

AI驱动的雷达目标检测:前沿技术与实现策略
人工智能
描述
深度学习是近年来人工智能领域最为热门和前沿的技术之一,在计算机视觉、自然语言处理、语音识别等方面取得的效果显著,展现出强大的预测、分类以及聚类能力。本期文章我们将简要探讨AI技术在雷达目标检测方向的研究和应用。
1 传统检测方法存在的问题
传统的雷达目标检测方法,主要围绕雷达回波信号的统计特性进行建模,进而在噪声和杂波的背景下对目标存在与否进行判决,常用的典型算法如似然比检测(LRT)、检测前跟踪(TBD)以及恒虚警(CFAR)等。
但实际工程化应用中我们发现,雷达回波信号的统计特性复杂多变,建模匹配难度高,并且检测模型和算法参数对雷达型号、特性及周围环境有很强的依赖性,在不同的探测环境下系统参数难以量化,目标检测的效果常常不尽人意。
2 深度学习技术应用的可行性分析
基于图像的目标检测(Object Detection)是计算机视觉领域的重要研究方向。近些年,随着深度学习技术的快速发展,目标检测算法也从基于手工特征的传统算法转向了基于深度卷积神经网络的检测技术,并具有更好的准确性和鲁棒性。如RCNN、Fast R-CNN、Faster R-CNN和YOLO等典型深度学习目标检测模型,已经在民用及军事领域取得了出色的应用效果。
在雷达目标检测方向,虽然雷达图像相比光学图像信息量较少,在成像机理、目标特性、分辨率等方面也存在差异,但随着现代雷达技术的发展,空间分辨率、多普勒分辨率等技术指标的逐步提升,回波图像的质量和信息量显著提高,基于深度学习的雷达目标检测在理论上分析是可行的,该技术的研究和应用是解决传统算法瓶颈的新思路、新方法。
3 算法概要原理
基于深度学习的目标检测算法原理框图如图1所示。

图1 深度学习雷达目标检测算法原理框图 流程上主要包括数据特征预处理、特征提取、分类器和检测判决四个部分。其中数据特征预处理负责将逐帧的回波B显图像转换到特征空间,即通过特定的统计方法将图像信息转化成算法要求的量化数据。随后通过深度学习神经网络进行特征提取,这个阶段我们所知的干扰、杂波、噪声及目标必然在某些特征上存在差异,进而分类器可依据提取的特征构建分类模型实现对目标、干扰以及杂波的区分。最后检测判决模块依据分类结果,对疑似目标进行判决输出,形成点迹。
目前,在典型的目标检测算法中,大致可分为“两阶段检测”以及“单阶段检测”两种检测方法。
3.1 两阶段检测算法
两阶段检测算法,先通过选择性搜索方法确定候选区域,再使用深度学习方法对该区域进行特征提取和分类。该算法的代表的Faster R-CNN, 但其检测速度一般情况下难以满足实时性要求。Faster R-CNN结构流程图,如下图2所示。
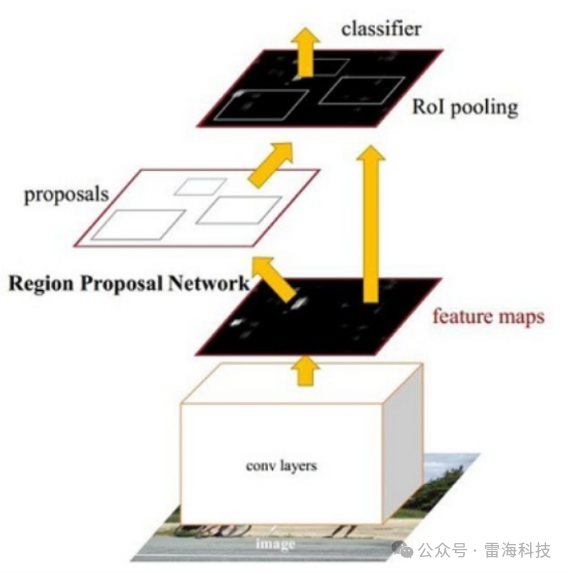
图2 Faster R-CNN结构流程图
Faster RCNN检测部分主要可以分为四个模块:
(1)conv layers。即特征提取网络,用于提取特征。通过一组conv + relu + pooling层来提取图像的feature maps,用于后续的RPN层和取proposal。 (2)RPN(Region Proposal Network)。即区域候选网络,该网络替代了之前RCNN版本的Selective Search,用于生成候选框。这里任务有两部分,一个是分类:判断所有预设anchor是属于positive还是negative(即anchor内是否有目标,二分类);还有一个bounding box regression:修正anchors得到较为准确的proposals。因此,RPN网络相当于提前做了一部分检测,即判断是否有目标。 (3)RoI Pooling。即兴趣域池化,用于收集RPN生成的proposals(每个框的坐标),并从(1)中的feature maps中进行提取,生成proposals feature maps送入后续全连接层继续做分类和回归。 (4)Classification and Regression。利用proposals feature maps计算出具体类别,同时再做一次bounding box regression获得检测框最终的精确位置。
3.2 单阶段检测算法
单阶段检测算法,采取端到端的检测,只进行一次前馈网络计算,检测速度得到了大幅提高。具有代表性的算法模型是,YOLO(You Only Look Once)。
以yolov5模型为例,其模型结构如图3所示,主要包括以下组成部分:
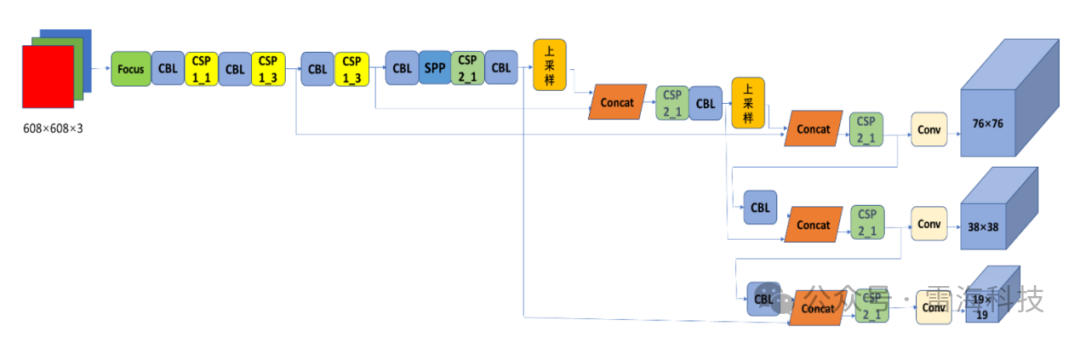
图3 YOLOv5 的网络结构
(1)输入端:YOLOv5的Head网络由3个不同的输出层组成,分别负责检测大中小尺度的目标。 (2)Backbone网络:YOLOv5使用CSPDarknet53作为其主干网络,其具有较强的特征提取能力和计算效率。
(3)Neck网络:YOLOv5使用的是FPN网络,可以融合来自不同特征图层次的信息。
(4)输出端:损失函数,YOLOv5使用的是Focal Loss损失函数,该函数可以缓解目标检测中类别不平衡的问题,提高模型的性能。非极大值抑制(NMS),YOLOv5在输出结果后,会对重叠的目标框进行NMS处理,以得到最终的检测结果。
总体来说,YOLOv5的模型结构相对简单,其中使用了多种技术和策略,如CSP结构、FPN网络、Mish激活函数和Focal Loss损失函数等,以提高模型的性能和鲁棒性。
4 应用示例
这里,我们选用YOLOv5模型实测应用,在100张训练样本的基础上,基于舟山试验场实装雷达环境部署测试,算法推理效果如图4所示,目标自动检测跟踪效果如图5所示。
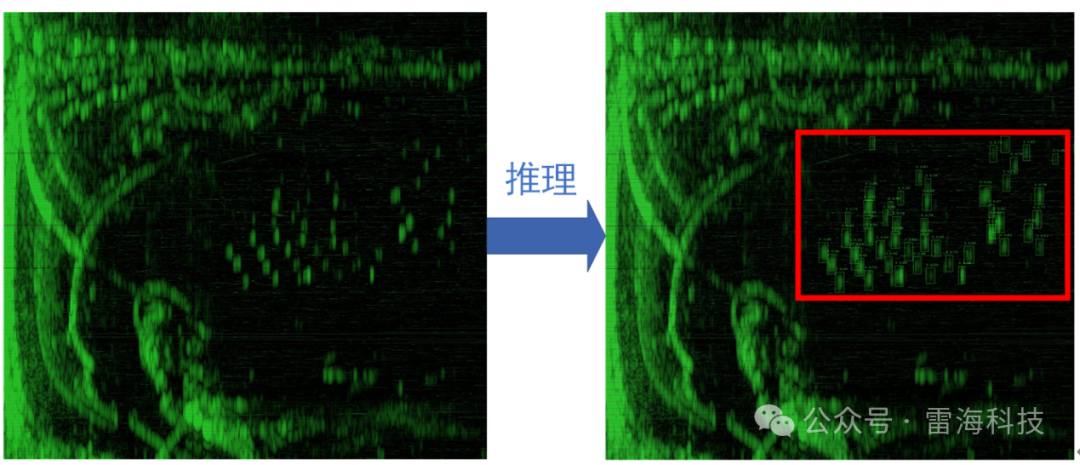
图4 算法推理效果图
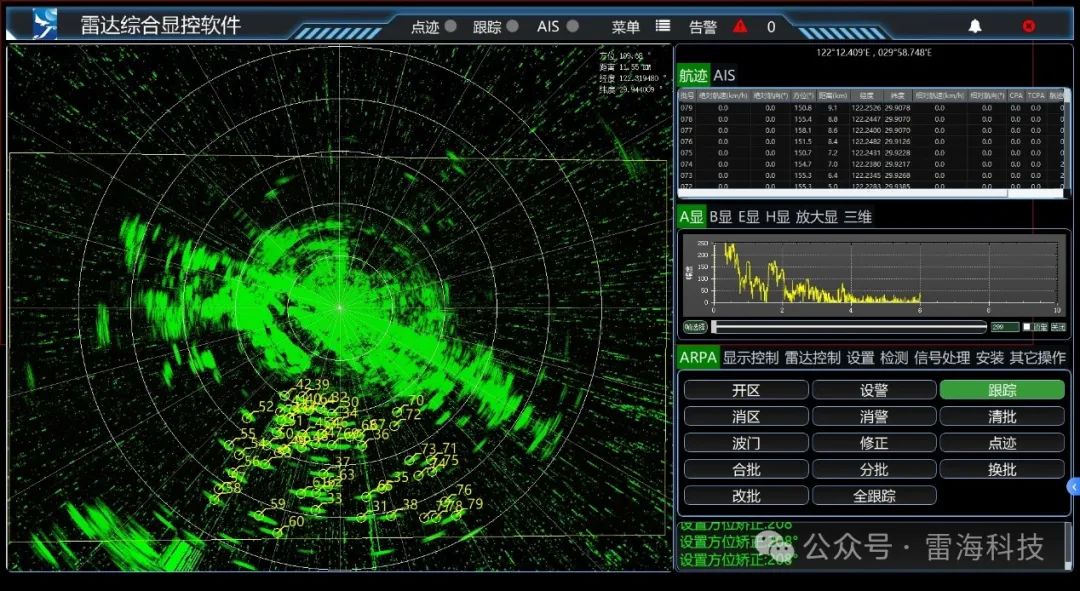
图5 目标自动检测跟踪效果图
5 总结
实际效果表明,基于AI的雷达目标检测技术合理可行,相比传统方法可显著提高杂波区目标检测概率、有效降低虚警率,提升系统整体目标检测精度,具备重要而又长远的研究意义。
【参考文献】
1.《深度学习在雷达目标检测中的应用综述》,施端阳 2.《雷达回波信号的深度学习目标检测识别方法研究》,宋海凌 3.《基于改进型YOLOv3的SAR图像舰船目标检测》,陈冬 4.《基于深度学习的雷达目标检测技术》,刘军伟 5.《基于时频图深度学习的雷达动目标检测与分类》,牟效乾 6.《基于迁移学习的SAR图像目标检测》,张椰
审核编辑:黄飞
-
【「AI芯片:科技探索与AGI愿景」阅读体验】+内容总览2025-09-05 4299
-
声智科技与蚂蚁集团共探声学AI前沿技术2025-07-24 1282
-
智能工业检测:海康威视HK-100C网络控制板的前沿技术2024-10-15 1411
-
【前沿技术】全栈式AI驱动型EDA解决方案Synopsys.ai2023-06-02 1631
-
UWB技术前沿2021-07-26 2682
-
未来汽车前沿技术及其产品的开发应用概述2019-07-19 2783
-
雷达目标检测算法研究及优化2018-02-28 5414
-
电磁效应领域基础与前沿技术 主题论坛2017-11-23 6554
-
FPGA前沿技术更新2015-10-16 4551
-
2014年有望实现的十大前沿技术2014-03-03 11267
-
物联网最新前沿技术应用大赏(图文)2012-08-20 6456
-
IDF 2011展示“互联计算”前沿技术2011-05-07 687
-
影响未来的六大前沿技术2011-05-06 2165
-
纵观全球前沿技术 博览行业领先精品2011-01-05 1994
全部0条评论

快来发表一下你的评论吧 !
