

英伟达和AMD新芯片,突破PCIe限制
描述
学过微处理器的同学可能还记得,最初的8086/8088处理器没有浮点单元。主板通常有一个额外的插槽,用于可选的8087 数学协处理器。数学协处理器进入了 CPU 本身,如今,CPU 没有可选的数学协处理器。
然而, SIMD 处理器(例如GPU)有多种选择。众所周知,GPU 可以比 CPU 主机更快地加速数学处理(例如矩阵运算)。
随着Nvidia GH-200 处理器 和AMD MI300A APU的推出,市场正在见证“8087 时刻”——即 CPU 吸收外部性能硬件。Nvidia 和 AMD 都已将 GPU 纳入处理器中,其结果是 HPC 性能大幅跃升,并预示着未来的发展。
再见 PCI
AMD 和 Nvidia 的 GPU 都依赖 PCI 总线与 CPU 进行通信。CPU 和 GPU 有两个不同的内存域,数据必须通过 PCI 接口从 CPU 域移动到 GPU 域(并返回)。
使用第 5 代 PCIe 总线中全部 16 个通道的 GPU 的最大带宽约为 63GB/s。此瓶颈将限制 CPU 和 GPU 之间的内存移动。
Nvidia GH200 通过 900 GB/s 双向 NVLink-C2C 连接 Grace CPU 和 Hooper GPU。结果大约快了 14 倍。此外,GH200 还带来了单一共享 CPU-GPU 内存域的优势。无需通过 PCI 总线在 CPU 和 GPU 之间移动数据。如图 1 所示,CPU 和 GPU 对所有内存具有一致的视图。CPU内存高达480GB LPDDR5X(带ECC),GPU具有96GB HBM3或144GB HBM3e。总的相干(单域)内存在 576GB 到 624GB 之间。
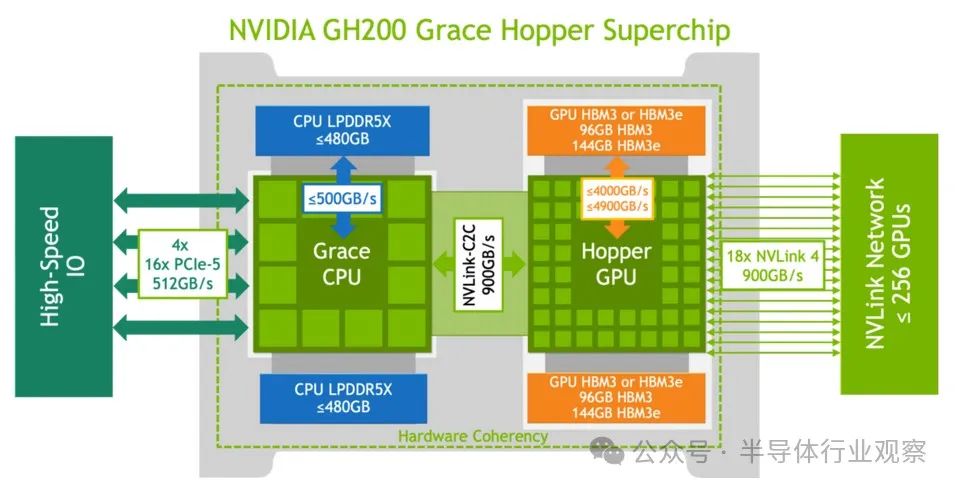
当前的 AMD Instinct MI300A APU 中采用单一内存域,具有 128 GB HBM3 内存,使用 Infinity Fabric 在 CPU 和 GPU 之间一致共享,封装峰值吞吐量为 5.3 TB/s 。 虽然 MI300A 目前不支持像 GH200 那样额外的 DDR 内存扩展,但 CXL 是一个值得将来记住的词。
对于 GH200 和 MI300A,关键的突出短语是“呈现单个存储域”。在传统的CPU-PCIe-GPU组合中,GPU内存量通常小于CPU内存,数据必须通过PCIe接口进行混洗。这两个新设计消除了这个瓶颈。单个大内存域一直对 HPC 有吸引力,而 GenAI 的增长加速了这种需求(即,能够在内存中加载大型模型并使用 GPU 运行它们)。对于传统 GPU,GPU 内存量限制了模型大小,需要采用分布式 GPU 方法。(注:GH200 可以通过外部 NVLink 连接,创建海量统一内存;例如,Nvidia-AWS NLV32可以提供高达 20 TB 的统一内存。)
离你的桌面并不远
技术领域明显的趋势之一是从昂贵的新技术市场转向低成本的大宗商品市场。高性能计算也不例外。随着市场需求,从多核到高级内存的一切都已从高端转移到“手机”。迁移到单个内存域就是这些变化之一。
最近,在 Linux 基准测试网站Phoronix上,杰出的测试员Michael Larabel在 GH200 工作站上运行了 HPC 基准测试。该系统由德国的GPTshop.ai提供。
据了解,系统塔式机箱配备 GH200 Grace Hopper Superchip,配备 576G 内存、双 2000+ W 电源、QCT 主板以及多种配置选项,包括 SSD 和 NVIDIA Bluefield/Connect-X 适配器。一项有趣且有用的功能是 TDP 可以从 450W 编程到 1000W(CPU + GPU + 内存),这在非数据中心环境中应该很有用。另外,默认风冷噪音据称为25分贝。液体冷却也是一种选择。
然而,桌面超级工作站并不便宜。目前可用的型号 GH200 576GB起价为 47,500 欧元(根据 Phoronix 的说法,由于在欧盟以外地区运输时无需缴纳 19% 的增值税,因此该价格相当于 41,000 美元)
这个价格可能看起来很高,但考虑到具有 80 GB HBM2e 内存的 Nvidia H100 PCIe GPU 目前的市场价格在 3 万美元到 3.5 万美元之间。这不包括为 GPU 供电和运行的主机系统。此外,用户还受到 80GB GPU 内存的限制,该内存通过 PCIe 总线与主内存域分开。
GPTshop工作站提供576GB的单域内存。HPC 和 GenAI 用户会发现这半 TB 的 CPU-GPU 内存很有吸引力。
初步基准
借助 GPTshop,Phoronix 能够远程运行多个基准测试。基准应被视为初步的,而不是最终的绩效衡量标准。特别是,基准测试仅针对 CPU,没有使用 Hopper A100 GPU。因此,基准图是不完整的。Phoronix 计划在未来测试基于 GPU 的应用程序。
据 Phoronix 称,Ubuntu 23.10 与 Linux 6.5 一起使用 GCC-13 作为标准编译器。使用类似的环境来测试可比较的处理器,包括 Intel Xeon Scalable、AMD EPYC 和 Ampere Altra Max 处理器。完整的列表可以在Phoronix 网站上找到。
此外,没有可用于基准测试运行的功耗数据。据 Phoronix 称,NVIDIA GH200 目前似乎没有在 Linux 下公开任何 RAPL/PowerCap/HWMON 接口,仅用于读取 GH200 的功率/能源使用情况。系统上的BMC确实通过Web界面暴露了整个系统的功耗,并且功率数据没有通过IPMI暴露。
尽管存在这些限制,一些重要的基准测试还是首次在 Nvidia 之外的 GH200 上运行。
好奥莱 HPCG
Phoronix 报告的第一个测试是标准HPCG内存带宽基准测试,如图 2 所示。
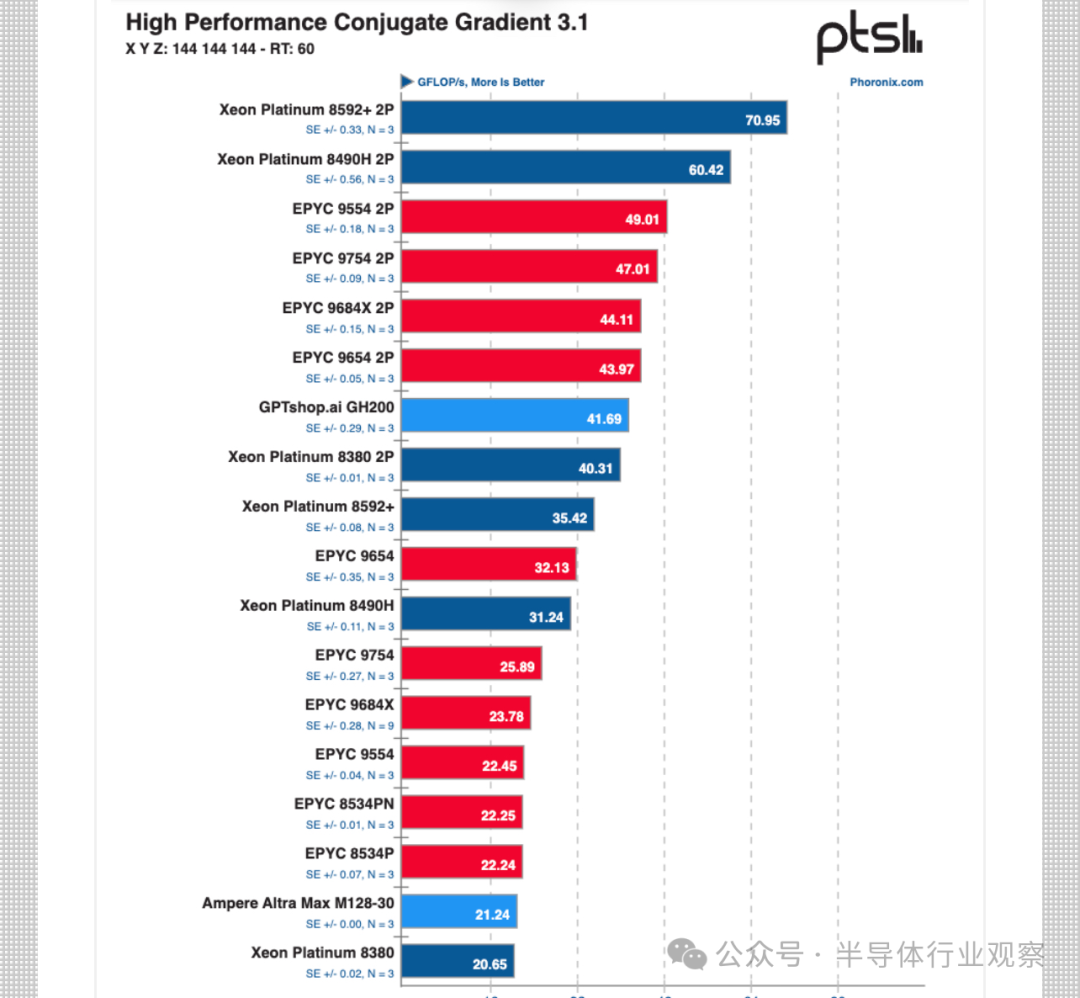
可以看出,GH200 Arm 的性能达到了可观的 42 GFLOPS,略高于 Xeon Platinum 8380 2P(40 GFLOPS),略低于 EPYC 9654 Genoa 2P(44 GFLOPS)。另外值得注意的是 72 核 Arm Grace CPU,其性能几乎是 Ampere Altra Max 128 核 Arm 处理器的两倍。
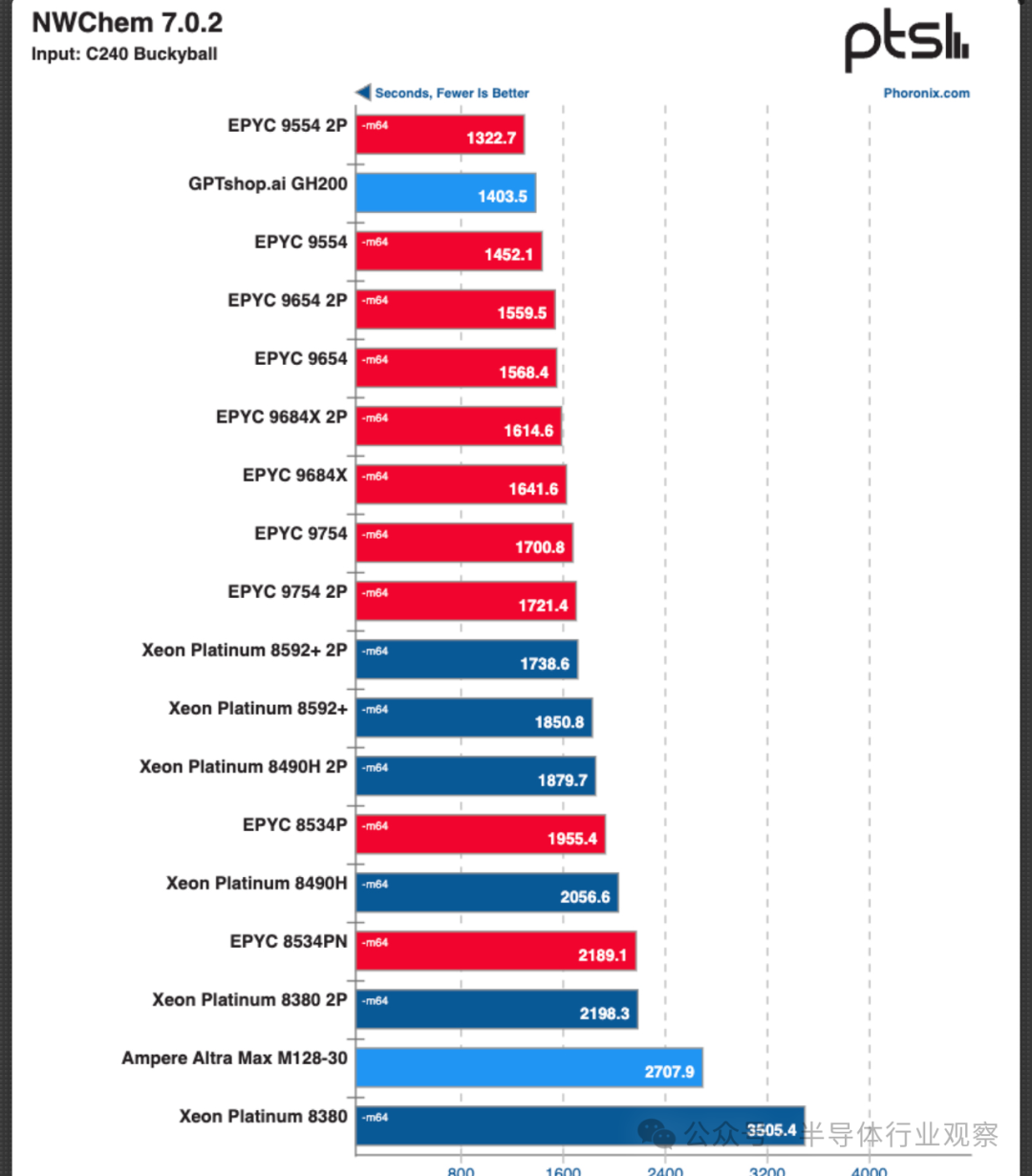
GH200 在其他基准测试中表现良好。最令人印象深刻的结果如图 3 所示。使用 72 核 Arm GH200 的NWChem (C240-Bucky Ball) 运行时间为 1404 秒,仅落后于领先者 128 核 Epyc 9554 (2p),成绩为 1323 秒。
即将发生的事情
Nvidia GH200 和 AMD MI300A 引入了新的处理器架构。与吸收 8087 数学协处理器类似,高端 CPU 也开始吸收 GPU(或 SIMD 处理单元)。然而,这个想法并不是全新的。自 2011 年以来,AMD 已将中等 GPU 集成到其台式机/笔记本电脑APU 处理器中。虽然这些高端处理器可能被认为是“专用”的,因此价格昂贵,但随着时间的推移,对 GenAI 的巨大兴趣可能会将这些设计推向商品价格点。随着更多基准的出现,这个故事将继续发展。
此外,引入具有足够内存的个人高性能工作站,可以在您的办公桌旁运行一些最大的法学硕士,这是一个重要的里程碑。更不用说运行许多大内存 GPU 优化的 HPC 应用程序的能力了。数据中心和云仍将是当今的主力,但必须要说的是“拥有重置按钮”。
-
美国限制英伟达和AMD向中东销售AI芯片2024-05-31 3269
-
美方持续收紧AI芯片对华出口限制,英伟达等巨头面临挑战2024-04-02 2064
-
英伟达和AMD发布适用于台式电脑的新型AI芯片2024-01-10 1755
-
谷歌揭秘Gemini,AMD对峙英伟达2023-12-07 1643
-
美国否认限制英伟达和AMD向中东国家出口AI芯片2023-09-01 1576
-
AMD今年底推AI芯片匹敌英伟达,看好中国人工智能市场2023-08-02 1222
-
AMD正式出击!推出最新AI芯片挑战英伟达2023-06-16 1905
-
美国限制英伟达向中俄出口高端芯片 中方回应2022-09-02 5816
-
英伟达DPU的过“芯”之处2022-03-29 5956
-
英特尔、AMD和英伟达的“芯片之战”开启2021-01-13 2773
-
AMD宣布放开对英特尔CPU和英伟达GPU的兼容性限制2020-11-23 5420
-
AMD研发类似DLSS超采样技术 与英伟达展开对决2020-10-30 4675
-
区块链市场迎来爆发 AMD和英伟达获益颇多2018-02-05 1197
-
高端VR设备起量,英伟达称今年1500万,明年翻倍2016-12-13 2918
全部0条评论

快来发表一下你的评论吧 !
