

简单说一下阻塞IO、非阻塞IO、IO复用的区别?
描述
前言
在《Unix网络编程》一书中提到了五种IO模型,分别是:阻塞IO、非阻塞IO、IO复用、信号驱动IO以及异步IO。本篇文章主要介绍IO的基本概念以及阻塞IO、非阻塞IO、IO复用三种模型,供大家参考学习。
一、什么是IO
计算机视角理解IO:
对于计算机而言,任何涉及到计算机核心(CPU和内存)与其他设备间的数据转移的过程就是IO。IO对于计算机而言有两层意思:
IO 设备:比如我们最常见的打印机、鼠标、键盘。
对IO设备的数据读写。
程序视角理解IO:
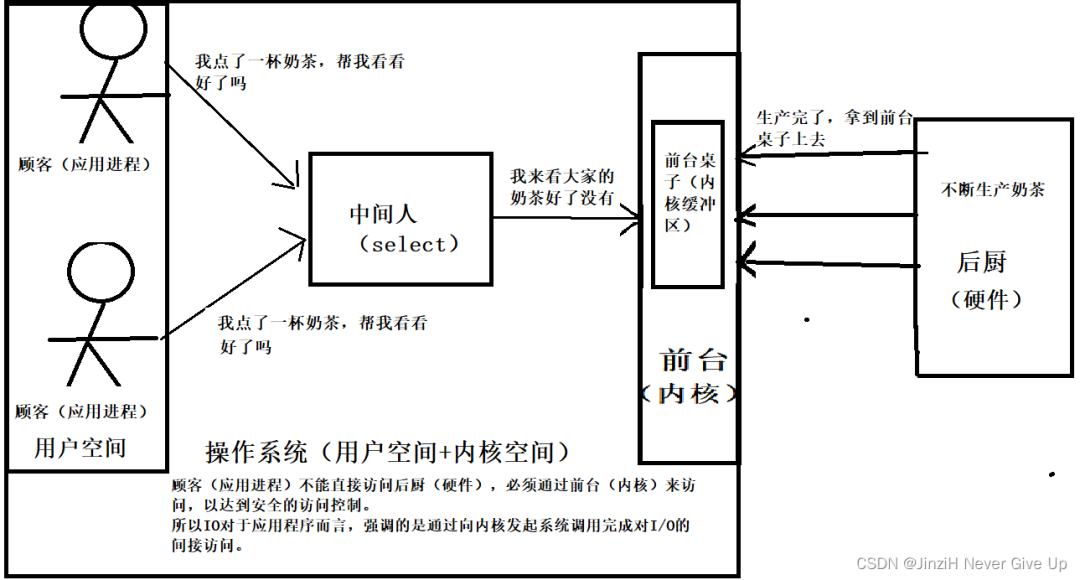
现代操作系统将空间划分为用户空间和内核空间。
用户空间:非内核应用程序则运行在用户空间。用户空间中的代码运行在较低的特权级别上,不能直接访问内核空间和硬件设备。
内核空间:操作系统的核心,是操作系统工作的基础,它负责管理系统的进程、内存、设备驱动程序、文件和网络系统,决定着系统的性能和稳定性。
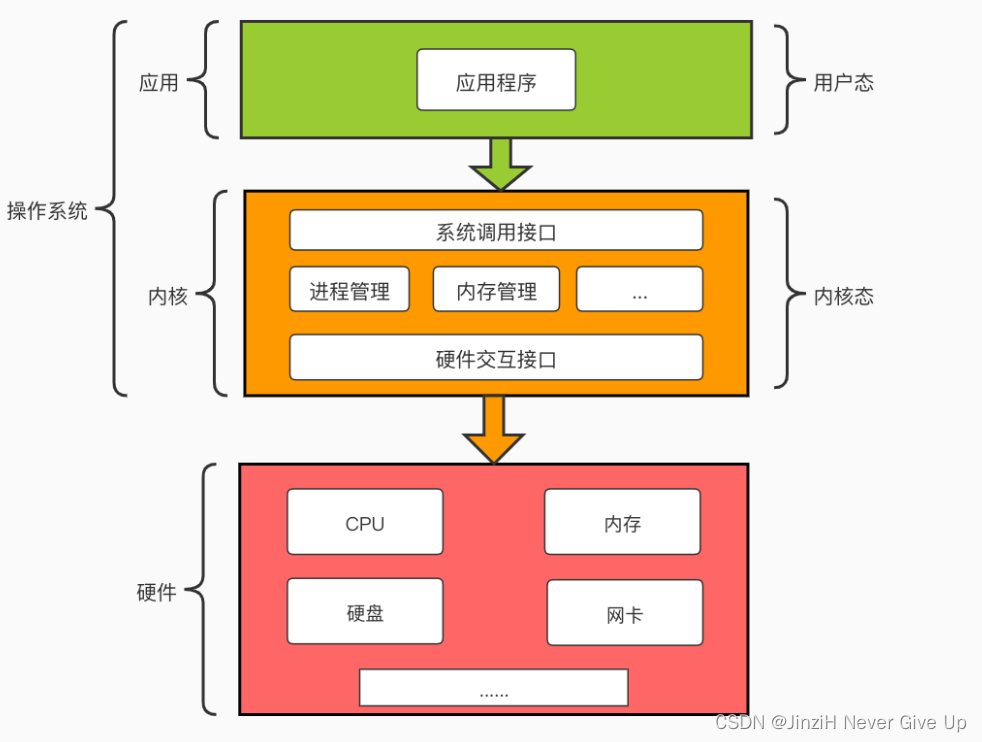
操作系统为了能够正常平稳地运行下去,它是不会允许应用程序随意访问计算机硬件部分,如内存、硬盘、网卡,应用程序必须通过操作系统提供的API来访问,以达到安全的访问控制。
总结:IO对于应用程序而言,强调的是通过向内核发起系统调用完成对I/O的间接访问。
应用程序发起一次IO访问分为两个阶段:
IO调用阶段:应用程序向内核发起系统调用。
IO执行阶段:内核执行IO操作并返回。
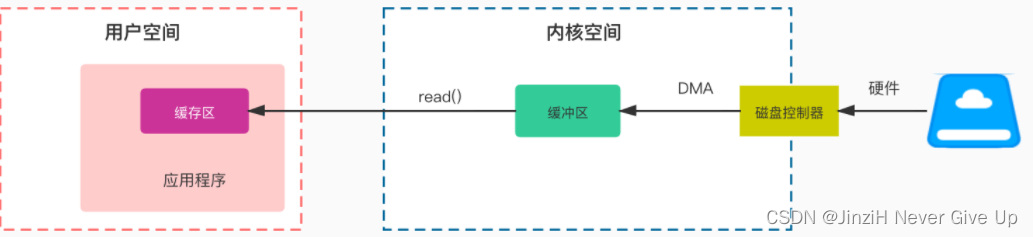
数据准备阶段:内核等待IO设备准备好数据
数据拷贝阶段:将数据从内核缓冲区拷贝到用户空间缓冲区
二、阻塞IO模型
阻塞I/O模型是最常见的IO模型,其流程图如下所示。
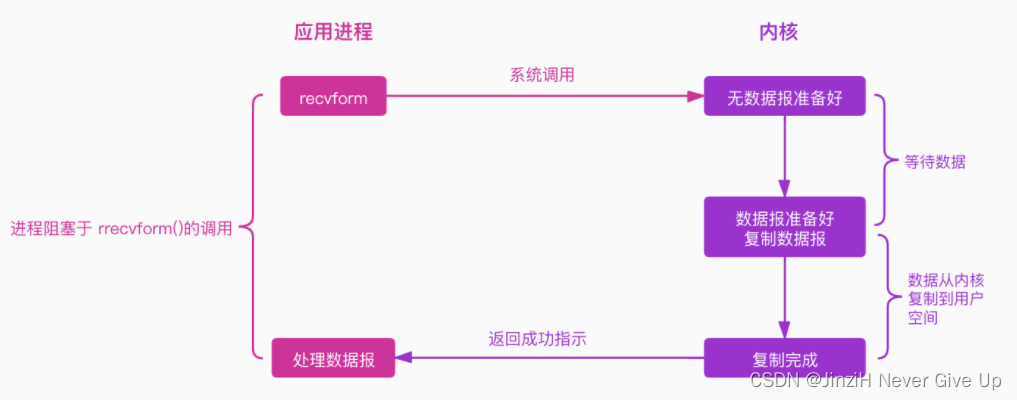
应用程序发起一个系统调用(recvform),这个时候应用程序会一直阻塞下去,直到内核把数据准备好,并将其从内核复制到用户空间,复制完成后返回成功提示,这个时候应用程序才会继续处理数据。
优点:模型简单,实现难度低,适用于并发量较小的应用开发。
缺点:IO调用阶段和IO执行阶段都会阻塞。
典型的阻塞I/0模型的例子为data=socket.read(),如果内核数据没有准备就绪,Socket线程就会一直阻塞在read()中等待内核数据就绪。
生活场景:某天,你跟你女朋友去奶茶店买奶茶,点完奶茶后后,由于你们不知道奶茶什么时候才能做好,所以你们就只能一直等着,其他什么事情也不能干。
三、非阻塞 IO模型
在非阻塞IO模型中,应用进程需要不断询问内核数据是否就绪,在内核数据还未就绪时,应用进程还可以做其他事情。
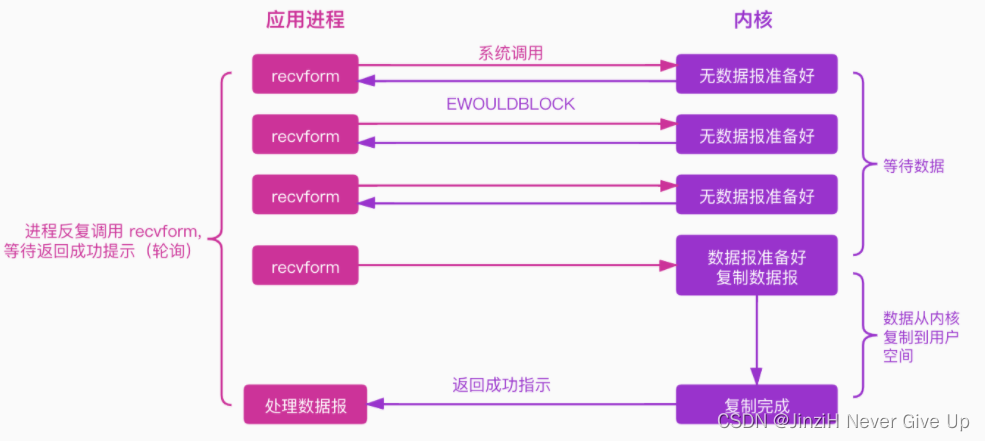
从上图可以看出, 非阻塞IO模型需要应用进程不断地主动询问内核数据是否已准备好了。
优点:模型简单,实现难度低;与阻塞IO模型对比,它在等待数据报的过程中,进程并没有阻塞,它可以做其他的事情。
缺点:轮询发送 recvform,消耗CPU 资源。
生活场景:你和你女朋友去奶茶店买奶茶,吸取了上一次的教训,点完奶茶后顺便去逛了逛商场。由于你们担心会错过取餐,所以你们就每隔一段时间就来问下服务员,你们的奶茶做好了没有,来来回回好多回,若干次后,终于问到奶茶已经准备好了,然后你们就开心的喝了起来。
四、IO复用模型
非阻塞IO模型需要进程不断地轮询发起recvform系统调用,就会有很多的线程不断调用recvfrom 请求数据,先不说服务器能不能扛得住这么多线程,就算扛得住那么很明显这种方式是不是太浪费资源了,线程是我们操作系统的宝贵资源,大量的线程用来去读取数据了,那么就意味着能做其它事情的线程就会少。
例如:你是奶茶店的服务员,每个人点好奶茶后,每隔几分钟就来问你一次好了没有,随着问的人越来越多,你可能会开始怀疑人生。那么有没有什么好的解决办法呢?
答案:不需要所有进程轮询来发起recvform来查询数据是否已经准备好了,而是有人帮忙来询问,这个帮忙的人就是select。
IO复用模型如下所示:
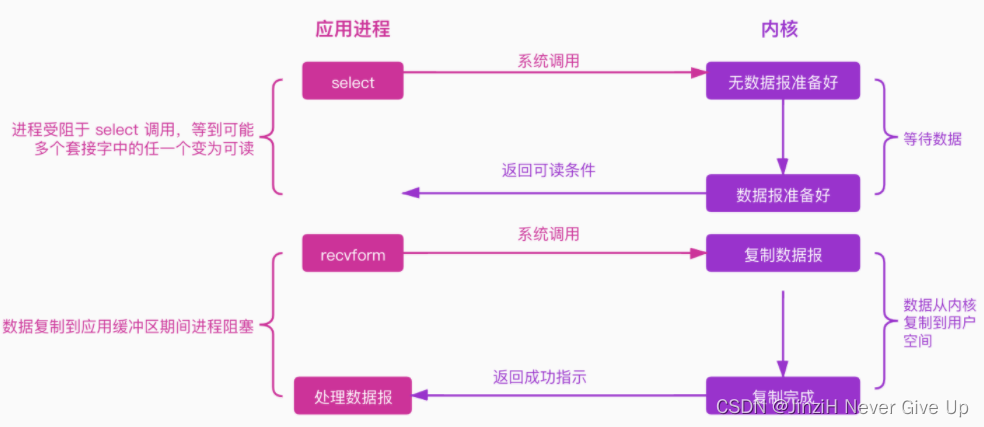
多个进程的IO注册到一个复用器(select)上,select 会监听所有注册进来的IO。如果内核的数据报没有准备好,调用select 的进程将会被阻塞,而当任一IO在内核缓冲区中有数据,select调用就会返回可读条件,然后进程再进行recvform系统调用,内核将数据拷贝到用户空间,注意这个过程是阻塞的。
注意:IO 复用模型在第一个阶段和第二个阶段其实都有阻塞,第一个阶段阻塞于 select 调用,第二个阶段阻塞于数据复制。
优点:适用于高并发应用程序。
缺点:模型复杂,实现、开发难度较大。
生活场景:如果每个人都过一会就来问一下奶茶好了没有,奶茶店的压力也太大了。于是奶茶店想到了一个办法,找一个中间人(select)挡在奶茶店前面,顾客(应用进程)询问那个中间人奶茶好了没有(对应多个进程的IO注册到一个复用器(select)上),如果没有好就让顾客等待(应用进程阻塞于 select 调用)。中间人持续查看顾客的奶茶是否准备好,如果有一个人的奶茶准备好了就会去通知那个人可以取了(而当任一IO在内核缓冲区中有数据,select调用就会返回可读条件,然后进程再进行recvform系统调用)。
总结
学习IO模型时,必须要把每个模型联系起来看,比如阻塞IO模型会阻塞较长时间,而非阻塞IO在等待数据报的过程中,进程并没有阻塞,它可以做其他的事情。IO复用模型可以很好的降低服务器的压力,且在连接数众多且消息体不大的情况下有很大的优势。
审核编辑:刘清
-
一文解读Linux 5种IO模型2024-11-09 1834
-
socket阻塞和非阻塞的区别是什么2024-08-16 2155
-
信号驱动IO与异步IO的区别2023-11-08 2298
-
网络IO模型:阻塞与非阻塞2023-10-08 1868
-
IO与NIO有何区别2023-09-25 1862
-
一文了解阻塞赋值与非阻塞赋值2023-07-07 3370
-
简要叙述分布式IO和远程IO的区别2022-12-29 13523
-
一文详细了解五种IO模型2022-02-14 6776
-
网络IO的弊端以及多路复用IO的优势2021-08-25 3874
-
深入分析同步阻塞网络IO的内部实现详解2021-04-03 2981
-
网络IO套路分享2020-10-13 2735
-
linux下的IO模型详解2019-10-09 17489
-
《Linux设备驱动开发详解》第8章、Linux设备驱动中的阻塞与非阻塞IO2017-10-27 1134
-
veriolg中阻塞赋值与非阻塞赋值区别2017-09-16 920
全部0条评论

快来发表一下你的评论吧 !
