

看看PCIe设备之间的通信方式
描述
在上一篇中,我们介绍了PCIe设备的配置空间,及其设计的目的,最后我们说到了消息路由的设计。所以,这一篇我们就继续这个话题,来看看PCIe设备之间的通信方式吧。
1. PCIe协议栈
PCIe是以包(Packet)为单位传输数据的。和计算机网络类似,其协议也是分层的。
其协议栈主要分为三层:物理层(Physical Layer),数据链路层(Data Link Layer)和事务层(Transaction Layer),如下图所示:
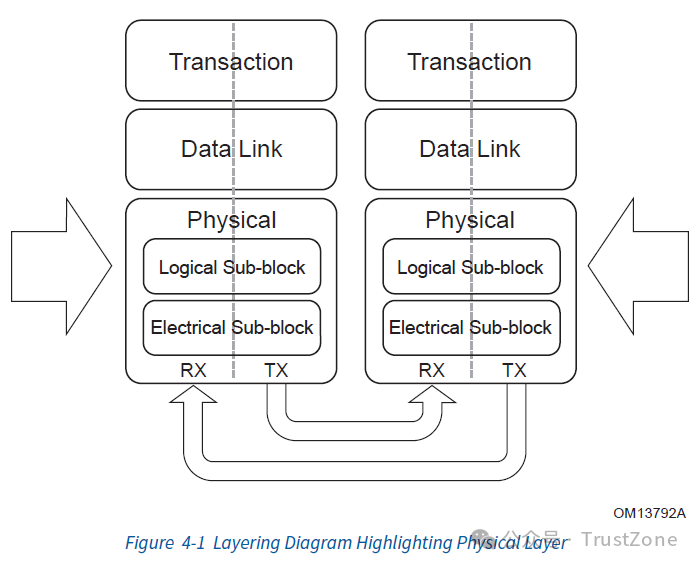
2. 事务层(Transaction Layer)
PCIe的协议栈最上层叫做事务层,这一层定义了所有和用户相关的PCIe的操作,所以这也会时大家最感兴趣的一层。
2.1. 事务(Transaction)
PCIe的所有操作都被称为一个事务(Transaction),这些事务分为四种类型:
内存事务(Memory Transaction)
IO事务(IO Transaction)
配置事务(Configuration Transaction)
消息事务(Message Transaction)
一个事务根据其请求的处理方式又被分为两种:
Non-Posted:每个事务的请求消息发送出去后,会需要一个完成消息(Completion)来完成事务。比如,读内存。
Posted:请求发送后不需要完成消息,属于Fire and forget。比如,写内存和所有的消息事务(这也是唯二的两类请求)
所以,事务层的消息有三类:Non-Posted(NP),Posted(P)和Completion(Cpl)。
2.2. TLP(Transaction Layer Packet)
PCIe的事务请求和完成消息都是以TLP(Transaction Layer Packet)为单位传输的。其结构如下:

TLP Prefix:用来实现一些高级特性,比如精确时间测量(Precision Time Measurement),因为它不是必须的,所以我们先跳过。
TLP Digest:4个字节,可以存放诸如CRC的校验码,不过一般不需要开启,因为后面说的数据链路层已经自带了校验了,这里相当于是双保险。
TLP Header:这个是TLP中最重要的部分,我们后面马上会详细介绍。
TLP Payload:这个是TLP中的数据部分,根据不同的事务类型,其大小也不同。比如,读事务就不需要Payload。另外Payload的大小也是有限制的,它不能超过Max_Payload_Size,最大为4096字节。
2.2.1. TLP头
TLP的头部根据处理地址长度的不同,会有12字节(称为3DW)或者16字节(称为4DW)宽。其前4个字节(第一个DW)是公共的头部,包含了绝大部分的用于描述该事务本身的信息和行为的字段,其后的8个字节(第二个和第三个DW)会根据事务种类的不同而产生变化。其前四个字节如下:
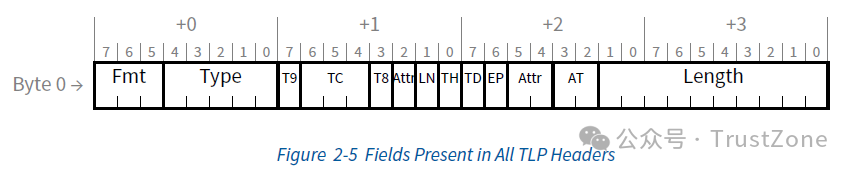
Fmt: TLP头的格式
Bit 7:如果是1,则Fmt必须是100,表示这个头是TLP Prefix
Bit 6:1 = 读事务(TLP头之后没有Payload),0 = 写事务(TLP头之后有Payload)
Bit 5:1 = 使用32位地址,头部长度12字节(3DW Header),0 = 使用64位地址,头部长度16字节(4DW Header)
Type:事务类型,表示这个事务是什么类型的事务,比如内存事务、IO事务、配置事务、消息事务等
LN(Lightweight Notification):用于标识当前这个内存请求或者完成消息是不是一个轻量级通知
TH(TLP Hints):用于表示TPH(TLP Processing Hint)是否启用和TPH TLP Prefix是否存在
TD(TLP Digest):1 = 有TLP Digest,0 = 没有TLP Digest
EP(Error Poisoning):1 = 有错误,0 = 没有错误
AT(Address Translation):虚拟化相关的字段,00 = 无地址转换,01 = 需要地址转换,10 = 地址转换已完成,11 = 保留
Length:Payload的长度,单位为DW(Double Word),1DW = 4字节
这里由两个字段TC和Attr我们没有介绍,因为它们是事务描述符的一部分,我们马上就会介绍。
2.2.2. 事务描述符(Transaction Descriptor)
为了帮助通信的双方知道对方的信息和对消息的处理方式进行描述,在TLP的头中有几个公共的字段,合在一起被称为事务描述符:事务ID(Requester ID和Tag两个字段),消息的属性(Attr字段),流量分类(TC字段)。
虽然TLP头中第二个DW开始的部分会随着请求类型的不同而发生变化,但是这四个字段几乎会在所有的消息中存在(某些情况下Tag会被忽略),所以这里我们用一个内存请求的消息来做例子,展示它们在TLP中的位置:
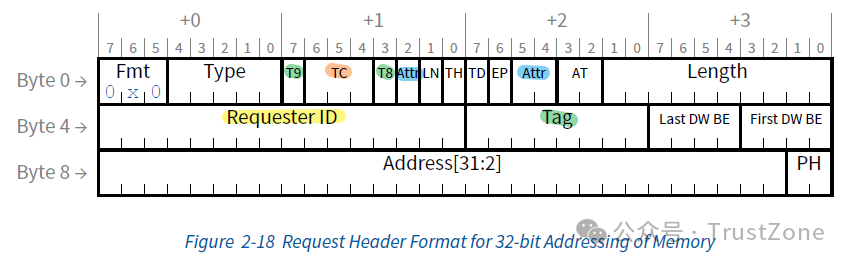
2.2.2.1. 事务ID(Transaction ID)
事务ID由Requester ID和Tag两个字段组成,用于标识一个事务。其中,
Requester ID:一共16个bit,用于标识发起这个事务的设备,是请求发起者的BDF
Tag:一共10个bit,每个发出的TLP都会被赋予一个唯一的标签,帮助PCIe进行数据传输的跟踪和管理,比如并行处理,流控或乱序处理。这里注意T8和T9两个bits,它们和其他的tag的bits不在一起(绿色高亮),且需要修改10-Bit Tag Requester Enable配置寄存器启用
2.2.2.2. 消息属性(Attributes)
消息属性一共有三个bits:高两位 Attr[2:1](Byte 1 - Bit 2,Byte 2 - Bit 5)用于控制消息处理的顺序,而最低位 Attr[0](Byte 2 - Bit 4)用于控制Coherency。
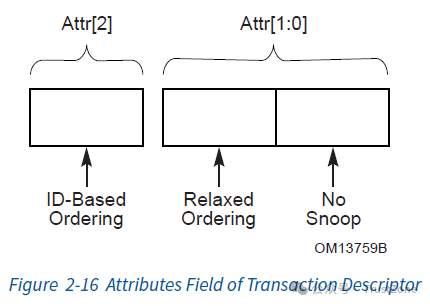
2.2.2.2.1. 消息处理顺序(Ordering)
Attr[2:1]这两个Bits用于控制消息处理的顺序,一共有四种情况:
| Attr[2] | Attr[1] | 顺序类型 | 说明 | |
|---|---|---|---|---|
| 0 | 0 | 强制顺序 | 默认值,不允许乱序处理 | |
| 0 | 1 | Relaxed Ordering | 允许接收者在当前请求没有完成的时候,同时处理任何后续的请求 | |
| 1 | 0 | ID-based Ordering | 允许接收者在当前请求没有完成的时候,同时处理来自其他设备的请求 | |
| 1 | 1 | 无序 | 相当于是Relaxed Ordering和ID-based Ordering的并集,允许接收者在当前请求没有完成的时候,同时处理任何的请求 | |
2.2.2.2.2. No Snoop
NoSnoop(Attr[0])使用来控制缓存一致性的。默认的情况下(值为0),PCIe会对请求进行缓存一致性的处理,比如一个内存的读请求,它会保证先去读Cache,如果没有读到再去读主内存。但是如果这个值为1,PCIe就会直接跳过Cache,去操作主内存。这样就有可能导致一致性的问题,因为有可能Cache中的内容还没有被写入主内存中,这样就读到了错误的值。
但是,这并不代表这个flag没有用,如果我们非常确定我们不需要考虑缓存,那么我们可以启用这个flag,直接去操作主内存,从而提高性能。
当然,也正因为有一致性的问题,所以这个功能被很多事务禁止使用了:比如配置事务、IO事务、大部分的消息事务和MSI(跳过缓存发起中断会导致DMA等功能出错,读到脏数据)等。
2.2.2.3. 流量分类(Traffic Class)
Traffic Class总共有3个bit,用于把所有的事务分成8个不同的类别,用于流控。
基于TC的流控是通过和VC(Virtual Channel)合作来实现的:
PCIe中的所有物理链路(Link)都可以创建多个VC(Virtual Channel),而每个VC都独立工作,并有着流量控制机制。
一个或者多个TC可以被映射到一个VC上,这样就可以通过操作TLP的TC来控制TLP走的VC了。
VC通过信用机制来控制发包速度,每个VC都有着自己的Credit Pool,如果一个VC的Credit不为0,那么它就可以发送TLP,并且消耗特定的Credit。每个VC的Credit也会在特定的时候补充,保证通信不会中断。
TC的默认值是0,也是所有设备必须实现的。它被Hardcoded到了VC0上,所以如果没有设置TC,那么所有的TLP都会走VC0。
最后,如果两个包有了不同的VC,或者不同的TC,那么它们之间将没有顺序的保证。
这里我们主要了解TC到VC的映射就好,关于VC的具体机制,我们会在后面数据链路层介绍。以下是一个TC和VC相互合作的配置的例子。通过这种方法,我们就可以对PCIe进行流量控制啦!
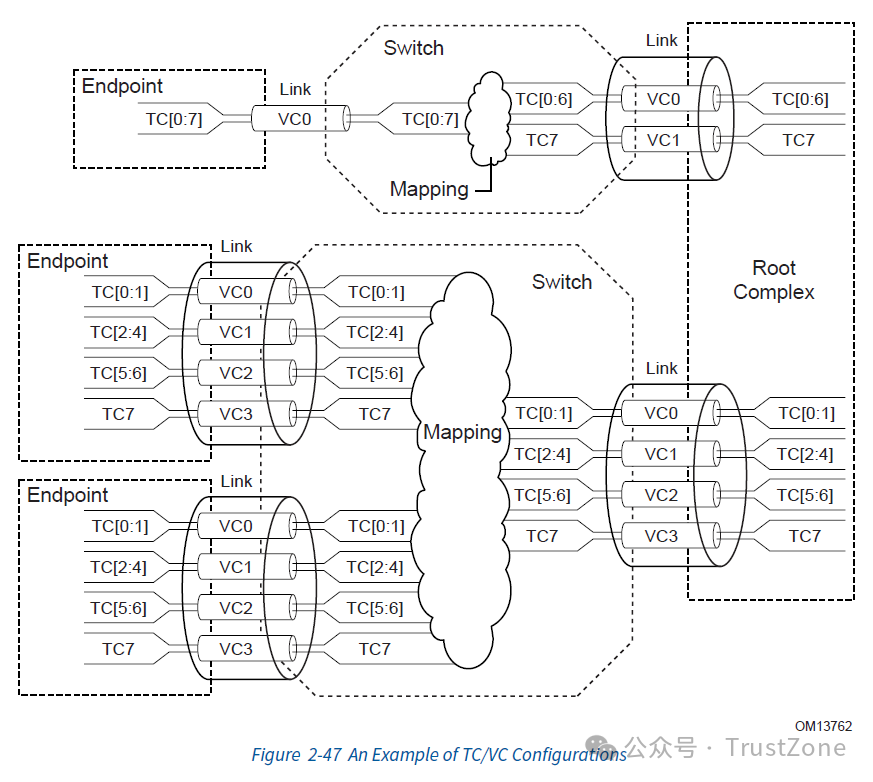
2.3. TLP事务路由
有了事务ID,我们可以很容易的了解当前事务的源是谁,然而为了能让通信双方通信,我们还需要知道事务的目的地是哪里,这样我们才能把事务发送到正确的地方。
在PCIe中,不同类型的事务中会使用不同的字段和方法来指定目的地,但是总结起来只有两种:
通过具体的地址来指定目的地:这种路由方式叫做基于地址的路由(Address-Based Routing)。这种方式主要用于内存事务(Memory Transaction)和IO事务(IO Transaction),通过需要访问的地址,我们就可以通过我们上一篇中介绍的路由机制来进行路由了。
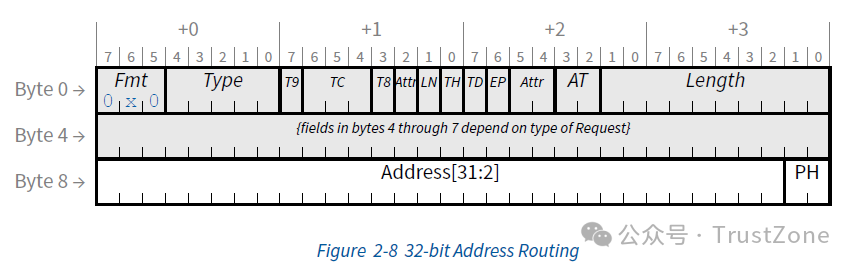
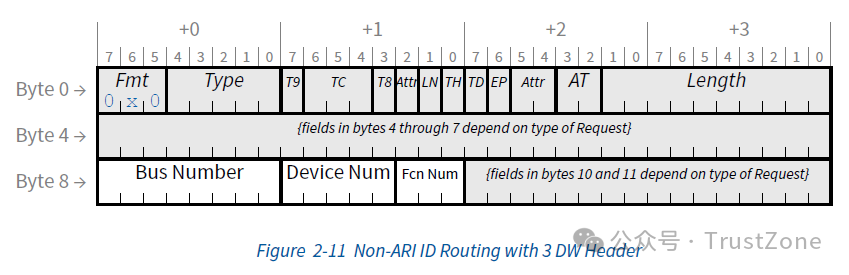
通过BDF来指定目的地:这种路由方式叫做基于ID的路由(ID Based Routing)。这种方式主要用于非内存访问型的事务,比如:配置事务(Configuration Transaction),消息事务(Message Transaction)和事务完成的消息通知(Completion)。
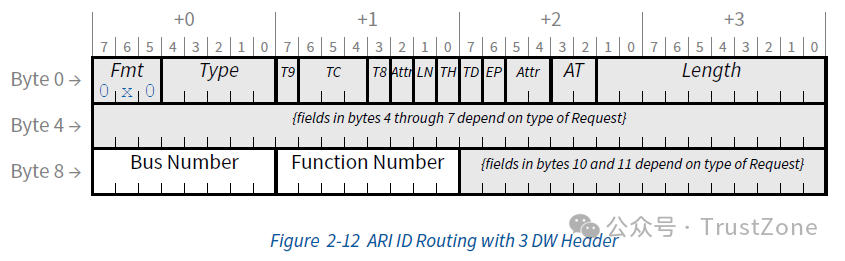
另外,我们上一篇还提到了一种特殊的ID分配方式ARI(Alternative Routing ID),它的唯一区别就是把Device Number的5个Bit给了Function Number,用以支持更多的Function,如下:
2.4. TLP小结
好了,到此我们已经把最核心的TLP的公用字段都介绍完毕了,包括TLP主题格式,事务如何分类,如何路由,如何进行流控等等。这里,为了再来整体的来看一下事务层的处理,我们可以参照Intel Cyclone 10的总体框图,如下:
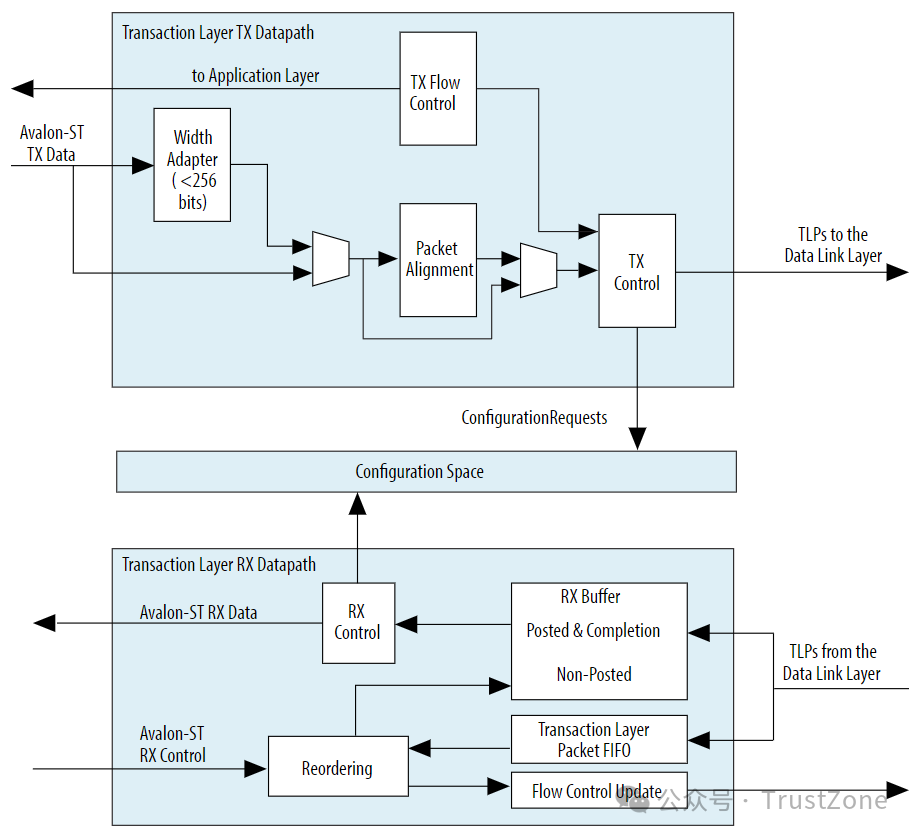
当然在TLP的头中,我们仍然有很多字段没有涉足,这些字段都和具体的事务类型相关,所以我们在这一篇中就不会过多的深入了。毕竟,我们这一篇主要是想聚焦在PCIe的通信协议本身上,来展示PCIe是如何进行通信的,关于每个具体的事务及其格式,我们会放在后面单独的说。
3. 数据链路层(Transaction Layer)
当事务层将事务消息准备好之后,就会向下传递给数据链路层(Data Link Layer)。对于我们发送的事务消息来说,数据链路层主要负责一件事情:保证事务消息能正确的传输到目的地。
数据链路层传输的包主要包括两种,一种用于传输TLP事务消息,一种用于传输数据链路层的控制消息,比如功能(Feature)控制,流量控制,电源管理等等。这两种类型的包通过物理层的Token来进行区分:STP(Start of TLP)表示TLP消息,SDP(Start of DLLP)表示控制消息(DLLP,Data Link Layer Packet)。我们这里一个一个来看。
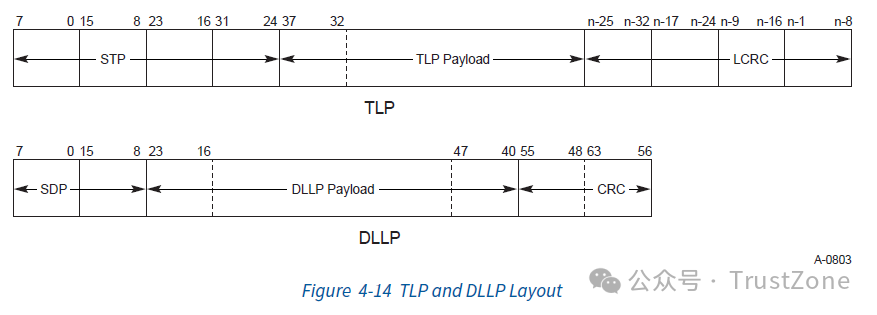
3.1. TLP事务消息的传输
3.1.1. 数据包格式和数据发送
为了达到这个目的,数据链路层会对数据包再进行一层封装:
在包的前方添加一个序列号(Sequence Number),占用2个字节,用于保证包发送的顺序。这个序列号是每个Link独立的,只有上下游两端保存的序列号(NEXT_RCV_SEQ)一致,才会被对端接收。在包的后方添加一个CRC校验码,叫做LCRC(Link CRC),占用4个字节,用于保证包中数据的正确性。注意,计算CRC的时候,刚刚添加的序列号也会被纳入计算范围中。
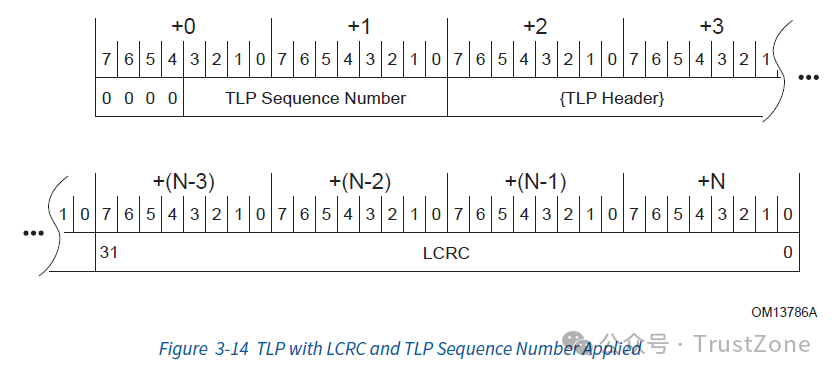
封装完成后,为了保证成功的发送,数据链路层会先将包保存在Retry Buffer中,再转交给物理层(Physical Layer)进行发送。在每条消息发送完毕之后,发送方会等待接收方发送ACK消息,如果接收到的返回消息是失败消息,比如Seq错误,CRC校验错误,或者任何物理层的错误,发送方就会把Retry Buffer中的消息拿出来重新发送。[1](3.6 Data Integrity Mechansisms) 。
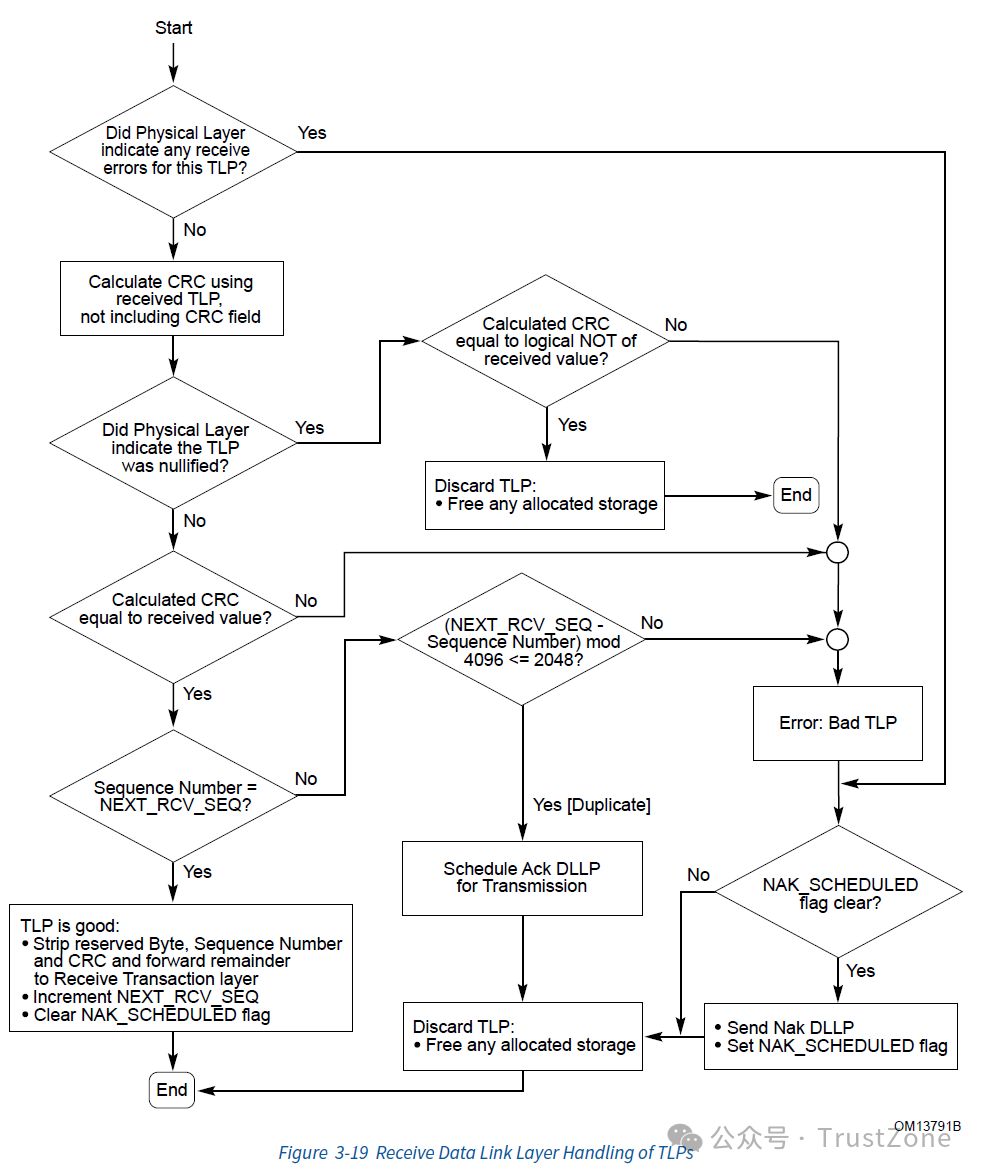
3.1.2. 数据接收
对于数据的接收方,操作流程则相反。接收方会检查接收到的数据包的序列号和CRC是否正确,如果不正确,就会发送一个Nak消息,要求发送方进行重传。如果正确,就会回发一个Ack消息,表示接收成功,而此时发送方在收到了ACK消息后也可以将其从Retry Buffer中移除。这样,数据链路层就保证了TLP的正确传输。[1](3.6 Data Integrity Mechansisms) 。
更加具体的数据接收处理流程如下:
3.2. 控制消息:DLLP(Data Link Layer Packet)
除了传输TLP数据包之外,数据链路层还需要很多专门用于控制的数据包,比如上面提到的Ack和Nak,这些数据包叫做DLLP(Data Link Layer Packet)。其格式如下:
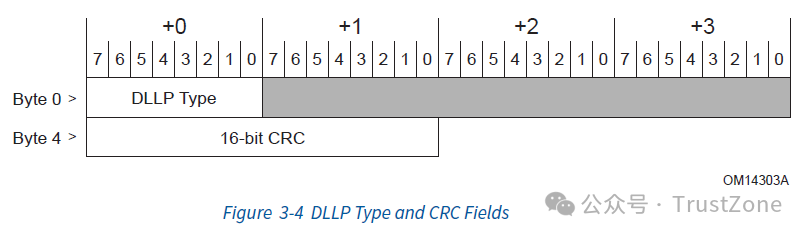
DLLP中DLLP Type用来指定包的类型,而最后16位的CRC用来做校验,其主要分为以下几种类型:
| 名称 | Type | 描述 | 说明 | |
|---|---|---|---|---|
| Ack | 00000000b | 用于确认接收到的TLP数据包 | 默认值,不允许乱序处理 | |
| Nak | 00010000 | 用于拒绝接收到的TLP数据包 | 允许接收者在当前请求没有完成的时候,同时处理任何后续的请求 | |
|
|
(Type较多,后面来说) | 用于流量控制,P/NP/Cpl表示流控类型 | 允许接收者在当前请求没有完成的时候,同时处理来自其他设备的请求 | |
| MRInitFC1/MRInitFC2/MRUpdateFC | <0111/1111/1011>0xxxb | 用于流量控制,P/NP/Cpl表示流控类型 | 相当于是Relaxed Ordering和ID-based Ordering的并集,允许接收者在当前请求没有完成的时候,同时处理任何的请求 | |
| PM_* | 00100xxxb | 用于电源管理,告知对端当前的电源状态 | ||
| NOP | 00110001b | 用于保持链路活跃,防止链路被关闭 | ||
| Data_Link_Feature | 00000010b | 用于告知对端当前链路的特性,如支持Scaled Flow Control | ||
| Vendor-specific | 00110000b | 用于支持厂商自定义的DLLP,实现厂商特有功能 |
3.2.1. Ack/Nak
我们在TLP事务消息传输的里就提到过Ack和Nak消息,它们可以说是DLLP中最常用的消息了。功能顾名思义,Ack表示接收成功,Nak表示接收失败,需要重传。这两个包的格式如下:
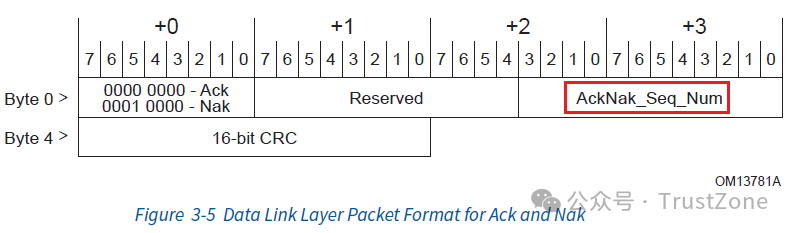
其中,AckNak_Seq_Num表示当前已经收到的最新的消息序号,所以和TCP类似,PCIe的Ack和Nak可以进行批量操作:无论是Ack还是Nak,当发送方收到这个消息之后,就可以将Retry Buffer中比这个序号老的消息全部移除了,所以Ack/Nak时只需要将最新的序号带上即可。Ack/Nak的差别在于:如果是Nak,那么发送方在移除之后,需要对Retry Buffer中这个序号之后的消息全部进行重传。
最后,DDLP的重传是由次数限制的,默认阈值是4次。如果超过四次,就出触发物理层开始重建(retrain)链路。如果依然失败,就会将该链路关闭。
3.2.2. VC(Virtual Channel)与流量控制
在说TLP的时候,我们提到了PCIe的流量控制是通过将TC(Traffic Class)映射到VC(Virtual Channel),并且利用VC的信用机制来实现的。这里我们就一起来看看这个信用机制吧!
数据链路层中的信用额度管理有两个重要的特点:
不同处理方式是的TLP消息有着单独的信用额度管理:Posted(P),Non-Posted(NP)和Completion(Cpl)。这三种消息的信用额度是独立的,互不影响。
每个VC都有着自己的独立的信用额度管理,而不是Link。也就是说,如果一个Link上有多个VC,那么每个VC都需要单独的初始化和更新。参与流量控制的消息有很多,主要有三类,每一类有三个变种(N/NP/Cpl),我们的流量控制也主要分三步,其细节和统一的消息格式如下:
InitFC1-P/NP/Cpl:接收端设备使用此消息向发送端发起初始化流量控制的流程,并初始化信用额度,这是第一步。这个消息有接收端发起的原因是因为,不同的接收端能力不同,所以应该由接收端根据自己的能力,比如缓存的大小,来决定信用额度的大小。
InitFC2-P/NP/Cpl:用于发送端向接收端确认InitFC1的消息,这是第二步。这个消息中会带有从第一步接收到的信用信息,但是它会被接收端忽略,并没有什么用。另外,这个消息发送之后,发送端将不会再理会任何后续的InitFC1消息了。
UpdateFC-P/NP/Cpl:用于在信用额度初始化完成之后,接收端向发送端对信用额度进行更新。
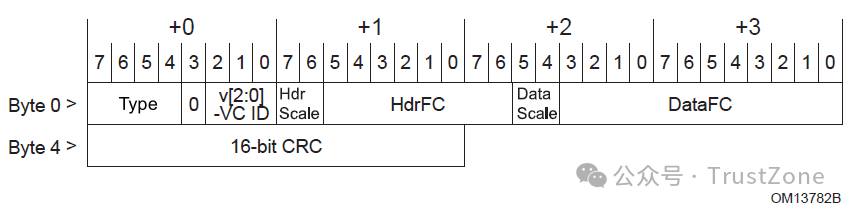
这个消息中各个字段含义如下:
Type:消息ID,映射如下:
| Type | Id | |||
|---|---|---|---|---|
| InitFC1-P | 0100b | |||
| InitFC1-NP | 0101b | |||
| InitFC1-Cpl | 0110b | |||
| InitFC2-P | 1100b | |||
| InitFC2-NP | 1101b | |||
| InitFC2-Cpl | 1110b | |||
| UpdateFC-P | 1000b | |||
| UpdateFC-NP | 1001b | |||
| UpdateFC-Cpl | 1010b |
VC ID(v[2:0]):Virtual Channel的Id,Id一共有3位,代表8个VC。
HdrFC:TLP头部的Credit数量。在发送时,一个TLP头对应着一个Header Credit,不论该TLP的大小如何。
DataFC:TLP数据部分的Credit数量。一个 DW(Double Word,双字,即4字节)对应着一个Data Credit。
举个例子,我们假设有一个64位地址的内存的写请求,数据长度为128字节,那么我们会需要发送一个4 DW的TLP头,加上128字节的Payload,和一个1 DW可选的TLP Digest,所以我们一共最多消耗1个Header Credit,和 (128 + 4) / 4 = 33个Data Credit。
然后,为了保证发送方正常的消息发送,当接收方处理完部分消息后(或者一些特殊情况后),就会根据其当前缓存的大小,向发送方发送UpdateFC消息,告诉发送方,接收方的信用额度还剩下多少。另外,除了这种情况,接收方还会定时的向发送方上报自己的信用额度(最长间隔30us),这么做的原因是为了避免意外情况,如CRC校验出错,导致信用额度上报丢失,从而导致发送方停止发送消息的问题。
最后,数据链路层还支持Scaled Flow Control,即信用额度的数量可以是2的幂次方,这样就可以管理更大的信用额度了:
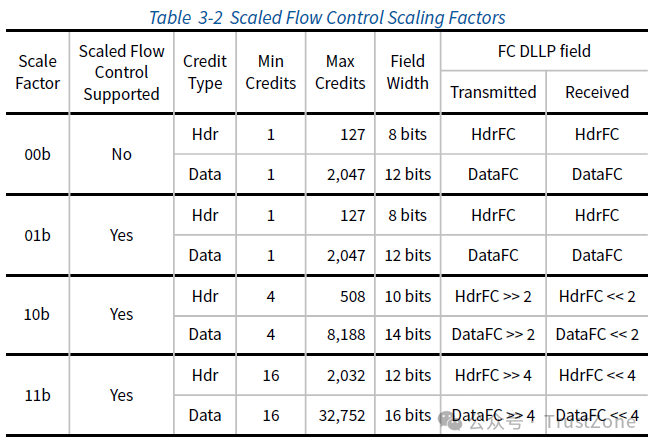
为了帮助理解,我们举一个例子:
注意:如果查看原始的包,在计算时需要注意,HdrFC和DataFC都没有对其到字节上,所以记得做好位运算。
首先,PCIe的Endpoint会向Switch发送如下三条消息来进行流控初始化:

当Switch收到这个消息后,也会向Endpoint发送三条类似的消息,进行反向的初始化。因为流程类似,从这里开始,之后Switch向Endpoint发送的反向流程我们就忽略了。
Switch收到了InitFC1 DLLP后,会使用InitFC2 DLLP进行确认:
到此,等两边InitFC2的消息交换完毕之后,初始化就完成了!
3.3. 数据链路层小结
最后为了帮助理解,我们再来看一下数据链路层的整体架构:
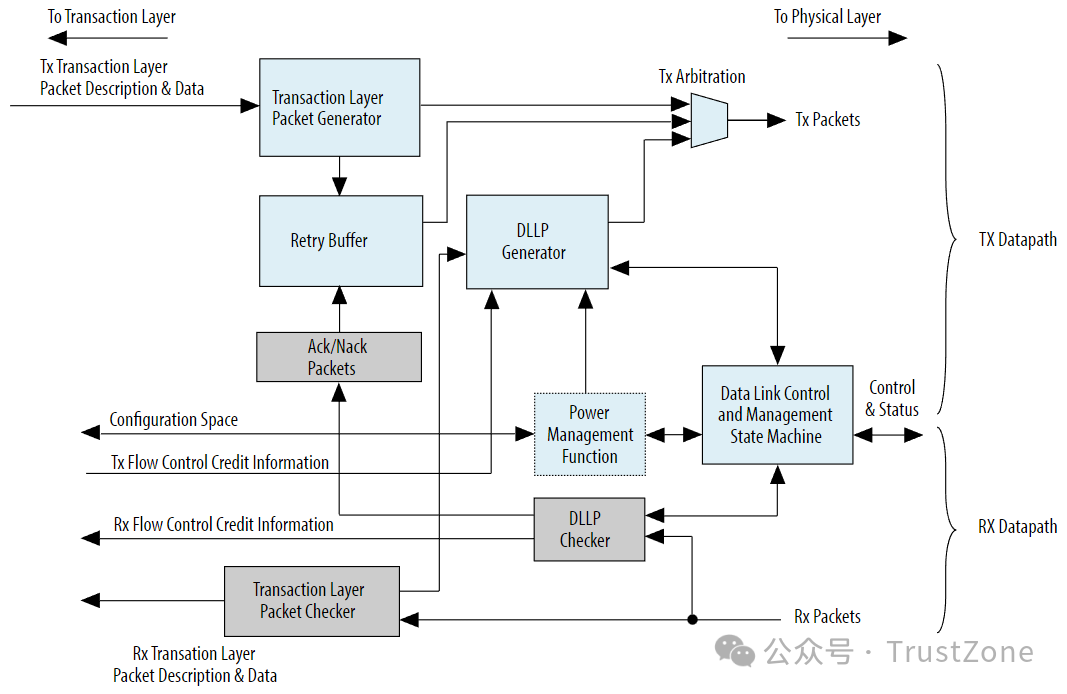
到这里,数据链路层上和数据传输相关的核心内容就都介绍完了!数据链路层中其实还有很多其他的内容,比如Link的初始化,状态机,电源管理,和Vendor-specific DLLP等等,这些内容我们这里就不详细介绍了,有兴趣的读者可以自行查阅PCIe Spec [1]。
4. 小结
好了,由于篇幅原因,我们这一篇就先到这里。这一篇中我们介绍了PCIe的协议栈,并且详细的介绍了事务层(Transaction Layer)和数据链路层(Data Link Layer)是如何工作的,包括事务的分类,各种消息的格式,数据链路层的作用和封装,以及PCIe基于TC和VC的流控机制。
在下一篇中,我们会继续介绍PCIe协议栈中遗留的部分 —— 物理层(Physical Layer)。
审核编辑:刘清
-
PCIe协议分析仪能测试哪些设备?2025-07-25 1750
-
pcie设备驱动程序安装步骤2024-11-13 5630
-
PCIe接口的工作原理 PCIe与PCI的区别2024-11-06 6649
-
docker容器与容器之间通信2023-11-23 2788
-
基于FPGA的PCIE通信测试2023-09-04 7833
-
聊聊PCIe设备在系统如何发现与访问?2022-12-09 6551
-
PCIe设备的低功耗状态2021-12-28 1460
-
如何实现两个处理器之间的通信2020-04-16 3769
-
PLC与PLC之间的通信方式设置2019-11-24 24004
-
单片机和投影仪之间可以通过网络通信方式通信吗?2019-03-05 3665
-
PCIe总线的两种复位方式2018-12-30 24941
-
关于PCIe通信问题2018-08-07 3553
-
简谈PCIe的软件配置方式2018-07-27 4356
-
PCIe物理层实现了一对收发差分对,可以实现全双工的通信方式2018-05-31 14799
全部0条评论

快来发表一下你的评论吧 !
