

100%在树莓派上执行的LLM项目
电子说
描述
ChatGPT的人性口语化回复相信许多人已体验过,也因此掀起一波大型语言模型(Large Language Model, LLM)热潮,LLM即ChatGPT背后的主运作技术,但LLM运作需要庞大运算力,因此目前多是在云端(Cloud)上执行。
然而在云端执行也有若干缺点,一是Internet断线时无法使用;二是或多或少会泄漏个资隐私;三是上传的话语内容会被审查,但审查标准难以捉摸,且已有诸多矫枉过正的案例;四是因为模型已放在云端与人共享,也可能已被他人误导,俗称模型被教坏了。
所以有些人也希望LLM能在本地端(Local)、本机端执行,如此就不怕断线、泄漏隐私、内容审查、误导等缺点。但要能在本地端执行,其LLM就不能太大,目前已经有诸多信息技术专家提出各种尝试,期望能将云端的LLM轻量化、减肥减肥,以便能在运算力有限的本机端执行。
全世界最简单的类GPT语音助理
对此已有创客发起项目,项目名就叫World’s Easiest GPT-like Voice Assistant,即世界上最简单的类GPT语音助理,以此实现完全在本机端执行的GPT语音服务,不需要任何Internet联机。
至于具体技术作法,首先是找一片树莓派单板计算机,例如RPi 4,然后装上麦克风与喇叭,成为语音互动对话的输入输出,而后安装Whisper这套软件,可以将麦克风接收到的语音转成文字,文字喂给LLM。
LLM接收输入后进行推论处理,处理后的结果以文字输出,输出的文字则透过另一个安装软件进行转化,即eSpeak,把文字转成语音后,再透过喇叭发声回复。
用TinyLlama-1.1B模型来实现类GPT语音助理项目
麦克风与喇叭只是末梢,重点是在LLM,哪来的轻量型、本机端执行的LLM?答案是llamafile项目,这个项目将LLM打包成单一个档案,如此可方便地分发(分发distribute,通俗而言指可以轻易地下载文件、传递分享档案)与执行,项目发起者运用llamafile项目中的TinyLlama-1.1B模型来实现类GPT语音助理。

图3 llamafile项目官网画面(图片来源:GitHub)
TinyLlama-1.1B确实是一个娇小的LLM,以GPT-3而言就有175B,B即Billion指的是10亿,LLM的大小通常以参数数目为准,1,750亿个参数的LLM已相当庞大,需要对应强大的运算力才能顺畅执行。
其他庞大的LLM还有MT-NLG,有5,300亿个参数,或5,400亿个的PaLM等,都难以下放到本机端执行,本机端很难有对应强大的运算力来跑模型。而TinyLlama-1.1B顾名思义只有11亿个参数,参数大大减少下,本机端是有足够运算力执行该模型。
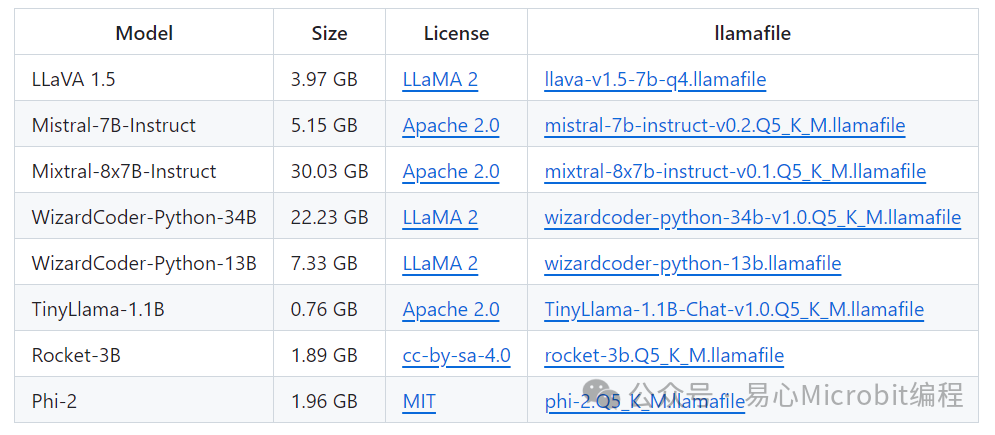
图4 llamafile项目提供多种预训练模型,目前以TinyLlama-1.1B最小,仅760MB(图片来源:GitHub)
当然,上述所言均是预训练模型(Pre-Train Model),或近期常称为基础模型(Foundation Model, FM),后续还是可以依据个人需要再行训练与调整,以便有更精准、更切合需求的推论结果。
这个类GPT语音助理项目完成上述后,实际测试的结果是,多数的发话询问后需要15秒左右的时间才能回复,复杂的询问则要更久的时间。有人可以等或觉得这时间还可以,若觉得太慢或许可以改用运算力更强的RPi 5单板计算机,可能可以快一点。
值得注意的是,这个项目不是用语音关键词(如Hey! Siri或OK! Google)来唤醒助理,而是设置一个按钮,按下去后才让树莓派开始接收语音询问。
另外,这整个项目用的都是开放源代码及免授权费的软件与模型,所以实现成本大概只有单板计算机、喇叭、麦克风、按钮等硬件而已。
其他技术细节包含llamafile与Raspberry Pi OS不兼容,所以在树莓派上是改安装Ubuntu Linux,更具体而言是64位的Ubuntu Server 22.04.3 LTS。另外,当然也要安装Python才能操控树莓派的GPIO接脚,从而能读取按钮状态(是否被按下)。
小结
最后,这肯定不是第一个也不是最后一个LLM本地端化的尝试,各种尝试正前仆后继地进行着,有的是提供压缩工具将原本肥大的LLM加以缩小,有的干脆是原生训练出轻量的LLM,现阶段可谓是百家争鸣。
而笔者个人的看法,1.1B的LLM已经很小,或许未来可以更小,但现阶段可能改用更强的硬件会更务实,例如使用有GPU的桌面计算机,或给树莓派加装AI硬件加速器等,以便让类GPT语音助理更快速响应。
审核编辑:刘清
-
Pidora下载 (社区对Fedora在树莓派上的移植)2014-07-01 6596
-
在linux\Mac下,如何不通过vnc来启动树莓派上的gui程序2014-09-11 8010
-
在树莓派上安装和使用MySQL2016-01-13 13610
-
在树莓派上用Wolfram语言拍照2016-01-26 5719
-
在树莓派上搭建51单片机开发环境2016-03-28 41017
-
树莓派上运行pulse sensor2016-07-05 6529
-
如何在树莓派上运行Fedora2020-09-08 4926
-
如何将ubuntu安装到树莓派上2022-08-08 4538
-
在树莓派上使用TuyaOS link SDK的智能门铃2022-11-01 1828
-
树莓派上的Kubernetes2022-11-17 781
-
在树莓派上搭建Kubernetes智能边缘集群2022-12-09 867
-
人脸识别指南:如何在树莓派上安装和设置 Dlib2025-03-24 1946
-
不要等Manus的邀请码了,树莓派上也能实现 AI Agent !2025-03-25 1889
-
如何在树莓派上安装并运行 Arduino 集成开发环境!2025-07-01 4906
-
C++ 与 Python:树莓派上哪种语言更优?2025-07-24 1403
全部0条评论

快来发表一下你的评论吧 !
