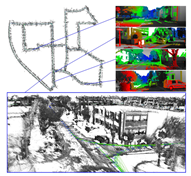
LSD-SLAM 在 CPU 上实现了半稠密场景的重建,这在当时(2014)是非常有创见的工作,是作者(TUM 计算机视觉组)多年对直接法进行研究的成果。LSD-SLAM 的半稠密追踪使用了一些精妙的手段,来保证追踪的实时性与稳定性。 另一方面,由于 LSD-SLAM 使用了直接法进行跟踪,所以它既有直接法的优点(对特征缺失区域不敏感),也继承了直接法的缺点。例如,LSD-SLAM 对相机内参和曝光非常敏感,并且在相机快速运动时容易丢失。

3.2 ORB-SLAM2 方案
ORB-SLAM 系列是最为经典的SLAM 方案之一,ORB-SLAM2 发表于2017年,是ORB-SLAM的升级版,同时支持单目、双目、RGB-D相机。ORB-SLAM2的算法流程与ORB-SLAM几乎相同,共包含三个模块(线程),如下所示。

需要注意的是,重定位和回环检测都是基于DBoW2词袋实现的,而词袋需要预先建立好,通常可以通过一个大型图片数据集离线建立起词袋,数据集数据越广泛,建立的词袋越实用。

3.3 ORB-SLAM3 方案
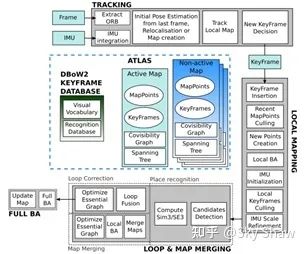
在前作的基础上,西班牙Zaragoza大学于2020年7月最新开源了ORB-SLAM3的论文和源码。ORB-SLAM3支持的设备和功能更多,支持单目、双目、RGB-D相机,针孔、鱼眼,视觉惯性里程计,多地图SLAM等,几乎全覆盖了视觉SLAM各个分支。总体来说,ORB-SLAM3 基本框架、代码结构都是ORB-SLAM2的延伸,但是加入了很多新的方法,实现了更好的效果,体现在以下三个方面:
构建了基于特征的高度集成视觉-惯导SLAM系统,更加鲁棒,适应于室内/外的大/小场景,精度提升2~5倍。
是一个多地图系统,VO丢失时,会建立新的地图,当找回场景后,会与之前的地图自动融合。
系统鲁棒性与state-of-the-art相当,但精度更高,在无人机数据集上平均精度3.6cm,室内数据集平均精度9mm。

3.4 DSM 方案:Direct Sparse Mapping
DSM 方案由西班牙的学者(作者之一同为ORB系列的作者)于2019年发表,这是一个基于直接法的完整单目SLAM系统。直接法SLAM系统通常采用光度误差进行BA优化,但直接法不能依赖自身解决相同场景的 reobservation问题和相同点的融合问题(因此直接法的回环检测多依赖特征点解决,如LSD-SLAM);DSM则解决了这一问题,是首个完全基于直接法实现回环检测和地图重用的SLAM系统,并在 EuRoC 数据集上取得了直接法SLAM中最高的精度。 DSM设计了独特的“局部窗口选择策略”来选择共视点,通过 coarse-to-fine 的策略来实现 reobservation,并以此实现回环检测;在优化方面,仍然基于光度误差做BA优化。
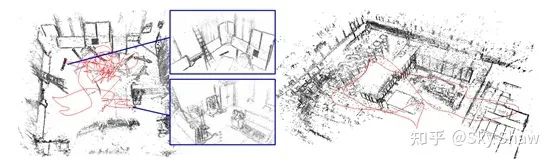
基于以上特点,DSM 具有较快的运行速度(无需计算特征点描述子),精度很高;除了直接法自身的缺点之外,其缺点还在于单目无法恢复出尺度信息。

3.5 VINS-Fusion 方案
VINS系列由港科大沈劭劼课题组发表和公开,其中VINS-Fusion 是继 VINS-Mono (单目视觉惯导 SLAM 方案)后的双目视觉惯导 SLAM 方案,VINS-Fusion 是一种基于优化的多传感器状态估计器,可实现自主应用(无人机,无人车, AR / VR)的精确自定位。VINS-Fusion 是 VINS-Mono 的扩展,支持多种视觉惯性传感器类型(单目相机+ IMU,双目相机+ IMU,双目相机-only),但两者的技术框架是相同的,如下图所示。其主要技术模块有:
轻量级前端(视觉光流跟踪+IMU预积分)
传感器在线标定+视觉惯导联合初始化
紧耦合滑窗优化(同时具有快速重定位功能)
回环检测
全局四自由度位姿优化
(注:红色加粗表示核心工作)
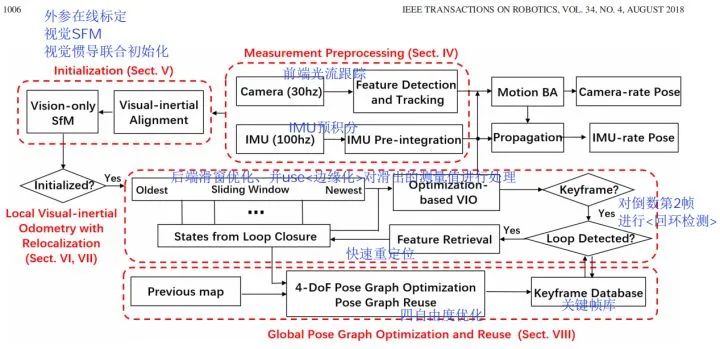
VINS方案本身是基于特征点的,因此只能用于稀疏建图。VINS的优点在于实现了很高的定位精度,这种精度来源于视觉+IMU融合以及紧耦合滑窗优化算法。VINS对计算资源的消耗比较小,在普通CPU上既可以实现在线实时运行,适合于对实时性有要求的移动设备。

3.6 ElasticFusion 方案
ElasticFusion (2016) 是由帝国理工发表的一项优秀RGB-D SLAM系统,具有稠密建图、在线实时运行、轻量级等显著特点。如前文所述,ElasticFusion 以稠密建图为主要目标(而非定位),建图的精度和质量是主要指标。ElasticFusion 的技术特点如下:
基于 RGB-D 的稠密三维重建一般使用网格模型融合点云,ElasticFusion 是为数不多使用 surfel 模型的方案。
传统的 SLAM 算法一般通过优化位姿或者路标点来提高精度,而 ElasticFusion 采用优化 deformation graph 的方式。
融合了重定位算法(当相机跟丢时,重新计算相机的位姿)。
ElasticFusion 算法融合了 RGB信息(颜色一致性约束) 和深度信息(ICP 算法)进行位姿估计。
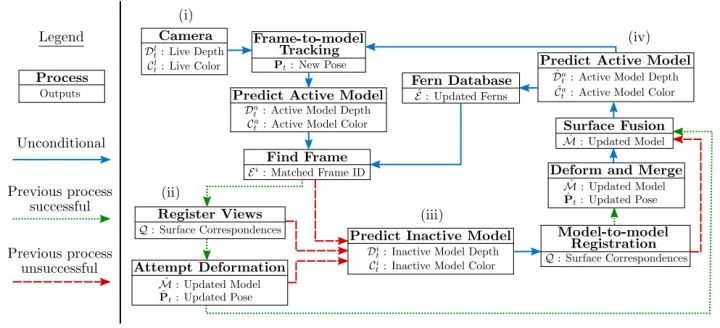
ElasticFusion首先根据RGB-D图像配准估算位姿,根据位姿误差决定进行重定位还是回环检测;若存在回环,则首先优化Deformation graph 然后优化 surfel地图;若不存在,则更新和融合全局地图,并估算当前视角下的模型,用于下一帧图像配准。总体来说,ElasticFusion具有较高的重建精度,在重建房间大小的场景时效果很好;但没有对代码做特别的优化,在大场景重建时效果不佳。
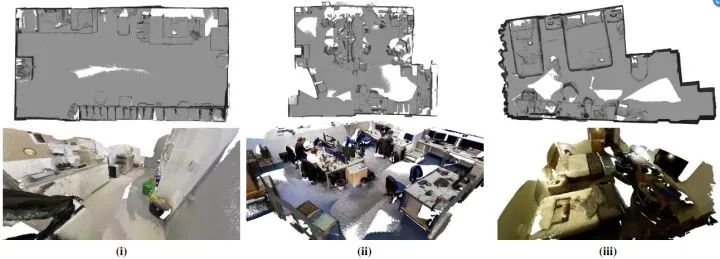

3.7 InfiniTAM 方案
InfiniTAM 是牛津大学于2016年发表的稠密 SLAM 方案,该方案基于 KinectFusion 和 体素块哈希表(voxel block hashing)发展而来。首先,InfiniTAM 方案在建图部分利用 TSDF 模型(截断符号距离场)进行建模,只是在建模的时候,不是对整个空间都划分等大小的网格,而是只在场景表面的周围划分网格(voxel blocks),且只为待重建的表面上的Voxel block分配显存,并使用哈希表这一结构来管理GPU对Voxel block的内存分配和数据访问。通过这样的方法,InfiniTAM 大大减小了稠密建图对 GPU 的内存消耗,提升了算法效率。 InfiniTAM 的 算法流程 如右图所示,InfiniTAM 系统的前端与KinectFusion较为相似,主要分为三个阶段:
跟踪阶段:对新输入的图像进行定位,估算对应的相机位姿;
融合阶段:用于将新数据集成到现有的3D世界模型当中(更新voxel中存储的SDF值);
渲染阶段:利用光线投影算法(Raycasting)从世界模型中提取与下一个跟踪步骤相关的模型区域,用于下一帧的位姿估算;
在后端部分,InfiniTAM 维护一个 Active Submaps List(基于Voxel block + Hashing),从而实现轻量级的后端优化。
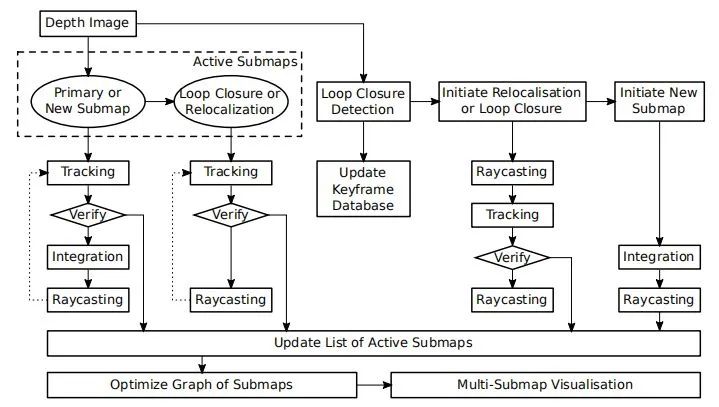
InfiniTAM 是一个完整的稠密SLAM系统,包括前端位姿估计,回环检测,重定位,后端优化等全部SLAM功能。InfiniTAM使用哈希表来管理体素(voxel),大大节约了GPU内存占用,因此可以构建更大规模场景的地图。


3.8 BundleFusion 方案
斯坦福大学2017年提出的BundleFusion技术,被认为可能是目前基于RGB-D相机进行稠密三维重建效果最好的方法。BundleFusion的整体流程是比较清晰的:输入的color+depth的数据流首先需要做帧与帧之间的匹配信息搜索,然后基于“稀疏特征+稠密特征”融合匹配以求得精确位姿变化;把连续相邻帧聚合为“帧段”并在帧段内做局部位姿优化,获得帧段地图/Chunk;然后基于“帧段”做全局位姿优化,将整体的漂移矫正;融合相邻Chunk,得到全局位姿和地图。整个过程持续动态更新。
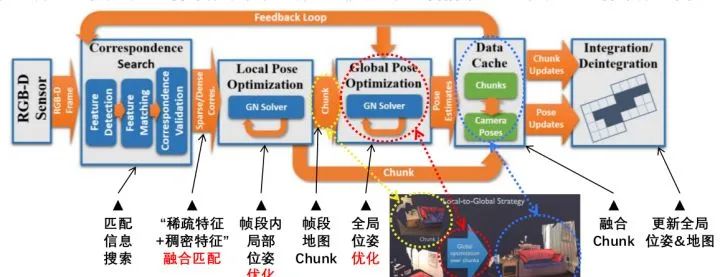
【融合匹配】在匹配方面,论文使用的是一种sparse-then-dense的并行全局优化方法。也就是说,先使用稀疏的SIFT特征点来进行比较粗糙的配准,因为稀疏特征点本身就可以用来做loop closure检测和relocalization。然后使用稠密的几何和光度连续性进行更加细致的配准。图1展示了sparse+dense这种方式和单纯sparse的对比结果。 【优化】在位姿优化方面,论文使用了一种分层的 local-to-global 优化方法,如图2所示。总共分为两层,在第一层,每连续10帧组成一个chunk,第一帧作为关键帧,然后对chunk内所有帧做局部位姿优化。在第二层,只使用所有的chunk的关键帧进行互相关联然后进行全局优化。通过这种分层处理技巧,一方面可以剥离出关键帧,减少存储和待处理的数据;另一方面,分层优化方法减少了每次优化时的未知量,保证该方法可扩展到大场景而漂移很小。
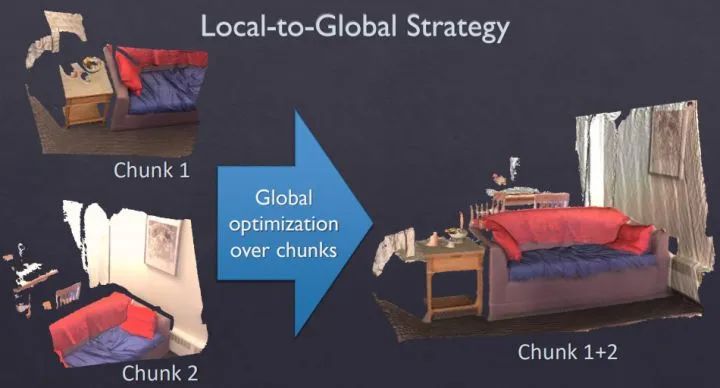
▲ local-to-global 优化策略

▲ 稀疏匹配与融合匹配效果对比 BundleFusion 方案在算法上具有明显的优点:
使用持续的local to global分层优化,去除了时域跟踪的依赖。
不需要任何显示的loop closure检测。因为每一帧都和历史帧相关,所以其实包含了持续的隐式的loop closure。
支持在GPU上实时鲁棒跟踪,可以在跟踪失败时移动到重建成功的地方进行relocalization,匹配上后继续跟踪。
实验表明,BundleFusion的重建效果确实是目前该领域效果最好的方法,下图是和其他方法的对比,重建优势明显。

BundleFusion 的良好效果除了算法的功劳,还必须有强大硬件算力的支撑。当使用两块GPU(GTX Titan X + GTX Titan Black)时,BundleFusion在各大数据集上可以达到 36 fps 左右的处理深度;当使用一块 GTX Titan X 时,处理速度则是 20 fps 左右。也即:目前算法需要两块GPU才能实时运行,因此算法的优化和加速仍是可改进的地方。


04 激光SLAM中的挑战和阶段分析


4.1 非结构化道路的SLAM问题?抑或者激光SLAM的退化特性?
在广场、机场等开阔区域,即使是多线激光,也只能看到几圈地面上的点云。仅使用地面点云进行匹配,很可能在水平面上发生随机移动。
在长隧道、单侧墙、桥梁等场地中,激光匹配会存在一个方向上的额外自由度。也就是说,沿着隧道前进时,获取到的激光点云是一样的,使得匹配算法无法准确估计这个方向上的运动。类似地,如果机器绕着一个圈柱形物体运动时,也会发生这种情况。
在一些异形建筑面前,激光可能发生意想不到的失效情形。
解决思路:建图算法适当降低激光轨迹的权重,利用其他轨迹(或者数据约束)来补偿激光的失效。


4.2 地图表达与实际环境的差异?
机器人用的栅格地图,主要表达何处有障碍物,何处是可通行的区域,此外就没有了。它具有基础的导航与定位功能,精度也不错(厘米级),制作起来十分简单,基本可以让机器人自动生成。
但除了通行区域,还有什么是需要机器人从地图中获取的环境信息?
4.3 占栅格地图和高精地图有哪些差别?
在室内,机器人可以去任意可以通过的地方,不会有太多阻拦,而对于自动驾驶来说,每条路都有对应的交通规则:有些地方只能靠右行驶,有些地方不能停车,十字路口还有复杂的通行规则。
室内机器人可以利用栅格地图进行导航,但在室外可不能在十字路口上横冲直撞。所以,在导航层面,室内与室外的机器人出现了明显的区别。室内的导航可以基于栅格来实现诸如A*那样的算法,但室外基本要依赖事先画好的车道。
但自动化的高精地图标注该如何进行和实现工程落地?
目前SLAM程序的流程大抵上都一样,基本的流程都是:
对陌生环境进行一次扫描,建立地图;
保存地图;
以后运行时,打开这张地图进行定位。
而在第一和第三流程阶段,回到文章的开头,其本质就是State Estimation in Robotics。而由此进行分析的话,受到一致认可的方向大抵有以下三类:
精度:传感器选型、传感器布局和传感器标定,但若相同的传感器“条件”,精度本质上还是由硬件决定了上限;
鲁棒性:多传感器融合,传感器差异特性互补;
效率:点云配准 & 优化计算的效率提升
05 总结
以上内容都是经过网上各位大佬的经验分享和个人简单的整理,汇整而成,本人也是十分感激能站在巨人们的肩膀上看整个SLAM技术大体样貌。望与各位技术同僚共勉,一同在SLAM技术道路上高歌猛进。 审核编辑:黄飞
-
TFT-LCD的基本原理与制造技术2012-08-20 6775
-
SLAM技术的应用及发展现状2018-12-06 15506
-
RFID技术怎么分类?基本原理是什么?2019-09-24 3563
-
磁悬浮技术基本原理是什么?2021-03-18 2778
-
CapSense技术的基本原理是什么?它有哪些应用?2021-04-21 2158
-
语音识别技术的基本原理及应用是什么?2021-05-31 5101
-
锂电池基本原理解析2021-09-15 1877
-
RAID技术的基本原理是什么2021-10-14 2594
-
VoIP的基本原理与技术2009-07-31 1374
-
3D深度传感ToF技术的基本原理解析2020-04-12 14867
-
射频技术rf的基本原理是什么2021-10-01 10959
-
深度解析PiN二极管基本原理及设计应用2022-12-21 3190
-
6.4.2.1 基本原理∈《碳化硅技术基本原理——生长、表征、器件和应用》2022-01-24 2757
-
解析压敏电阻MOV:从基础原理到应用?2024-01-24 1939
-
深度解析深度学习下的语义SLAM2024-04-23 2296
全部0条评论

快来发表一下你的评论吧 !
