

“网红”芯片Groq让英伟达蒸发5600亿
描述
前言: 鉴于ChatGPT的广泛应用,引发了AI算力需求的迅猛增长,使得英伟达的AI芯片供不应求,出现大规模短缺。如今,英伟达似乎在面对更多挑战。
比英伟达GPU快10倍的LPU
近两天,一家名为Groq的美国人工智能公司受到了广泛关注,其主要原因在于其自主研发的LPU芯片在人工智能推理技术上取得了突破。
通过优化架构和减少内存瓶颈,Groq的LPU芯片在大模型处理方面展现出高效率和低延迟的特点,速度远超英伟达GPU,每秒生成速度接近500 tokens,而GPT-4仅40 tokens。
因此,Groq LPU被誉为[史上最快的大模型技术]。
Groq LPU的工作原理与英伟达的GPU不同,它采用了名为时序指令集计算机(Temporal Instruction Set Computer)架构,使用存储器为静态随机存取存储器(SRAM),其速度比GPU所用的高带宽存储器(HBM)快约20倍。
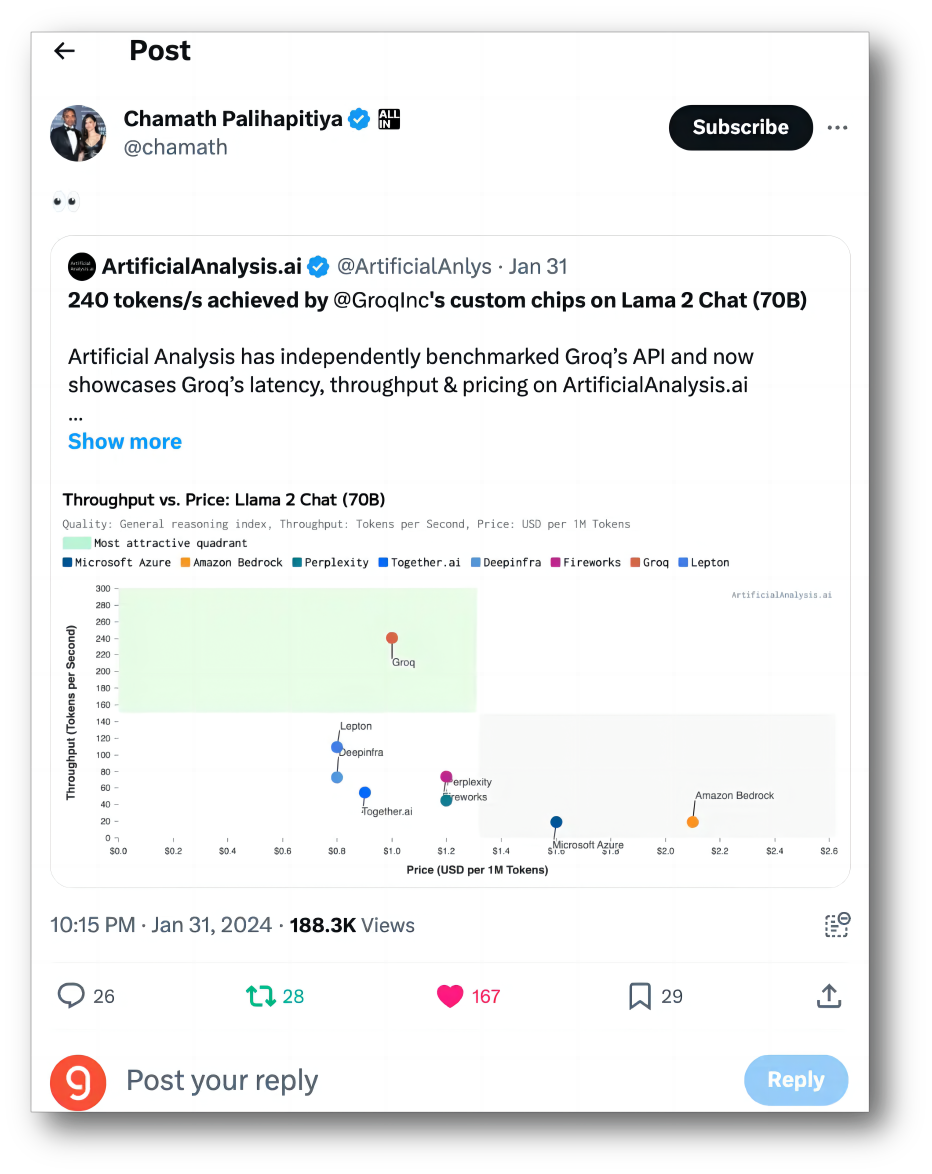
据Groq在2024年1月的第一个公开基准测试,由Groq LPU驱动的Meta Llama 2-70B模型,推理性能比其他顶级云计算供应商快18倍。
artificialanalysis.ai给出的测评结果也显示,Groq的吞吐量速度称得上是[遥遥领先]。
总结起来,Groq的架构建立在小内存,大算力上,因此有限的被处理的内容对应着极高的算力,导致其速度非常快。
有分析人士称,在A100和H100相对紧缺的时代,LPU或许会成为大模型开发商的新选择。
Grop部署起来甚至比英伟达要贵
当初Groq以其闪电般的速度令AI行业为之震撼。
然而,在震撼之余,许多业界人士核算后发现,这种速度背后的代价可能过于高昂。
Groq的LPU芯片摒弃了HBM,仅依赖SRAM进行计算。
尽管这种方式确实带来了令人瞩目的计算速度,但其成本效益问题却备受质疑。
值得关注的是,尽管Groq在速度上表现出色,但其背后的成本却相当高昂。
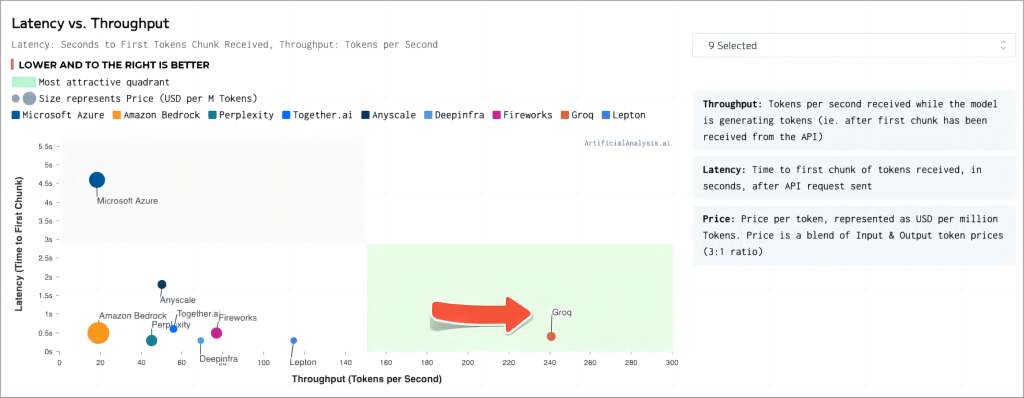
若以未来三年运行成本计算,Groq的硬件采购成本高达1144万美元,而运营成本至少为76.2万美元。
据此估算,在同等吞吐量下,Groq的硬件成本约为H100的40倍,能耗成本则是10倍。
若考虑运营三年,Groq硬件的购买成本为114.4万美元,运营成本为76.2万。
另一方面,对于一个8卡的H100盒子,硬件购买成本为30万美元,运营成本约为7.2万或稍低。
由于Groq内存容量相对较小(230MB),在运行Llama-270b模型时,需配备305张Groq卡才能满足需求,而使用H100仅需8张卡。
因此,从当前价格来看,在同等吞吐量下,Groq的硬件成本是H100的40倍,能耗成本是10倍。
换言之,Groq的高速性能是建立在有限的单卡吞吐能力基础之上的。
为实现与H100相同的吞吐量,Groq需采用更多张显卡。
在此背景下,[速度]成为了Groq的一把双刃剑。
Groq喊话[三年内赶超英伟达]
近期,一位自称为Groq员工的用户在与网络用户互动时表示,Groq致力于成为最快速的大规模模型硬件,并誓言在三年内超越英伟达。
然而,截至2月20日美股收盘,英伟达股价单日跌幅达4.35%,创下去年10月以来最大单日跌幅,市值一夜之间缩水780亿美元(约合5600亿元人民币)。
尽管Groq速度迅猛,但价格较高,目前尚不能与英伟达抗衡。SRAM技术面积大、功耗高,早已以IP内核形式集成至系统级芯片(SoC),而非单独应用,其未来发展潜力远不及HBM(高带宽内存)。
在单位容量价格、性能及功耗方面,英伟达GPU所采用的HBM技术均优于SRAM。
从技术和性能角度看,Groq目前尚无法撼动英伟达的地位。
原因在于,英伟达GPU产品具有通用性,而Groq产品为ASIC(专用集成电路),并非通用产品,而是定制产品。
换言之,任何人工智能算法均可使用英伟达的H200,但仅Mixtral和Llama2能采用Groq的LPU。
欲使用Groq产品,大模型公司需先明确需求、指定规格,然后进行功能验证,最终生产出的产品方可投入使用。
英伟达财报再次印证了其在人工智能浪潮中成为最大赢家的地位。
英伟达于北京时间2月22日发布截至2024年1月28日的四季度业绩报告。
报告显示,公司季度营收创纪录达到221亿美元,远超英伟达自身及华尔街预期,同比增长265%。
全年营收同样创下新高,达到609亿美元,同比增长126%。
英伟达预计本季度营收将进一步攀升至240亿美元。财报发布后,其股价盘后一度涨超10%。
结尾:
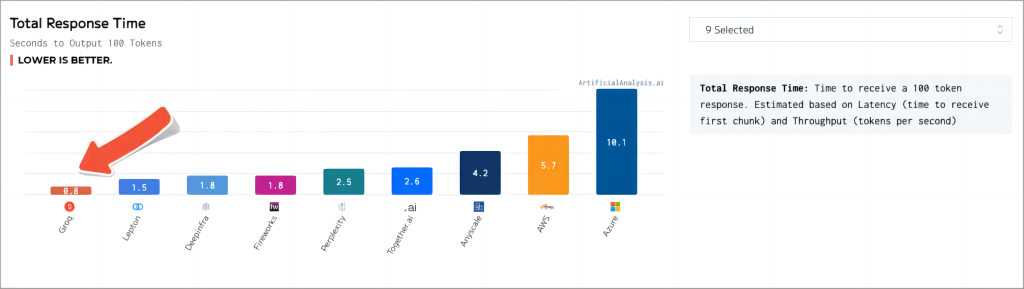
Groq架构的特点是小内存和大算力,适合频繁数据搬运的场景,速度快但单卡吞吐能力有限,需要更多卡来保证同等吞吐量,速度既是优势也是劣势。
此外,由于GPU的生态极为发达,其中英伟达的GPU不仅性能强大,在性能卓越的同时,还聚集了大量用户和丰富的生态环境。
相比之下,Groq 目前仅能为少数大型模型提供服务,想要在低延迟领域建立持续优势,需要拓宽服务范围并进一步减少总体成本。
审核编辑:刘清
-
英伟达重磅出手!AI 推理存储全面觉醒2025-12-26 12425
-
英伟达市值一夜蒸发近2万亿 英伟达股价下跌超8%2025-03-04 1312
-
英伟达市值蒸发近2000亿美元2024-08-30 1230
-
AI芯片巨头英伟达涨超4% 英伟达市值暴增7500亿2024-08-13 2132
-
英伟达或面临重大技术性抛售 英伟达市值一夜蒸发1.4万亿2024-07-31 1849
-
Groq筹资约3亿美元,向Cerebras等对手看齐2024-05-23 1206
-
英伟达市值一夜蒸发6116亿元2024-04-18 1207
-
英伟达一天蒸发近万亿 英伟达市值蒸发超9200亿元2024-03-10 2753
-
英伟达要小心了!爆火的Groq芯片能翻盘吗?AI推理速度「吊打」英伟达?2024-03-08 2454
-
刷屏的Groq芯片,速度远超英伟达GPU!成本却遭质疑2024-02-22 5212
-
英伟达市值蒸发310亿美元 英伟达收跌约2.7%2023-12-05 2269
-
英伟达市值一夜蒸发3700亿元2023-08-10 3103
-
英伟达DPU的过“芯”之处2022-03-29 5961
-
英伟达GPU惨遭专业矿机碾压,黄仁勋宣布砍掉加密货币业务!2018-08-24 4312
全部0条评论

快来发表一下你的评论吧 !
