

什么是自动语音识别(ASR)?如何使用深度学习和GPU加速ASR
人工智能
描述
自动语音识别(ASR)或语音转文本,是流程和软件的组合,能够解码人类语音并将其转换为数字化文本。
1►
什么是自动语音识别(ASR)?
自动语音识别(ASR)会收录人类语音,然后将其转换为可读文本。ASR 能够帮助我们免手动操作地编辑文本消息,并提供用于机器理解的框架。人类语言愈加可搜索和可操作,这使开发者能够获取情感分析等高级分析。ASR 是对话式 AI 应用程序流水线的第一阶段,使用自然语言与机器进行交流。
典型的对话式 AI 应用程序使用三个子系统来处理和转录音频,即理解提出的问题(获取含义)、生成回复(文本),然后将回复反馈给人类。通过多个深度学习解决方案协同工作来实现这些步骤。
首先,ASR 用于处理原始音频信号,并从中转录文本。其次,自然语言处理(NLP)用于从转录文本(ASR 输出)中提取含义。最后,语音合成或文字转语音(TTS)用于从文本中人工生成人类语音。各步骤均需构建和使用一个或多个深度学习模型,因此优化此多步骤流程非常复杂。
2►
为何选择 ASR?
无论是语音助手和聊天机器人,还是支持客户自助服务的问答系统,语音识别和对话式 AI 的应用频率与日俱增。涵盖金融和医疗健康等众多领域的各行各业,在其解决方案中采用 ASR 或对话式 AI。语音转文本的实际应用非常广泛:
外科医生或飞机驾驶员等“忙碌的”专业人士可以在工作期间进行记录并发出命令。
如果不能使用键盘,或者在开车时遇到危险,用户可以发出语音需求或口述消息。
声控电话应答系统可以处理复杂的请求,而无需用户导航菜单。
无法使用其他输入方式的残障人士可以使用语音,与计算机和其他自动化系统进行交互。
自动转录的速度比人工转录的速度更快,并且成本更低。
在大多数情况下,语音识别速度比打字速度更快。普通人每分钟大概可以说 150 个单字,但只能打 40 个字左右。使用密小难辨的智能手机键盘打字,性能甚至会更慢。
现在,语音转文本在智能手机和台式电脑中的应用随处可见。特殊用途还可用于医学、法律和教育学科。随着其广泛应用成为主流,并且在家庭、汽车和办公室设备中广泛部署,学术界和业界已加大对此领域的研究力度。
3►
ASR 的工作原理
ASR 是自然语言中一项颇具挑战性的任务,它由语音分割、声学建模和语言建模等一系列子任务组成,根据噪声和未分割的输入数据形成预测(标签序列)。深度学习在识别音素(用于创建语音的基本声音)时具有更高的准确性,因此已取代隐马尔可夫模型和高斯混合模型等传统的 ASR 统计方法。深度学习 Connectionist Temporal Classification(CTC)的引入消除了对预分割数据的需求,其允许直接对网络进行端到端训练,从而完成 ASR 等序列标记任务。
典型的 ASR CTC 流程包括以下步骤:
特征提取:第一步是从输入音频中提取有用的音频特征,并且忽略噪声以及其他不相关信息。梅尔频率倒谱系数(MFCC)技术能够在频谱图或梅尔频谱图中捕捉音频频谱特征。
声学模型:将频谱图传递给基于深度学习的声学模型,以便预测每个时间步的字符概率。在训练期间,声学模型使用包含数百小时的音频以及目标语言转录的数据集(LibriSpeech ASR Corpus、《华尔街日报》、TED-LIUM Corpus 和 Google Audio set)进行训练。声学模型根据单词的发音方式进行输出,因此可能包含重复字符。
解码:解码器和语言模型根据上下文将字符转换为单词序列。这些单词可以进一步缓冲为短语和句子,并进行适当分段,然后再发送至下一阶段。
Greedy(argmax):是解码器的简单策略。在每个时间步选择出现概率最高的字母(时序 Softmax 输出层),无需考虑对交流内容的任何语义理解。然后,移除或折叠重复字符,并丢弃空白标记。
语言模型可用于添加上下文,从而纠正声学模型中的错误。定向搜索解码器将 Softmax 输出的相对概率与特定单词在上下文中出现的概率进行加权,并尝试将声学模型听到的内容与可能出现的下一个单词相结合,从而确定说话内容。
4►
使用深度学习和 GPU 加速 ASR
Connectionist Temporal Classification(CTC)等创新技术将 ASR 直接融入于深度学习领域。用于 ASR 的热门深度学习模型包括 Wav2letter、Deepspeech、LAS 以及近期 NVIDIA 研究发布的 Jasper,这是一款使用深度学习来开发语音应用程序的热门工具包。Kaldi 是 C++ 工具包,除了深度学习模块之外,还支持传统方法。
一个由数百个核心组成的 GPU,可以并行处理数千个线程。由于神经网络由大量相同的神经元构建而成,因此本质上具有高度并行性。这种并行性会自然映射到 GPU,因此相比仅依赖 CPU 的训练,计算速度会大幅提高。例如,GPU 加速的 Kaldi 解决方案的执行速度比实时音频快 3,500 倍,比只用 CPU 的解决方案快 10 倍。这种性能使得 GPU 成为训练深度学习模型和执行推理的首选平台。

5►
行业应用
医疗健康
医疗健康面临的困难之一是难以获得。拨打医生办公室电话电话需要一直等待的情况十分常见,与索赔代表尽快联系同样困难。使用对话式 AI 来训练聊天机器人是医疗健康领域的一项新兴技术,旨在解决医疗健康专业人士的短缺问题,并开创与患者的沟通渠道。
金融服务
对话式 AI 正在为金融服务公司构建更出色的聊天机器人和 AI 助手。
零售
聊天机器人技术也常用于零售应用程序,能够准确分析客户查询,并生成回复或建议。这可简化客户流程,并提高商店运营效率。
6►
NVIDIA GPU 加速的对话式 AI 工具
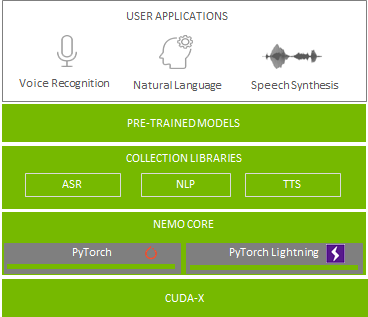
借助对话式 AI 部署服务似乎比较困难,但 NVIDIA 现已具备能够简化这一流程的工具,包括神经模块(简称 NeMo)和一项名为 NVIDIA Riva 的新技术。为节省时间,NGC 软件中心还提供预训练 ASR 模型、训练脚本和性能结果。
NVIDIA NeMo 是一款基于 PyTorch 创建的工具包,能够开发用于对话式 AI 的 AI 应用程序。在模块化深度神经网络的开发过程中,NeMo 可通过连接模组、混合和匹配组件来实现快速实验。NeMo 模块通常表示数据层、编码器、解码器、语言模型、损失函数或组合激活函数的方法。NeMo 针对 ASR、NLP 和 TTS 使用可重复使用的组件,使得构建复杂神经网络架构和系统变得容易。
此外,借助 NVIDIA GPU Cloud(NGC),您可以获得用于对话式 AI 的 NeMo 资源,例如预训练模型、用于训练或评估的脚本,以及 NeMo 端到端应用程序,允许开发者试验不同算法并使用各自数据集执行迁移学习。
为促进整个 ASR 流程的实施和领域适应性,NVIDIA 创建了特定于域的 NeMo ASR 应用程序。此应用程序由 NeMo 助力开发,支持您使用自己的数据来训练或微调预训练(声音和语言)ASR 模型。您可以借此逐步创建专为您自己的数据而构建的更高性能 ASR 模型。
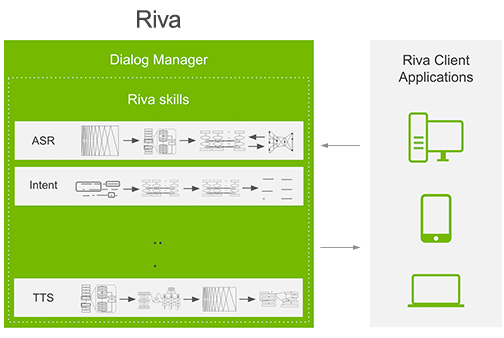
NVIDIA Riva 是一款应用程序框架,能够为完成对话式 AI 任务提供多个制流程。
7►
NVIDIA GPU 加速的端到端数据科学
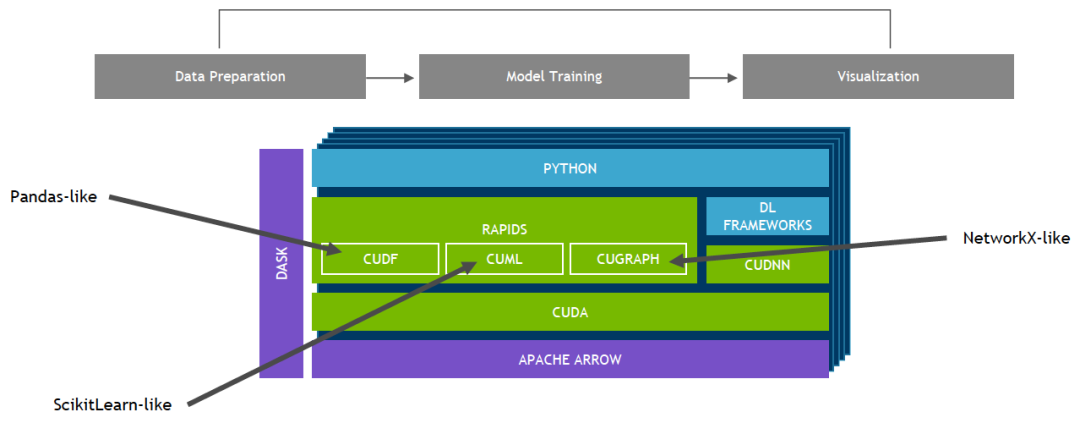
建立在 CUDA 基础上的 NVIDIA RAPIDS 开源软件库套件使您能够完全在 GPU 上执行端到端数据科学和分析流程,同时仍然使用 Pandas 和 Scikit-Learn API 等熟悉的界面。
8►
NVIDIA GPU 加速的深度学习框架
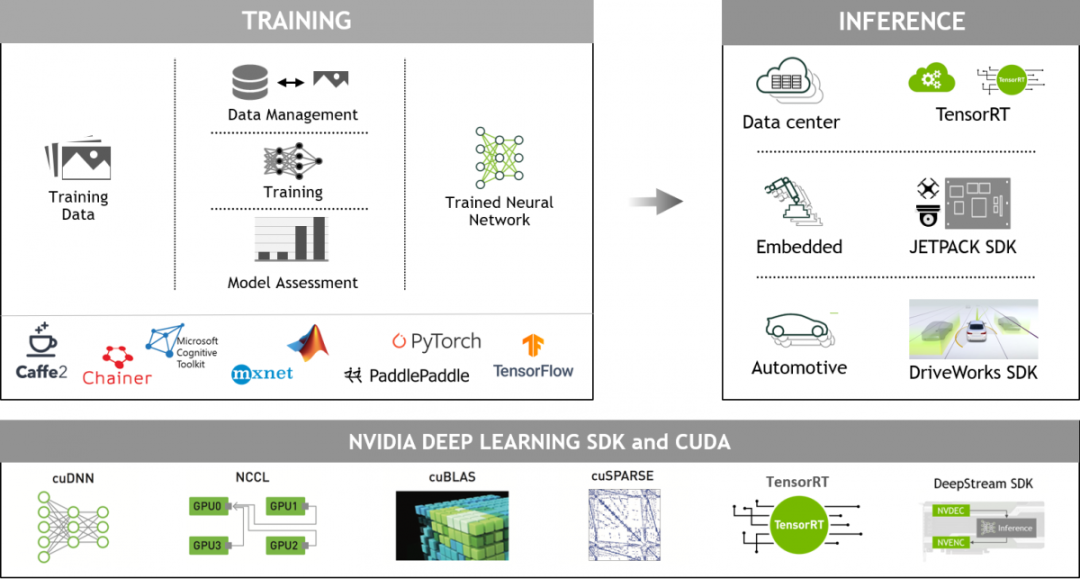
GPU 加速深度学习框架能够为设计和训练自定义深度神经网络带来灵活性,并为 Python 和 C/C++ 等常用编程语言提供编程接口。MXNet、PyTorch、TensorFlow 等广泛使用的深度学习框架依赖于 NVIDIA GPU 加速库,能够提供高性能的多 GPU 加速训练。
审核编辑:黄飞
-
ASR语音识别技术应用2024-11-18 3850
-
解决自动语音识别部署难题2022-10-11 2132
-
LU-ASR01语音识别模块使用说明2022-04-13 19139
-
TWEN-ASR ONE 语音识别系列教程(1)——运行第一个语音程序2021-06-16 6391
-
ASR语音技术的原理以及未来发展趋势分析2020-03-21 4874
-
ASR语音识别技术的介绍应用和优势及实际案例分析2018-10-17 3669
-
对于谷歌应用传统的自动语音识别(ASR)系统的解析2017-12-31 9521
-
什么是汽车的ASR/加速防滑系统2010-03-12 1034
-
ASR控制系统,ASR控制系统是什么意思2010-03-11 17617
-
语音识别技术,语音识别技术是什么意思2010-03-06 3281
全部0条评论

快来发表一下你的评论吧 !
