

以太网存储网络的拥塞管理连载方案(三)
描述
第 3 层优先权流量控制
在 OSI 模型的第 3 层,流量由 IPv4 或 IPv6 源地址和目标地址标识。如图 7-5 所示,IP 标头(v4 和 v6)包含一个 6 位 DSCP 字段,允许多达 64 种分类,但并非所有分类都被使用。
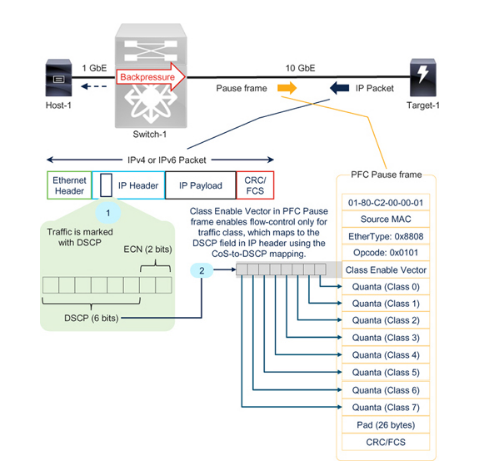
Figure 7-5 IP 数据包的 DSCP 字段与 PFC 暂停帧中的类启用向量之间的关系
但 PFC 暂停帧只携带八个流量类别的quanta值,因此需要进行映射(表 7-1)才能成功实现第 3 层 PFC。这就是所谓的 CoS 到 DSCP 或 DSCP 到 CoS 映射。
在图 7-5 中,Host-1、Switch-1 和 Target-1 同意将 CS3 用于无损流量。目标-1 在 IP 头中标记 DSCP 值 24(二进制 CS3 或 011000)。Switch-1 将 CS3 标记的 IP 数据包(请参阅表 7-1 中的映射)分配到一个无损队列。当该队列超过暂停阈值时,Switch-1 会发送一个类启用向量为 00001000 的 PFC 暂停帧。因此,Target-1 会停止传输 CS3 标记的 IP 数据包,而不会影响其他类别的流量。要使 CS4 流量也能实现无损行为,类启用矢量应为 00011000。
Table 7-1 以太网 VLAN CoS 和 IP DSCP 映射
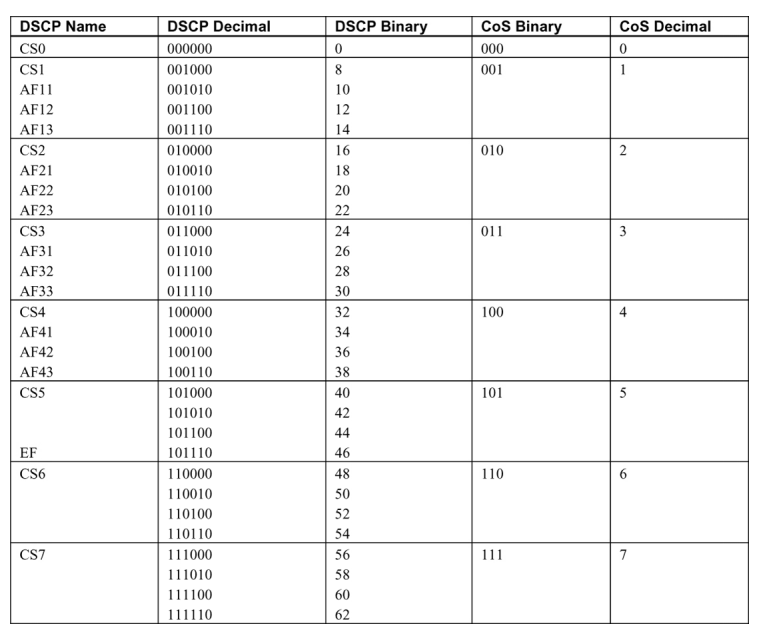
要了解 Cisco Nexus 9000 交换机上的默认 CoS 到 DSCP 和 DSCP 到 CoS 映射,请使用 NX-OS 命令 show system internal ipqos global-defaults。
融合以太网网络
如第 1 章所述,在同一网络中允许有损和无损流量的以太网网络在本书中称为融合以太网网络。除 PFC 外,融合以太网网络还需要以下功能:
Bandwidth guarantee: 当无损流量和有损流量共享以太网链路时,必须合理分配带宽,以免一种流量消耗掉链路的全部容量,导致另一种流量处于饥饿状态。带宽保证通过增强传输选择(ETS)来实现,这是一项 IEEE 标准(IEEE 802.1Qaz)。
Consistent configuration: 要成功运行 PFC,直接连接的设备必须对无损和有损流量的定义以及带宽的保证程度有一致的理解。要在所有网络设备上一致地进行这些更改,手动操作既慢又容易出错。更好的方法是在直接连接的设备中使用自动发现功能。数据中心桥接交换(DCBX)提供这种发现和广告功能,它是一种 IEEE 标准(IEEE 802.1Qaz)。DCBX 是另一个 IEEE 标准(IEEE 802.1AB-2005)--链路层发现协议(LLDP)的扩展。
PFC、ETS 和 DCBX 属于 IEEE 标准类别,称为数据中心桥接 (DCB)。它还有许多其他名称,如数据中心以太网(DCE)、聚合以太网(CE)、聚合增强以太网(CEE)等。
请注意,某些文献中使用的术语--融合网络或融合以太网网络--指的是不考虑无损行为而承载存储和非存储流量的网络。不过,本书将此类网络称为共享存储网络。共享存储网络的一个子类别是聚合网络,即配置为同时传输有损和无损流量的网络。例如,当网络传输无损 RoCE 和有损 HTTP/Web 流量时,它被称为共享存储网络和聚合网络。当网络承载有损 iSCSI 和有损 HTTP/Web 流量时,它被称为共享存储网络,而不是聚合网络。如果你的理解不同,本书无意改变。不过,本书使用聚合网络来表达网络承载有损和无损流量,因此启用了 PFC、ETS 和(大部分)DCBX。
配置无损以太网
与默认启用 B2B 流量控制的光纤通道不同,配置以太网流量控制需要额外的步骤,并需要了解服务质量 (QoS) 和模块化 QoS CLI (MQC)。这些配置细节不在本文讨论范围之内。有关这些主题的深入教学内容已在参考文献部分列出。为便于理解,本章仅对 QoS 概念进行了简化解释,并特意忽略了实施细节。
启用 PFC 需要以下步骤:
1. Classifying and marking the traffic: 对流量进行分类和标记是第一步,因为各种类型的流量(如存储、语音、视频、网络和 FTP)都可能在同一个端口上。分类是通过第 2 层的以太网 VLAN CoS 字段实现的。在第 2 层边界之外或帧未标记 VLAN 时,则使用 IP 报头中的 DSCP 字段。终端设备可以在向网络发送帧之前对其进行标记,网络可以信任这些标记。另外,边缘交换端口也可以自行对数据包进行分类和标记。
2. Flow-control and bandwidth allocation: 分类后,必须确定哪些流量需要无损行为,哪些流量需要有损行为。无损流量由 PFC 进行流量控制。如前所述,由 PFC 进行流量控制的流量类别称为无无损类别。交换端口还必须为无损类提供带宽保证,如链路容量的 50%。其他类别的流量不受流量控制,但仍可保证其带宽。不丢弃类中的流量变为无损,而所有其他类中的流量保持不变(有损)。
3. Consistent implementation: 最后,QoS 配置必须在所有终端设备和交换机上一致应用。例如,如果一台交换机为 CoS 3 启用了无损行为,而同一网络中的另一台交换机却为 CoS 4 启用了无损行为,那么结果将是无损流量变成有损流量。此外,QoS 配置错误还可能导致拥塞和更多问题。如前所述,DCBX 或软件定义网络技术可以简化实施过程。
配置这些步骤取决于交换机类型及其架构,通常需要一定的学习时间。虽然使用自动化或图形用户界面可以简化配置,但排除拥塞问题需要了解实现这些功能的命令。
请注意以下有关配置无损以太网的要点:
1. 我们建议使用供应商提供的 QoS 配置,而不是自定义配置。如果供应商文档中使用 CoS 3 作为不丢弃类,那么最好在您的环境中使用相同的分类。虽然从技术上讲可以更改分类,但与供应商文档保持一致可使您的环境与全球其他部署保持一致。用户可以直接复制/粘贴配置命令,而且在故障排除过程中,他们不必记住无损类的不同 CoS 值。
2. 正如前面 "暂停阈值 "和 "恢复阈值 "部分所述,我们建议避免更改默认或供应商建议的数据中心内短距离链路暂停阈值和恢复阈值的 PFC 配置。自定义这些值需要了解设备的缓冲区分配和队列架构。如果更改不当,可能会导致暂停帧延迟发送或在需要时提前发送,从而导致性能下降。不过,长距离无损以太网链路需要更改这些阈值。
3. 根据设备的用例和能力,可能会有多个无损类别。例如,一个无损类用于 FCoE,而另一个无损类用于 RoCEv2。在这种情况下,一个无损类中的流量控制不会干扰其他无损类中的流量控制。PFC 暂停帧中的 "类启用矢量"(Class Enable Vector)可启用相应流量类的位及其量值。
4. 在配置将流量类别(DSCP)分配到不丢弃队列后,交换机会对所有标记了 DSCP 值的数据包使用逐跳流量控制。如果终端设备错误地标记了数据包,交换机将无法得知,并将有损流量分配到无损队列,或将无损流量分配到有损队列。
本书将无损类别的流量称为无损流量,将其他流量称为有损流量,而不考虑分类、标记、带宽分配和特定设备的实施细节。
专用和融合以太网网络
将网络配置为融合以太网网络(有损和无损流量)并不一定意味着有损和无损流量可以同时运行。例如,假设你配置了一个网络,50% 的带宽分配给无损流量,50% 的带宽分配给其他流量。如果当时没有无损流量,那么在数据层,该网络与其他有损以太网网络没有任何区别。另一方面,如果无损类中没有流量,该网络就会像专用无损网络一样运行。换句话说,它 "配置 "为融合网络,但 "运行 "为专用网络。
请看下面的例子。
1. Cisco UCS Servers: Cisco UCS 服务器使用融合以太网在同一链路上传输无损(光纤通道和 RoCE)和有损(TCP/IP)流量。但是,如果没有服务器通过光纤通道或 RoCE 使用存储,则内部链路将永远不会报告 "暂停 "帧,尽管聚合以太网的配置仍应用于这些链路。有关 Cisco UCS 服务器的更多详细信息,请参阅第 9 章 "Cisco UCS 服务器中的拥塞管理"。
2. FCoE on Cisco MDS Switches: 虽然 Cisco MDS 交换机上的 FCoE 端口是为融合以太网配置的,但它们只能处理无损流量,不能发送/接收有损类流量。
需要了解的关键一点是,即使是专用无损网络,其配置也与融合网络相同。上一节中解释的流量分类、带宽保证、流量控制等配置在这两类网络中都适用。不过,流量模式使两者有所不同。对于拥塞检测和故障排除,第一步是验证配置,这对两种类型的网络都是一样的。下一步是关注流量模式,这取决于网络是只传输无损流量(专用),还是同时传输无损和有损流量(融合)。
了解无损以太网网络中的拥塞问题
无损以太网网络容易出现与光纤通道结构类似的拥塞,因为两者都在直接连接的设备之间使用流量控制。而且,这种拥塞会向流量源蔓延,使许多共享相同网络路径和流量类别的其他设备受害。
第 1 章 "存储网络中的拥塞--概述 "一节解释了拥塞传播的基本原理以及拥塞的各种原因和来源。本节将进一步阐述无损以太网网络中的这些基础知识。
慢速排空
与流量传输速率相比,处理速率较慢的终端设备称为慢排泄设备,由此造成的拥塞称为慢排泄。这种终端设备使用暂停帧来控制入口流量速率。这通常会导致该设备发送过多的暂停帧。这些帧在其连接的交换端口上被报告为入口暂停帧。
过度使用链接
当交换端口以最大速度传输数据,但传输的帧数超过了该链路的传输能力时,就会出现因过度使用而导致的拥塞。交换机会使用暂停帧来控制通过过度利用链路发送流量的上游设备的流量速率。这将导致高利用率或充分利用链路,而链路正是拥塞和向上游设备发送过多暂停帧的根源。
比特错误
比特错误可能干扰 LLFC/PFC,导致拥塞或使现有拥塞恶化。当流量发送端在接收到的暂停帧中检测到 CRC 错误时,会丢弃已损坏的暂停帧,因此不会停止流量。下一个有效的暂停帧应能停止流量,但当下一个暂停帧停止流量时,缓冲区空间可能已满。这可能会导致不丢帧类中的丢帧。
位错误的另一个重要影响是 FCoE Fabric 的性能,因为即使只有一个数据包被丢弃,整个 I/O 操作也会重新启动。第 1 章 "链路上的位错误 "一节解释了这一概念。
由于这些原因,应尽快检测位错误,找到其根本原因,并进行纠正更改。
单交换机无损以太网网络中的拥塞蔓延
请参阅图 7-6 中的单交换机无损以太网网络,该网络连接 40 台主机和 8 个目标。每台主机通过无损类中的所有 8 个存储端口访问存储。在无损类中,主机之间不进行通信。同样,目标也不会在无损类中相互通信。所有设备都与无损类之外的其他设备通信。
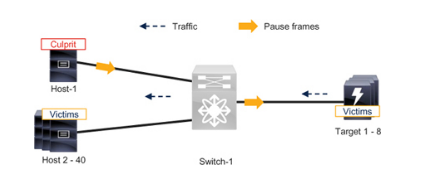
Figure 7-6 单交换机无损以太网网络中的拥塞问题
当主机(Host-1)成为慢排泄设备时,它会通过发送暂停帧来降低入口流量的速率。交换机可以缓冲一些帧,但最终其队列会超过暂停阈值,因此会向八个目标发送暂停帧,以降低它们的速度。
这是意料之中的行为。但它也有副作用。PFC 会减慢无损类中的所有流量,无论流量目的地是哪里。因此,其他 39 台服务器即使没有调用 PFC,也会受到影响。
最后,在这个拥有 40 台主机和 8 个目标的单交换机网络中,一台罪魁祸首主机就能使所有其他设备受害。这种无损以太网网络中的拥塞扩散效应与类似的光纤通道结构并无不同,因为两者都使用逐跳流量控制。
正如第 4 章 "故障排除光纤通道 Fabric 中的拥塞 "中 "识别受影响的设备(受害者)"一节所述,目标是直接受害者,因为它们与主机 1 直接通信。主机 2 - 40 是间接受害者,因为它们与直接受害者(目标)进行通信。
边缘核心无损以太网网络中的拥塞蔓延
接下来,请看图 7-7,图中显示了一个具有三个主机边缘交换机和一个核心交换机的边缘-核心网络。每个主机边缘交换机连接 200 台主机,存储边缘交换机连接 100 个目标。存储流量保持在无损类。在无损类中,主机之间不进行通信。同样,目标也不会在无损类中相互通信。所有设备都与无损类之外的其他设备通信。
当主机成为慢耗设备时,它会通过发送暂停帧来降低入口流量的速率。主机边缘交换机可以缓冲一些帧,但最终其队列会超过暂停阈值,因此它会向核心交换机发送暂停帧。这将减慢该边缘交换机与核心交换机之间所有不丢弃类流量的速度,无论流量目标是什么,这将影响连接到同一边缘交换机的多达 199 台主机。
此外,核心交换机可以缓冲一些帧,但最终其队列也会超过暂停阈值,因此它会向在拥塞 ISL 上发送流量的所有目标发送暂停帧。这些目标会减慢无损类中的流量,而不管流量的目的地是什么,这些目的地可能是连接到任何主机边缘交换机的任何主机,甚至是连接到存储边缘交换机的主机(图 7-7 中未显示)。
因此,一台故障设备会使整个网络中的许多设备受害。在这个无损以太网网络中,拥塞扩散的效果与在类似光纤通道结构中观察到的效果相同。将图 7-7 与第 6 章 "网络设计注意事项 "一节中的示例进行比较。
正如第 4 章 "识别受影响设备(受害者)"一节所述,图 7-7 中的受害者可进一步分为直接受害者、间接受害者和同路径受害者。
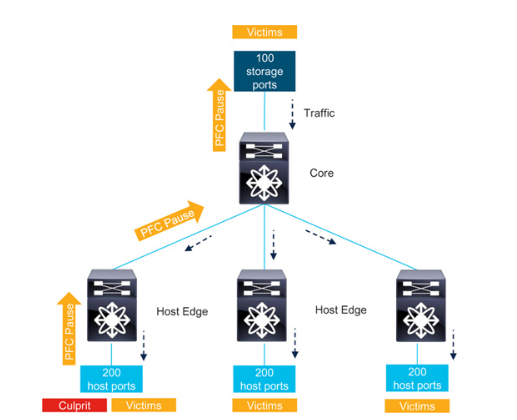
Figure 7-7 边缘核心无损以太网网络中的拥塞问题
为了减少图 7-7 中拥塞的扩散,正如第 6 章 "增加单个交换机的流量定位 "一节所述,如果目标及其主机连接到同一交换机,那么其他交换机上的终端设备就不会受害。
无损脊叶网络中的拥塞扩散
请看图 7-8,了解无损叶脊网络中的拥塞传播。主机和目标不按特定顺序连接到叶交换机。存储流量保持在无损级。主机之间不在无损类中通信。同样,目标也不会在无损类中相互通信。所有设备都与无损类之外的其他设备通信。由于等价多路径(ECMP)的存在,主交换机和叶子交换机之间的所有链路都被统一使用。例如,从目标-1 到主机-1 的流量先到叶子-1,然后到所有四个主交换机,最后通过其所有上行链路到叶子-6。
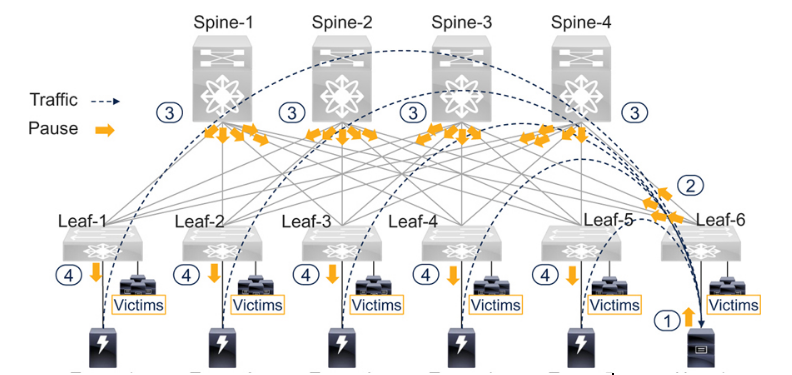
Figure 7-8 无损以太网脊叶网络中的拥塞问题
连接到 Leaf-6 的 Host-1 接收来自五个目标主机的流量,这些目标通过 Leaf-5 交换机连接到 Leaf-1。当 Host-1 成为慢排空设备时,它会向 Leaf-6 发送暂停帧,以减缓入口流量。最终,Leaf-6 的 "暂停阈值 "超标,因此它会向其上游邻居发送暂停帧。这就减慢了从四个骨干交换机到 Leaf-6 的流量,从而使连接到 Leaf-6 并从任何其他叶交换机后面的任何其他目标接收流量的其他主机受害,尽管这些主机没有调用 PFC。
此外,骨干交换机超出了暂停阈值,因此它们会向所有向叶子 6 发送流量的叶子交换机(叶子 1 - 叶子 5)发送暂停帧。这就减慢了来自叶子交换机的所有流量(无论其目的地如何),因此许多无关设备也受到了影响。
最后,与目标主机连接的叶子交换机(如 Leaf-1)超过了暂停阈值,因此它们会向目标主机(如 Target-1)发送暂停帧,以降低其速度。在 Leaf-1 上,由于 Target-1 会减慢无损类中的所有流量(无论其目的地如何),甚至连接到 Leaf-6 并从 Target-1 接收流量的主机也会受到影响。这些受害者往往被忽视,因为他们的流量仍在本地叶交换机上,而罪魁祸首却连接到了不同的叶交换机上。但是,由于罪魁祸首会对目标造成不利影响,所有从这些目标接收流量的主机都会受到影响,无论它们位于何处。
正如第 4 章 "识别受影响设备(受害者)"一节所述,图 7-8 中的受害者可进一步分为直接受害者、间接受害者和同路径受害者。
慢速排空
图 7-8 解释了当Host-1 的处理速度低于向其传输帧的速度时(慢排空)的情况。但它的链路并未得到充分利用。例如,Host-1 以 10 GbE 连接到 Leaf-6,但它只能以 5 Gbps 的速度接收流量,这是因为 Host-1 内部存在其他问题,导致它无法处理超过 5 Gbps 的入口流量,因此它调用了 PFC。
主机边缘链路的过度使用
当 Host-1 能够以其链路的全部容量(10 Gbps)处理入口流量时,就会出现因过度使用而导致的拥塞。它没有调用 PFC。然而,Leaf-6 接收到的流量(例如 11 Gbps)超过了可以发送到 Host-1 的流量,因此 Leaf-6 调用 PFC 来减缓来自骨干交换机的流量。
因排空缓慢和过度使用造成的拥堵比较
如果拥塞是由慢排空设备或过度使用主机边缘链路造成的,那么对结构的影响也是一样的。
区别在于边缘交换端口。当拥塞由慢排空引起时,连接的边缘交换端口会收到很多暂停帧,其出口利用率并不高。相反,当拥塞由过度使用造成时,边缘交换端口不会收到暂停帧,而出口利用率却很高。这种差异是检测拥塞原因的基础。
检测无损以太网网络中的拥塞问题
以下是无损以太网网络拥塞检测工作流程的关键因素。
检测到什么
拥堵的影响是什么?换句话说,有多严重?
拥堵的原因是什么?
拥堵的根源(罪魁祸首)在哪里?
拥堵(受害者)扩散到哪里?
拥堵是什么时候发生的?
如何检测
反应式方法: 在拥堵事件发生后进行检测并排除故障。
积极应对: 实时检测拥堵事件。
预测性: 在拥堵事件发生之前进行预测。
从何处检测
在交换机、主机/服务器或存储阵列等设备上运行。
使用远程监控平台,如 UCS 流量监控应用程序,详见第 9 章。
有关这些主题的详细说明,请参阅第 3 章 "检测光纤通道 Fabric 中的拥塞 "中的 "拥塞检测工作流程 "一节。同样的细节也适用于无损以太网网络,因此在此不再赘述。本节仅提供适用于无损以太网网络的简要概述。
拥堵方向 - 入口或出口
拥塞是有方向性的。拥塞通常发生在一个方向,而反方向可能不拥塞。试图沿着错误的方向追踪拥塞情况,并不能找到拥塞的源头和原因。
例如,在图 7-8 所示的脊叶网络中,在骨干交换机上,只有叶 6 方向的流量会受到拥塞的影响。从 Leaf-6 到骨干交换机的流量不受拥塞影响。
出口交换端口的拥塞会导致入口端口的拥塞,而入口端口的拥塞又会导致流向源的流量路径上至少一些上游端口的出口拥塞。换句话说,出口拥塞会导致入口拥塞。入口拥塞不会导致出口拥塞。因此,出口方向的拥塞检测工作流程和指标对于识别拥塞源更为重要。
图 7-9 显示了图 7-8 所示脊叶网络的一个子集。拥塞源是 Host-1,它会导致 Leaf-6 出现出口拥塞。这种出口拥塞导致连接到叶子交换机的叶子-6 端口出现入口拥塞。同样的入口和出口拥塞顺序一直持续到流量源(目标-1)。根据端口的位置,调查入口或出口方向的拥塞情况。
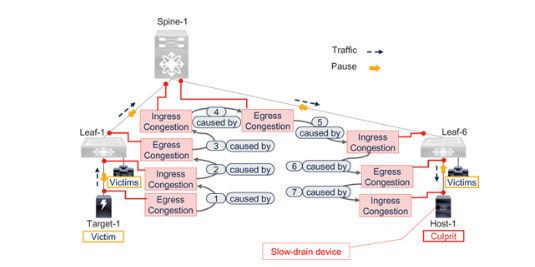
Figure 7-9 无损脊叶网络中的拥塞方向和流量方向
拥塞检测指标
以下是有助于检测无损以太网网络拥塞情况的指标。
检测流量暂停的指标,也称为暂停帧监控。
流量暂停持续时间: 端口因接收到邻居的暂停帧而无法传输的时间。
流量暂停的次数: 接收或发送的暂停帧数。
可用缓冲区的瞬时值: 在流量接收器上,瞬时缓冲区利用率会显示距离暂停阈值的距离,从而触发暂停帧。
检测丢帧的指标。
检测位错误(如 CRC 破坏帧)的指标。
检测链路利用率的指标,如端口上接收和发送的帧的数量和大小。
用于检测应用程序 I/O 配置文件的指标,例如帧内 I/O 操作的时间、大小、类型和速率。
这些指标类型与第 3 章 "光纤通道端口拥塞检测指标 "一节中解释的指标类型相同。无损以太网端口没有只针对光纤通道 B2B 流量控制的指标,如链路重置协议或 B2B 状态更改机制。光纤通道端口会在剩余 Tx-B2B 信用为零且持续时间较长时启动信用损失恢复(通过链路重置协议)。无损以太网没有类似的概念,无论端口被邻居持续暂停多长时间。
如果以太网端口不报告指标或访问指标不够方便,变通方法是反向使用直接连接的邻接端口的指标。例如
端口的入口利用率与其邻居的出口利用率相同,反之亦然。
在大多数情况下,以太网端口发送的暂停帧与其邻居接收的暂停帧相同。暂停帧有可能在中间损坏,从而无法被对等设备识别。在这种情况下,端口将继续发送暂停帧,直到其队列利用率低于恢复阈值。因此,在实际操作中,只需监控链路上一个端口的暂停帧即可。例如,在主机端口与其连接的交换端口之间的链路上,可以只监控其中一个端口上的 TX 和 RX 暂停。
这种跨相邻设备的关联最好在远程监控平台上进行。
流量暂停持续时间 - TxWait 和 RxWait
TxWait 是端口因接收到邻居的暂停帧而无法传输的持续时间。它也称为暂停持续时间。
RxWait 与反向的 TxWait 类似。它是端口因发送暂停帧而无法接收流量的持续时间。
TxWait 和 RxWait 可以转换成更有意义的值,称为 TxWait 百分比,即端口在一定时间内无法传输的时间百分比。例如,20 秒内 50%的 TxWait 表示端口在 10 秒内无法传输。
请注意以下有关 TxWait 和 RxWait 的要点:
1. TxWait 是因为 Rx 暂停,而 RxWait 是因为 Tx 暂停。
2. 如果端口不报告 TxWait,则可选择在其邻居上使用 RxWait。
3. 优先使用 TxWait 和 RxWait(或检测流量暂停持续时间的类似指标)来检测无损以太网网络中的拥塞情况。当 TxWait 和 RxWait 不可用时,使用其他指标,如暂停帧数。
4. 在撰写本文时,Cisco MDS 和 Nexus 7000 交换机收集 FCoE 端口上的 TxWait 和 RxWait。Cisco Nexus 9000 交换机和 Cisco UCS 服务器不收集 TxWait 和 RxWait。
以太网端口上的 TxWait 和 RxWait 与光纤通道端口上的 TxWait 和 RxWait 类似。本节简要介绍显示 Cisco MDS 交换机 FcoE 端口上 TxWait 和 RxWait 的命令。更多详细信息请参阅第 3 章 "以微秒为单位的 Tx Credit Unavailability(TxWait)"和 "以微秒为单位的 Rx Credit Unavailability(RxWait)"一节。
Raw and Percentage TxWait and RxWait
例 7-5 显示了 Cisco MDS 交换机 FCoE 端口的原始和百分比 TxWait 和 RxWait。MDS 交换机以 2.5 微秒(μs)为增量报告 TxWait 和 RxWait,因此 4 的值等于 10 μs。例 7-5 显示过去 1 秒内 RxWait 为 49%,这表明该端口在过去 1 秒内向邻居发送了暂停帧,以停止流量 490 毫秒 (ms)。
请注意,TxWait 仅针对 VL3 进行测量。这是用于 CoS3 流量的 FCoE 类别,使用 PFC 进行流量控制。

Example 7-5 交换机上显示接口中的 TxWait 和 RxWait
TxWait 和 RxWait 历史图表
Cisco MDS 交换机显示三个 TxWait 和 RxWait 历史记录图。
每列显示每秒的累计 TxWait 或 RxWait。
每列显示每分钟的累计 TxWait 或 RxWait。
每列显示每小时的累计 TxWait 或 RxWait。
有关输出示例,请参阅第 3 章 "TxWait 历史图表 "部分,FC 和 FCoE 接口的输出示例相同。
TxWait and RxWait History in OBFL
如例 7-6 所示,当 TxWait 和 RxWait 的值在 20 秒间隔内增加 100 毫秒或更多时,Cisco MDS 交换机会在板载故障日志 (OBFL) 缓冲区中记录这两个值。

请参阅第 3 章 "TxWait History Graphs(TxWait 历史记录图表)"一节,了解该输出的详细说明,FC 和 FCoE 接口的输出相同。有关 OBFL 的详细信息,请参阅第 4 章 OBFL 命令 - show logging onboard 部分。
Number of Pause Frames
当 TxWait 和 RxWait 不可用时,下一个选择是了解以太网端口发送和接收的暂停帧数。
这些计数器类似于光纤通道端口上的 "信元转换为零 "计数器,只是没有那么具体,因为只有一些quanta不为零的暂停帧才会真正停止流量。
以下是使用暂停帧数检测拥塞的一些要点:
1. 在撰写本报告时,大多数实现都不会单独计算暂停(非零quanta)和非暂停(零quanta)。暂停帧计数是两种暂停帧类型的总和。
2. 在正常情况下,暂停帧计数器的增量可能很小,不会对应用性能产生任何影响。当边缘端口上的暂停帧计数增量很小,而上游端口上的暂停帧计数不增量时,这表明拥塞已被该交换机的缓冲区吸收。这种情况不会危及其他设备,因此不像拥塞扩散那样令人担忧。它只是说明 LLFC/PFC 运行良好。
3. 暂停帧计数只能作为上次清除计数器后的累计值报告。大量的暂停计数并不能说明拥塞是昨天、上周还是上个月发生的。在撰写本文时,除了 Cisco MDS 和 Nexus 7000 交换机外,Cisco 设备只能提供累计的暂停帧计数,因为这两种交换机会保留带有时间和日期戳的历史记录。
例 7-7 显示了 Cisco UCS Fabric Interconnect 上的入口和出口 PFC 暂停帧。运行 NX-OS 命令 show interface priority-flow-control 两次,每次间隔 10 秒。输出结果如下:
1. 以太网 1/1 和以太网 1/8 使用 LLFC(操作关闭),而以太网 1/1/7 使用 PFC(操作打开)。
2.以太网 1/1/7 仅在 CoS 3 中使用 PFC。 VL bmap 显示 PFC 暂停帧中的类启用向量(图 7-4)。它采用十六进制格式。0x8 的二进制值为 1000。从右侧读取并从 0 开始,第 3 位被启用。这表明 CoS 3 流量被分配到了不丢弃类。同样,VL vmap 值为 0x28 意味着为 CoS 3 和 CoS 5 启用了 PFC,因为 0x28 的二进制值为 101000。
3. RxPPP 和 TxPPP 显示所有类别中 PFC 暂停帧的总计数。PPP 表示每优先级暂停。
4. 以太网 1/1 在这 10 秒内没有出现入口或出口拥塞,因为 TxPPP 和 RxPPP 计数器没有变化,尽管暂停帧是在较早的未知时间发送和接收的。
5. 以太网 1/8 出现了出口拥塞,因为 RxPPP 计数在 10 秒内增加了 1456(846831773 - 846830317)。它没有出现入口拥塞,因为 TxPPP 计数器保持不变。
6. 以太网 1/1/7 出现入口拥塞,因为 TxPPP 计数在 10 秒内增加了 38(1406361419 - 1406361381)。它没有出现出口拥塞,因为 RxPPP 计数器保持不变。
7. 对以太网 1/8 (1456 个) 和以太网 1/1/7 (38 个) 10 秒间隔内的暂停帧数量进行比较后发现,以太网 1/8 的拥塞情况更为严重,尽管方向相反。
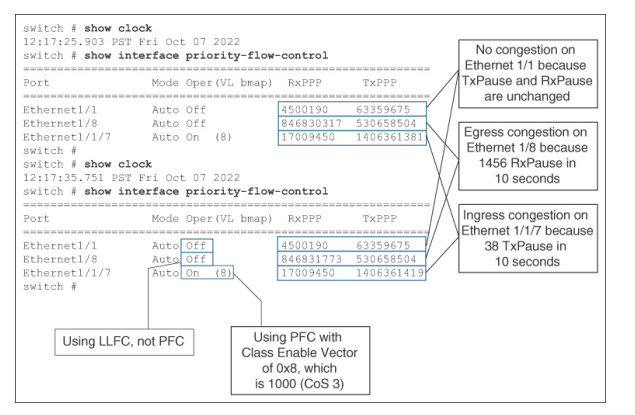
Example 7-7 Pause frame count in show interface priority-flow-control on Cisco UCS
“show interface priority-flow-control” 是 Cisco Nexus 9000 交换机和 Cisco UCS 服务器上检测和排除拥塞故障的主要命令,因为它非常简单。但它显示的是所有类别的暂停帧的总计数,这没有问题,因为大多数环境可能只对单个流量类别使用 PFC。
要查找 Cisco Nexus 9000 交换机上每个类的暂停帧计数,请使用 NX-OS 命令 show queuing interface。例 7-8 显示了以太网 1/1 上入口和出口方向的拥塞指示。在类级别上,只有 CoS 1 出现拥塞,而 CoS 3 没有任何拥塞迹象。此外,请注意在执行该命令时,CoS 1 处于暂停的活动状态。要找到处于激活状态的 RxPause 或 TxPause 必须非常幸运。如果在多次快速执行该命令时 RxPause(ox TxPause)一直处于活动状态,则表明直连邻居是一个慢耗尽设备,导致严重拥塞。
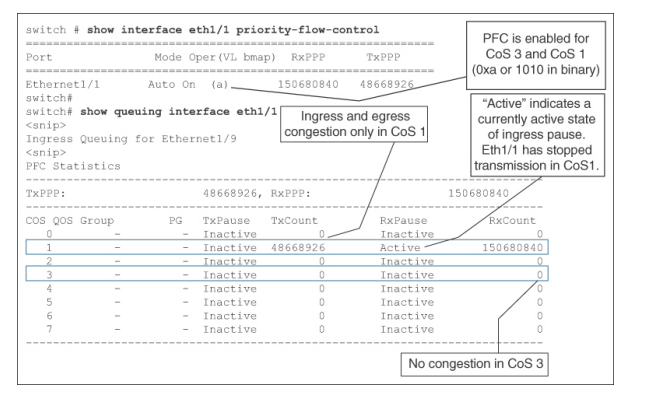
Example 7-8 Per-priority Pause frame count and current state in show queuing interface
Cisco Nexus 9000 交换机和 Cisco UCS 服务器上的 show interface 命令也会显示暂停计数器(例 7-9)。但这些都是 LLFC 计数器,启用 PFC 时不会递增。
Example 7-9 LLFC Pause counter in show interface
Frame Drops or Discards
使用 LLFC 或 PFC 时,不应丢弃帧。但是,如果端口在超过暂停阈值后仍继续接收流量,且其缓冲区净空已完全耗尽,端口就会丢弃帧。丢弃帧的另一种情况是在严重拥塞时,帧在队列中停留的时间超过了暂停超时或 PFC 看门狗时间间隔(稍后解释),队列会清空所有数据包。
由于各种原因,大多数以太网端口都会报告丢弃或丢弃的帧。请参阅例 7-9,其中显示了 NX-OS 命令 show interface 中的输入和输出丢弃情况。这是无损和其他类别的集体计数。
使用 NX-OS 命令 show queuing interface 查找每个流量类别的丢包情况。请参考例 7-10。它显示已为 CoS 3 和 CoS 4 启用了 PFC。 该输出所使用的交换机支持两个无损队列。分配给 CoS 值较小 (3) 的无损队列中的数据包丢弃显示在 "Low Pause Drop Pkts "下面。同样,分配给 CoS 值较大 (4) 的无损队列中的丢包显示在 "高暂停丢包 "下。Low(低)和 High(高)指的是较小和较大的 CoS 值。CoS 3 的无损类别丢弃了 255 个数据包,而分配给 CoS 4 流量的无损类别没有丢弃任何数据包。
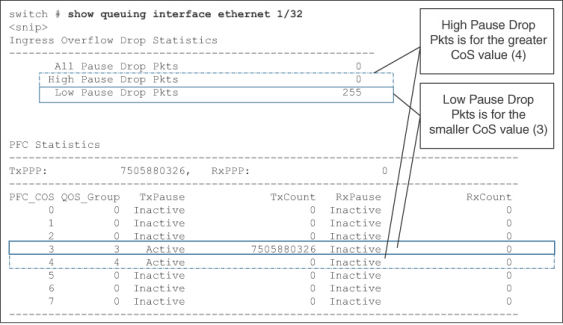
Example 7-10 Packet drops per no-drop class
Bit Errors
检测以太网端口位错误的主要方法是 CRC、stomped CRC 和 FEC。
CRC Counters
发送方对帧内容计算帧校验序列(FCS)多项式,并将计算结果置于帧的 CRC 字段中。接收方收到帧后,对帧内容计算相同的 FCS 多项式。如果计算输出与 CRC 字段的内容不匹配,则该帧未通过 CRC 校验,称为 CRC 损坏帧。因此,接收器会递增输入的 CRC 计数器。
需要记住的一个要点是,只有当比特错误出现在帧内时,CRC 计数器才会递增。但如果比特错误在帧边界之外,或者如果流量较低导致链路上的帧较少,那么即使链路上存在比特错误,CRC 计数器也可能不会递增。第 2 章 案例研究 - 一家在线零售商演示了这种情况。
例 7-9 使用 NX-OS 命令 show interface 显示 Cisco Nexus 9000 交换机和 Cisco UCS 服务器上的 CRC 错误。
使用 CRC 计数器检测位错误时,一个重要的考虑因素是交换机的直通式或存储转发式结构。第 2 章 "检测和丢弃 CRC 损坏帧的能力 "一节将详细解释这一点。简而言之,直通式交换机可减少端口到端口的交换延迟。但这些交换机无法丢弃 CRC 破坏的帧,因为它们在接收到完整的帧之前就开始传输帧,而且 CRC 字段位于帧的末尾。在这种情况下,同一个 CRC 损坏的帧会导致其路径上不同交换机上多个端口的 CRC 计数器递增,从而使检测比特错误源变得复杂。如果交换机支持堆叠 CRC,则可在一定程度上降低这种复杂性,具体说明见下节。
Stomped CRC Counters
Stomped CRC 计数器有助于在使用直通式交换机的网络中查找位错误的位置。更确切地说,这些计数器有助于找到不存在位错误的地方。
当直通交换机支持踩踏 CRC 功能时,它会在损坏帧的 CRC/FCS 字段中编码一个特殊值。这就是所谓的 "帧踩踏"。如前所述,交换机不能丢弃损坏的帧,因为它已经开始传输。但交换机可以踩帧,因为它知道帧已损坏,而且尚未传输帧末的 CRC 字段。当下一个交换机检测到被踩踏的帧时,它只会递增被踩踏的 CRC 计数,而不会递增 CRC 计数。对所有这些端口进行比较后,就可以排除有踩踏 CRC 错误的端口,对有 CRC 计数器的端口/链路进行调查。损坏的帧最终会在目的地或存储转发交换机上丢弃。
例 7-9 使用 NX-OS 命令 show 界面显示了 Cisco Nexus 9000 交换机和 Cisco UCS 服务器上的 Stomped CRC 错误。
Forward Error Correction
启用 FEC 时,发送方会在比特流中增加一些额外的奇偶校验位。接收器可利用这些奇偶校验位检测和恢复有限的比特错误。
当 FEC 能够恢复损坏的比特时:
经校正的 FEC 计数器增量,以及
CRC 计数器不会递增,因为 FEC 已在较低层恢复了比特错误,比特将按照发送方发送的方式移交给成帧层。
当 FEC 无法恢复损坏的比特时:
FEC 未校正块计数器增量,以及
如果位错误发生在一个帧内,CRC 计数器可能会递增。
在 Cisco Nexus 9000 交换机上,使用命令 show hardware internal tah mac hwlib show mac_errors fp-port 显示 FEC Correctable 和 FEC UnCorrectable 计数器。如例 7-11 所示,这是一条模块级命令,因此使用前必须使用 NX-OS 命令 attach module。




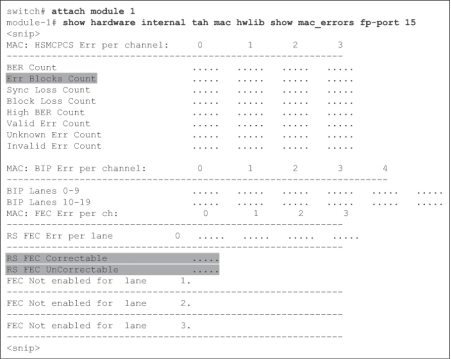


Example 7-11 FEC Counters on Cisco Nexus 9000 switches
switch# attach module 1
module-1# show hardware internal tah mac hwlib show mac_errors fp-port 15
MAC: HSMCPCS Err per channel: 0 1 2 3
------------------------------------------------------------
BER Count ..... ..... ..... .....
Err Blocks Count ..... ..... ..... .....
Sync Loss Count ..... ..... ..... .....
Block Loss Count ..... ..... ..... .....
High BER Count ..... ..... ..... .....
Valid Err Count ..... ..... ..... .....
Unknown Err Count ..... ..... ..... .....
Invalid Err Count ..... ..... ..... .....
MAC: BIP Err per channel: 0 1 2 3 4
--------------------------------------------------------------------
BIP Lanes 0-9 ..... ..... ..... ..... ..... .....
BIP Lanes 10-19 ..... ..... ..... ..... ..... .....
MAC: FEC Err per ch: 0 1 2 3
------------------------------------------------------------
RS FEC Err per lane 0 ..... ..... ..... .....
------------------------------------------------------------
RS FEC Correctable .....
RS FEC UnCorrectable .....
FEC Not enabled for lane 1.
------------------------------------------------------------
FEC Not enabled for lane 2.
------------------------------------------------------------
FEC Not enabled for lane 3.
------------------------------------------------------------
FEC 计数器不仅能检测比特错误,还能预测网络的健康状况。第 2 章 "案例研究--一家在线零售商 "一节对此进行了演示。
有关 FEC 的详细说明,请参阅第 2 章 "前向纠错 "一节。由于光纤通道重复使用以太网 IEEE 803.2 标准中的 FEC 代码,因此以太网网络也适用相同的细节。但术语可能有所不同。以太网称为 "块",而光纤通道称为 "传输字"。请参阅示例 7-11,其中显示了错误块计数。当启用 FEC 且无法恢复比特错误时,该计数器会递增。同样,FEC 块、FEC 帧和 FEC 编解码器指的是携带 FEC 有效载荷和奇偶校验位的同一实体。这些细节将在第 2 章中解释,此处不再赘述。
Link Utilization
例 7-9 显示了用于计算 Cisco Nexus 9000 交换机和 Cisco UCS 服务器上链路利用率的多个计数器。
接口速度
累计输入和输出字节
30 秒和 5 分钟的平均输入和输出率。这些值通过输入和输出字节累积值的差值(delta)计算,然后除以轮询间隔。
Txload 和 Rxload 就像百分比利用率。负载越高,链路利用率越高。255/255 的负载是 100% 的利用率。负载和百分比利用率都是用吞吐量除以链路速度计算得出的。
大多数以太网端口都会报告类似的计数器。
审核编辑:刘清
-
以太网存储网络的拥塞管理连载方案(一)2024-02-26 3303
-
以太网存储网络的拥塞管理连载方案(二)2024-02-27 3260
-
以太网存储网络的拥塞管理连载案例(五)2024-03-04 2514
-
以太网存储网络的拥塞管理连载案例(六)2024-03-06 2463
-
以太网存储网络的拥塞管理连载案例(七)2024-03-08 2031
-
以太网和工业以太网的不同2018-10-23 2841
-
工业以太网的实现方案和现场实际应用情况2021-01-13 2730
-
基于BOOTP的工业以太网IP仪表的智能化管理策略2011-02-26 938
-
Silabs以太网方案2011-06-14 1301
-
以太网光纤通道(FCoE)技术问答2011-12-01 1405
-
以太网协议及应用方案2017-01-21 826
-
以太网的分类及静态以太网交换和动态以太网交换、介绍2018-10-07 7826
-
万兆以太网和IP SAN的融合2020-01-24 4404
-
光纤通道到以太网存储结构解析2020-07-21 1632
-
AI网络管理新范式:精要解读超以太网联盟(UEC)1.0 规范(2025Q2)2025-07-11 2727
全部0条评论

快来发表一下你的评论吧 !
