

芯来科技正式发布首款专用处理器产品线Nuclei Intelligence系列
描述
本土RISC-V CPU IP领军企业——芯来科技正式发布首款针对人工智能应用的专用处理器产品线Nuclei Intelligence(NI)系列,以及NI系列的第一款AI专用RISC-V处理器CPU IP——NI900系列内核。
随着Chatgpt的横空出世,全球掀起一股AI的浪潮,从云端数据中心到边缘侧对AI的需求进一步提升。AI应用主要分布在训练和推理,需要大量的并行计算和NPU来完成,更离不开高性能CPU的算力加持。CPU有着广泛的普及性、兼容性、可扩展性和可靠性,并通过多核多节点进行串行计算、混合计算和安全防护等复杂任务;除此之外,CPU的通用矢量(Vector)指令集也可以提供强大且通用的并行计算能力,在AI领域进行高效的并行计算、前处理、后处理、激活函数等工作,更加灵活地处理GPU和NPU相对难以处理的复杂计算任务。
近期OpenAI发布的Sora模型将AI能够理解和生成的内容模态从文字和图片拓展到视频,进一步证明基础模型能力上限不断被突破,想象空间被打开,对算力基础设施的需求也远没有停止。芯来科技此次推出的NI900重点布局AI应用场景,助力本土芯片设计公司快速完成AI产品的设计。
NI900基于900系列处理器,针对“AI应用”进行了多项特性优化
基础标量处理器:
可以配置为900系列的RV32或RV64的任何一款N900、U900、NX900、UX900。
RVV1.0 VPU: 可配置基于RISC-V V Extension(RVV1.0 Vector指令集)的VPU单元,VPU的VLEN可配置为512-bit或者1024-bit。在INT8数据类型下对性能带来的提升达数百倍;在INT32与FP32数据类型下对性能带来的提升达数十倍。 NPU加速器:
可通过NI900的IOCP(IO Coherent Port)与处理器紧耦合,实现对CPU内部Cache的一致性。
用户自定义指令扩展接口: 用户可以使用Nuclei的NICE硬件扩展接口,增加自己自定义的指令,包括Scalar或Vector指令。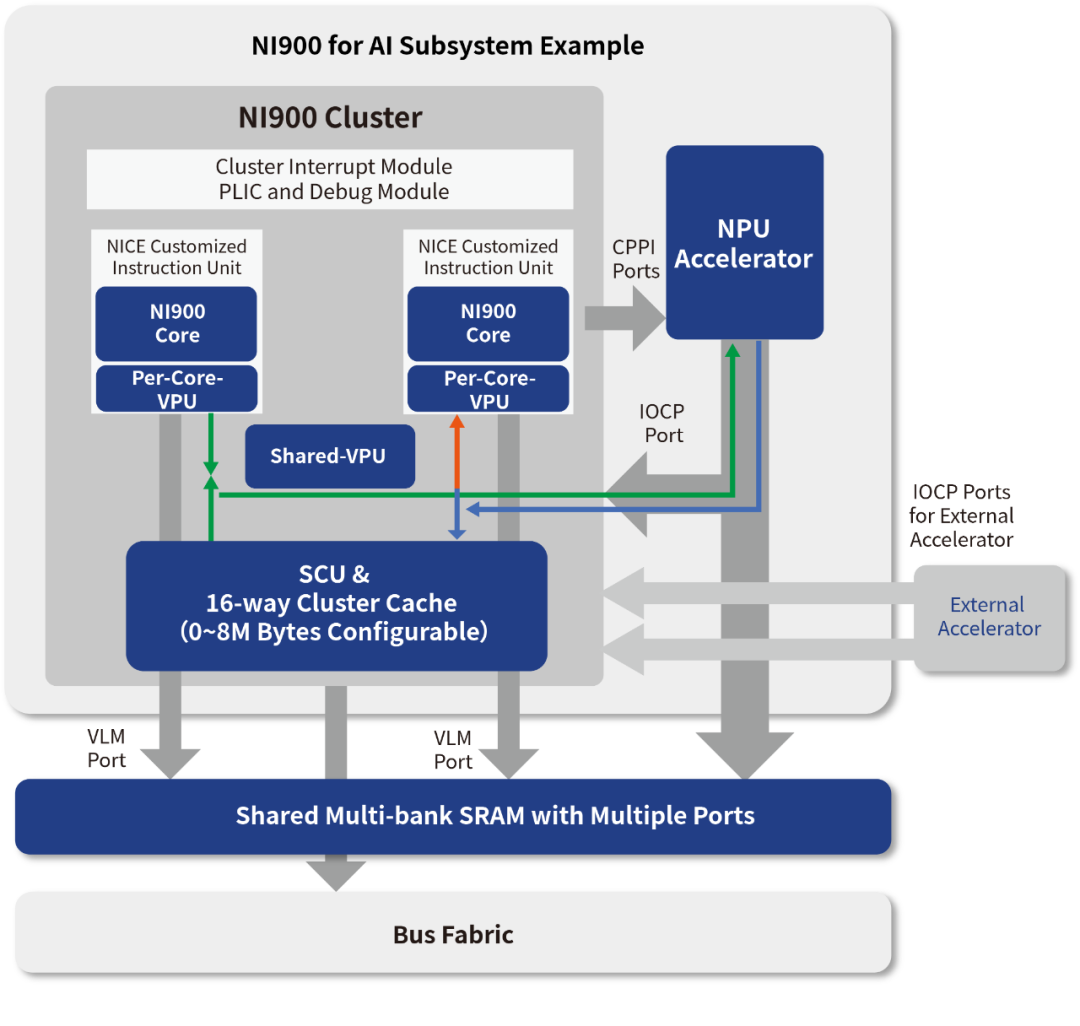
NI900支持RISC-V Vector1.0标准
矢量扩展被称之为RV指令集标准最重要的一组扩展,2015年发起,2021年正式生成标准。
RVV 1.0支持的数据类型广泛,运算类型丰富且可动态扩展,同一套指令可无修改适配各种微架构实现。
RISC-V GCC从10.2版本已经支持RVV1.0指令,目前GCC13对应的intrinsic API接口已经升级到最新v0.12版本,且已部分支持自动向量化;预计GCC14正式发布,GCC的自动向量化会更加完备。RISC-V CLANG17版本也已支持最新v0.12版本intrinsic APl, 支持自动向量化。
RISC-V Linux 5.18 版本开始支持RVV,其它各种计算库及应用中间件都快速支持了RVV1.0。
有了RVV1.0标准和软件生态的完备,为应对AI算力的需求,需要RISC-V CPU 在微架构设计上做更多有针对性的设计。
NI900拥有强大的并行计算能力
RVV参数描述:
VLEN:一个向量寄存器的总bit数(宽度)
DLEN:内部运算单元能够并行处理的一个向量元素的最大bit数
ELEN:并行处理的数据类型的最大宽度,如果ELEN=32,则最大的处理数据类型是INT32和FP32
| 可配选项 | 参数值 |
| VLEN_512 | VLEN=512, DLEN=512,ELEN=32/64 |
| VLEN_1024 | VLEN=1024, DLEN=1024,ELEN=32/64 |
VPU支持的数据类型和计算能力:
1024-bit的VPU支持多种数据类型的计算,包括:INT8 / 16 / 32 / 64, BFP16 / FP16 / FP32 / FP64。
1024-bit的VPU支持每个时钟完成128x8-bit / 64x16-bit / 32x32-bit / 16x64-bit的数据计算
NI900拥有强大的Memory读写能力
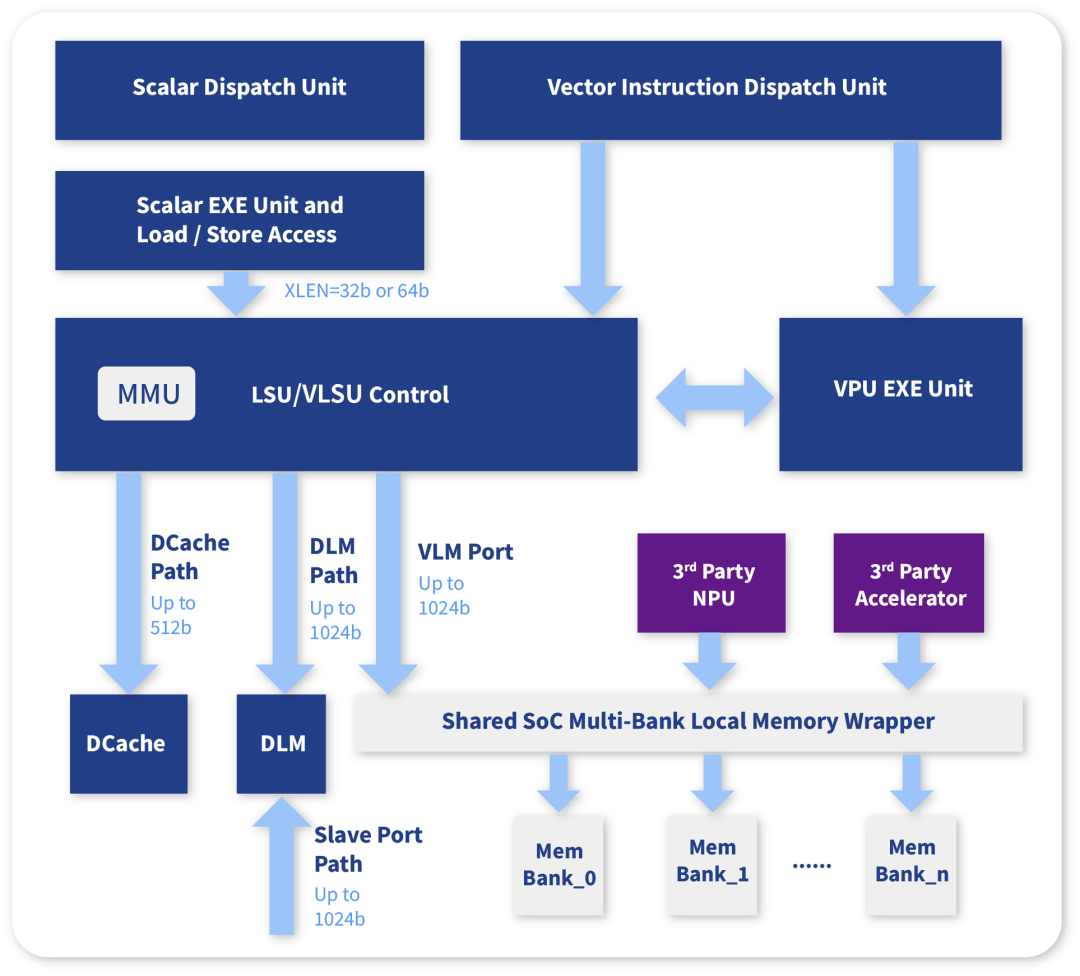
VPU和Core LSU共享MMU资源
VPU并非独立的协处理器,而是与主Core的内存空间实现完全的Coherent
Vector指令与普通Scalar一样,支持虚拟地址访问,使得NI900的Vector指令可以无缝运行于大型操作系统之上
VPU和Core LSU共享Memory资源与通道
VPU拥有最高512-bit位宽直接访问DCache
VPU拥有最高1024-bit位宽直接访问DLM
DLM具备1024-bit的Slave Port供SoC访问
可单独配置VLM port以进一步增加性能
VLM port可以直接连接到外部加速器或者内存
VLM port位宽=VLEN(目前支持最多1024-bit)
Scalar Core也可以通过Load Store访问到VLM区间
NI900的VPU带来极大的性能提升
通过强大的运算能力与强劲的Memory读写通道,NI900能带来极大的并行计算性能提升。
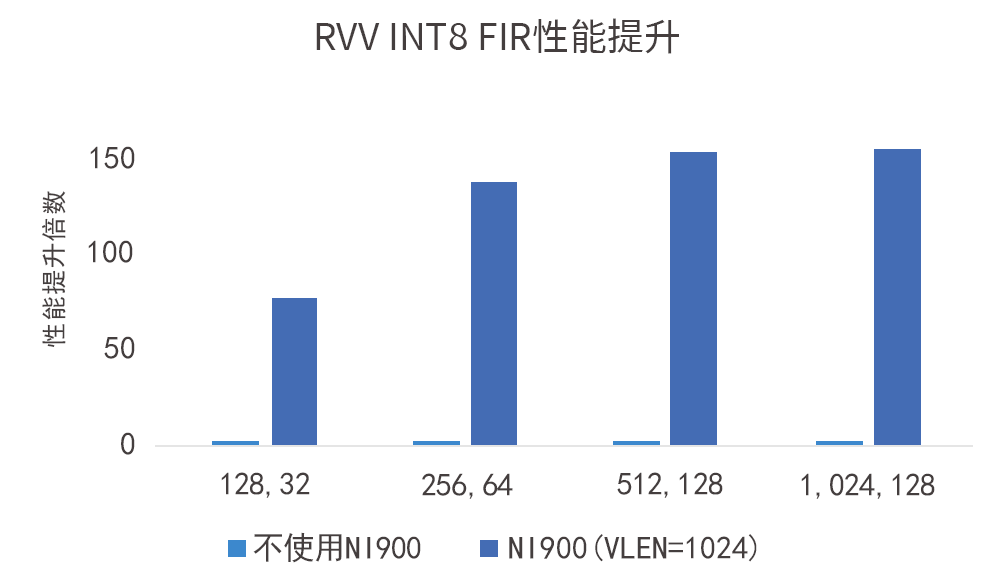
如图所示,VLEN=1024-bit的VPU在INT8数据类型下对性能带来的提升达数百倍:
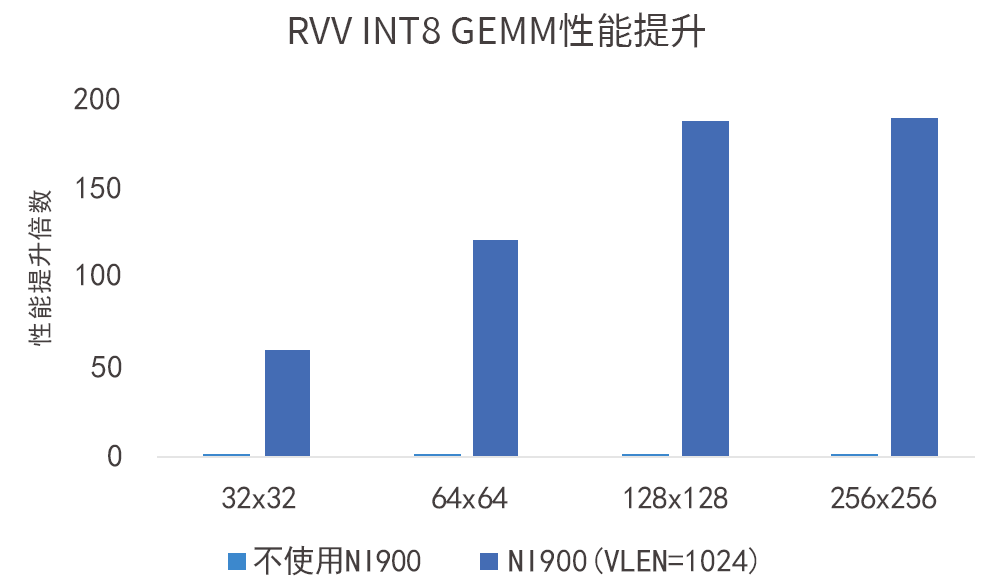
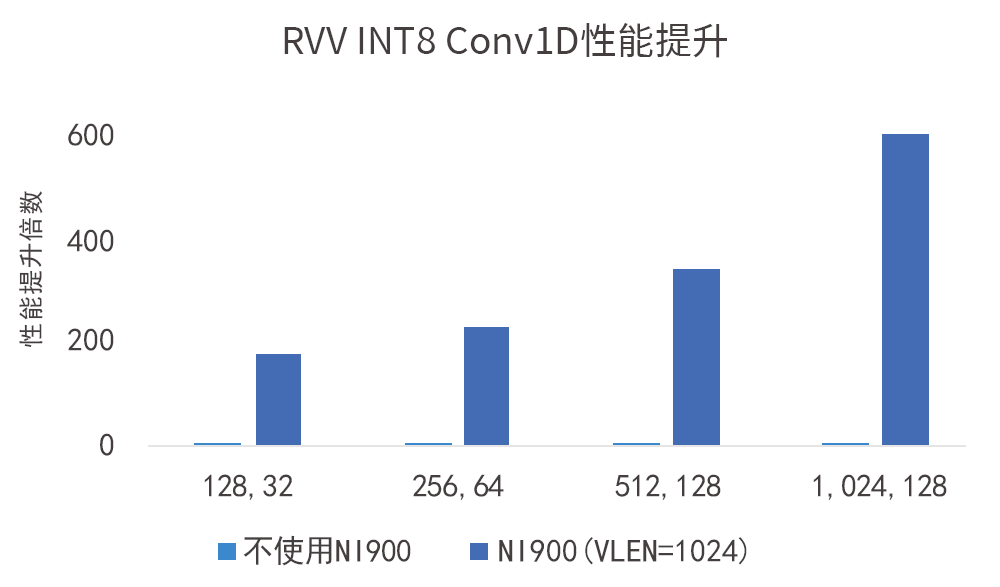
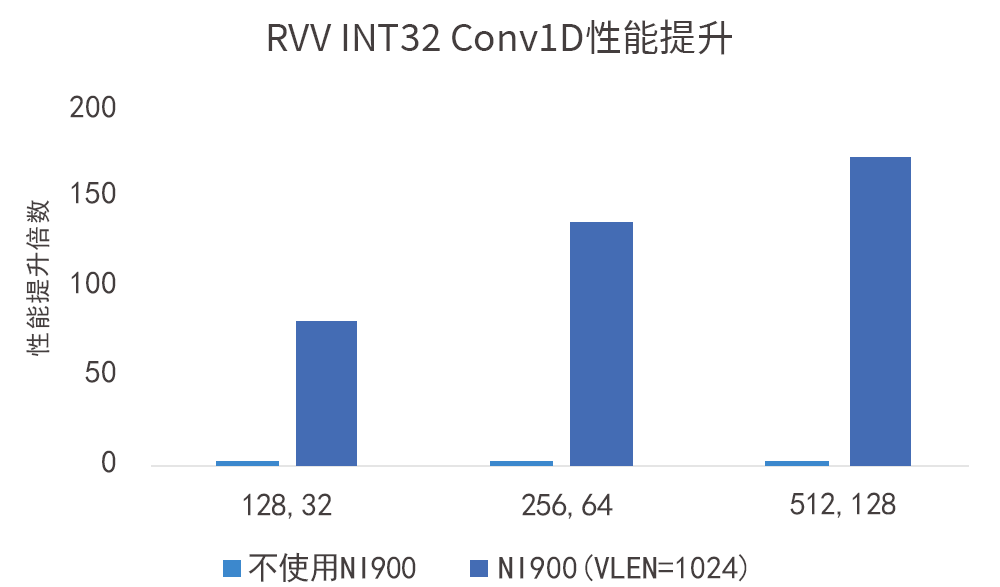
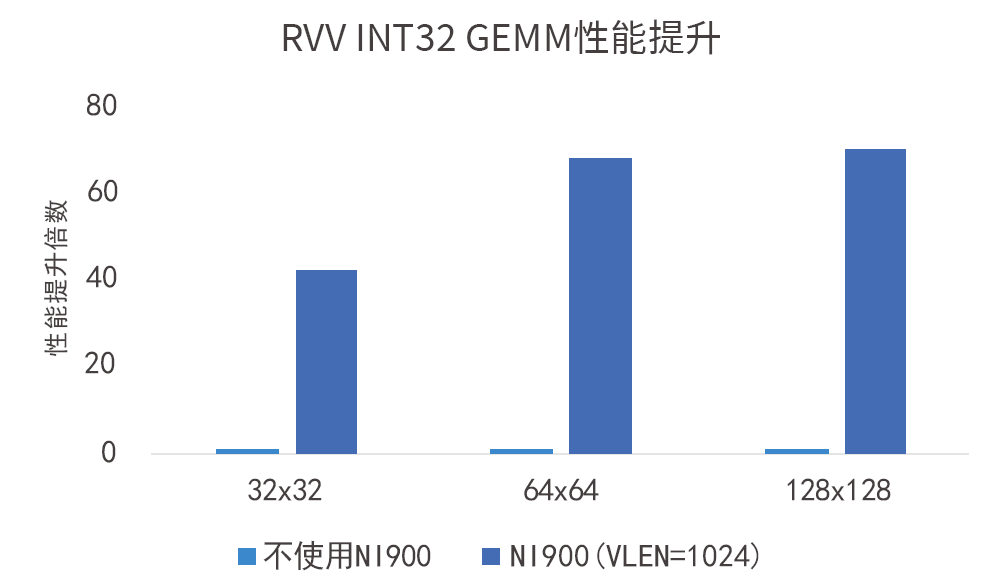
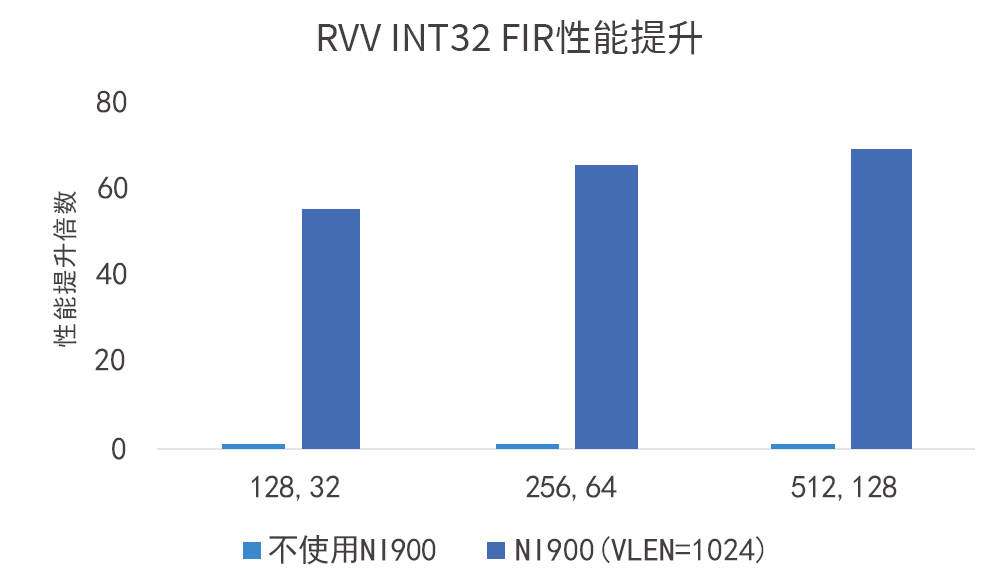
如图所示,VLEN=1024-bit的VPU在INT32数据类型下对性能带来的提升达数十倍:
如图所示,VLEN=512-bit的VPU在FP32数据类型下对性能带来的提升达数十倍:
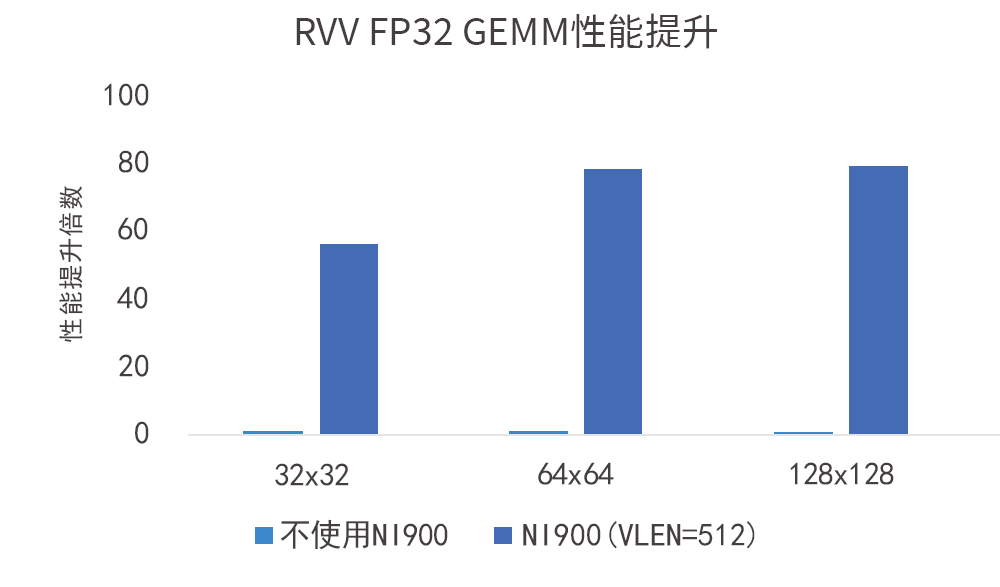
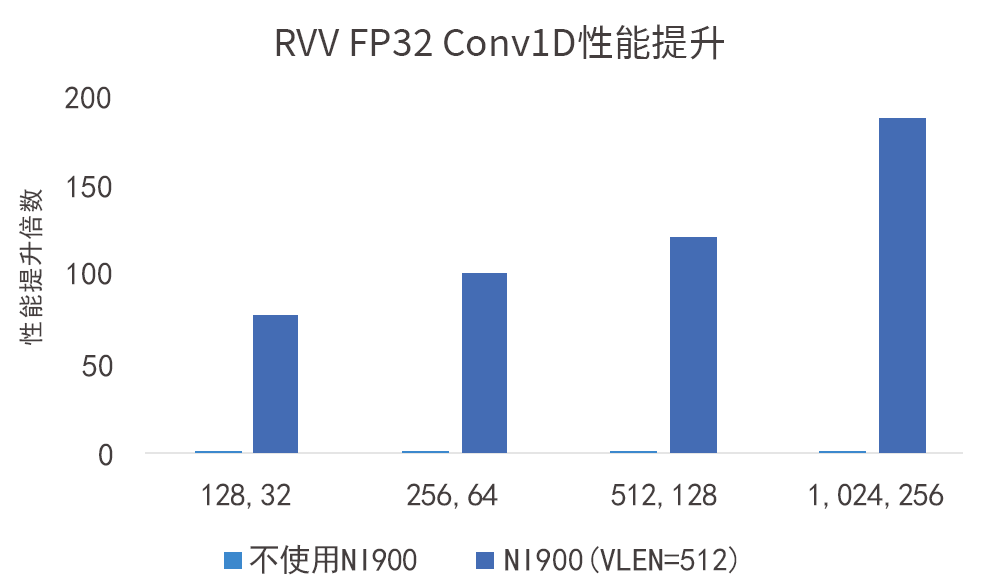
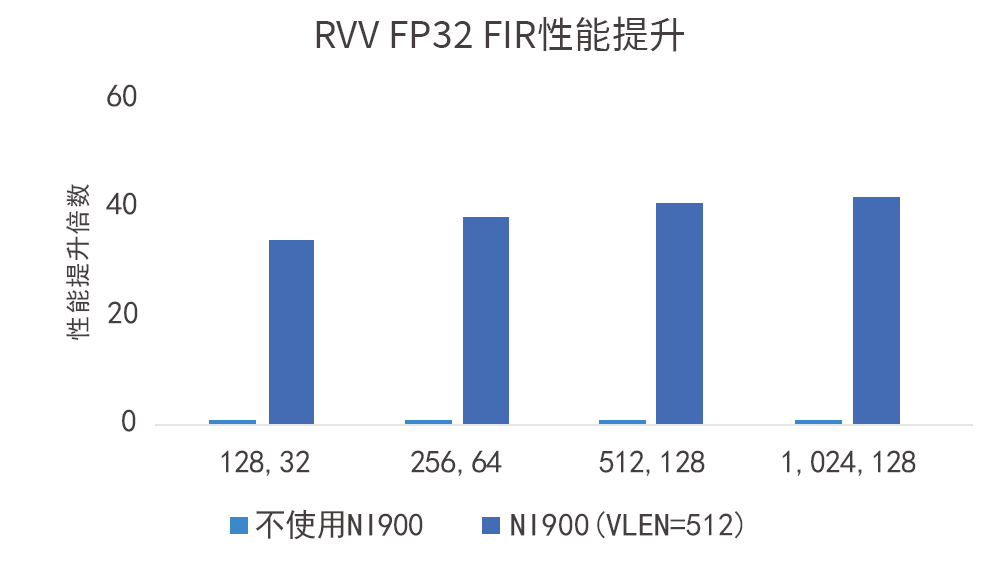
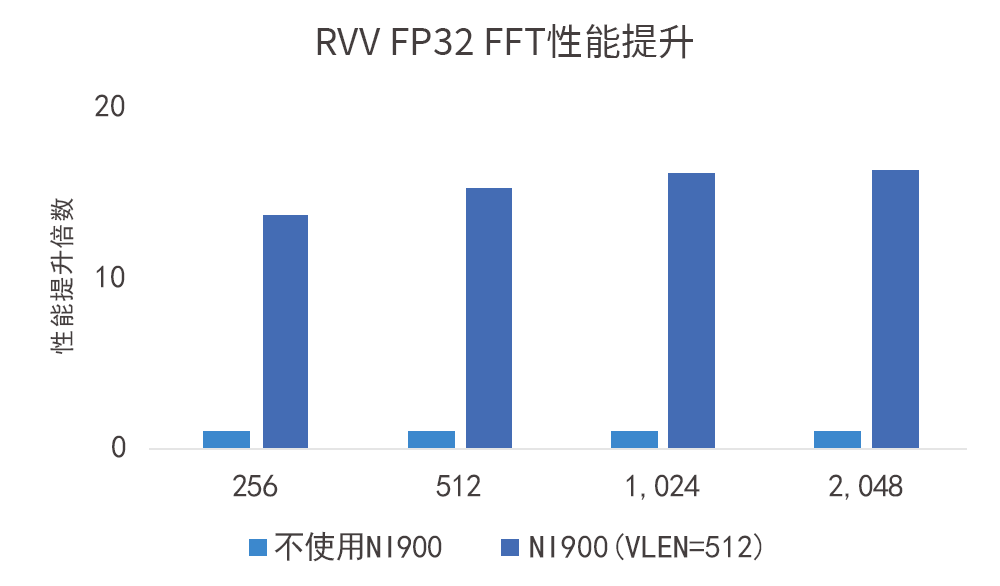
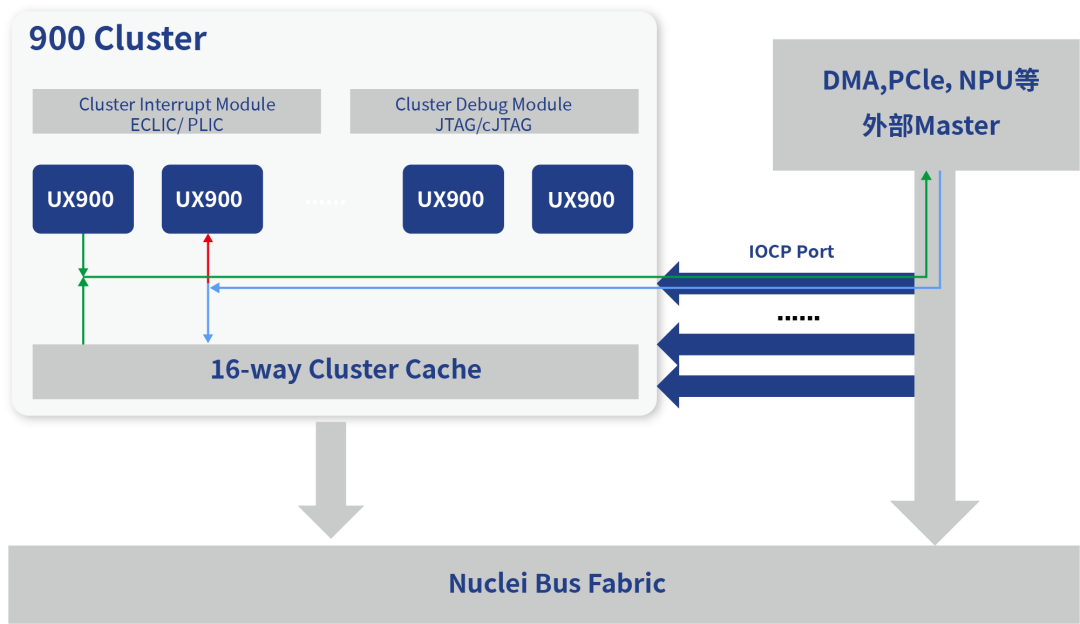
NI900支持NPU等AI加速器与处理器紧耦合,实现对CPU内部Cache的一致性
NI900支持整合外部AI加速器、NPU、PCIe、DMA,通过900系列的IOCP(IO Coherent Port)与900系列处理器紧耦合,实现对CPU内部Cache的一致性。
NI900的Scalar/Vector NICE自定义指令接口提供更多特定场景的优化可能性 NICE(Nuclei Instruction Co-unit Extension)是芯来CPU IP的一种用户可扩展指令接口机制,允许用户基于芯片的标准通用CPU内核定义自己的扩展指令集。
NI900提供用于Scalar指令扩展的NICE接口,可支持单周期,多周期,流水线等不同指令类型
NI900提供用于Vector指令扩展的NICE接口,可支持单周期,多周期,流水线等不同指令类型
NI900的NICE扩展单元不仅可以进行运算型的自定义指令扩展,还可以通过专用总线访问Core的存储资源(DCache等)实现与主Core的内存一致性,总线位宽可以达到VLEN(最高1024-bit)
用户可以结合自己的应用扩展自定义指令,将NI900处理器内核扩展成为面向AI领域进一步强化的专用处理器。
RISC-V生态日益成熟,芯来NI900赋能AI时代
CPU是算力结构中必不可少的一个环节,在已经到来的人工智能算力时代,通用和专用芯片结合而成的异构计算是未来AI算力基础设施的主流。芯来致力于提供标量、矢量、以及自定义指令结合的计算架构,以满足端侧云侧数据中心的多元化的算力需求。
目前NI900已经获得多家下游客户的认可并投入产品设计中,未来芯来将推出更多NI系列处理器内核IP,赋能AI时代的算力基础设施建设。
审核编辑:刘清
-
专用处理器,未来电机驱动的主流2015-12-31 5344
-
小米首款自主处理器发布 会成功吗?2017-03-02 8034
-
采用专用处理器实现电机驱动方案2019-07-26 3070
-
全志科技正式发布首款AI语音专用芯片R3292020-11-23 2753
-
兆芯处理器首款国产16纳米CPU性能匹敌7代i52019-05-08 9384
-
CEVA的智能传感技术适用于边缘AI计算的专用处理器2020-07-23 1271
-
芯来科技软件平台发布2020.09版本2020-09-25 2674
-
ARM中国发布首款ISP玲珑监控系统2020-12-04 2712
-
芯来科技发布Nuclei Studio 2022.04版本2022-04-02 4495
-
阿里云正式发布云数据中心专用处理器CIPU2022-06-13 2369
-
芯易荟发布首款领域专用处理器生成工具FARMStudio2023-04-12 1553
-
什么是专用处理器?专用处理器的设计方法和工具介绍2023-07-17 2429
-
芯来科技发布AI专用RISC-V处理器内核NI900系列2024-02-26 2402
-
芯来科技正式发布基于RISC-V处理器的HSM子系统解决方案2024-03-11 3182
-
恩智浦全新i.MX 93W应用处理器重磅发布2026-03-16 2706
全部0条评论

快来发表一下你的评论吧 !
