

为什么深度学习的效果更好?
描述
导读
深度学习是机器学习的一个子集,已成为人工智能领域的一项变革性技术,在从计算机视觉、自然语言处理到自动驾驶汽车等广泛的应用中取得了显著的成功。深度学习的有效性并非偶然,而是植根于几个基本原则和进步,这些原则和进步协同作用使这些模型异常强大。本文探讨了深度学习成功背后的核心原因,包括其学习层次表示的能力、大型数据集的影响、计算能力的进步、算法创新、迁移学习的作用及其多功能性和可扩展性。
为什么深度学习的效果更好?
分层特征学习深度学习有效性的核心在于其分层特征学习的能力。由多层组成的深度神经网络学习识别不同抽象级别的模式和特征。初始层可以检测图像中的简单形状或纹理,而更深的层可以识别复杂的对象或实体。这种多层方法使深度学习模型能够建立对数据的细致入微的理解,就像人类认知如何处理从简单到复杂的信息的方式一样。这种分层学习范式特别擅长处理现实世界数据的复杂性和可变性,使模型能够很好地从训练数据泛化到新的情况。海量数据大数据的出现给深度学习带来了福音。这些模型的性能通常与它们所训练的数据集的大小相关,因为更多的数据为学习底层模式和减少过度拟合提供了更丰富的基础。深度学习利用大量数据的能力对其成功至关重要,它使模型能够在图像识别和语言翻译等任务中实现并超越人类水平的表现。深度学习模型对数据的需求得到了信息数字化以及数据生成设备和传感器激增的支持,使得大型数据集越来越多地可用于培训目的。计算能力增强GPU 和 TPU 等计算硬件的进步极大地实现了大规模训练深度学习模型的可行性。这些技术提供的并行处理能力非常适合深度学习的计算需求,从而实现更快的迭代和实验。训练时间的减少不仅加快了深度学习模型的开发周期,而且使探索更复杂、更深的网络架构成为可能,突破了这些模型所能实现的界限。 算法创新深度学习的进步也是由不断的算法创新推动的。Dropout、批量归一化和高级优化器等技术解决了深度网络训练中的一些初始挑战,例如过度拟合和梯度消失问题。这些进步提高了深度学习模型的稳定性、速度和性能,使它们更加稳健且更易于训练。迁移学习和预训练模型
迁移学习在深度学习民主化方面发挥了关键作用,使深度学习模型能够应用于无法获得大型标记数据集的问题。
通过微调在大型数据集上预先训练的模型,研究人员和从业者可以使用相对少量的数据实现高性能。这种方法在医学成像等领域尤其具有变革性,在这些领域获取大型标记数据集具有挑战性。
标多功能性和可扩展性最后,深度学习模型的多功能性和可扩展性有助于其广泛采用。这些模型可以应用于广泛的任务,并根据数据和计算资源的可用性进行调整。这种灵活性使深度学习成为解决各种问题的首选解决方案,推动跨学科的创新和研究。
代码
为了使用完整的 Python 代码示例来演示深度学习的工作原理,让我们创建一个简单的合成数据集,设计一个基本的深度学习模型,对其进行训练,并使用指标和图表评估其性能。
我们将使用NumPy库进行数据操作,使用 TensorFlow 和 Keras 构建和训练神经网络,并使用 Matplotlib 进行绘图。
import numpy as npimport matplotlib.pyplot as plt.pyplot as pltfrom sklearn.datasets import make_moonsfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Densefrom tensorflow.keras.optimizers import Adamfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_score
# 步骤 1:生成合成数据集X, y = make_moons(n_samples=1000, noise=0.1, random_state=42)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
#步骤2:构建深度学习模型model = Sequential([ Dense(10, input_dim=2, activation='relu'), Dense(10, activation='relu'), Dense(1, activation='sigmoid')])
model.compile(optimizer=Adam(learning_rate=0.01), loss='binary_crossentropy', metrics=['accuracy'])
# 步骤 3:训练模型history = model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=100, verbose=0)
# 步骤 4:评估模型predictions = model.predict(X_test) > 0.5print(f"Accuracy: {accuracy_score(y_test, predictions)}")
# 绘图plt.figure(figsize=(14, 5))
# 绘制决策边界plt.subplot(1, 2, 1)plt.title("Decision Boundary")x_span = np.linspace(min(X[:,0]) - 0.25, max(X[:,0]) + 0.25)y_span = np.linspace(min(X[:,1]) - 0.25, max(X[:,1]) + 0.25)xx, yy = np.meshgrid(x_span, y_span)grid = np.c_[xx.ravel(), yy.ravel()]pred_func = model.predict(grid) > 0.5z = pred_func.reshape(xx.shape)plt.contourf(xx, yy, z, alpha=0.5)plt.scatter(X[:,0], X[:,1], c=y, cmap='RdBu', lw=0)
# 绘制损失曲线plt.subplot(1, 2, 2)plt.title("Training and Validation Loss")plt.plot(history.history['loss'], label='Train Loss')plt.plot(history.history['val_loss'], label='Val Loss')plt.legend()
plt.tight_layout()plt.show()
该代码执行以下操作:
make_moons使用 的函数生成合成数据集sklearn,该数据集适合展示深度学习在非线性可分离数据上的强大功能。
构建一个具有两个隐藏层的简单神经网络,对隐藏层使用 ReLU 激活,对输出层使用 sigmoid 激活,以执行二元分类。
使用二元交叉熵作为损失函数和 Adam 优化器在合成数据集上训练模型。
评估模型在测试集上的准确性并打印它。
- 绘制模型学习的决策边界,以直观地检查它区分两个类的程度,并绘制历元内的训练和验证损失以演示学习过程。
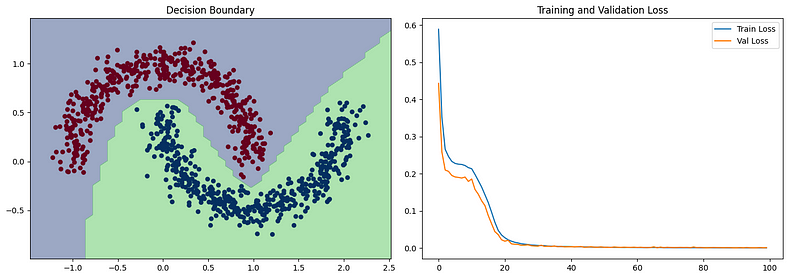
此示例说明了深度学习在从数据中学习复杂模式方面的有效性,即使使用相对简单的网络架构也是如此。决策边界图将显示模型如何学习分离两个类,损失图将显示模型随时间的学习进度。
总结
深度学习的成功归因于其复杂的特征学习方法、大型数据集的可用性、计算硬件的进步、算法创新、迁移学习的实用性及其固有的多功能性和可扩展性。随着该领域的不断发展,深度学习的进一步进步预计将释放新的功能和应用,继续其作为人工智能基石技术的发展轨迹。
本文来源:小Z的科研日常
-
AI大模型与深度学习的关系2024-10-23 4310
-
深度学习GPU加速效果如何2024-10-17 1349
-
深度学习的七种策略2023-08-17 3166
-
什么是深度学习?使用FPGA进行深度学习的好处?2023-02-17 2179
-
CMOS和CCD哪个视觉效果更好2023-01-31 3455
-
深度学习模型是如何创建的?2021-10-27 2408
-
深度学习存在哪些问题?2021-10-14 1973
-
深度学习DeepLearning实战2021-01-09 19138
-
深度学习是什么?了解深度学习难吗?让你快速了解深度学习的视频讲解2018-08-23 1462
-
Nanopi深度学习之路(1)深度学习框架分析2018-06-04 4395
-
阿里深度学习:在深度学习CTR预估核心问题上的应用进展2018-04-10 6886
全部0条评论

快来发表一下你的评论吧 !
