

以太网存储网络中的拥塞控制与管理策略
存储技术
描述
本文节选自《DetectingTroubleshooting, and PreventingCongestion in Storage Networks 存储网络中拥塞处理》
微突发检测
Cisco Nexus 9000 交换机可在微秒等较短时间内检测流量突发。这样就可以捕捉到可能导致较低粒度拥塞,但由于轮询间隔较长而未被其他手段发现的事件。
当出口队列利用率超过上升阈值时,Cisco Nexus 9000 交换机可检测到微突发。当队列利用率低于下降阈值时,微突发结束。根据交换机型号的不同,本文撰写时的最小微突发粒度为 0.64 微秒,持续时间为 73 微秒。
要了解微突发检测的要点是,它是在 Cisco Nexus 9000 交换机的出口队列上报告的(图 7-10)。正如前面在 "入口和出口队列 "一节中所解释的,暂停帧的发送取决于入口队列的利用率。但只有在出口队列达到一定程度(未满)后,入口队列才会填满。因此,微突发检测是出口拥塞的一种指示。由于出口拥塞会导致入口拥塞,因此微突发检测也是入口拥塞的早期征兆。换句话说,它是该交换机入口端口发送暂停帧的早期信号。
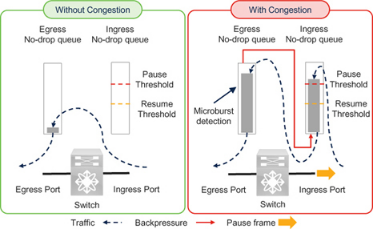
Figure 7-10 Microburst detection on egress queues for lossless traffic
有关其他详细信息,请参阅第 8 章队列深度监控和微突发检测一节。
PFC Storm
PFC 风暴已成为一个术语,用来指传输 RoCE 和 RoCEv2 流量的无损以太网网络(共享或专用)中的拥塞。这可能是因为一个端口发送了许多暂停帧来减慢或停止流量,在其邻居上看起来就像一场 PFC 暂停帧风暴。
但是,使用这个术语可能会产生误导,因为 "风暴 "表达了大量的暂停帧,而且可能与拥塞严重程度有不准确的联系。暂停帧的数量越多,并不一定表示拥塞的严重程度越高。这是因为暂停帧对流量的影响取决于链路速度、暂停帧的类型(零或非零量子)及其模式。
前面关于以太网流量控制和暂停时间的章节介绍了这些细节。在了解了拥塞检测指标和故障排除后,让我们再来看看它们的实际效果。
Link Speed and PFC Storm
正如前面有关暂停时间的章节所述,流量暂停的实际持续时间取决于链路的速度。例如,如果一个 10 GbE 端口每秒只收到 3000 个暂停帧,每个帧的量子点为 65535(暂停时间为 3.355 ms),那么它就可以完全停止传输。同一网络中的另一个端口每秒接收 6000 个暂停帧,每个暂停帧的量子数为 65535,但仍不能完全停止传输,因为这是一个 100 GbE 端口,至少需要每秒接收 30,000 个暂停帧才能完全停止传输。
在这种情况下,100 GbE 端口的风暴更严重,但实际上 10 GbE 端口的拥塞严重程度更高。因此,在根据暂停帧数量检测拥塞时,只应比较运行速度相同的链路。
Pause Time and PFC Storm
与接收到较多较小quanta值暂停帧的端口相比,接收到较少较高quanta值暂停帧的端口受到的影响更大。正如前面的 "何时发送暂停帧 "一节所述,大多数实施可能使用最大量值 65535,因此这一点的实际意义可能较小。但是,您应该验证在您的环境中使用的产品的实现。
Reason for Pause Frames and PFC Storm
使用 "PFC 风暴 "一词并不能说明拥塞的原因。正如前面 "无损脊叶网络中的拥塞 "一节所解释的,慢排空和过度使用都会导致向上游直接连接的设备发送暂停帧。
The Pattern and Content of Pause Frames and PFC Storm
在所有其他因素中,接收到的暂停帧的模式是对数据传输产生实际影响的最重要因素。其次是发送方在接收到暂停帧时的状态。让我们来分析一下这两个因素。
1. The Pattern and content of Pause frames: 如果认为收到非零quanta的暂停帧后,流量会在quanta所代表的时间内停止,那是不正确的。实际上,一个非零quanta的暂停帧之后可能很快就会出现一个取消暂停/恢复帧(零quanta的暂停帧)。如果一秒钟内有 3000 个暂停帧,它们是否都有最大quanta?其中是否有一半具有最大quanta,而其余的quanta为零?如果有 3000 个暂停帧都具有最大quanta,那么 10 GbE 链路上的传输就会完全停止 1 整秒。但是,如果这些暂停帧中有一半的quanta值为零,并且是在具有最大quanta值的初始暂停帧之后 1 微秒才发送的,那么在这 1 秒钟内暂停传输的时间可能只有 1500 微秒。换句话说,仅仅计算暂停帧并不能完全反映实际情况。
2. The State of the Transmitter: 流量 "可能 "暂停的时间是暂停帧和解除暂停帧之间的时间。这是 "可能",而不是 "将要",因为在收到暂停帧后可能会有轻微延迟。在收到暂停帧后,停止传输会稍有延迟(不要与暂停时间混淆),因为端口不会中断当时已经在传输的帧。这种延迟取决于链路速度、帧大小以及何时收到暂停帧。如果一个 10 GbE 端口在传输 1500 字节帧的最后一位时因收到暂停帧而决定停止传输,则链路传输会立即停止。但是,如果同一个 10 GbE 端口在开始传输 1500 字节帧时因收到 "暂停 "帧而决定停止传输,则传输在接下来的((1500 x 8) 位 / 10 Gbps)1.2 微秒内不会停止。在这段时间内,如果收到一个 Un-Pause 帧,那么端口在收到两个暂停帧后也不会停止传输。如果该序列在 1 秒内每 1.2 微秒重复一次,那么端口在该秒内将报告约((1 秒/1.2 微秒)x 2)160 万个暂停帧,同时继续以满负荷传输。仅仅通过计算暂停帧的数量,这条链路就可能被归类为 PFC 风暴,但它的行为与另一条 10 GbE 链路明显不同,后者仅 3000 个暂停帧就能停止传输 1 整秒。请注意以下几点:
A. 为简单起见,本示例使用 1500 字节的帧大小。但是,存储流量的帧大小可能更大,约为 2300 字节(FCoE)或甚至 4 KB(RoCEv2)。随着帧大小的增加,接收到的 "暂停 "帧的动作延迟时间可能会更长,例如,在 10 GbE 链路上,2300 字节帧的延迟时间为 2.3 微秒,4 KB 帧的延迟时间为 4.2 微秒。
b. 暂停帧大小为 64 字节。在传输一个数据帧时,可能会收到许多暂停帧。
c. 从这一解释中可以看出,纯粹根据暂停quanta值,甚至根据接收到的暂停帧和解除暂停帧之间的时间差来计算 TxWait 是不准确的。准确的 TxWait 值必须计算传输实际停止了多长时间。
以太网中的 "暂停帧数 "与光纤通道中的 "B2B 信元转为零 "类似。光纤通道端口在有一个剩余的 Tx-B2B 信元时,会将此计数器递减为零,然后开始传输帧。但是,在传输帧的过程中,它可能会收到一个信元,因此下一帧完全不会延迟。这种情况会导致 "B2B 信元转为零 "计数器递增,而传输实际上并没有停止。
虽然这种情况很少被报告,而且更难检测,但需要了解的关键一点是,无论是光纤通道中的 "B2B 信元转换为零 "计数器,还是以太网中的 "暂停帧数",都不是检测拥塞的有力机制。因此,应避免使用基于此计数器的 PFC Strom 这样的术语,因为它可能会误导某些人,让他们相信暂停帧数才是拥塞的真正衡量标准。
本书使用 TxWait 和 RxWait 来表示无损网络(光纤通道或无损以太网)中各方向传输停止的实际时间。PFC Storm 作为一个术语,似乎非常适合累计暂停时间(TxWait 和 RxWait)不可用的环境,而且暂停帧的数量是检测拥塞的主要指标。但是,将来当设备改进了暂停时间检测(TxWait 和 RxWait)后,使用 "PFC 风暴 "这一术语将更具误导性。例如,一个 10 GbE 端口可能在每秒只有 3000 个暂停帧的情况下显示 100% 的 TxWait,而一个 100 GbE 端口可能在每秒有 6000 个暂停帧的情况下显示 10% 的 TxWait。100 GbE 端口的 "风暴 "严重性可能看起来更高,但 10 GbE 端口的拥塞严重性更高。
我们希望通过本书传达的一个观点是,将在一种传输类型(如光纤通道)中学到的知识用于另一种传输类型(如无损以太网)。在以太网中使用 "PFC Storm "就像在光纤通道中使用 "Credit Transition Storm "来表示拥塞一样。许多年前,也就是现在看来,当光纤通道交换机不提供 TxWait 时,"B2B 信元过渡到零 "是拥塞检测的唯一指标。然而,自从有了 TxWait,它就成了检测拥塞的主要指标,而 "B2B 信元转换为零 "只是在万不得已的情况下才使用。如今,将拥塞称为 "信元过渡风暴 "是不合适的,将其称为 "PFC 风暴 "也是不合适的。由于 PFC Strom 反映的是暂停帧的数量,因此现在使用它意味着无损以太网并没有真正从光纤通道中学习。
当然,切勿在光纤通道结构中使用 "信元转换风暴 "一词。对于无损以太网网络,尽管本节反对使用 PFC Storm 一词,但包括 Cisco 在内的一些供应商还是使用了该词。我们将让读者自己决定是否以及何时使用 PFC Storm 这个术语会产生误导,然后再决定要做什么。
Storage I/O Performance Monitoring
存储网络中的流量是应用程序启动读取或写入 I/O 操作的直接结果。因此,通过分析应用程序 I/O 配置文件,如 I/O 操作的时间、大小、类型和速率,可以更好地了解网络流量模式。从本质上讲,应用程序 I/O 配置文件有助于理解网络出现流量或拥塞的原因。
第 5 章介绍了如何通过存储 I/O 性能监控解决拥塞问题。由于上层(SCSI 和 NVMe)相同,因此相同的细节(至少在概念上)也适用于 FCoE 和 RoCE(传输协议不同除外)。在继续阅读之前,请参考第 5 章中的以下章节,为简洁起见,此处不再赘述。
第 5 章 "为什么要监控存储 I/O 性能?"一节介绍了监控存储 I/O 性能的基本价值。
第 5 章 "如何以及在何处监控存储 I/O 性能 "一节介绍了监控存储 I/O 性能的三个位置--主机、存储阵列或网络。
第 5 章 "Cisco SAN Analytics "一节介绍了 Cisco MDS 交换机如何在交换机内部监控存储 I/O 性能。这种功能称为 SAN Analytics,仅在光纤通道端口上可用。本节还有助于理解为什么以太网交换机不具备类似功能。
第 5 章 "了解存储网络中的 I/O 流量 "一节有助于了解光纤通道结构中的 I/O 流量与无损以太网网络中的 I/O 流量之间的区别。请特别注意 "I/O 流量与 I/O 操作 "小节。
第 5 章 "I/O 流量指标 "一节有助于了解如何使用各种指标监控 I/O 流量的性能,如 I/O 完成时间(光纤通道中称为交换完成时间)、IOPS、吞吐量和 I/O 大小。
了解第 5 章的这些内容后,请注意可以在以下层面监控无损以太网网络的性能:
1. 端口或流量类别: 大多数终端设备和交换机都会报告网络端口或接口上发送/接收的数据包和发送/接收的字节等计数器。与其他类别相比,可以单独监控无损类别的流量。
2. UDP 流量: OSI 模型第 4 层的流量由 5 个元组标识:源 IP、目标 IP、源端口、目标端口和第 4 层协议(TCP、UDP 等)。换句话说,RoCEv2 流量可按 UDP 流量分类。每个 UDP 流量的发送/接收的数据包、发送/接收的字节数和丢弃的数据包等计数器可根据网络设备的能力分别进行监控。
3. I/O 流:I/O 流是对存储卷(SCSI 为逻辑单元,NVMe 为命名空间)的 SCSI 或 NVMe I/O 操作的感知。通过监控 I/O 流级别的性能,可以计算 I/O 操作完成所需的时间、吞吐量、IOPS、类型(读或写)、I/O 大小等。
UDP Flow Monitoring versus I/O Flow Monitoring
UDP 流量监控不应与 I/O 流量监控混淆,原因如下:
1. UDP 属于 OSI 模型的传输层(第 4 层)。它不了解 RDMA、SCSI 和 NVMe 等上层协议的功能。
2. 许多 I/O 操作可能在一个 UDP 数据流中传输。这些 I/O 操作可能属于不同的 I/O 流。请参阅第 5 章 "I/O 流与 I/O 操作 "一节。
3. 如前所述,UDP 流量有自己的性能监控指标,如每秒传输的数据包、吞吐量等。这与 I/O 流量的性能监控指标(如 IOPS、I/O 吞吐量、完成 I/O 操作所需的时间、I/O 大小等)不同。
Unavailability of I/O Flow Monitoring in Lossless Ethernet Networks
在撰写本文时,无损以太网网络中还没有对 I/O 流量进行性能监控。以太网交换机可能会报告网络延迟,这通常是指数据包在网络中花费的时间。这不是 I/O 完成时间。同样,以太网交换机可能会报告 UDP 流量的吞吐量,但这不是读或写 I/O 吞吐量或 IOPS。
虽然启动程序和目标程序的 IP 地址可被视为 IT 流量,但如果不了解 I/O 流量指标,这种流量定义就没有什么价值。
即使在将来,以太网交换机也不可能监控 I/O 性能,类似于 Cisco MDS 交换机光纤通道端口上的 SAN Analytics。这是因为以太网网络携带数千个上层协议,每个协议都有不同的 TCP 和 UDP 端口号。增强以太网交换机以解码存储协议(FCoE、RoCE 等)并测量其性能,可能无法弥补进行这些增强所需的额外成本。这对 Cisco MDS 交换机来说并不是一个挑战,因为光纤通道是专门为存储流量而构建的。相比之下,以太网网络则可传输各种流量,如第 1 章图 1-11 所示。
Alternative Approaches
另一种方法是监控主机或存储阵列内的存储 I/O 性能。第 5 章将解释这些细节以及如何使用 I/O 性能指标来解决拥塞问题。虽然第 5 章重点介绍光纤通道,但其概念也适用于无损以太网网络。
一些以太网交换机(如 Cisco Nexus 9000 交换机)会监控 UDP 流的性能。但如前所述,这并不是对 I/O 流量的性能监控,这些 UDP 流量中包含了 I/O 流量。因此,在对主机和存储阵列进行 I/O 性能监控的同时,应使用以太网交换机进行 UDP 流量监控。RoCEv2 目标/控制器使用 UDP 端口 4791,这意味着发往目标/控制器的数据包具有目标端口 4791,而发往主机的数据包具有源端口 4791。UDP 端口 4420 分配给 NVMe/RoCE。可以将各种来源的信息关联起来,构建自己的解决方案。
FCoE I/O Operations
FCoE 网络中的 SCSI 和 NVMe I/O 操作与光纤通道 Fabric 相同。有关详细信息,请参阅第 5 章。
但 SAN 分析功能仅适用于 Cisco MDS 交换机上的光纤通道端口。如果流量在端到端数据路径中至少经过一次具有分析功能的光纤通道端口,则仍可对其进行检查,以收集 I/O 流量指标。即使流量通过网络中其他位置的 FCoE 端口,这种方法也能发挥作用。一个典型的例子是思科 UCS 服务器,它在内部使用 FCoE。当相同的流量到达 MDS 上的光纤通道端口时,可以使用 SAN Analytics 对其进行检查,以收集 I/O 流量指标。
RoCE I/O Operations
图 7-11 显示了 NVMe over RoCE 读 I/O 操作。主机通过向目标机发送命令包中的 RDMA_SEND 来启动读 I/O 操作。目标机根据 I/O 操作请求的数据量和网络的最大传输单元 (MTU),通过 RDMA_WRITE 以一个或多个数据包的形式向主机发送数据(更多详情请参见第 8 章 IP MTU 和 TCP MSS 考虑因素部分)。最后,当目标发送响应包时,I/O 操作完成。
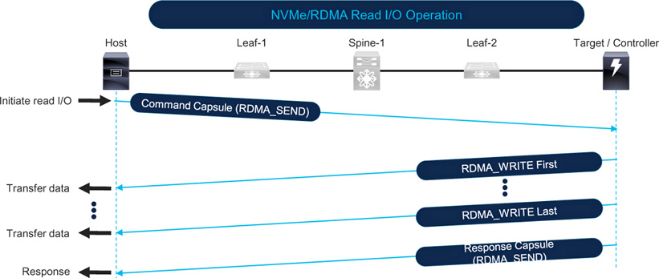
Figure 7-11 NVMe over RoCE read I/O operation
图 7-12 显示了 NVMe over RoCE 写 I/O 操作。主机通过向目标机发送命令包中的 RDMA_SEND,启动写 I/O 操作。然后,目标机向主机发送 RDMA_READ 请求。接下来,主机根据 I/O 操作请求的数据量和网络的 MTU,通过 RDMA_READ 响应以一个或多个数据包的形式向目标发送数据。最后,当目标机发送响应包时,I/O 操作完成。
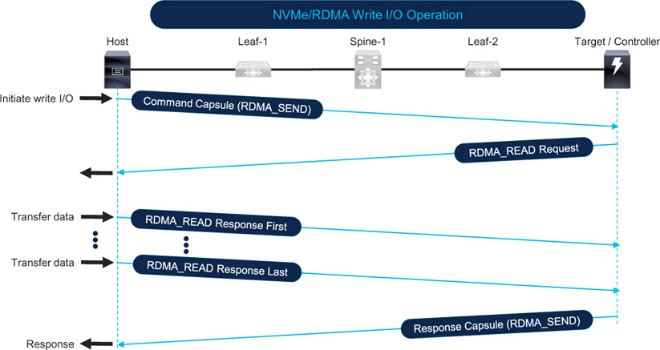
Figure 7-12 NVMe over RoCE write I/O operation
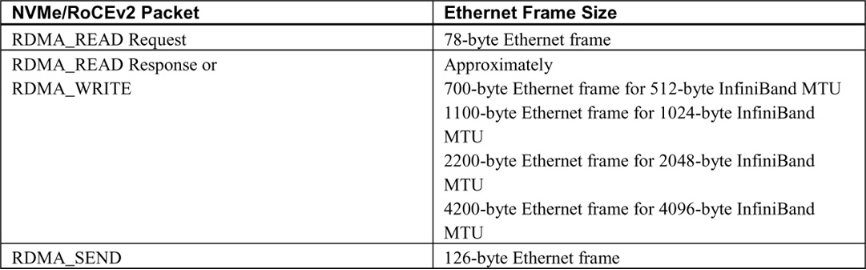
Table 7-2 shows the Ethernet frame sizes and directions based on the type of RDMA operation.
Table 7-2 Typical size of Ethernet frames for NVMe/RoCE I/O operations
Correlating I/O Operations, Traffic Patterns, and Network Congestion
请参阅第 5 章的以下章节,为简洁起见,此处不再赘述。
将第 5 章中的 I/O 操作和网络流量模式一节与前一节进行比较,可以发现流量模式之间有惊人的相似之处。因此,与网络拥塞的相关性也很相似。对于读取数据,SCSI 和 NVMe 使用读 CMD,而 RDMA 则反向使用 RDMA_WRITE verb。同样,在写数据时,SCSI 和 NVMe 使用写 CMD,而 RDMA 则反向使用 RDMA_READ verb。
第 5 章 "网络流量方向 "一节介绍了各种端口类型因读写 I/O 操作而产生的流量。
第 5 章 "I/O 操作、流量模式和网络拥塞的相关性 "一节解释说,主机链路拥塞的主要原因是来自该主机的多个并发大容量读取 I/O 操作。同样,存储链路拥塞的主要原因是存储阵列请求的数据总量。
Detecting Congestion on a Remote Monitoring Platform
远程监控平台可同时监控网络中的所有端口,以提供全网单一窗口可视性。
请参阅第 3 章 "在远程监控平台上检测拥塞 "一节,其中介绍了如何使用以下类型的监控应用程序:
设备制造商/供应商开发的应用程序,如 Cisco Nexus Dashboard Fabric Controller (NDFC) 和 Nexus Dashboard Insights。
第三方或定制开发的应用程序,如 MDS 流量监控 (MTM) 应用程序。
本节简要介绍用于检测以太网拥塞的 Cisco Nexus Dashboard Insights。
要进一步了解定制开发的用于检测和排除无损以太网网络拥塞故障的应用程序,请参阅第 9 章,其中介绍了如何使用 UCS 流量监控应用程序 (UTM)。
第 3 章还介绍了 "监控网络流量的陷阱"。其中关于平均利用率和峰值利用率的小节也适用于无损以太网网络。
Congestion Detection using Cisco Nexus Dashboard Insights
Cisco Nexus Dashboard Insights 以 1 秒的低粒度接收来自交换机和计算节点的指标。然后,它使用基线、相关性和预测算法分析原始指标,深入洞察流量模式。在拥塞检测方面,Nexus Dashboard Insights 可检测数据平面异常,如丢包、延迟、微爆发等。它使用直观的图形用户界面显示流量的端到端数据包路径,以及丢包和丢包的原因。
图 7-13 显示了 RoCEv2 流量的端到端路径、平均网络延迟和 Nexus Dashboard Insights 上的突发。
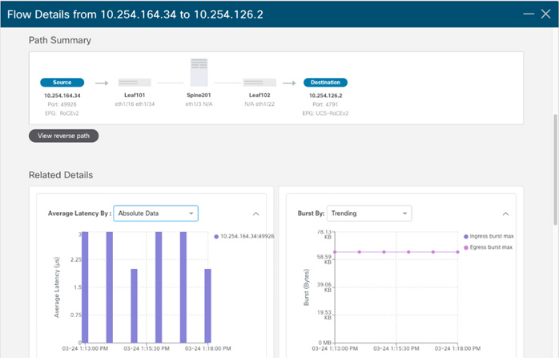
Figure 7-13 Monitoring RoCEv2 in Cisco Nexus Dashboard Insights
Metric Export Mechanisms
对于定制开发的应用程序或脚本而言,指标导出机制是一个重要的考虑因素。第 3 章 "指标导出机制 "一节中解释的大部分细节也适用于无损以太网网络。
请特别注意第 3 章介绍的指标输出建议。使用命令行输出和 SNMP 在历史上很常见,但现在使用 API 已成为常态。对于大规模的低粒度度量导出,流式遥测是最佳选择,而且正在被迅速采用。
Cisco Nexus Dashboard Fabric Controller 和 Nexus Dashboard Insights 默认选择最佳导出机制。
以下小节简要介绍了 Cisco Nexus 9000 交换机上的指标导出机制,不再重复第 3 章中的说明。
SNMP
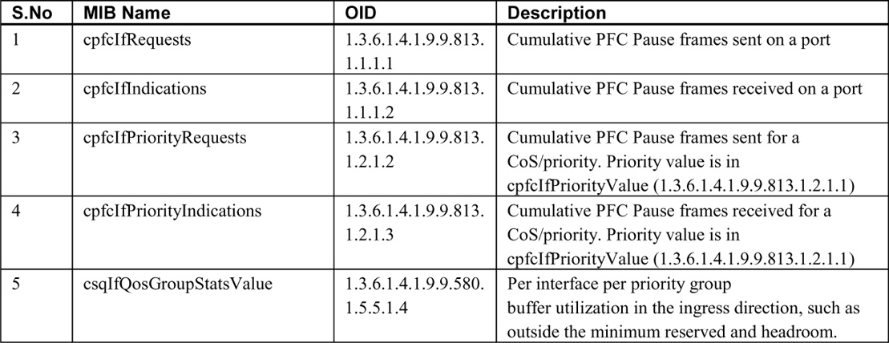
表 7-3 提供了可检测启用 LLFC 和 PFC 的端口拥塞情况的指标的 SNMP MIB。
Note the following points: 请注意以下几点:
1. Cisco Nexus 9000 交换机上的 PFC 计数器可由 CISCO-PFC-EXT-MIB 监控,该 MIB 包含更多计数器,如 TxWait 和 RxWait,但表 7-3 没有列出所有计数器,因为 Nexus 交换机在本文撰写时不支持 TxWait 和 RxWait。虽然交换机可能会响应 MIB 请求,但它们的值不会随时间而改变。如果交换机类型支持 CISCO-PFC-EXT-MIB,它还可用于监控 PFC 看门狗。
2. 需要注意的是,多年来,Cisco 设备上的 LLFC 和 PFC MIB 计数器一直受到某些固件版本和交换机型号执行不力的影响。在依赖返回值之前,请验证它们是否与交换机上的命令行输出相匹配。根据返回值 0 进行初步验证是不够的,因为尽管 0 是一个有效值,但它可能不会递增。这将造成没有拥塞的错误提示。
3. IF-MIB 包含接口速度、字节输入和字节输出,可用于计算利用率百分比。
4. 由于 PFC 是通过以太网交换机上的 QoS 实现的,因此监控 CISCO-SWITCH-QOS-MIB 可提供每个队列的指标。
Streaming Telemetry
有关流遥测的详细信息,请参阅第 3 章 "流遥测 "一节。Cisco Nexus 9000 交换机有以下额外注意事项:
1. Nexus 交换机可以从前面板数据端口导出指标,从而实现低粒度指标导出。在撰写本文时,MDS 交换机只能从交换机的管理端口导出指标。
2. Nexus 交换机支持 NetFlow 和 sFlow。不过,流式遥测可导出粒度更小的指标。
3. Cisco Nexus 交换机上的软件遥测功能可导出控制平面信息和接口指标。
4. 此外,Nexus 交换机还支持硬件遥测,可导出粒度(根据交换机类型可低至 1 秒)的指标:
a. 流统计数据导出 (SSX),用于导出原始 ASIC 统计数据。
b. 流量表 (FT),用于导出流量级别信息。
c. 流量表事件 (FTE),用于在满足配置条件时触发通知。
5. Nexus 交换机支持带内网络遥测 (INT),用于监控丢弃的数据包和拥塞的队列。
网络遥测和分析领域发展迅速。我们建议您参考文档和发行说明,了解产品在您的环境中的功能以及如何使用它们。
审核编辑:黄飞
-
以太网存储网络的拥塞管理连载方案(二)2024-02-27 3267
-
以太网存储网络的拥塞管理连载案例(五)2024-03-04 2520
-
以太网存储网络的拥塞管理连载案例(六)2024-03-06 2469
-
以太网和工业以太网的不同2018-10-23 2842
-
以太网保护设计策略和思路2020-12-28 1712
-
工业以太网中流量控制策略的研究2009-03-17 679
-
交换以太网在网络控制系统中的应用2009-06-06 544
-
以太网远程监控系统实现远程监测控制和管理技术设计开发2009-01-20 1475
-
根据VC的执行机构以太网控制系统的设计策略2010-04-21 1101
-
基于BOOTP的工业以太网IP仪表的智能化管理策略2011-02-26 941
-
以太网光纤通道(FCoE)技术问答2011-12-01 1407
-
基于SDN架构的网络拥塞避免策略2017-12-06 1324
-
以太网的分类及静态以太网交换和动态以太网交换、介绍2018-10-07 7836
-
万兆以太网和IP SAN的融合2020-01-24 4408
-
以太网光模你了解多少2023-02-14 2377
全部0条评论

快来发表一下你的评论吧 !
