

英伟达要小心了!爆火的Groq芯片能翻盘吗?AI推理速度「吊打」英伟达?
电子说
描述
随着科技的飞速发展,人工智能公司Groq挑战了英伟达的王者地位,其AI芯片不仅展现出卓越的实力,还拥有巨大的潜力。Groq设计了一种独特的推理代币经济学模式,该模式背后牵动着众多因素,却也引发了深度思考:新的技术突破来自何处?中国该如何应对并抓住变革中的机遇?Groq成本如何评估?这些都是值得研究和思考的问题。
Groq芯片的实力与潜力
近期AI芯片领域崭Groq可谓是火爆全球,其在处理大型模型token生成上所展示出的表现令人惊叹。这意味着我们可以在与GPT等复杂聊天机器人互动时,实时获得回应,无需等待机器人逐个生成答案。
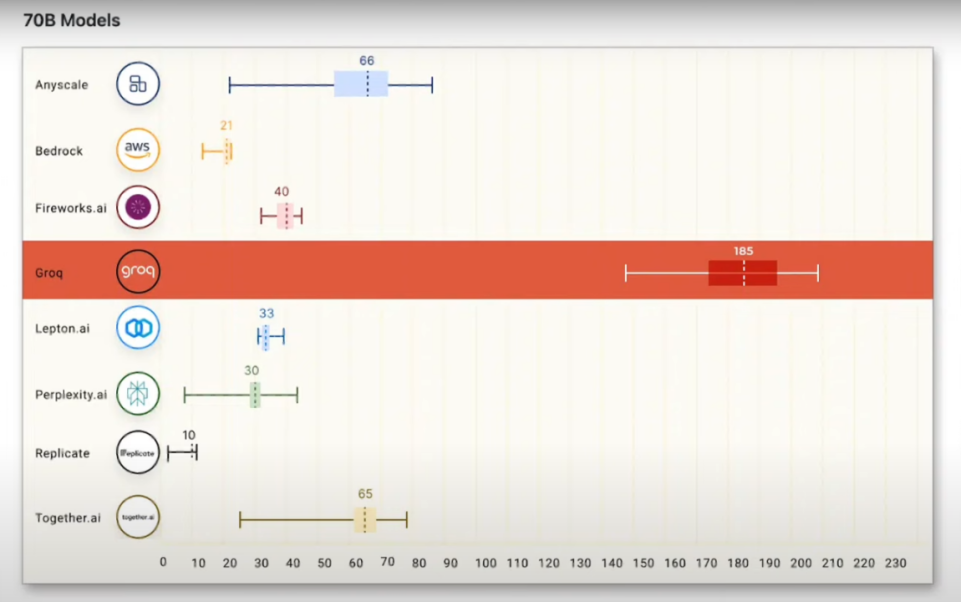
那么,Groq驱动的大模型生成速度究竟有多快呢?令人难以置信的是,当Groq的LPU驱动含有700亿参数的Llama 2大模型时,其生成速度被推至新高度,平均每秒生成185个token。该速度远超其他使用GPU驱动的AI云服务提供商。
而在面对Mix Strore8x7B模型时,Groq的性能更是达到新峰值,其生成速度飙至每秒488.6个token,相比依赖英伟达GPU的系统每秒仅能产生15个token的速度,可以说是取得了压倒性的胜利。从这些事实中,不难看出Groq的LPU在大型模型生成速度上占据绝对优势。LPU曾被称为TSP(Tensor Streaming Processor),即一个装配有大量Tensor单元的流式处理器。
那么对于Groq公司,大家一定对它的来历感到好奇吧?
Groq是由前谷歌TPU团队核心成员乔纳斯罗斯2016年创立的公司,其推出产品被称为LPU(Language Processing Unit),专为处理大模型设计的加速芯片。
一、GPU的局限性
尽管GPU在训练机器学习模型方面的强大作用无可替代,其强大的计算能力、快速参数更新速度和丰富的生态系统使之成为业内的主流选择,但它并非模型推理的理想选择。一方面是因为GPU架构复杂,其中只有部分核心专门针对AI场景。其次,GPU承载存储和计算两个部分,导致数据需要频繁读写,从而降低运行速度,提高功耗。
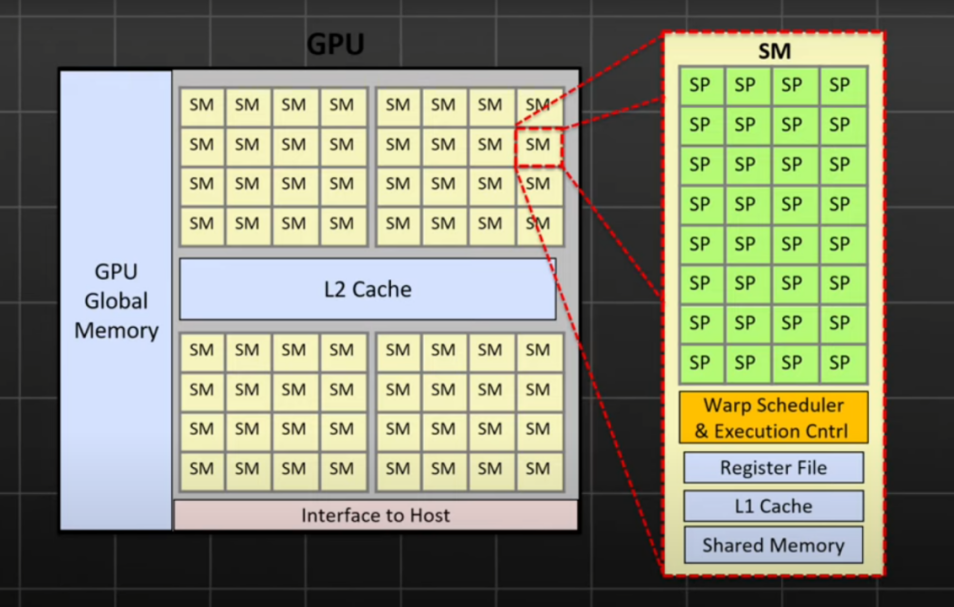
二、GPU、TPU和Groq的LPU的优势与挑战
下面我们一起来分析专门为AI应用设计的芯片,以谷歌的TPU和Groq的LPU为例。TPU和LPU都有自身的独特优势,但也有着各自的挑战需要我们去理解和探讨。
1、谷歌TPU
TPU专为AI应用设计的芯片,专门处理矩阵运算(AI应用中超过90%的计算任务)。在执行AI训练和推理过程中,TPU能够便捷地处理不同的计算任务,如激活函数、优化算法以及损失函数等。这些都是通过高效的向量计算模块来完成的。而其特色之处在于,TPU采用一种独特的阵列设计方法,数据一旦导入,便会在内部形成一个流水线,持续运动直到完成计算。这种持续流动式处理方式极大地降低了数据的读写次数,从而提升了在AI应用中的计算效率。
2、Groq的LPU
Groq的LPU采用与TPU相同的处理模式,不同的是它在计算单元旁边直接集成了大约230MB的SRAM,带宽可达80TB/s。比起GPU,当运行同等参数的模型时,LPU需要的内存更多,这也是LPU在运行速度上拥有优势的原因。
不过,尽管LPU的速度令人瞩目,但其昂贵的价格也是一个不容忽视的问题。LPU每块价格近20000美元,如果要运行拥有上千亿参数的大模型,可能需要购买数百块LPU。也就是说,尽管LPU的单独计算率高,但在数量需求上,部分GPU在成本效益上更具优势。
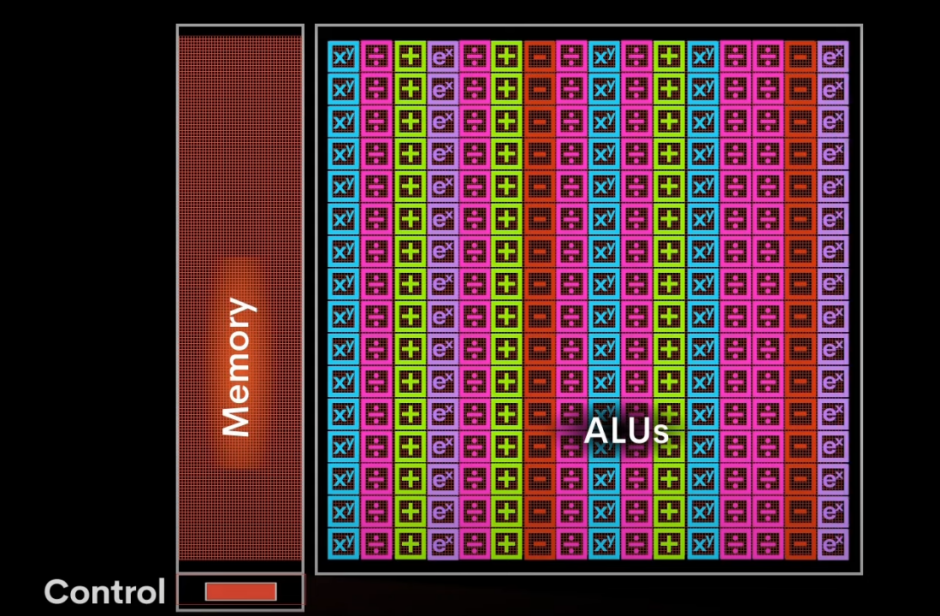
3、SRAM的容量问题
有人可能会提出为什么不直接扩大到1TB?实际上,这样做的技术难度很高,同时也会增加制造成本。因此,230MB的SRAM可能就是在权衡设计难度和制造成本后,现阶段可以实现的一个平衡点。

Groq的成本分析
Groq人工智能硬件公司因其在推理API领域的卓越性能以及为技术如思维链的实际应用所铺就道路的贡献而广受关注。它在单串性能方面的优势更是受到称赞,对于特定的市场和应用环境,Groq的速度优势已经改变了原有的格局。然而,足够的运行速度只是解决方案的一部分。Groq的另一优势是供应链的多元化,即所有制造和封装流程都在美国完成。相比之下,洛基达、谷歌、AMD等依赖韩国内存和台湾先进芯片封装技术的AI芯片供应商形成鲜明对比。
虽然Groq的优势明显,但一个硬件是否具有变革性的决定因素是其性能与总成本的比值。不同于传统软件,AI软件的运行需要更强大的硬件基础设施,这无疑对资本和运营成本产生更大的影响,从而对净利润形成影响。因此,优化AI基础设施以实现AI软件的高效部署尤为重要,拥有优越基础设施的公司无疑将在使用AI部署和拓展应用程序的竞赛中立于不败之地。
根据"Inference Race to the Bottom"的研究,大量公司可能会在Mixtral API推理服务中亏本,以致于需要设定极低的访问率减少损失。然而,Groq却敢于在定价上与这些公司一较高下,其每个代币价格低至0.27美元。接下来,我们将更深入地研究Groq的芯片、系统以及成本分析,看看他们是如何实现这样卓越的性能。
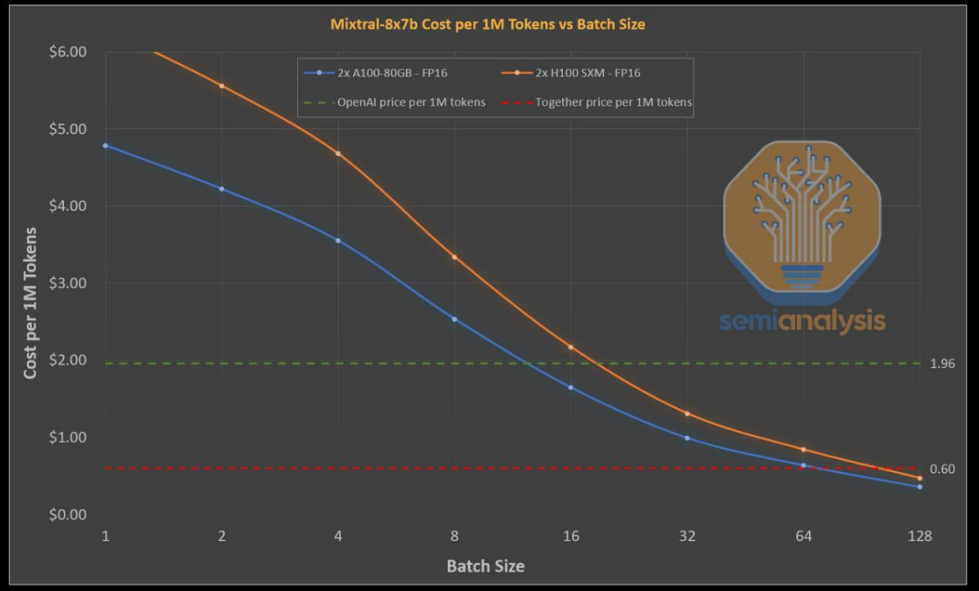
Groq芯片采用固定的VLIW架构,并在Global Foundries的14nm工艺上实现约725mm²的规模。由于芯片并未装配缓存器,所以所有权重、KVCache和激活数据在处理过程中都储存于芯片中,不需外置存储。然而,由于每枚芯片仅拥有230MB的SRAM,所以无法将实际的模型完整地装入单一芯片中。因此,需要使用多个芯片来共同执行模型的运算,并连接在一起。
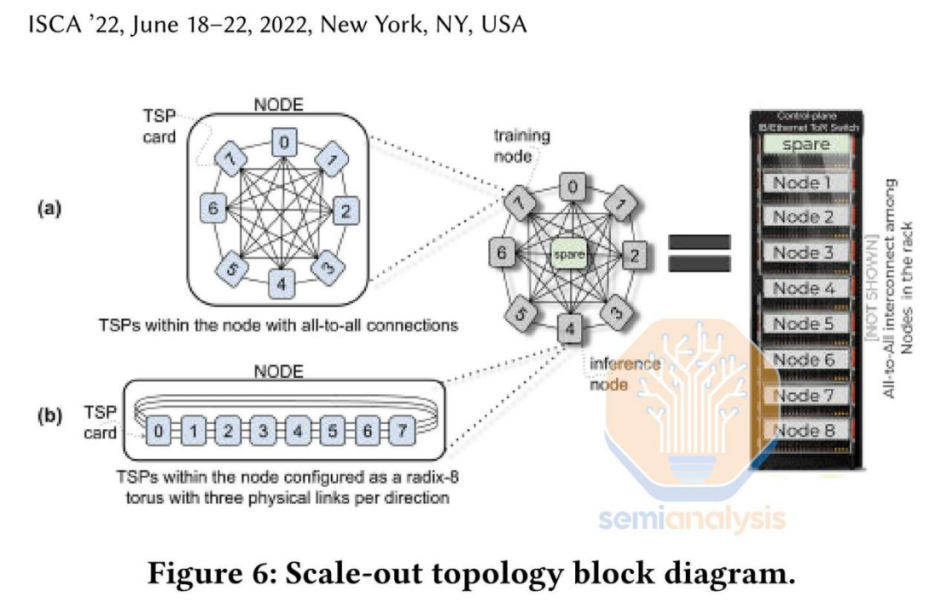
要运行Mixtral模型,Groq需将576个芯片串联起来,这些芯片被均匀地分布在72个服务器上,而这些服务器则被部署在8个不同机架中。相比之下,Nvidia的H100只需一个芯片就能运行同样的模型,而两个芯片则能处理大规模数据。
在芯片成本方面,产出Groq芯片的每片晶圆价格不会超过6000美元。而对照到Nvidia的H100芯片(尺寸为814mm²,采用台湾半导体制造公司的5nm自定义工艺),同样一片晶圆的制作成本就近在16000美元。此外,Groq在设计上并未考虑到良率收缩,与Nvidia有着鲜明的对比,后者会关闭大约15%的H100 SKU,以反映出产品的主流族群。
当考虑到内存成本,Nvidia从SK Hynix采购的每片80GB HBM芯片的预计价格为1150美元。另外,还需要额外付费给台积电的CoWoS服务,导致总成本进一步增加。然而,由于Groq并无额外的外部内存需求,因此其芯片构成要素清单大大缩减。
下表将展示Groq部署策略的特点,特别是在流水线并行性和批处理尺寸均为3时的情况。同时,也会将经过延迟和吞吐量优化后的Nvidia的H100推理部署情况做出对比。
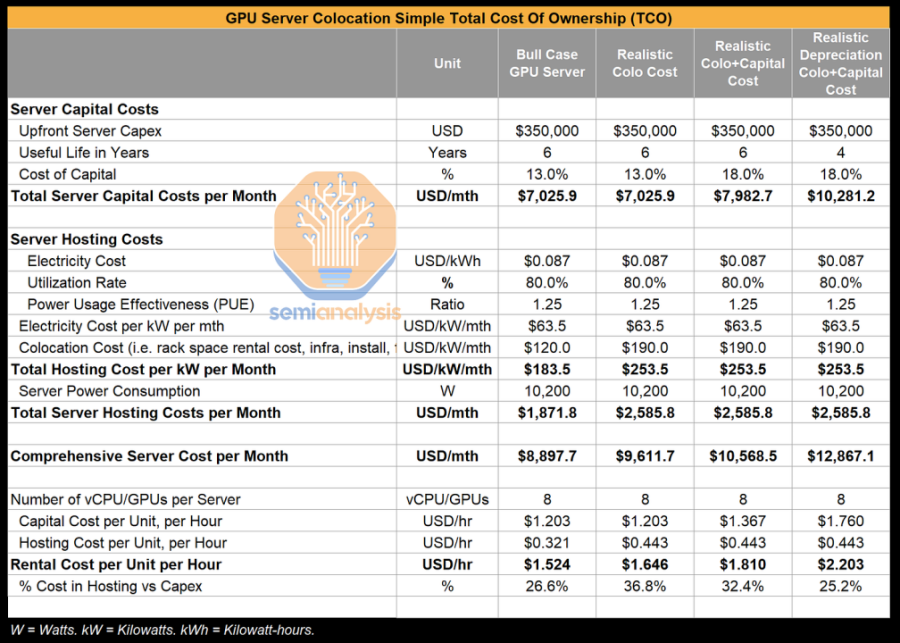
本次分析简化了部分经济因素,未充分考虑进一些系统成本及Nvidia巨大的利润空间。但却明确突出Groq芯片架构的优势,尤其是与延迟优化过的Nvidia系统进行比较时。
对于Mixtral模型,八颗A100s芯片可以提供约220个代币的吞吐量/秒,而这还不包括预测解码。同样地,八颗H100s芯片可以达到约280个代币的吞吐量/秒,如果加上预测解码,吞吐量更可以达到约420。当前,由于经济收益不高,市场上尚未出现面向延迟优化的API服务。然而,随着代理及其他低延迟任务的日益普及,以GPU为基础的API供应商可能会提供相应的优化API。
Groq的优势表现在不需要预测解码的高性能,且这一优势在实现批处理系统后仍然显著。Groq仍在使用相对较旧的14nm工艺,并向Marvell支付较高的芯片利润。然而,随着Groq的投资额增加,以及其下一代4nm芯片产量的提高,情况可能发生改变。
对性能优化过的系统来说,其成本效益将会显著改变。通过基于BOM计算,在每单位美元的投入中,Nvidia的性能增长率显著提升,但其用户吞吐量却相对较低。
简化的分析方式无法考虑到系统成本、利润率和功耗等因素,我们将在未来进一步研究性能与总成本的关系。
一旦将上述因素考虑进去,对Tokenomics的理解将发生改变。Nvidia的商业模式依赖于他们的GPU板的高额利润,以及所收取的服务器费用。
如今,最大的模型参数范围已达到1到2万亿,而预期谷歌和OpenAI将研发超过10万亿参数的模型。同时,大模型如Llama3和Mistral也即将发布。此类模型需要搭配几百个GPU和数十TB的内存的强大推理系统支持。已经有公司如Groq显示出处理不超过1000亿参数模型的能力,并计划在未来两年部署上百万芯片。
谷歌的Gemini 1.5 Pro能够处理高达1000万token的上下文,这意味着它可以处理长达10小时的影片、110小时的音质、30万行的编码或700万字的内容。这样的长上下文处理能力未来有望得到很多公司和服务商的迅速支持以更好地管理大量的编码库和文档库,取而代之低效的RAG模型。在处理这样的长上下文信息时,Groq需要构建由数万片芯片组成的系统,而目前诸如谷歌、英伟达和AMD等公司使用的是几十到几百片芯片。尽管预计四年后,由于其优秀的灵活性,GPU将能处理新模型,但对于Groq这样没有DRAM的公司来说,随着模型规模的扩大,系统寿命可能会缩短,从而增加成本。
利用树状/分支推测的方式,推测性解码的速度已经提高约3倍。如果这种技术能在生产级系统上得到有效部署,那么8块H100的处理速度将会提升到每秒600个Token,从而消解了Groq在速度上的优势。英伟达也未坐视不理,他们计划在下个月发布性能以及TCO超过H100两倍的B100芯片,并计划在下半年开始发货,同时旗下B200和X/R100的研发工作也正在积极推进。然而,倘若Groq能有效地扩大到数千个芯片的系统,那么便能大幅增加流水线数量,为更多的键值缓存提供空间,从而实现大规模的批处理,可能会大幅降低成本。即使有分析师认为这是可能的方向,但实现的可能性并不大。关键问题在于是否值得放弃灵活的GPU,转而建立专门的基础设施以满足小型模型推理市场对于快速响应的需求。
华为芯片应对挑战
Groq的出现为计算力市场提供新的选择,这既暗示强劲的市场需求和供应短缺,也说明科技公司正在构建自己的体系,以对抗英伟达、AMD等的垄断地位。对于国内市场,这无疑为国产芯片提供了更大的发展空间。
华为已经推出昇腾910和昇腾310两款采用达芬奇架构的AI芯片。该架构具有强大的计算能力,可以在一个周期内完成4096次MAC运算,并集成多种运算单元,支持混合精度计算和数据精度运算。
以昇腾系列AI处理器为基础,华为构建Atlas人工智能计算方案,包括多种产品形态,以应对各种场景的AI基础设施需求,覆盖了深度学习的推理和训练全流程。
基于昇腾系列处理器构建的全栈AI解决方案,已逐渐完善。该方案包括昇腾系列芯片、Atlas硬件系列、芯片使能、异构计算架构CANN以及AI计算框架等。其中,昇腾910芯片的单卡算力已能媲美英伟达A100。
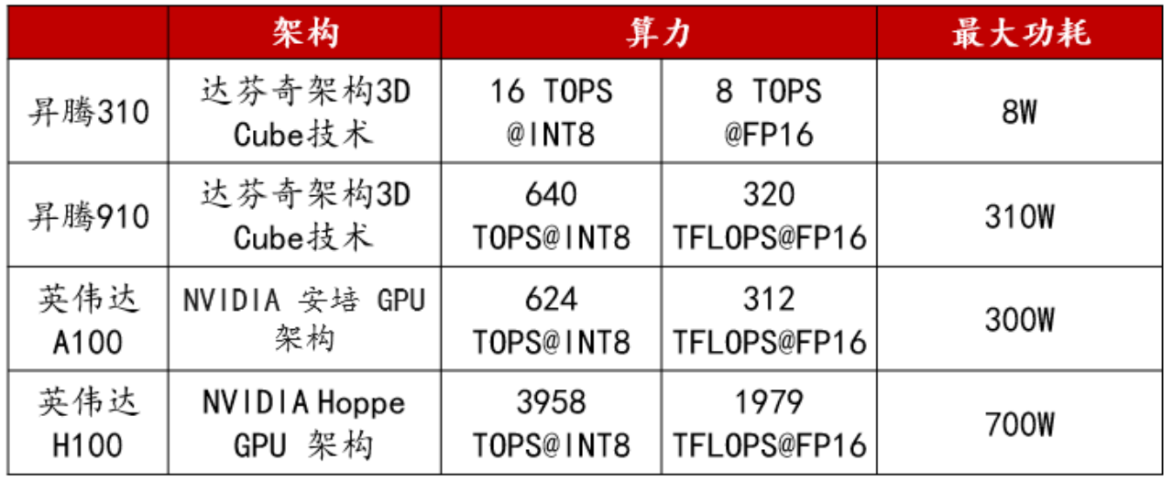
英伟达与华为参数比对
华为的昇腾计算平台CANN已从无到有取得显著突破。从2018年的CANN 1.0版本到目前的7.0版本,这个专为AI场景设计的异构计算架构平台,已成功成为上层深度学习框架和底层AI硬件间的桥梁。
CANN已形成了繁荣的生态体系,适用于50多个主流的大模型,如讯飞星火、GPT-3、Stable Diffusion等,而且兼容主流加速库和开发工具包,加速创新应用的落地。同时,CANN支持主流的深度学习框架,如Pytorch和Tensorflow,且能在周级时间内适配新版本。PyTorch已升级到2.1版本,支持昇腾NPU,助力开发者在华为昇腾平台上开发模型。此外,第三方开源社区,如清华大学的Jittor和飞浆的PaddlePaddle FastDeploy也已经支持接入CANN。
随着华为昇腾910B的算力接近英伟达A100的标准,以科大讯飞为代表的国产AI模型厂商已开始投入使用。科大讯飞宣布,即将以昇腾生态为基础,发布基于“飞星一号”平台的讯飞星火大模型,开启与GPT-4相对标的更大规模训练。科大讯飞星火大模型3.5版已发布,其语言理解和数学能力已超过GPT-4 Turbo,而代码能力及多模态理解分别达到其96%和91%。

华为 CANN 时间线
Groq的成本评估方式
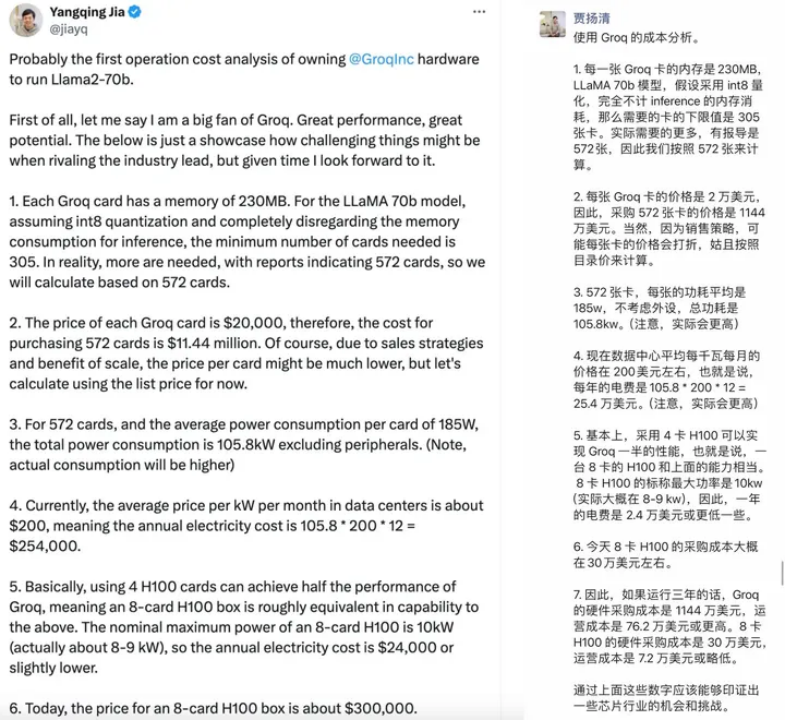
原阿里副总裁贾扬清教授对Groq的成本评估非常精准,他强调Groq相较于H100的性价比较低,这其中包含一部分运营成本。这种观点很有可能不仅仅是针对Groq,而是整个DSA设计领域。然而,如果忽略存储成本,仅按照每个单元(token)的理论成本重新计算,得出的结果可能与此前相差甚远。
在现实LLM需求环境中,推理工作负载对内存容量的需求是刚性的,包括模型权重、上下文KV值、各芯片/节点产生的中间结果、优化器状态(仅训练)等,都需要进行密集读取和移动。此种情况下,Groq在处理大批量任务时的性能可能就变得有限,流水线并行中可能会产生低效或负效益。总并行度受限于能存放KV值的内存容量,而并行度不足会对每token的成本产生影响。
相较之下,采用类似结构的Graphcore 7nm IPU面临的情况也差不多,尽管其配备900MB的片上SRAM,远超Groq的230MB,但依然遭遇商业化的困境。这进一步验证了,如果基于SRAM的解决方案真的可行,类似的产品早就应该弥漫市场了。再者,这种特殊构型对应的软件编程框架和引导编译器也是极大挑战;倘若一定要景气地运行Llama2 70B的推理任务,其复杂的软件和运维开销是不容忽视的。
接着,Groq的单卡计算单元规格似乎更适合处理小规模的推理任务,但其颇高的内存带宽在处理这类任务时的利用率未必能够达到最优。而倘若要处理中大型任务,则需要面临内存容量、通信瓶颈和复杂度的问题。虽然官方的测试主要聚焦在最大70B-最小7B的任务规模,但这显然是Groq比较擅长的工作负载规模,并特别强调INT8的算力(up to 750TOPs),说明Groq产品的主打应该是“INT8量化下的、面向70B-7B规模”的推理场景。
最后,无论从硬件还是软件层面来看,相较于片外HBM+更大的L4+CXL方案,Groq的方案似乎有较高的迭代局限性,可能并不满足当前LLM工作负载的刚性需求,边际效益也可能不如前者。然而,如果坚持设计基于SRAM的DSA加速器,为何不研究一下Tesla Dojo的构型呢?他们通过小颗粒SRAM+PE配对分散排列形成的2D矩阵的近存结构,而非片上集中主存,应该能降低一部分成本,而这种结构可能处理相当复杂的操作,在非LLM计算场景中可能表现优异。
审核编辑 黄宇
-
刷屏的Groq芯片,速度远超英伟达GPU!成本却遭质疑2024-02-22 5208
-
进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片2024-05-13 6751
-
英伟达TITAN AI显卡曝光,性能狂超RTX 4090达63%!# 英伟达# 显卡jf_02331860 2024-07-24
-
加速抛弃英伟达,微软又发布一颗芯片 #微软 #英伟达 #半导体 #芯片 #电路知识jf_15747056 2024-11-21
-
美对华芯片出口“松绑”:英伟达H200获准进入中国市场#AI芯片#英伟达#H200芯片jf_15747056 2026-01-14
-
英伟达GPU惨遭专业矿机碾压,黄仁勋宣布砍掉加密货币业务!2018-08-24 4309
-
英伟达DPU的过“芯”之处2022-03-29 5961
-
依图挺入“AI芯片”赛道 新产品“求索”视觉推理能力超越英伟达2019-05-11 4159
-
如何取替英伟达?如何颠覆英伟达?2023-07-10 2931
-
“网红”芯片Groq让英伟达蒸发5600亿2024-02-27 2507
-
英伟达被控延迟出货,阻碍竞争2024-02-29 1192
-
英伟达推出AI模型推理服务NVIDIA NIM2024-06-04 1624
-
英伟达GTC25亮点:NVIDIA Blackwell Ultra 开启 AI 推理新时代2025-03-20 1918
-
英伟达重磅出手!AI 推理存储全面觉醒2025-12-26 12417
-
从英伟达电话会看Agentic AI推理与FPGA价值2026-03-04 1448
全部0条评论

快来发表一下你的评论吧 !
