

AI芯片的技术原理与架构
人工智能
描述
这两年,图形处理和AI(人工智能)加速计算需求的不断涌现,国内AI芯片市场已呈现出百花齐放的发展态势,衍生出多种类型的AI加速产品。近期的全国政协会议也谈到了这个---“人工智能已经成为国家间科技竞争的必争之地。要深入挖掘国产AI芯片算力潜力,加速推动国产操作系统发展,夯实人工智能发展算力底座,助推新质生产力跑出加速度”。所以我们谈下AI芯片。
作为专为AI计算需求而设计制造的集成电路,AI芯片不仅革新了计算机处理信息的方式,更在图像识别、语音识别、自然语言处理、自动驾驶等多个前沿领域发挥了至关重要的作用。
AI芯片的基本概念
AI芯片,也称作AI加速器或智能芯片,是一种特制的微处理器,专门为高效运行人工智能算法而设计。不同于传统的CPU、GPU等通用处理器,AI芯片致力于解决AI应用中的大规模并行计算问题,尤其是针对神经网络模型的密集型数学运算,如矩阵乘法、卷积操作和激活函数计算等。这种高度定制化的设计极大地提升了计算效率,降低了能耗,并实现了实时响应和高性能推理能力。
AI芯片的技术原理与架构
人工神经网络模型 AI芯片的核心原理基于人工神经网络,其中芯片内部的处理单元模拟了生物神经元的工作机制。每一个处理单元能够独立进行复杂的数学运算,例如权重乘以输入信号并累加,形成神经元的激活输出。激活函数则决定了信号如何转化为有意义的结果,它是AI芯片中不可或缺的一部分。
硬件架构 AI芯片的硬件架构多种多样,根据其设计目标和应用场景,可分为以下几类:
GPU(图形处理器): GPU原本主要用于图形渲染,但因其并行计算能力强,被广泛用于训练大型深度学习模型,尤其擅长处理浮点数密集型计算任务。
FPGA(现场可编程门阵列): FPGA具有高度灵活的可编程性,能够在硬件层面快速重新配置以适应不同的AI算法,适用于早期开发阶段和动态工作负载的场景。
ASIC(专用集成电路): ASIC是为特定AI任务定制的芯片,相较于GPU和FPGA,它在特定应用中的计算效率更高,能耗更低,但缺乏通用性。
TPU(张量处理单元): Google推出的TPU是专门针对机器学习任务设计的ASIC实例,专注于高效的矩阵运算,尤其适合TensorFlow框架下的深度学习模型。
AI芯片的分类与市场应用
AI芯片广泛应用于各个领域,包括但不限于:
1、自动驾驶:AI芯片能够实时处理车辆传感器收集的数据,实现精确的导航和决策,提高自动驾驶的安全性和可靠性。
2、智能安防:AI芯片可用于视频监控、人脸识别等安防领域,提高安全监控的效率和准确性。
3、智能家居:AI芯片能够支持智能家居设备的智能化控制和管理,提升居住体验。
4、医疗健康:AI芯片可用于医疗影像分析、疾病诊断等领域,辅助医生进行精准治疗。
国内AI芯片现状以及未来挑战
国内AI芯片市场近年来发展迅猛,涌现出了一批具有创新能力和市场竞争力的企业,其中一些知名的包括华为、寒武纪、地平线、百度等,国外有英伟达等,下面分别列举了每个公司的一款芯片的介绍:
华为海思的昇腾910
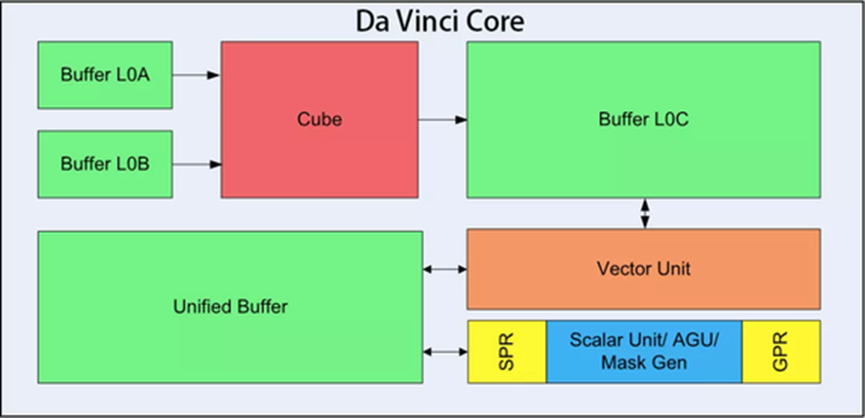
达芬奇架构
架构:基于达芬奇架构设计
制程工艺:7nm
核心数量:配备有大量AICore(人工智能内核),例如提到的256个AICore
性能指标:半精度(FP16)算力:高达256TeraFLOPS(每秒万亿次浮点运算)
整数精度(INT8)算力:可达512 TeraOPS(每秒万亿次整数运算)
支持高速内存接口和通道,比如128通道全高清视频编解码能力
最大功耗:约为350瓦
寒武纪的思元370
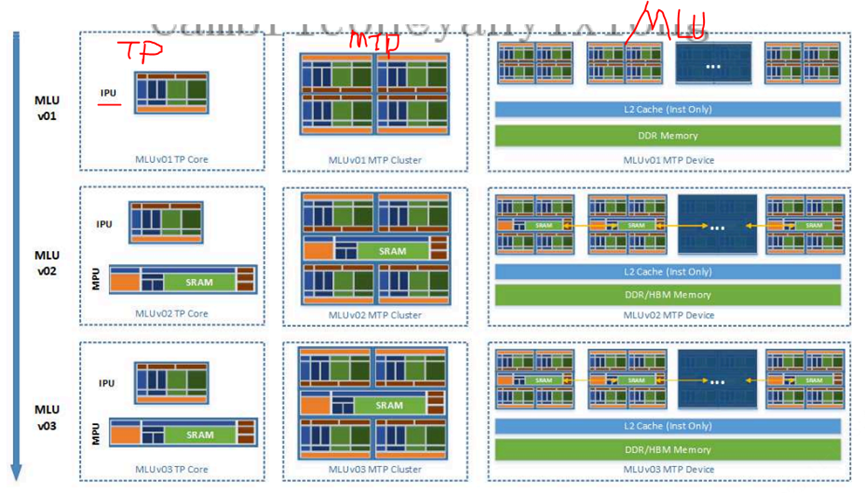
MLU架构
架构:MLUarch03
算力:最高256 TOPS(INT8),64 TOPS(FP16)
制程工艺:7nm
性能指标:最大算力高达256TOPS(INT8精度)
集成的晶体管数量:390亿个
内存支持:支持LPDDR5内存
应用场景:适用于云计算数据中心
最大功耗: 250W
地平线的征程5
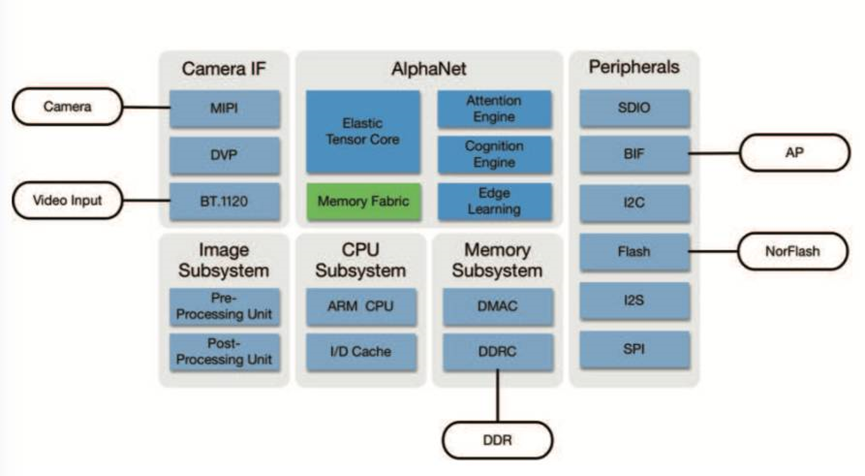
地平线架构
征程5:
架构:双核BPU:地平线自研的第二代贝叶斯架构,专为AI计算优化。
算力:单颗芯片AI算力最高可达128TOPS,能够处理大量的并行计算任务。
功耗:30W
工艺:16nm
应用场景:自动驾驶、智能座舱、智能监控等车载AI
百度昆仑芯片
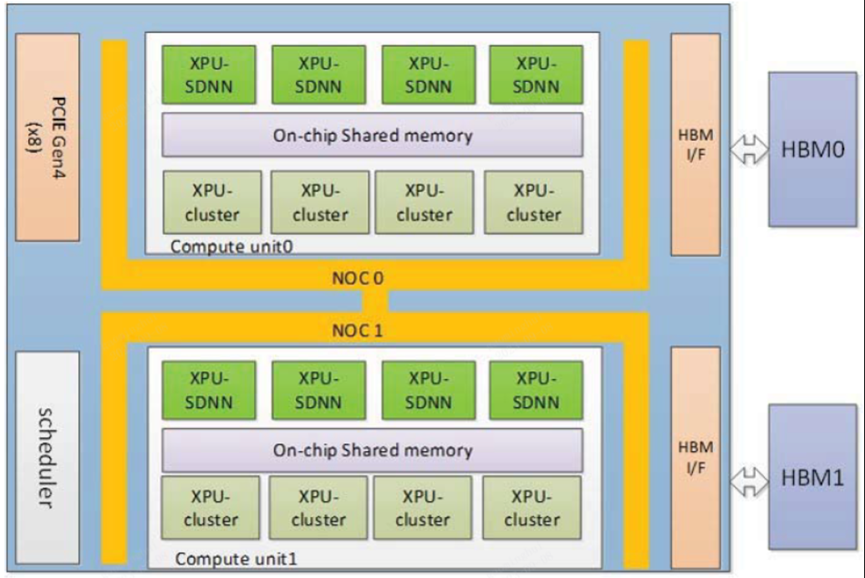
昆仑架构
架构:百度昆仑2芯片采用自研的第二代XPU架构,这是一种针对AI计算进行了深度优化的架构设计,能够高效执行大规模并行计算任务,特别适合深度学习和机器学习算法的处理。
算力:INT8整数精度算力达到256TeraOPS(每秒万亿次整数运算)。
半精度(FP16)算力为128 TeraFLOPS(每秒万亿次浮点运算)。
功耗:最大120W
工艺: 7nm。
应用场景:百度昆仑2芯片适用于云、端、边等多场景的AI计算需求。
英伟达H100
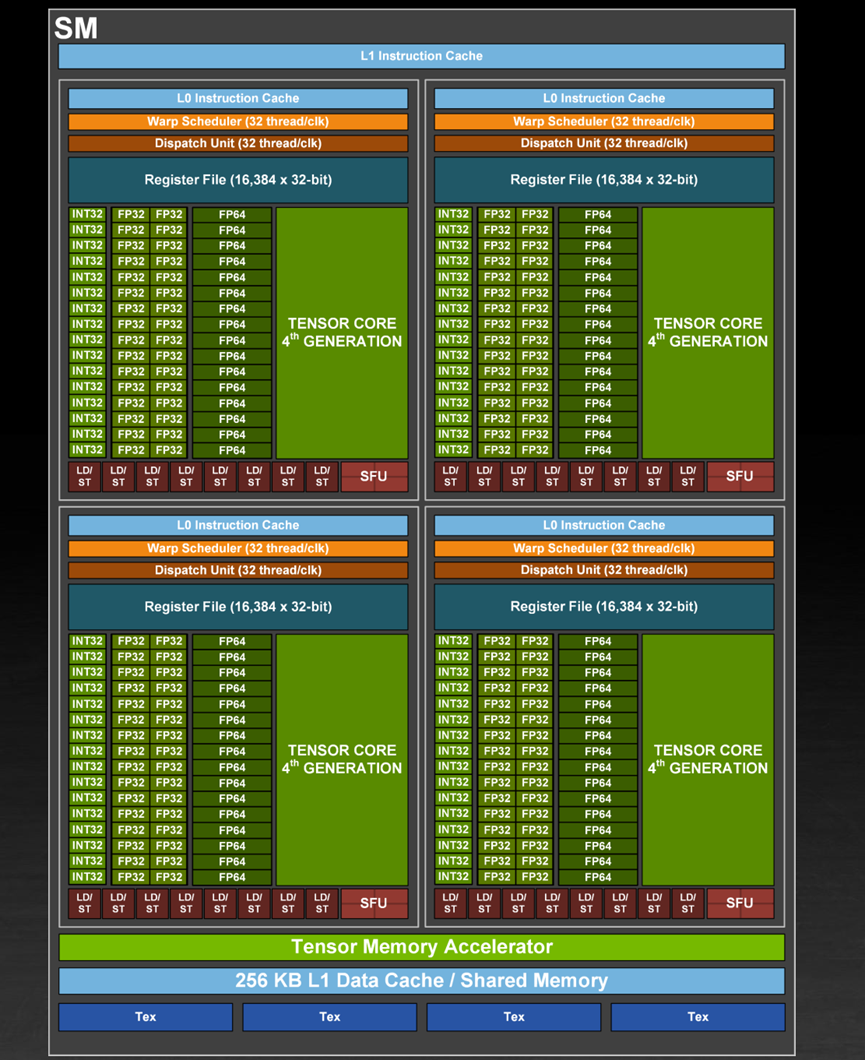
Nvidia H100SM
架构:Hopper架构
算力:FP64为67TFLOPS;
FP32为989TFLOPS;
FP16为1979TFLOPS;
BF16为1979TFLOPS;
INT8为3958TFLOPS
功耗:700W
工艺:4nm
应用场景:机器学习、深度学习训练和推理、科学计算模拟、数据分析、自然语言处理等
可以看出,尽管国内AI芯片在设计和应用上取得了一定的成就,但与英伟达等国际领先企业相比,仍存在一定的性能差距。国内AI芯片还面临着一系列关键的挑战:
1、技术壁垒与核心专利:在高端芯片设计、EDA工具、IP核以及先进制造工艺等方面,我国企业与国际领先水平相比存在差距,尤其是在7nm及以下的先进制程上,对外国先进技术和设备的依赖度较高,还面临被制裁的风险。
2、市场竞争与品牌认知:虽然国内市场华为等厂商影响力较大,但在国际市场上,英伟达、英特尔、AMD等公司在AI芯片领域还是占据了主导地位,中国企业要在全球范围内建立品牌影响力和客户信任度尚需时日。
3、人才储备与培养:高端AI芯片研发和设计需要大量专业人才,涉及的专业技术覆盖广泛,包括集成电路设计、算法优化、材料科学等,而中国在人才培养和引进方面还需进一步加强,以支撑产业的长远发展。
随着国内企业的不断努力和创新,相信未来这一差距会逐渐缩小。同时,国家也应加大对AI芯片产业的支持力度,推动国内AI芯片产业的快速发展。
审核编辑:黄飞
-
【书籍评测活动NO.64】AI芯片,从过去走向未来:《AI芯片:科技探索与AGI愿景》2025-07-28 52217
-
AI 芯片浪潮下,职场晋升新契机?2025-08-19 634
-
【「AI芯片:科技探索与AGI愿景」阅读体验】+内容总览2025-09-05 4125
-
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片的需求和挑战2025-09-12 3790
-
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片到AGI芯片2025-09-18 5886
-
新型DSP设计架构助力加速5G和AI开发2019-06-18 2075
-
手把手教你设计人工智能芯片及系统--(全阶设计教程+AI芯片FPGA实现+开发板)2019-07-19 8930
-
AI发展对芯片技术有什么影响?2019-08-12 3528
-
AI芯片热潮和架构创新有什么作用2020-04-23 2376
-
AI芯片热潮和架构创新是什么2020-04-24 2103
-
清华出品:最易懂的AI芯片报告!人才技术趋势都在这里 精选资料分享2021-07-23 3029
-
为何AI需要新的芯片架构?2023-05-13 1677
-
ai芯片技术架构有哪些?FPGA芯片定义及结构分析2023-08-05 10878
-
ai芯片技术架构有哪些2023-08-09 3341
-
AI芯片到底是什么?AI芯片技术架构有哪些?AI芯片主要有哪几种类型?2023-08-24 11092
全部0条评论

快来发表一下你的评论吧 !
