

构建实车数据消费链
描述
采集车除了用户自己的系统外还有大量的采集及支持设备。对于一个复杂的系统来说,保持稳定运行是一项异常复杂的任务。由于采集车数量众多,部署大量的技术人员进行维护成本非常高,通常都是一人多车的结构,因此为车上系统提供自动化及网络化的集成方案是一个必选项。在设备扩展方面,Vector提供时间同步服务和数据记录扩展接口,可以将用户的In-house方案以及第三方设备集成到CANape的环境中,形成一个“简洁”的应用。
实车数据应用背景
01
目标
采集实车数据的最终目的是服务于研发或者测试,数据消费的核心是利用算法支持和推动算法的快速迭代,而数据消费系统可以为算法运行和调试提供便捷的环境,但是大多数情况下我们会在消费系统的构建上花费大量的时间。例如:构建文件接口、对齐数据的时间、测定数据质量、数据匿名化等。缺乏“标准”的数据消费系统,会导致工程师不停地开发和维护多个数据消费系统,这种情况在多个项目并行开发时尤为明显,不仅消耗大量的时间,且产出(迭代效率)很低。因此要想达到数据闭环的效果就需要大量的标准化工作,而减少非核心环节上的消耗,将核心资源放在迭代和改进算法上,平衡与整合自研与商业工具链,这往往需要从时间、资金、人力等多个维度综合考量。
Vector工具链在具备标准性的同时,保持对用户的各种场景提供开放性支持,例如数据采集系统框架、数据可视化、自动化、文件IO等,用户可以基于自己的流程和认知进行灵活扩展和整合,快速构建起稳定、高效的实车数据消费链。
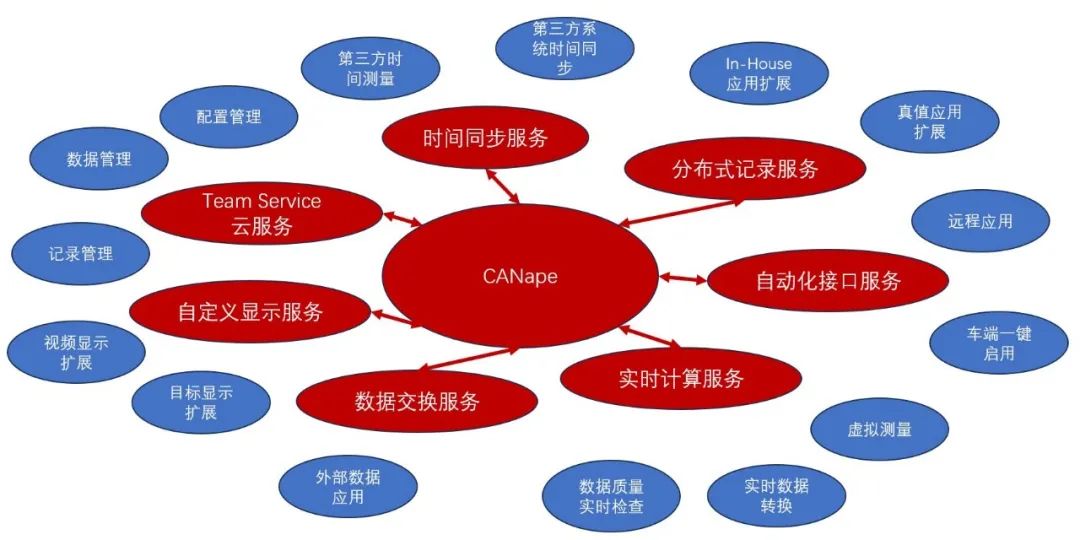
图1:CANape实车扩展应用
02
一般用户诉求
用户在构建数据消费链时的诉求,可能包括:私有化数据的落盘方案、多系统多时域的整合、采集车网络化自动化、数据物流与实时数据传输、数据质量控制、数据管理、配置工程管理、数据消费业务构建及部署、数据生命周期及复用技术等。
本质上可以将数据生命周期简单划分为:
>
车端数据收集
>
数据流转(物流及实时传输)
>
数据中心构建及数据消费业务整合
>
复用价值开发
其中每个过程中涉及的流程、技术及工具跨越比较大,从技术角度将不同领域人员的开发能力连接起来是比较困难的,创建必要的桥接流程及工具是构建数据链的核心任务,毕竟链路构成的稳定性和效率在连接,而不在节点本身。
03
数据格式选择
测量信号值是许多应用的一项基本任务。大多数试验需要对获取的信号同时进行处理、显示和存储,测量过程同时也需要与工程师进行前端交互,以达到敏捷闭环,针对后端的数据消费及闭环做好充足的准备。汽车应用中,典型信号包括传感器数据、ECU内部变量/状态、车辆网络中的总线报文或内部计算值等。
一般在选择记录数据格式时,需要考虑以下几个方面:
>
数据的属性关联;
>
数据的读写要求;
>
数据的体积
这些特征间接决定了数据记录及消费的总体成本(时间成本和资金成本)。
MDF本质是一个数据容器,支持数据的版本族信息写入,支持信号的定义甚至信号定义的文件写入,甚至支持坐标系信息、安装数据等一些额外信息写入。如果没有上述特征的支持,那么需要保存为多份文件,而文件关系本质上是离散的且难以管理的,这些会给后面的数据管理和消费带来额外的开发负担。
在当前的业务场景中经常看到,高速大带宽的数据写入需求,同时又看到数据消费环节要求的快速数据索引和数据提取,本质上这些要求都是相互矛盾的。通常的文件格式的性能特点要么是支持高速并发(乱序)写入,要么是支持高性能索引(有序)读取,而MDF为了满足这两方面要求,采用了数据块链表结构,在写入时支持乱序写入,在读取时支持快速重排序来保证高性能的索引及读取,如图2所示。
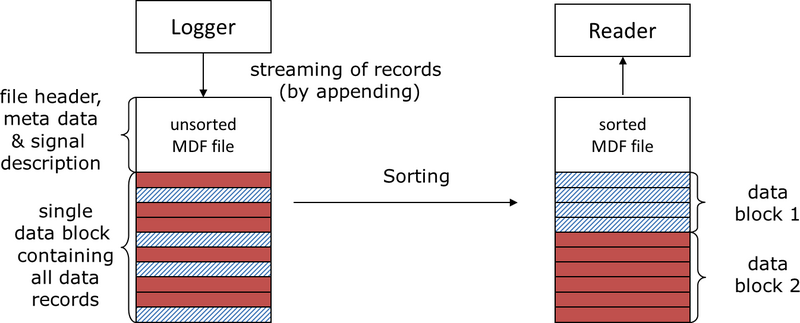
图2:摘自ASAM–MDF特征描述文献
MDF(Measurement Data Format)是一种二进制文件格式,用于存储记录测量或计算的数据,便于测量后处理、离线评估或长期存储。作为ASAM收录的数据文件格式标准,被广泛应用于测量和标定领域。MDF同时也支持无损数据压缩,第三方的数据序列化结果也可以直接存储在MDF的数据块中,例如:Protobuf、CDR、BSON等,甚至声音、视频这类数据也可以有损或者无损的存放在MDF中。这些特性可以很好的平衡存储与计算的资金成本。
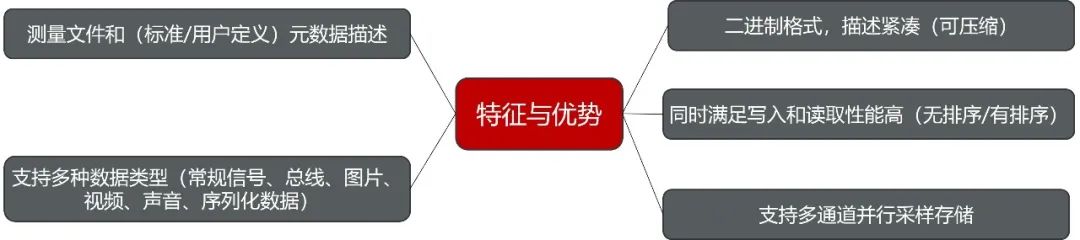
图3:MDF数据的特征与优势
除此之外,在汽车领域常用的还有很多数据格式,例如:总线数据格式BLF、以太网数据格式PCAP,以及各种数据库格式(DBC、A2L、ARXML等),仍具有各自的应用场景。
构建消费链
01
采集车网络化及自动化
通常站在驾驶员的视角,希望启动系统只需要一个按钮,然后等待系统回复是否可以开始驾驶。站在车上系统开发和维护人员的角度,希望系统所有的功能都可以按照设置条件自动执行,反馈并记录所有的细节,用于异常时的技术排查。站在更高的层面上,还有车队管理系统、数据看板系统等,因此希望车辆将必要的信息反馈回来获取车辆状态及任务进度,为决策提供更多的统计支撑。
CANape作为车载的核心软件之一为这类需求提供了必要的桥接能力。CANapeAPI是一个自动化接口,可以使用该接口实现一键自检和启动,同时也可以使用该接口将必要的状态信息实时传递到用户前端及监测系统端。图4是一个网络调用的实例,展示了如何驱动CANape载入工程运行脚本,控制测量的能力。实际上CANapeAPI提供非常丰富的功能。

图4:CANape网络调用实例
02
物流及实时传输
应用场景一:在日均TB级的数据生产环境中,网络传输的时效性和成本无法被行业用户接受,因此数据物流成为用户的必然选择。Vector的工控机提供磁盘阵列及Copy系统,减少用户对数据记录、存储和转移的焦虑。
应用场景二:在数据驱动的模式下,如何快速定位“价值”数据,让实时数据传输也成为必然的选项。由于传输能力的限制,存在两种不同的价值挖掘方法:
>
先筛后传:将筛选后的有限数据实时传输到数
据中心,数据中心的应用实时完成信息的定位
和提取;
>
先传后筛:车载工控机将“大数据”全部运输至
“云端/数据中心”,云端部署数据挖掘相关应用;
CANape和vSignalyzer分别提供在线和离线的数据挖掘功能,传输接口(SL-API)和云服务(Team Service)等提供多种组件和接口,可以帮助用户搭建其上述两种应用场景。
03
数据中心构建及数据消费业务整合
Vector提供SaaS服务,有多种应用可以选择,能够在公有云和混合云上为用户提供快速落地的解决方案,从软件角度快速连接车端和台架端,帮助数据中心快速建立。
对于数据消费业务,最大的壁垒在于打通本地的数据消费应用如何部署在服务器端,主要原因是人员知识背景和工程经验之间的差异。因此,提供一个“标准”样式,既适合本地端又适合服务端的框架,会让这个工作变得更容易推动。它不应挑战用户的技术背景和知识体系,且应该足够简单,不需要让用户学习太多与专业无关的知识与技能,这是一项技术能够快速被目标用户接受的前提。
Vector提供多种行业主流的记录格式读写库,例如:MDFlib、BLF等。但是直接使用这些库,需要用户了解格式的技术内容才能有效使用。Vector项目团队以众多项目经验为基石,对工具链进行封装,实现了接口代码的自动化,方便用户直接获取所需信息。同时根据数据消费业务的形式,按照DataFlow的风格抽象了数据处理的接口(如图5所示),方便用户开发风格统一的消费组件,便于业务层复用、本地开发和服务端部署。
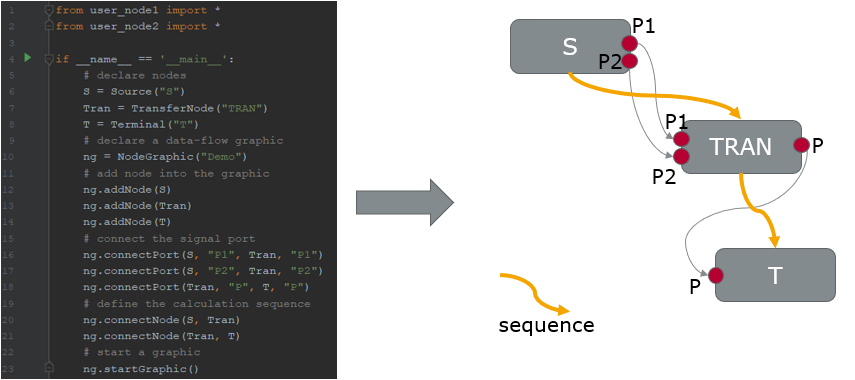
图5:DataFlow模块化设计
如图6所示,这是一个模块化图像处理的实际案例,用户在后端提供了所有模块的Python代码,实现了“MDF读取数据→检查图像质量→输出JPG图片”的业务功能,还可以在前端重新组装业务。
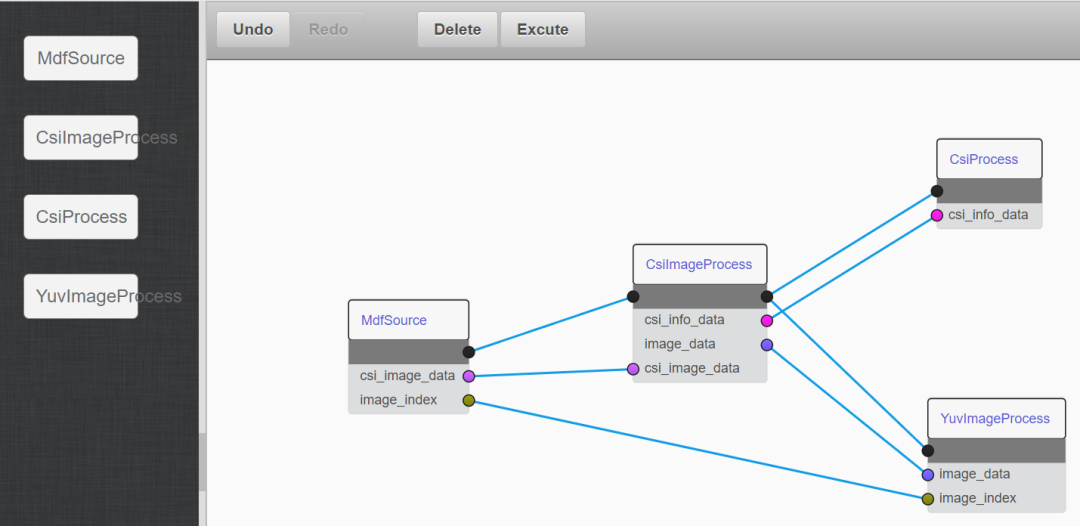
图6:模块化设计应用实例
04
Vector提供的支持
如图7所示,针对整个数据消费链,Vector提供多种标准化工具帮助用户快速搭建数据采集、管理、应用等模块,使用户能够集中精力聚焦核心业务。
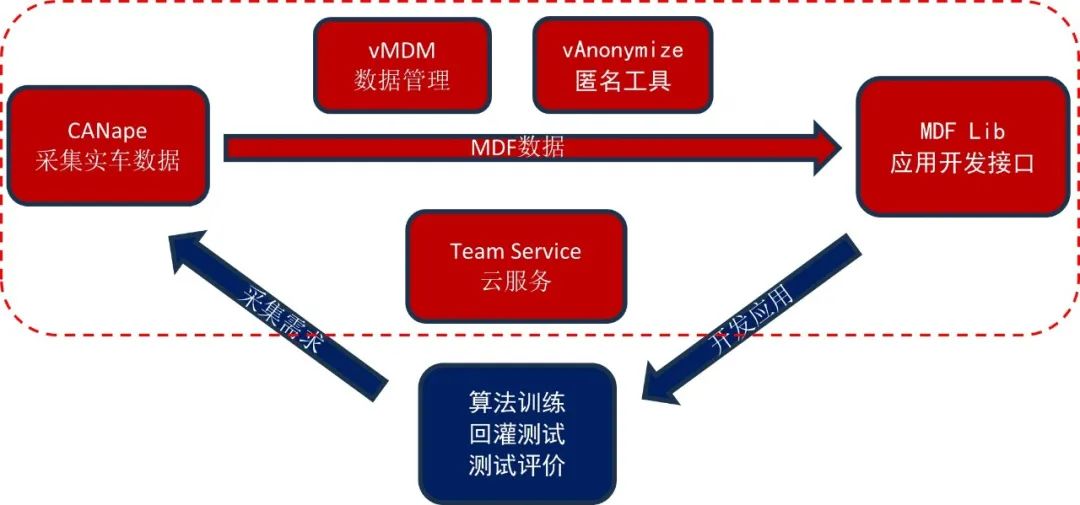
图7:数据消费链示意图
本篇文章技术内容所依赖的Vector标准工具,包括:
>
CANape - 用于测量与标定的标准上位
机软件
>
vMDM - 用于数据管理的服务器/客户
端软件
>
vAnonymize - 用于数据脱敏的匿名化
工具软件
>
Team Service - 用于云端管理数据/工
程的云服务
>
MDF4 Lib - 用于读写MDF数据操作
数据流的商用库接口,包括单机/服务器
和Windows/Linux版本
如有相关技术需求和兴趣,
欢迎联系我们,我们将竭诚为您答疑。
-
声控玩具车的构建2023-06-28 943
-
如何构建一辆无人驾驶车呢?2021-09-30 3852
-
区块链是如何构建车联网的安全性的2020-01-13 2620
-
区块链技术应用在金融数据面前的搭建方案2019-12-23 2692
-
构建JESD204B链路的步骤2018-09-13 4888
-
在ADIsimRF中构建信号链 使用-ADIsimRF-构建-一条信号链演示2018-06-01 4311
-
区块链应用与思考 矩阵元构建自己的第一款区块链应用2018-03-03 2111
-
UBI车险数据生态链该如何构建?2016-02-25 2921
全部0条评论

快来发表一下你的评论吧 !
