

度小满轩辕:金融行业的大模型实战派
描述
金融行业被广泛认为是AI大模型技术落地的前哨站,也是“人工智能+”行动的焦点所在。面向金融场景广泛、多样化的大模型需求,度小满轩辕系列全新发布了12款金融大模型。其中包括6B、13B、70B参数的基座模型、对话模型、int4/int8量化模型,并且实现了完全开源,供广大开发者下载使用。
总体来看,12款金融大模型包括3种参数。2023年5月,度小满开源了国内首个千亿级中文金融大模型“XuanYuan-176B”。2023年9月,“XuanYuan-70B”大模型在C-Eval和CMMLU两大权威榜单上位列所有开源模型榜首。本次度小满“轩辕”模型矩阵再次升级,十亿-百亿-千亿参数全覆盖,实现多场景任务适配。
而从效果上看,度小满轩辕达成了18大维度金融实战能力遥遥领先,多场景6B模型与72B模型表现相当;通用能力同样达到开源模型TOP水平,看齐GPT-4,并且采用了独创的数据处理流水线,生产更丰富、更安全、更符合中文场景的数据。通过首次将人类偏好对齐引入金融垂域大模型训练,相关模型实现了安全性显著提升、有用性突破瓶颈、金融任务表现明显增强 。
让我们来走进度小满轩辕,透视金融领域的大模型变革。
度小满「轩辕」大模型:全参数矩阵
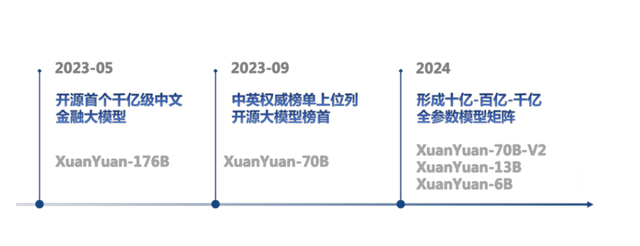
(度小满轩辕大模型发布时间轴)
度小满轩辕系列已经有17款开源大模型,适配广泛场景任务,满足不同开发者需要。

(度小满轩辕大模型矩阵)
模型矩阵的设计考虑了不同的应用场景和性能要求:70B及以上的模型专门针对需要深度分析、复杂指令执行以及全方位Agent调用的场景,而6B、13B的模型则更加适用于对响应速度有高要求、面向小规模场景和单任务的应用,它们也同样能够处理计算、编程、创作等一系列通用需求。特别地,最小化的XuanYuan-6B-4-bit量化Chat模型以其低推理部署成本,进一步降低了大模型的应用门槛。
模型效果:18大维度金融实战能力遥遥领先
01金融能力
将轩辕系列大模型在金融自动评测集FinanceIQ测试集上进行测试,FinanceIQ涵盖了注册会计师(CPA)、税务师、经济师、银行从业资格、基金从业资格、证券从业资格、期货从业资格、保险从业资格(CICE)、理财规划师等十大权威金融领域考试。结果如下表,XuanYuan-70B-V2在该项评测任务上拥有超过GPT-4的水平,在知识层面展示出金融领域专家的水平。
同时,为了考察轩辕大模型在金融实际任务上的能力,轩辕团队还特别组织了金融专家为对话大模型进行人工评测。任务的设计均是从金融行业实际应用场景出发,去判断轩辕是否在各项金融任务上具备“实战能力”。

(人工金融评测集任务构成)
最终结果显示,轩辕大模型各个参数上均具有“以小搏大”的实力,达到自己2倍甚至5倍参数量的模型水平。在各项金融评测任务上,XuanYuan-6B表现超越市面最新13B中文开源模型(左图),XuanYuan-13B表现超越市面最新72B中文开源模型(中图),XuanYuan-72B-V2表现可以媲美GPT4(右图),并且在金融法规、金融产品信息等中文场景上超越。

(轩辕拥有远超同参数水平的金融能力)
02通用能力
将轩辕大模型在MMLU、CEVAL、CMMLU、GSM8K、HumanEval等中外主流评测集上进行评测,观察大模型在知识、逻辑、代码等通用能力上的表现。同时加入类似参数矩阵的LLaMA2系列进行比较,结果显示轩辕不同参数大模型在各项榜单成绩上均有优异表现,在CMMLU、C-Eval等多个中文评测榜单上,更是有超越GPT-4的水准。
进一步分析发现,经过专门优化以增强考试能力的XuanYuan-6B和XuanYuan-13B模型,在C-Eval和CMMLU这两个中文考试评测指标上有了显著提升。然而,需要注意的是,“高分”并不意味着“高能力”。评测集成绩可通过优化模型考试能力来提升,不直接等同于模型在实际应用中的优势。因此,尽管小参数模型在某些评测中表现出色,这并不意味着它们的各方面真实能力均超越了同系列大参数模型。
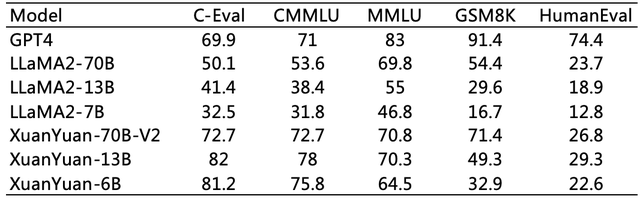
(轩辕大模型在各个评测集上的分数)
「轩辕」技术解析:对齐技术突破能力瓶颈,面向公众开放自动化训练框架
度小满轩辕大模型团队在过去一年,对大模型训练的各个环节积累了丰富的经验。这包括建立了一套完整的数据处理流水线、采用更适配领域模型的高效训练方法等,以及本次突破性的利用人类偏好对齐技术,极大地提升了6B、13B、70B模型的对话能力,显著增强了模型的场景适应性。
轩辕系列大模型使用DeepSpeed分布式训练框架,引入动态评估与调整机制以优化训练过程。在微调阶段,轩辕特别的采用了Self-QA策略来收集指令微调数据。该方法能够在没有人工标注的情况下生成大量高质量的问答数据,为模型提供有监督的训练样本,有效提升模型的学习效率和质量。
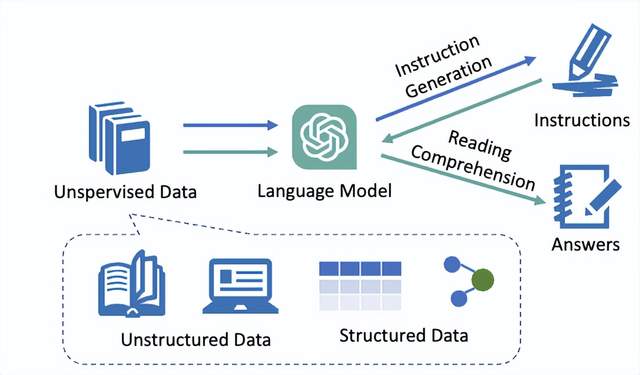
(轩辕大模型Self-QA数据构造方法)
针对金融领域的特定需求,轩辕大模型还开发了一种混合微调训练框架,旨在通过融合通用与特定领域数据来增强模型性能及适应性。这种混合微调方法不仅显著提高了模型在特定任务的表现,也增强了其整体的泛化能力和适应性,为金融领域任务的性能提升开辟了新途径。
度小满创新地在金融领域大模型中引入了人类偏好对齐技术,开创了领域内强化对齐训练的先河。通常,领域大模型仅在微调阶段引入特定领域数据,但这种方法在实际应用中常常显示出局限性。金融行业的复杂性要求模型能够更深入地理解并适应行业特定的需求,而强化对齐训练有助于突破仅依靠微调所能达到的性能瓶颈。
轩辕团队精心构建了涵盖通用性、安全性和金融特性的Prompt数据集,并组织了专业的标注团队对成对的回答进行偏好标注。接下来,团队通过一系列实践、分析和改进,成功完成了奖励模型(Reward Model)和后续的强化(采用近端策略优化算法)训练。下图以XuanYuan-6B为例展示了模型在通用性和金融能力的综合评估结果。从图中可以看出,在两个领域,经过人类偏好对齐后,模型的能力都有了极大的提升,证明了强化对齐训练的有效性。
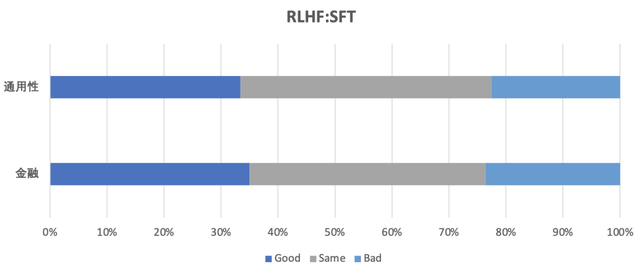
(RLHF-model vs SFT-model)
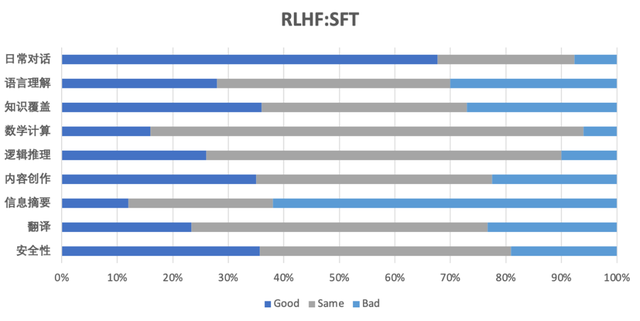
(通用能力:RLHF-model vs SFT-model)
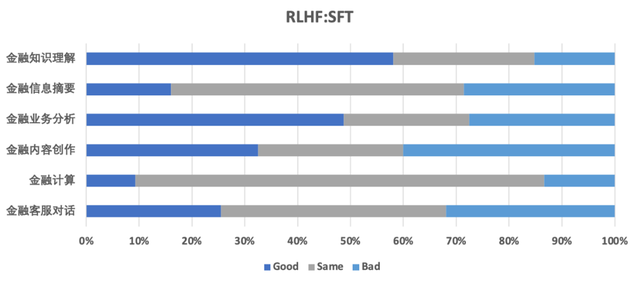
(金融能力:RLHF-model vs SFT-model)
度小满轩辕大模型团队一向贯彻开源开放的原则。为了让广大开发者能够更容易的上手使用大模型,使用真实数据和真实代码作为示例,详细介绍了训练模型的每个关键步骤。现在相关代码已经上传开源社区,供广大用户实操体验。
金融行业需要怎样的大模型?
金融领域对大模型的要求远超过基本的“判断”与“生成”能力,更加强调在“分析”与“决策”过程中的高级能力,这些能力是触及金融企业核心利益的关键。大模型的价值体现在其能否在核心业务场景中发挥实际作用,如通过综合分析用户信息以支持风险评估、客户画像绘制、精准营销策略,或通过企业数据分析支持财务审查、智能投顾和行业研究。
金融大模型的最终目标是提高企业ROI。这意味着,高效的金融大模型应当能够在实际应用中,如客服场景,通过提升对话处理、指令遵循和意图理解能力,不仅短期内提高客服效率,长期还可能实现机器人客服的全面替代,重塑客户服务流程,推动金融服务向更高智能化水平迈进。
结束语:关于度小满「轩辕」大模型
度小满轩辕大模型系列具有以下特色:
· 多尺寸开源,开发者友好。
· 拥抱开源,免费下载使用。
· 版本快速迭代,社区持续更新。
· 持续面向金融行业伙伴交流共建。
在今年的政府工作报告中,提出了“大力发展科技金融、绿色金融、普惠金融、养老金融、数字金融”。在这样的宏观背景下,AI大模型落地金融场景,为行业带来全新的智能化发展机遇,是金融行业本身的发展意愿,也是“新质生产力”的客观要求。
作为“实战派”的度小满轩辕,已经应用在金融领域的各个业务场景,并且初见成效。未来,度小满轩辕会成为金融行业的一个支点,为更多智能化探索打开大门。
欲知“轩辕”大模型详情,可移步Github官网。
-
九天菜菜大模型agent智能体开发实战2026一月班2026-04-15 475
-
大模型AI应用开发企业级项目实战2026-06-30 43
-
AI大模型应用开发实战训练营-第18期2026-07-06 42
-
Hollis【实战课程】大模型应用开发实战2026-07-08 131
-
百度世界·度小满金融大模型前沿发展论坛举办,头雁度小满的大模型落地实践脑极体 2023-10-17
-
使能智慧金融终端产业化,润和软件发布OpenHarmony金融行业重要成果2022-11-09 1812
-
百度AI开发者大会于7月4日举办,度小满金融首秀的三大猜想2018-07-03 1023
-
树莓派(Raspberry Pi)实战指南.pdf2018-05-07 3648
-
区块链技术与金融到底该怎么结合2018-12-11 7218
-
度小满通过AI技术创新和应用,降低小微企业融资成本2021-11-19 2141
-
做实大模型的产业价值,度小满深耕“NLP+金融”2023-05-18 1503
-
NVIDIA 专家做客“技术圆桌派”,详解 AI 赋能量化金融2023-05-24 1589
-
金融行业迎来大模型时代,存算基建成决胜关键2023-09-25 969
-
度小满,让“推理大模型”走向金融核心业务2024-10-31 3302
-
4台树莓派5跑动大模型!DeepSeek R1分布式实战!2025-03-24 1785
全部0条评论

快来发表一下你的评论吧 !
