

大语言模型(LLMs)如何处理多语言输入问题
人工智能
描述
师姐1个月攻下LLM的所有知识的捷径
How do Large Language Models Handle Multilingualism?

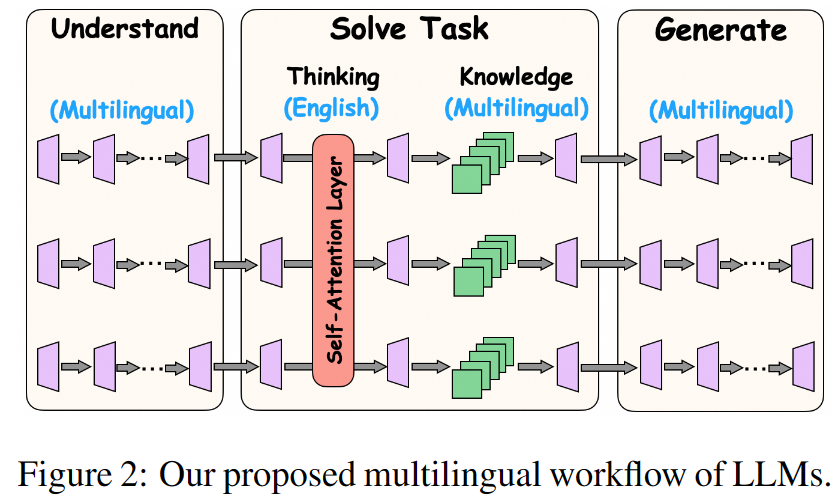
摘要:大语言模型(LLM)在各种语言中都表现出了卓越的性能。在这项工作中,我们将深入探讨以下问题:大语言模型如何处理多语言问题?我们引入了一个框架,描述 LLMs 处理多语言输入的过程:在前几层,LLMs 理解问题,将多语言输入转换为英语,以帮助任务解决阶段。在中间层,语言学习者分别利用自我注意结构和前馈结构,通过用英语思考和结合多语言知识来获取事实内容,从而参与问题解决。在最后几层,LLMs 生成与query的语言一致的回复。 此外,我们还研究了在处理某种语言时是否存在特定语言神经元。为了检测由输入语言激活的神经元(即使没有标签),我们创新性地设计了并行语言特异性神经元检测 PLND 方法,该方法能有效量化不同神经元在处理多语言输入时的重要性。通过deactivate不同层和结构的神经元进行综合消融分析,我们验证了我们提出的框架。此外,我们还证明了利用这种框架可以在无需大量训练的情况下有效提高模型多语言能力。
https://arxiv.org/abs/2402.18815
Q1: 这篇论文试图解决什么问题?
A:这篇论文探讨了大语言模型(LLMs)如何处理多语言输入的问题。具体来说,研究者们提出了一个框架来描述LLMs在处理多语言输入时的内部处理过程,并探讨了模型中是否存在特定于语言的神经元。为了验证这一框架,研究者们设计了一种名为并行语言特定神经元检测(PLND)的方法,用于检测在处理特定语言输入时被激活的神经元。此外,论文还研究了通过微调这些语言特定神经元来增强LLMs的多语言能力的可能性。

Q2: 有哪些相关研究?
A:论文中提到了以下几类相关研究:
多语言能力研究: 一些研究专注于探索语言模型的多语言能力,包括跨语言性能和语言之间的结构共性。
模型架构与能力关系研究:为了理解特定能力与模型架构(尤其是主导的Transformer架构)之间的关系,一些研究探索了LLMs的自注意力层的推理能力。
前馈层研究:其他研究关注前馈层,将其视为存储事实知识的键值记忆。
可解释性研究:传统的可解释性研究调查输入特征与其相应输出的重要性。在LLMs时代,一些研究致力于理解知识存储,例如研究前馈层作为知识库。
多语言处理研究:包括构建基准测试、通过翻译提升性能、对齐表示、提示等方法的研究,这些工作强调了使LLMs在多种语言中有效运行的重要性和复杂性。
Q3: 论文如何解决这个问题?
A:论文通过以下步骤来解决大型语言模型(LLMs)如何处理多语言输入的问题:
提出处理框架:研究者们提出了一个框架来描述LLMs在处理多语言输入时的内部处理过程。这个框架包括以下几个阶段:
在前几层,LLMs将多语言输入转换为英语,以便于任务解决阶段。
在中间层,LLMs通过英语思考并结合多语言知识来解决问题,分别利用自注意力和前馈结构。
在最后几层,LLMs生成与查询原始语言相一致的响应。
设计PLND方法:为了检测在处理特定语言时被激活的神经元,研究者们创新性地设计了并行语言特定神经元检测(PLND)方法。这种方法可以在没有标签的情况下有效地衡量神经元在处理多语言输入时的重要性。
进行消融分析:通过选择性地关闭不同层和结构中的神经元组,研究者们进行了全面的消融分析来验证他们提出的框架。这包括在理解、任务解决和生成阶段分别关闭语言特定神经元,并观察对模型性能的影响。
增强多语言能力:研究者们展示了如何通过微调语言特定神经元来有效提升LLMs的多语言能力,即使用较少的训练数据。这通过在特定语言的文本语料库上进行微调来实现,从而提高了模型在多语言任务上的表现。
实验验证:研究者们通过实验验证了他们的假设,包括在不同的多语言任务(如推理、自然语言理解、知识问答和自然语言生成)上进行实验,并观察关闭语言特定神经元对模型性能的影响。
Q4: 论文做了哪些实验?
A:论文中进行了一系列的实验来验证提出的框架和PLND方法,具体包括:
PLND方法验证:通过PLND方法,研究者们检测了在处理特定语言输入时被激活的神经元。他们通过向模型输入特定语言的文本语料库,并观察哪些神经元在响应中持续激活,从而识别出语言特定的神经元。
消融分析:研究者们通过选择性地关闭不同层和结构中的神经元组,观察这些操作对LLMs在多语言任务上的性能影响。这包括:
在理解层关闭语言特定神经元。
在任务解决层关闭语言特定神经元。
在生成层关闭语言特定神经元。
多语言任务性能测试:研究者们在多种多语言任务上测试了LLMs的性能,包括:
推理任务(MGSM)。
自然语言理解(NLU)任务(XQuAD)。
自然语言生成(NLG)任务(XLSum)。
知识问答任务(X-CSQA)。
多语言能力增强:研究者们通过微调语言特定神经元来增强LLMs的多语言能力。他们使用特定语言的文本语料库进行微调,并评估了微调前后模型在多语言任务上的性能提升。
不同多语言LLMs的分析:研究者们还分析了其他类型的多语言LLMs,如BLOOMZ(一个支持46种语言的超多语言LLM)和Chinese Llama(一个专注于英语和中文的双语LLM),以验证提出的框架的普适性。
Q5: 有什么可以进一步探索的点?
A:尽管论文提出了一个关于LLMs处理多语言输入的框架,并进行了一系列的实验验证,但仍有一些领域可以进一步探索:
更深入的神经网络解释:研究LLMs内部的更深层次机制,例如如何精确地在不同语言之间转换和编码信息,以及不同层之间是如何协同工作的。
跨语言知识迁移:探索LLMs如何在不同语言之间迁移和共享知识,以及这种迁移对模型性能的影响。
多语言数据集的构建:开发更大规模和更多样化的多语言数据集,以便更好地训练和评估LLMs的多语言能力。
多任务学习:研究LLMs在执行多种语言任务时的表现,以及如何优化模型以提高跨任务的泛化能力。
语言特定神经元的功能:深入研究语言特定神经元在模型中的具体作用,以及它们如何影响模型对特定语言的理解和生成能力。
模型压缩和优化:研究如何通过减少模型大小和计算需求来保持或提高多语言性能,这对于资源受限的环境尤为重要。
跨语言评估指标:开发和标准化跨语言评估指标,以便更公平地比较不同模型在多语言任务上的性能。
多语言模型的可解释性:提高LLMs的可解释性,以便更好地理解模型是如何做出决策的,特别是在处理多语言输入时。
多语言模型的伦理和社会影响:研究LLMs在多语言环境中可能产生的偏见和歧视问题,以及如何设计更公平、更包容的多语言模型。
实际应用场景:将LLMs应用于实际的多语言场景,如跨语言对话系统、翻译服务和多语言教育工具,以评估和改进模型在现实世界中的有效性。
Q6: 总结一下论文的主要内容?
A:这篇论文的主要内容包括:
问题提出:探讨大型语言模型(LLMs)如何处理多语言输入的问题,特别是在理解和生成文本时的语言转换机制。
处理框架:提出了一个处理多语言输入的框架,描述了LLMs在不同层级上如何将非英语输入转换为英语,利用英语进行问题解决,并最终生成与原始查询语言相一致的响应。
PLND方法:创新性地设计了并行语言特定神经元检测(PLND)方法,用于检测在处理特定语言输入时被激活的神经元,即使在没有明确标签的情况下。
消融分析:通过关闭不同层和结构中的神经元组,进行了全面的消融分析,以验证提出的处理框架。实验结果表明,关闭语言特定神经元会显著影响LLMs在非英语任务上的性能。
多语言能力增强:展示了如何通过微调语言特定神经元来提升LLMs的多语言能力,即使在训练数据较少的情况下也能有效提高模型性能。
实验验证:在多个多语言任务上进行了实验,包括推理、自然语言理解、知识问答和自然语言生成任务,以验证模型在处理多语言输入时的表现。
进一步探索:提出了未来研究方向,包括更深入的神经网络解释、跨语言知识迁移、多语言数据集构建、多任务学习、模型压缩和优化等。
结论:论文得出结论,LLMs通过将查询翻译成英语、使用英语进行思考和解决问题,然后再将响应翻译回原始语言来处理多语言输入。同时,通过微调语言特定神经元,可以有效地提升模型的多语言处理能力。
审核编辑:黄飞
-
多语言开发的流程详解2023-11-30 2141
-
这个多语言包 怎么搜不到2024-03-24 5939
-
串口屏能否支持全球多语言功能?2019-03-27 1908
-
HarmonyOS低代码开发-多语言支持及屏幕适配2023-05-23 3239
-
多语言综合信息服务系统研究与设计2009-04-01 507
-
华硕 M3A78-EH主板多语言版说明书2010-02-03 419
-
SoC多语言协同验证平台技术研究2015-12-31 1060
-
基于Toradex多语言image的编译与MUI切换演示2017-09-18 998
-
谷歌深度学习如何处理人类语言?2021-03-01 2014
-
Multilingual多语言预训练语言模型的套路2022-05-05 4311
-
蚂蚁集团开源高性能多语言序列化框架Fury解读2023-08-25 2490
-
基于LLaMA的多语言数学推理大模型2023-11-08 1175
-
如何在TSMaster面板和工具箱中实现多语言切换2023-11-11 2703
-
ChatGPT 的多语言支持特点2024-10-25 2599
-
京东多语言质量解决方案2026-01-13 1290
全部0条评论

快来发表一下你的评论吧 !
